1. 스코어 기반 모델의 복습 (Recap)
강의 초반부에서는 지난 시간에 다루었던 스코어 기반 모델의 핵심 개념을 복습합니다.
- 스코어 함수(Score Function) 모델링: 확률 분포를 모델링하기 위해 로그 우도(log-likelihood)의 그라디언트인 스코어 함수를 사용합니다. 이는 우도를 증가시키기 위해 데이터가 이동해야 할 방향을 알려주는 벡터 필드와 같습니다.
- 잡음 제거 스코어 매칭(Denoising Score Matching): 데이터 분포 의 스코어를 직접 추정하는 대신, 가우시안 잡음으로 섭동(perturb)된 데이터 분포 의 스코어를 추정합니다.
- 이는 수학적으로 잡음 제거(Denoising) 목적함수와 동치임이 증명되었습니다. 즉, 잡음이 섞인 이미지 에서 추가된 잡음 벡터를 예측하여 원본 이미지를 복원하는 모델을 학습하면, 잡음이 섞인 분포의 스코어를 학습하는 것과 같습니다.
- 랑주뱅 역학(Langevin Dynamics): 학습된 스코어 모델을 이용해 샘플링을 수행할 때, 임의의 초기값에서 시작하여 스코어 방향(기울기)을 따라 이동하며 매 단계마다 약간의 잡음을 추가하는 과정을 반복합니다.
- 다중 잡음 레벨(Multiple Noise Levels): 단일 잡음 강도 대신, 여러 단계의 잡음 강도()를 설정하여 학습합니다. 샘플링 시에는 큰 잡음(낮은 밀도 정보)부터 시작하여 점차 작은 잡음(세밀한 구조)으로 이동하는 Annealed Langevin Dynamics를 사용합니다.
2. 확산 모델과 VAE의 연결 (Diffusion as VAE)
이 섹션에서는 확산 모델을 계층적 변분 오토인코더(Hierarchical VAE)의 특수한 형태로 해석하는 관점을 제시합니다.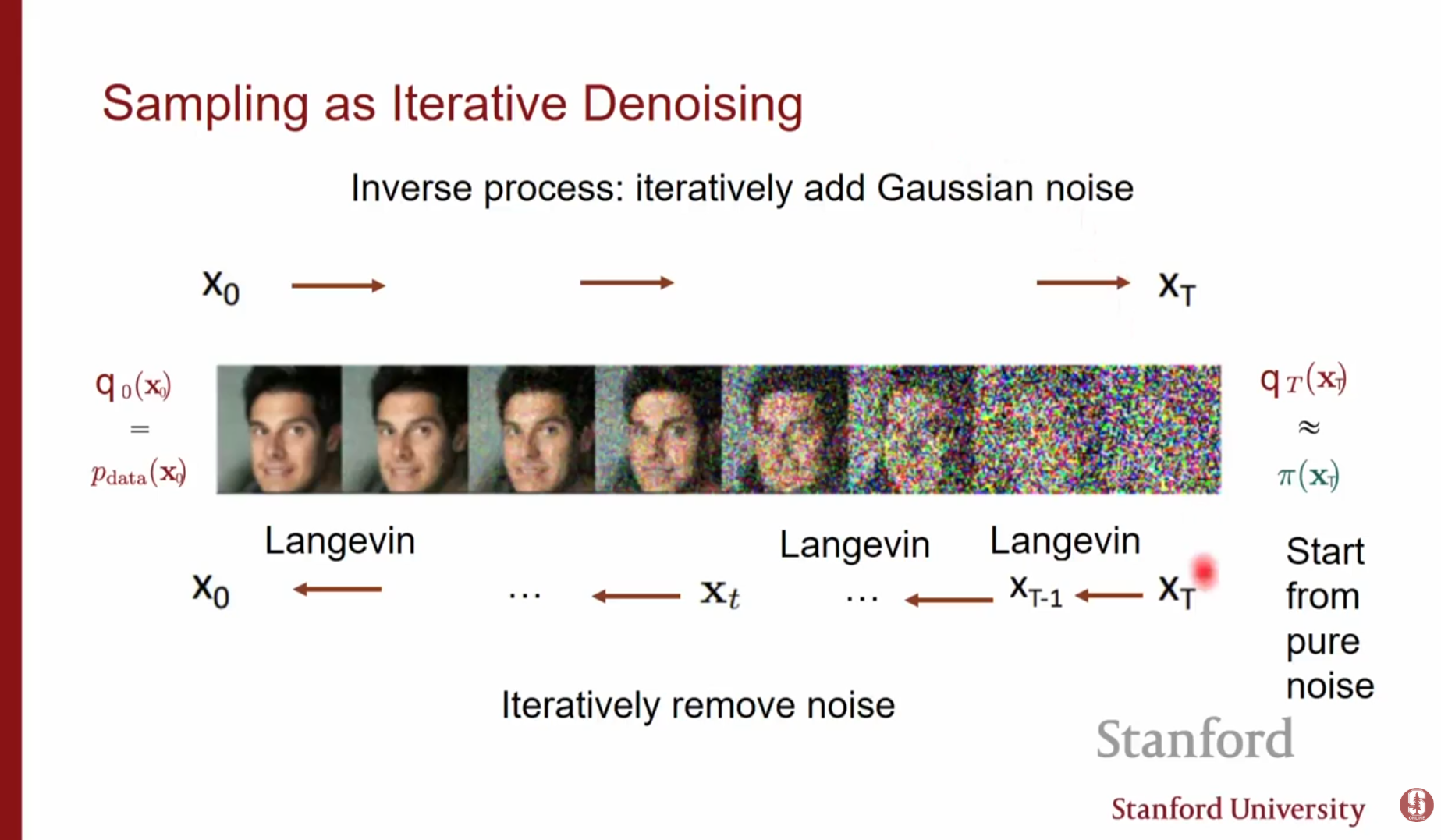
2.1. 인코더(Encoder): 확산 과정 (Forward Process)
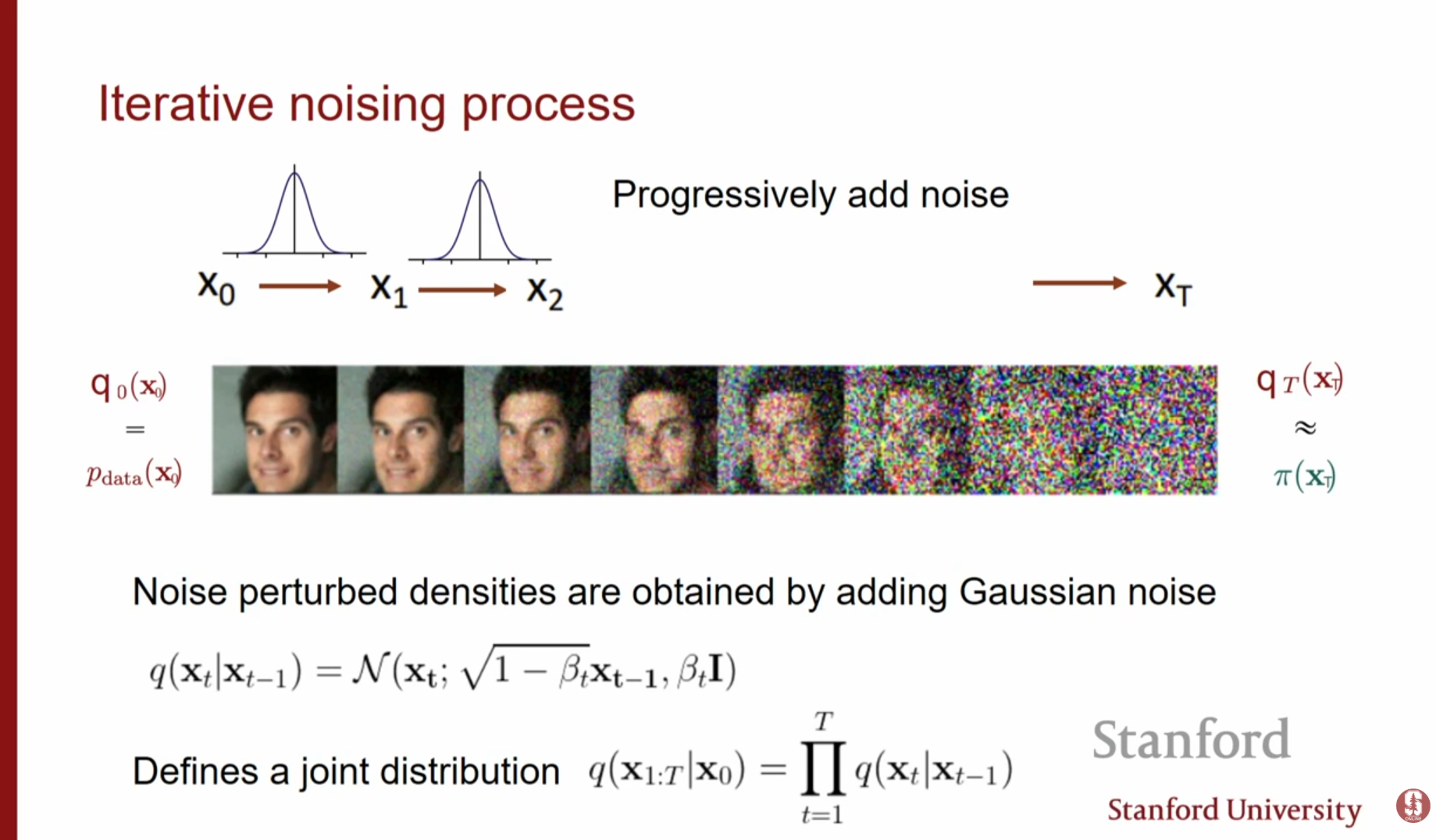
- 고정된 인코더: 확산 모델에서 데이터()에 잡음을 점진적으로 추가하여 완전한 잡음()으로 만드는 과정은 VAE의 인코더에 해당합니다. 하지만 일반적인 VAE와 달리 이 인코더는 학습되지 않으며, 단순히 가우시안 잡음을 더하는 고정된 과정입니다.
- 마르코프 체인(Markov Chain): 각 단계 에서의 잠재 변수 는 바로 전 단계 에만 의존합니다. 이를 조건부 확률로 나타내면 다음과 같습니다.
여기서 는 잡음의 크기를 조절하는 상수입니다. - 주변 분포(Marginals)의 가우시안 성질: 가우시안 커널을 여러 번 적용해도 결과는 여전히 가우시안입니다. 따라서 전체 과정을 시뮬레이션하지 않고도 에서 임의의 시점 로의 전이 확률 를 닫힌 형태(closed form)로 계산할 수 있어 효율적입니다.

2.2. 디코더(Decoder): 역확산 과정 (Reverse Process)
-
생성 모델: 생성 과정은 완전한 잡음()에서 시작하여 데이터를 복원해 나가는 과정으로, 이는 VAE의 디코더에 해당합니다.
-
변분적 정의: 실제 역방향 분포 는 알 수 없으므로, 이를 근사하는 파라미터화된 분포 를 학습합니다.
이때 평균 와 공분산 는 신경망을 통해 예측합니다.


3. 학습 목표와 등가성 (Training Objective & Equivalence)
확산 모델(DDPM)의 학습 목표인 ELBO(Evidence Lower Bound)가 잡음 제거 스코어 매칭과 수학적으로 동치임을 설명합니다.
- 계층적 VAE의 ELBO: 확산 모델은 잠재 변수들이 시간 순서대로 연결된 계층적 VAE이므로, 일반적인 VAE의 ELBO와 유사한 손실 함수를 가집니다. 우리는 데이터의 로그 우도를 최대화하기 위해 ELBO를 최대화(또는 음의 ELBO를 최소화)해야 합니다.

- 인코더가 고정된 VAE: 일반적인 VAE는 인코더()와 디코더()를 모두 학습하지만, 확산 모델에서는 인코더 가 고정되어 있으므로 디코더 부분만 최적화하면 됩니다.

- 스코어 매칭과의 연결: 디코더의 평균 를 예측할 때, 입력 이미지 에 추가된 잡음 을 예측하는 신경망 를 사용하도록 파라미터화하면, ELBO 손실 함수는 잡음 제거 스코어 매칭(Denoising Score Matching) 손실 함수와 형태가 같아집니다.
즉, VAE 관점에서 유도한 학습 목표가 결국은 잡음이 섞인 데이터의 스코어를 추정하는 것과 동일한 작업을 수행하게 됩니다.

심화 내용: DDPM과 스코어 기반 모델의 차이
비록 손실 함수는 거의 동일하지만, 샘플링 방식에는 차이가 있습니다. 스코어 기반 모델은 랑주뱅 역학(Langevin Dynamics)을 사용하여 각 잡음 레벨에서 여러 번의 스텝을 밟으며 분포를 수정(correct)해 나가는 반면, DDPM은 학습된 역방향 조건부 분포 를 따라 한 번의 스텝으로 다음 시점의 샘플을 생성합니다. 하지만 본질적으로 두 모델 모두 잡음을 예측하고 제거하는 유사한 절차를 따릅니다.
4. 연속 시간 관점: SDE (Stochastic Differential Equations)
이산적인 시간 단계(예: 1,000 단계)를 무한히 늘려 연속적인 시간 로 확장하면, 확산 모델을 확률 미분 방정식(SDE)으로 해석할 수 있습니다.
4.1. 전방향 및 역방향 SDE
- 전방향 SDE (Forward SDE): 데이터에 잡음을 추가하는 확산 과정은 다음과 같은 SDE로 표현됩니다.
여기서 는 표류(drift) 계수, 는 확산(diffusion) 계수이며, 는 위너 프로세스(브라운 운동)입니다.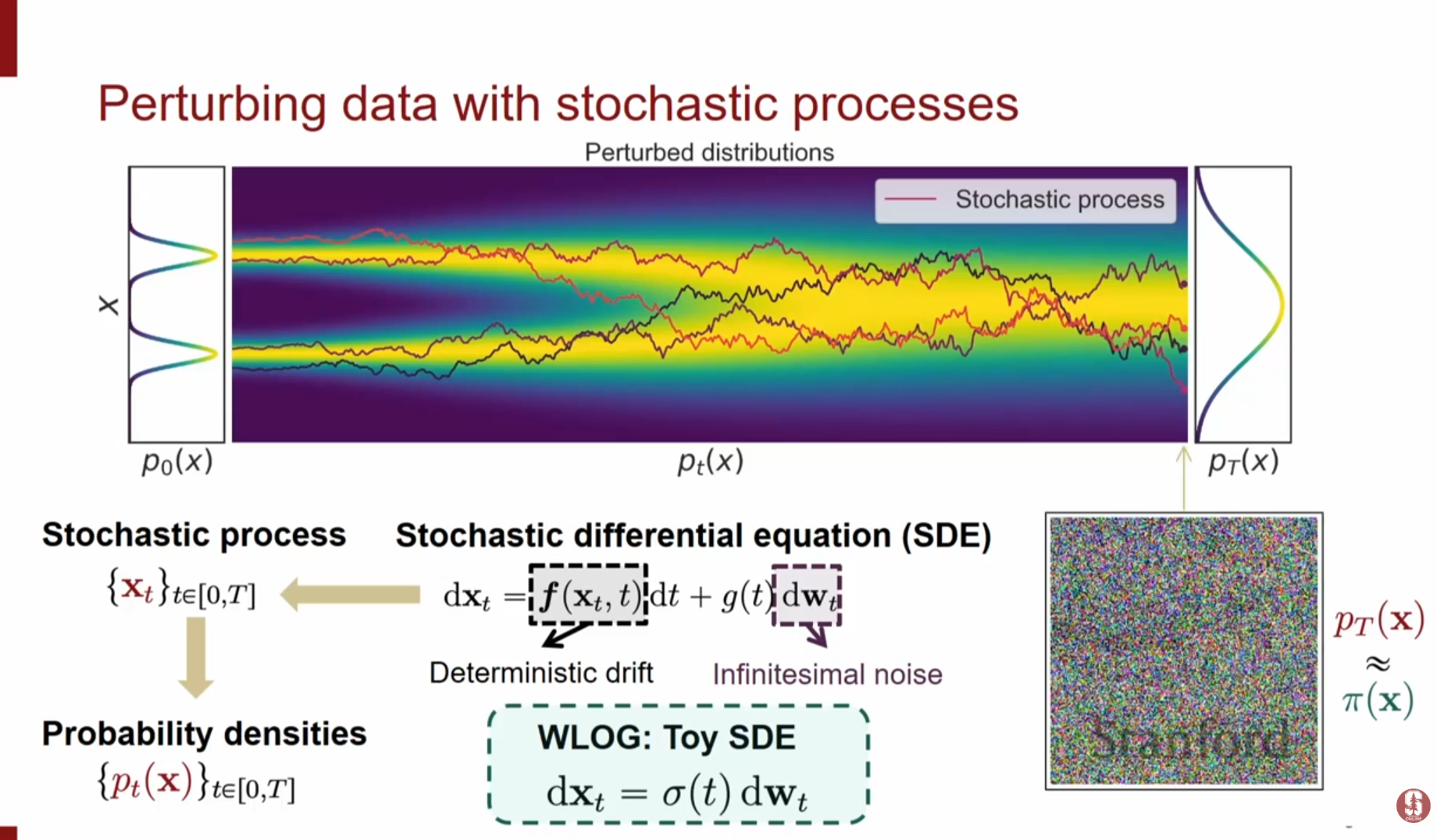
- 역방향 SDE (Reverse SDE): 앤더슨(Anderson)의 결과에 따르면, 위 확산 과정을 역으로 돌리는 과정 또한 SDE로 표현 가능합니다.
이 식을 풀기 위해서는 매 시점 에서의 스코어 함수 를 알아야 합니다.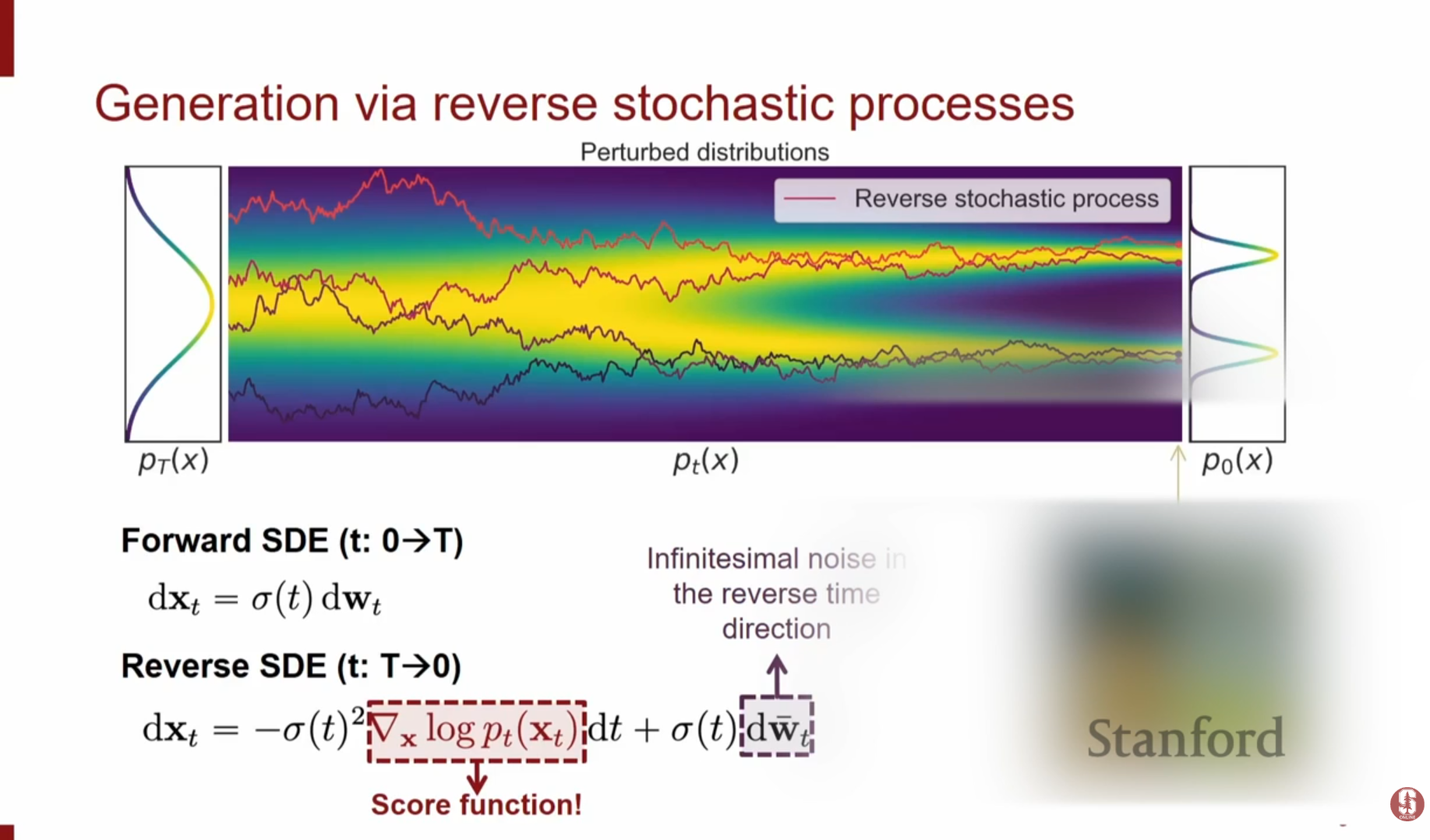

4.2. SDE를 이용한 샘플링
- 수치적 해결 (Numerical Solvers): 학습된 스코어 모델 를 실제 스코어 자리에 대입한 뒤, 오일러-마루야마(Euler-Maruyama)와 같은 수치적 방법을 사용하여 역방향 SDE를 적분함으로써 샘플을 생성할 수 있습니다.
- Predictor-Corrector 방법:
- Predictor: 수치적 SDE 솔버를 사용해 다음 시점의 샘플을 추정합니다. (DDPM 방식과 유사)
- Corrector: 랑주뱅 역학(MCMC)을 사용하여 현재 시점의 분포 에 더 잘 맞도록 샘플을 수정합니다. (스코어 기반 모델 방식)
이 두 가지를 결합하여 더 정확한 샘플링이 가능합니다.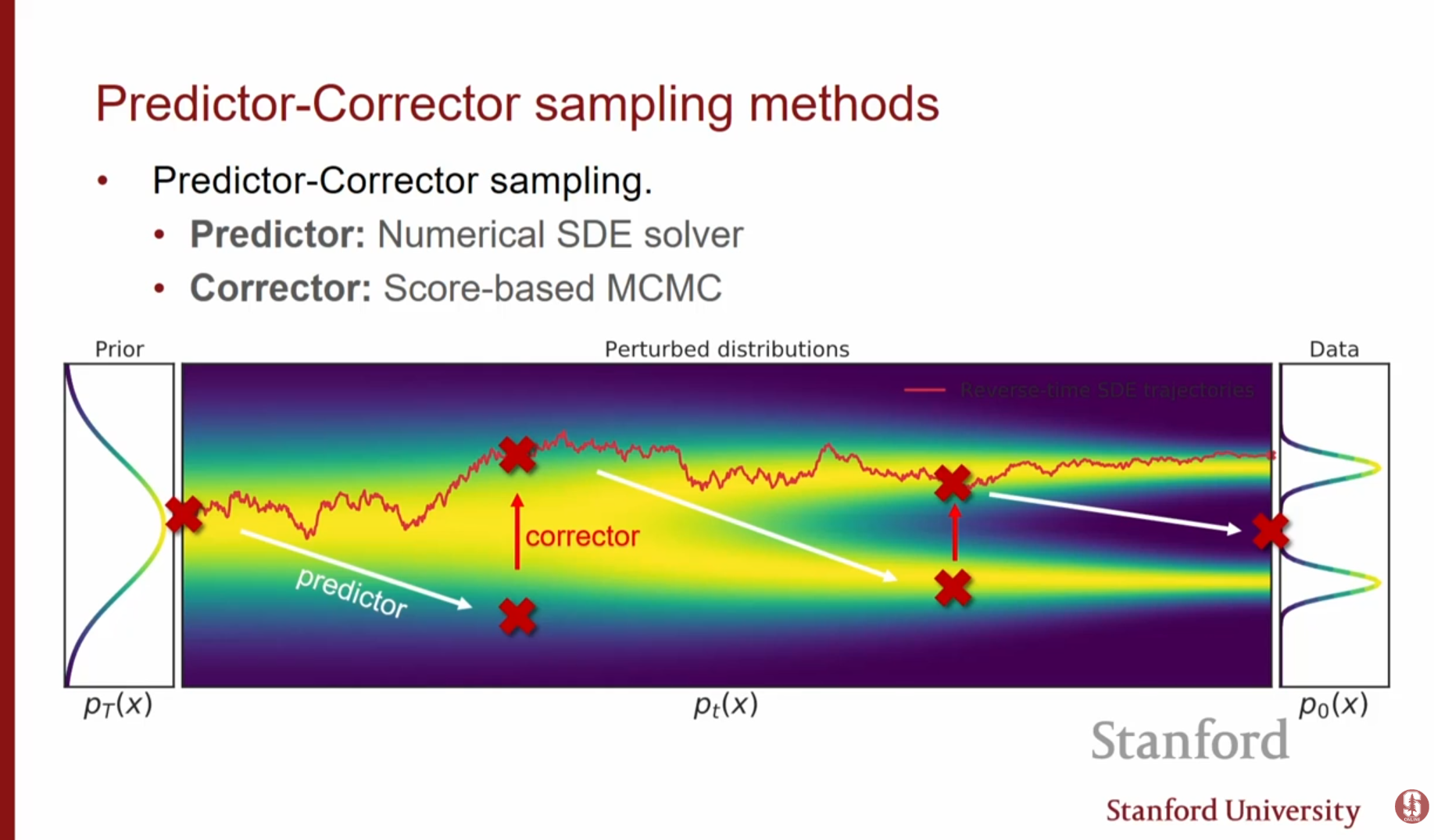
5. 확률 흐름 ODE (Probability Flow ODE)
SDE의 무작위성을 제거하고, 동일한 주변 확률 분포(Marginal Distribution)를 가지는 결정론적(Deterministic) 과정인 상미분 방정식(ODE)으로 변환할 수 있습니다.
- ODE로의 변환: 모든 시점 에서 SDE와 동일한 확률 밀도 를 생성하는 ODE가 존재합니다. 이를 Probability Flow ODE라고 합니다.
이 식에는 잡음항()이 없으므로, 초기 잡음이 정해지면 데이터까지의 경로가 결정론적으로 정해집니다.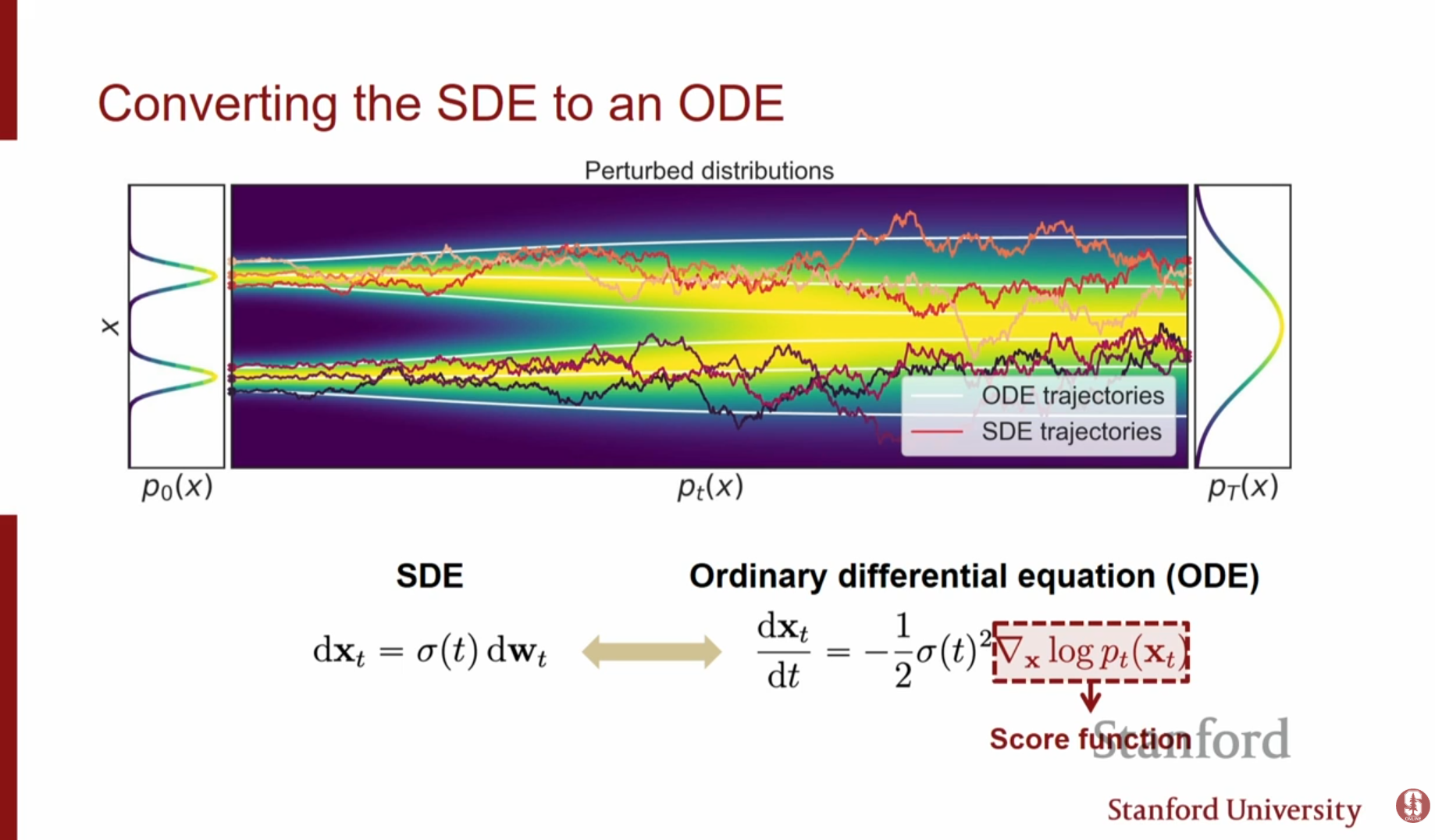
- 장점:
- 가역성(Invertibility): ODE는 역연산이 가능하므로, 데이터를 잠재 공간(잡음)으로 매핑하거나 그 반대로 매핑하는 것이 자유롭습니다. 이는 모델을 Flow 모델로 해석할 수 있게 합니다.
- 정확한 우도 계산 (Exact Likelihood): 변수 변환 공식(Change of Variable Formula)을 적용하여 데이터의 정확한 로그 우도를 계산할 수 있습니다.
6. QnA 섹션
강의 중 제기된 주요 질문들과 그에 대한 답변입니다.
Q1: 초기 데이터 분포나 중간 분포들이 반드시 가우시안이어야 하나요?
A1: 아닙니다. 초기 데이터 분포는 복잡한 다봉 분포(예: 이미지)일 수 있습니다. 중요한 것은 전이 커널(Transition Kernel)이 가우시안이라는 점입니다. 가우시안 잡음을 충분히 많이 더하면 최종 분포는 데이터 분포와 상관없이 가우시안에 가까워지기 때문에, 역과정의 시작점(Prior)을 단순한 가우시안으로 설정할 수 있습니다.
Q2: 왜 인코더를 학습시키지 않고 고정하나요? 인코더를 학습시키면 더 좋지 않을까요?
A2: 인코더를 학습시키는 것이 이론적으로는 ELBO를 더 높일 수 있지만, 실제로는 샘플 품질이 떨어지는 경우가 많습니다(예: 흐릿한 이미지). 인코더를 단순히 잡음을 더하는 과정으로 고정했을 때 학습이 더 안정적이며, 이 경우 손실 함수가 잡음 제거(Denoising)라는 직관적이고 효율적인 목표와 동치가 된다는 장점이 있습니다.
Q3: 샘플링 속도를 높이는 방법은 없나요?
A3: SDE나 ODE 관점에서 보면, 샘플링은 미분방정식을 푸는 과정입니다. 따라서 더 발전된 수치적 미분방정식 풀이법(Advanced Numerical Solvers)을 사용하거나, DDIM(Denoising Diffusion Implicit Models)과 같이 ODE 궤적을 따르는 방식을 사용하여 더 적은 단계로도 고품질의 샘플을 생성할 수 있습니다.
7. 핵심 내용 (Key Takeaways)
강의의 전체 내용을 관통하는 핵심 요약입니다.
- 확산 모델은 고정된 인코더를 가진 계층적 VAE입니다. 데이터를 서서히 잡음으로 만드는 전방향 확산 과정(인코더)과, 잡음에서 데이터를 복원하는 역방향 생성 과정(디코더)으로 구성됩니다.
- DDPM의 학습 목표(ELBO)는 잡음 제거 스코어 매칭과 동치입니다. 즉, 잡음이 섞인 데이터에서 잡음을 예측하여 제거하도록 학습하는 것이 곧 데이터 분포의 스코어를 학습하는 것과 같습니다.
- 연속 시간 확산 모델(SDE/ODE)은 통합된 프레임워크를 제공합니다. 시간 단계를 무한히 쪼개면 확산 과정은 SDE가 되며, 이를 결정론적인 ODE로 변환하면 정확한 우도 계산과 유연한 샘플링이 가능한 Flow 모델로 해석할 수 있습니다.
