1. Diffusion Model과 Score-based Model의 연결
강의 초반부에서는 지난 시간에 이어 Diffusion Model(DDPM)과 Score-based Model 간의 밀접한 연관성을 다시 한 번 짚어봅니다.
- DDPM과 VAE의 유사성: DDPM은 데이터를 노이즈로 만드는 인코더(Forward Process)와 노이즈에서 데이터를 복원하는 디코더(Reverse Process)를 가진 계층적 VAE(Variational Autoencoder)로 해석할 수 있습니다.
- 학습 목표(Objective)의 해석: VAE의 학습 목표인 ELBO(Evidence Lower Bound)를 최적화하는 것은 수학적으로 Denoising Score Matching 목표와 정확히 일치합니다.
- 즉, 라는 디코더 분포를 학습하는 것은 각 노이즈 레벨(time step)에 해당하는 스코어 함수(데이터 밀도의 기울기)를 학습하는 것과 같습니다.
- Langevin Dynamics와의 연결: 학습 후 생성 과정에서 가우시안 디코더를 사용해 샘플링하는 과정은 스코어를 따르며 약간의 노이즈를 더하는 Langevin Dynamics와 매우 유사한 형태를 띱니다.
2. 연속 시간 프레임워크: SDE (Stochastic Differential Equation)
이전까지는 유한한 단계(예: 1,000 step)를 가진 이산적인(Discrete) 프로세스를 다뤘다면, 이제는 이를 무한한 단계로 확장하여 연속적인 시간(Continuous Time)에서의 SDE로 모델링합니다.
- 연속체(Continuum)로의 확장: 노이즈 레벨의 수를 무한대로 늘리면(), 이 과정은 확률 미분 방정식(SDE)으로 묘사되는 확률 과정(Stochastic Process)이 됩니다.
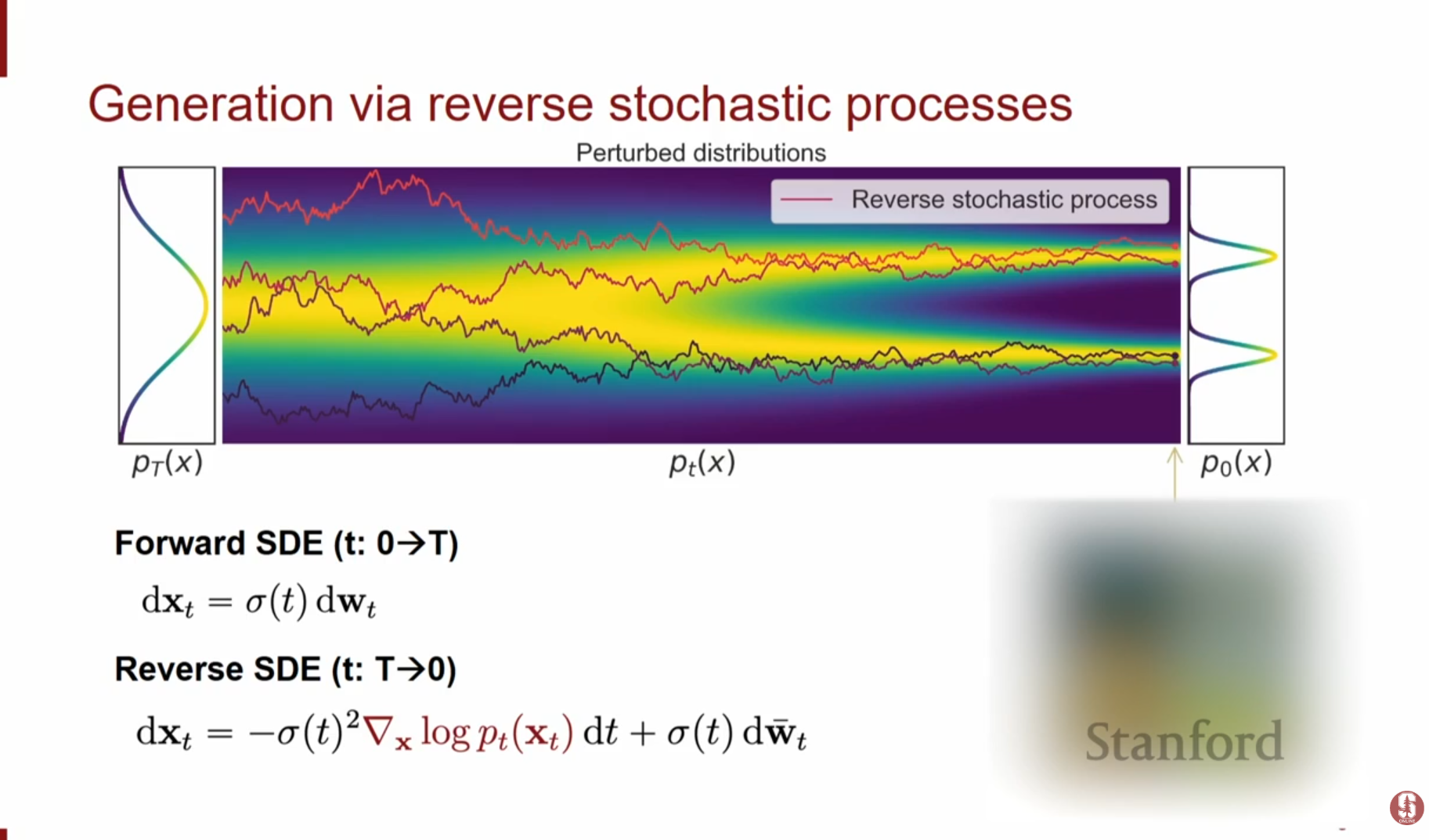
- Forward SDE: 데이터에 노이즈를 더해가는 과정은 다음과 같은 간단한 SDE로 표현됩니다. 여기서 는 아주 작은 시간 동안의 변화량을 의미하며, 이는 무한소의 노이즈()에 의해 주도됩니다.
- 이 과정은 사실상 Random Walk와 같으며, 시간이 지나면 데이터의 구조가 완전히 사라지고 순수한 노이즈만 남게 됩니다.
- Reverse SDE (생성 과정): 시간의 방향을 뒤집어 노이즈에서 데이터로 가는 과정 역시 SDE로 표현할 수 있습니다. 흥미로운 점은 Reverse SDE에는 Drift(드리프트) 항이 추가된다는 것입니다.
- Drift의 역할: Forward 과정은 방향성 없는 Random Walk였지만, Reverse 과정은 데이터를 향해 구조적으로 이동해야 하므로 '속도(Velocity)' 혹은 방향성을 부여하는 Drift 항이 필요합니다.
- 이 Drift 항은 정확히 Score Function()에 해당합니다. 즉, 스코어 함수를 알면 Reverse SDE를 풀어 데이터를 생성할 수 있습니다.

심화 내용: SDE의 의미와 학습
SDE 관점은 이산적인 DDPM을 일반화한 것입니다. DDPM의 샘플링 과정은 이 Reverse SDE를 이산화(Discretization)하여 근사한 것으로 볼 수 있습니다. 학습 시에는 여전히 신경망을 사용해 스코어 함수를 추정하며, 이는 모든 시간 에 대한 연속적인 'Denoising Score Matching'을 수행하는 것과 같습니다.
3. Probability Flow ODE (Ordinary Differential Equation)
SDE와 등가이면서 결정론적(Deterministic)인 과정인 Probability Flow ODE로의 변환에 대해 설명합니다.
- ODE로의 변환: SDE와 동일한 주변 확률 분포(Marginal Distribution)를 가지면서 노이즈를 전혀 더하지 않는 결정론적인 ODE를 정의할 수 있습니다.
- 이 ODE 역시 Score Function에 의해 정의됩니다.
- SDE와 달리 샘플링 과정에서 무작위성이 없으며, 초기 노이즈(Prior)만 샘플링하면 이후 경로는 결정되어 있습니다.
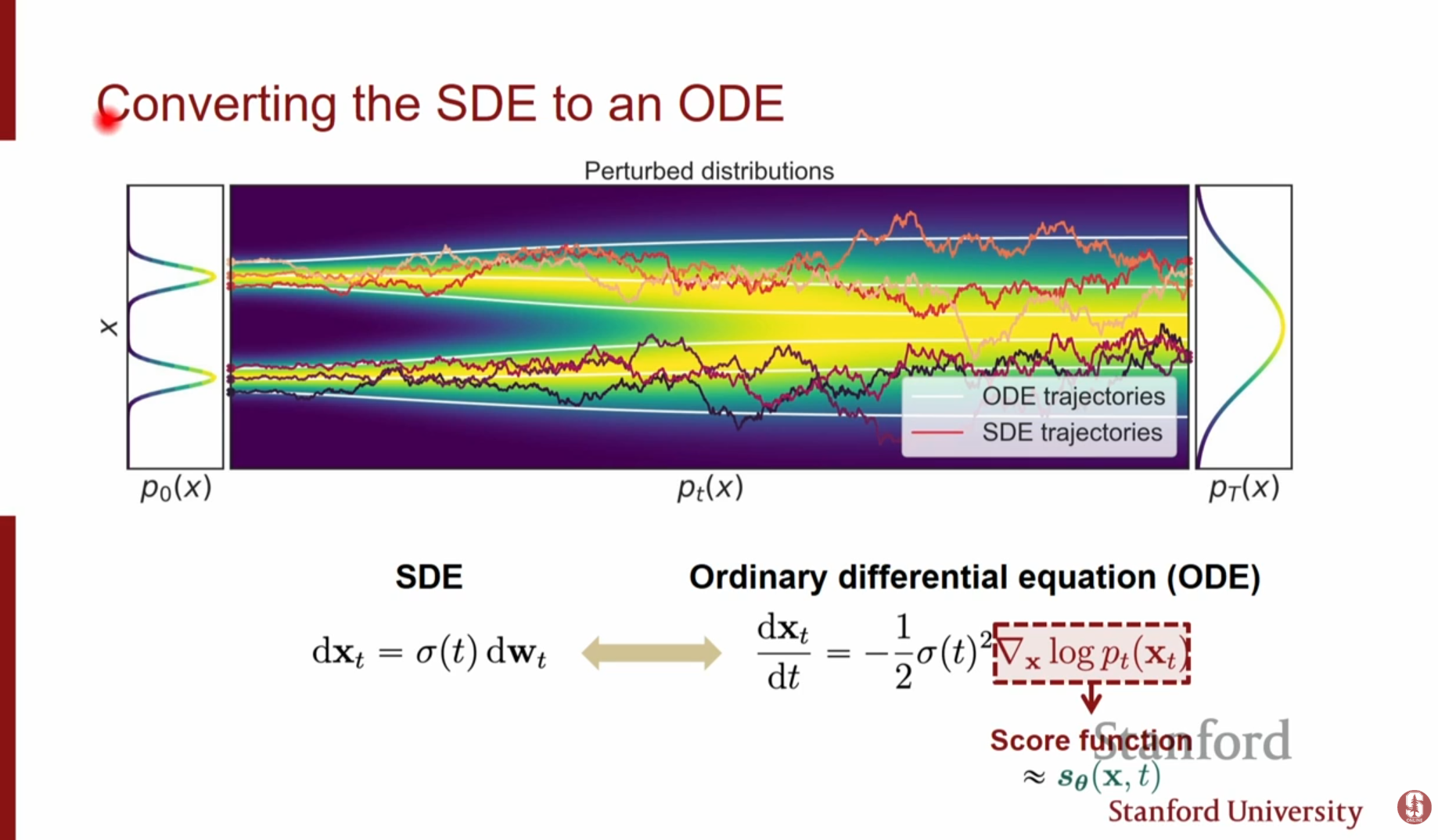
- Continuous Normalizing Flow와의 연결: 이 ODE 관점은 Diffusion Model을 무한히 깊은 Normalizing Flow 모델로 해석하게 해줍니다.
- ODE의 궤적은 서로 교차하지 않기 때문에(Uniqueness), 노이즈 공간과 데이터 공간 사이의 가역적인(Invertible) 매핑이 존재합니다.
- Likelihood 계산 가능: Flow 모델처럼 가역적이므로, 변수 변환(Change of Variable) 공식을 통해 데이터의 정확한 Likelihood(우도)를 계산할 수 있습니다.
- 이를 위해서는 Jacobian의 Trace를 적분해야 하는데, 이는 효율적으로 계산 가능합니다.
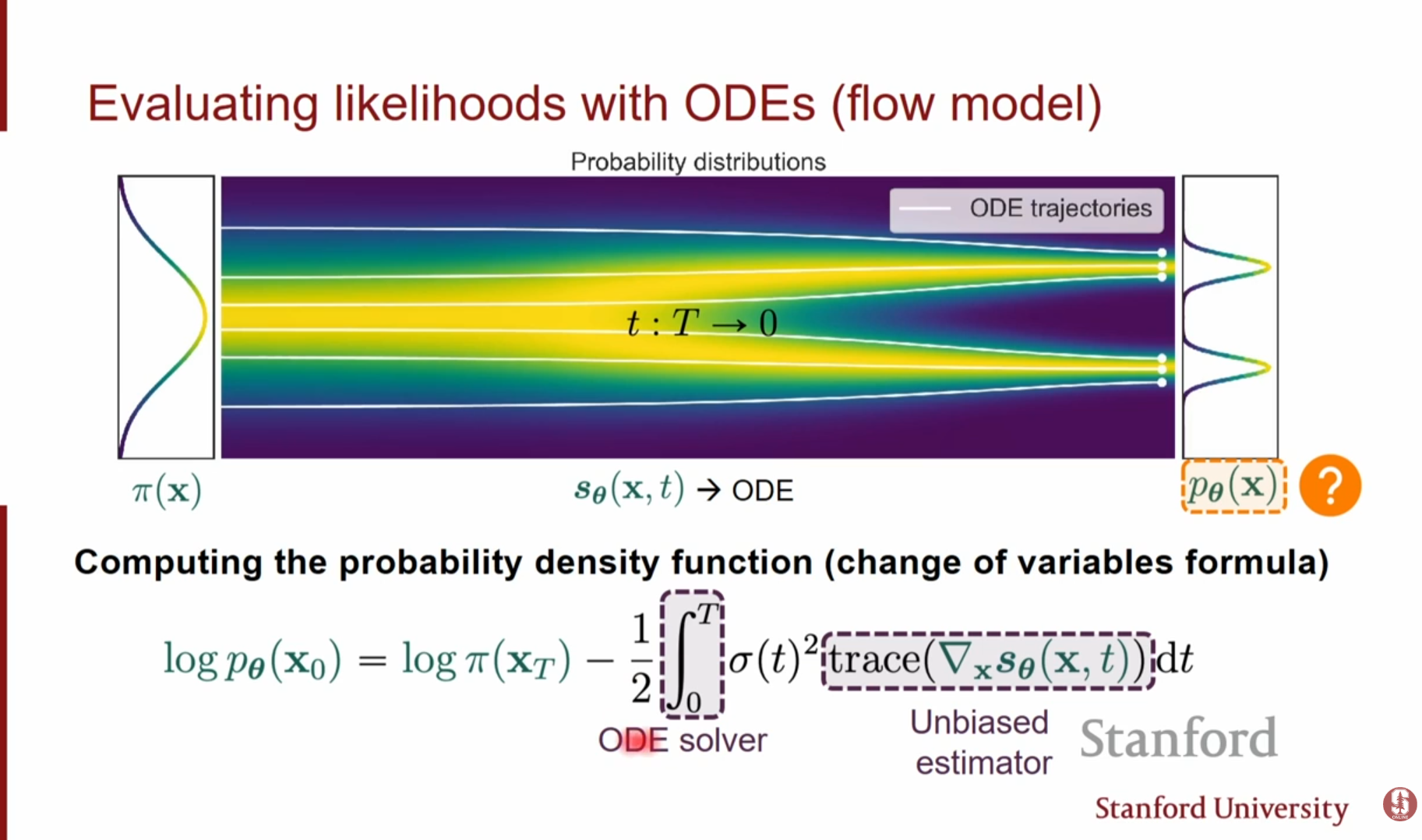
- 이를 위해서는 Jacobian의 Trace를 적분해야 하는데, 이는 효율적으로 계산 가능합니다.
4. 고속 샘플링 기법 (Fast Sampling)
Diffusion Model의 단점인 느린 샘플링 속도를 개선하기 위해, SDE/ODE 관점을 활용한 다양한 방법들이 소개됩니다.
- ODE Solver 활용: ODE 관점을 취하면, 수십 년간 발전해 온 수치해석학의 ODE Solver 기술을 적용할 수 있습니다. 이를 통해 적은 수의 단계(Step)로도 오차를 줄이며 빠르게 샘플링할 수 있습니다.
- DDIM (Denoising Diffusion Implicit Models): 시간을 거칠게 이산화(Coarse Discretization)하여, 1,000 step 대신 약 30 step만으로도 이미지를 생성하는 기법입니다. 큰 보폭(Big Jump)을 취하는 방식이며 실제 널리 사용됩니다.
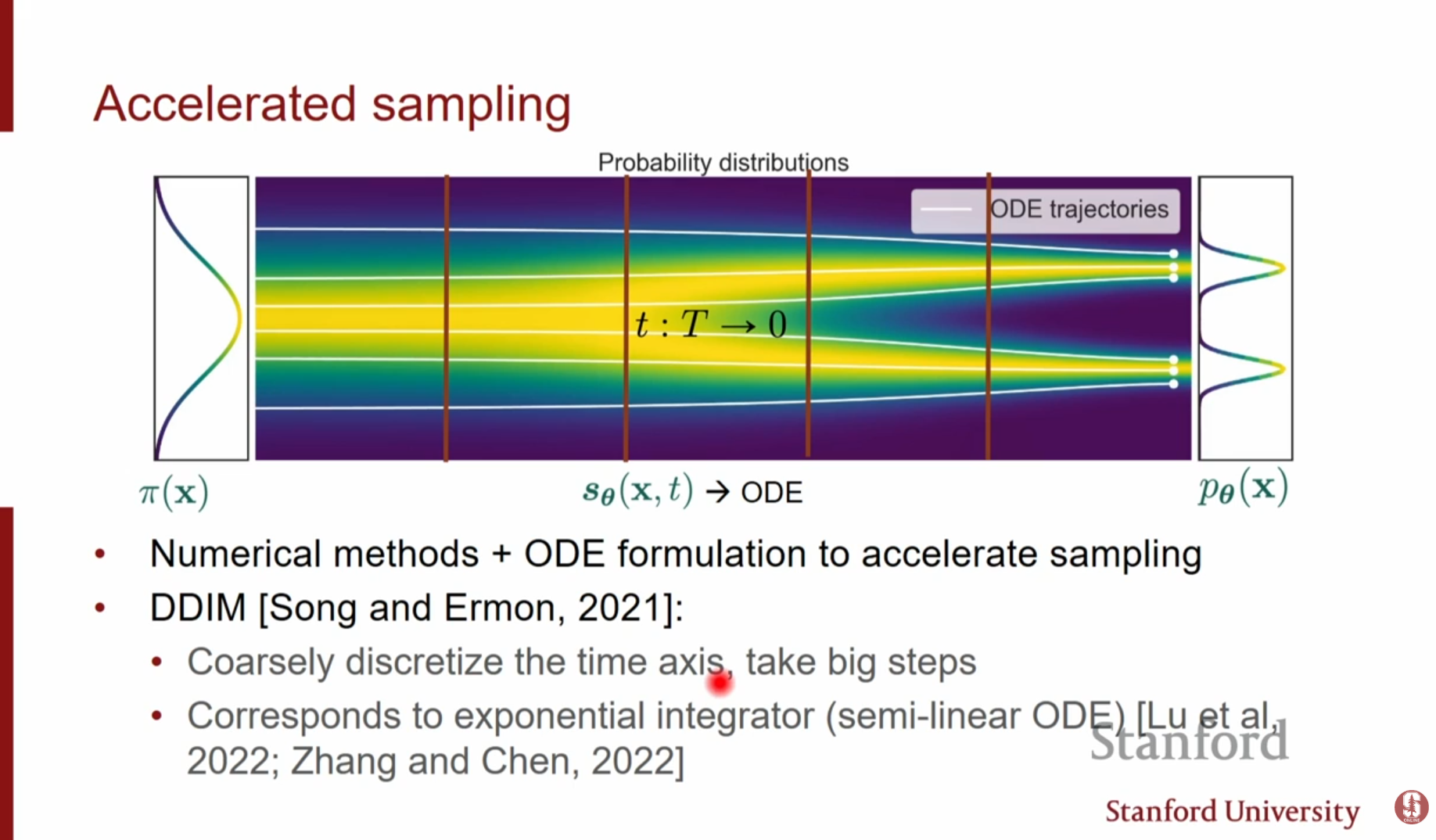
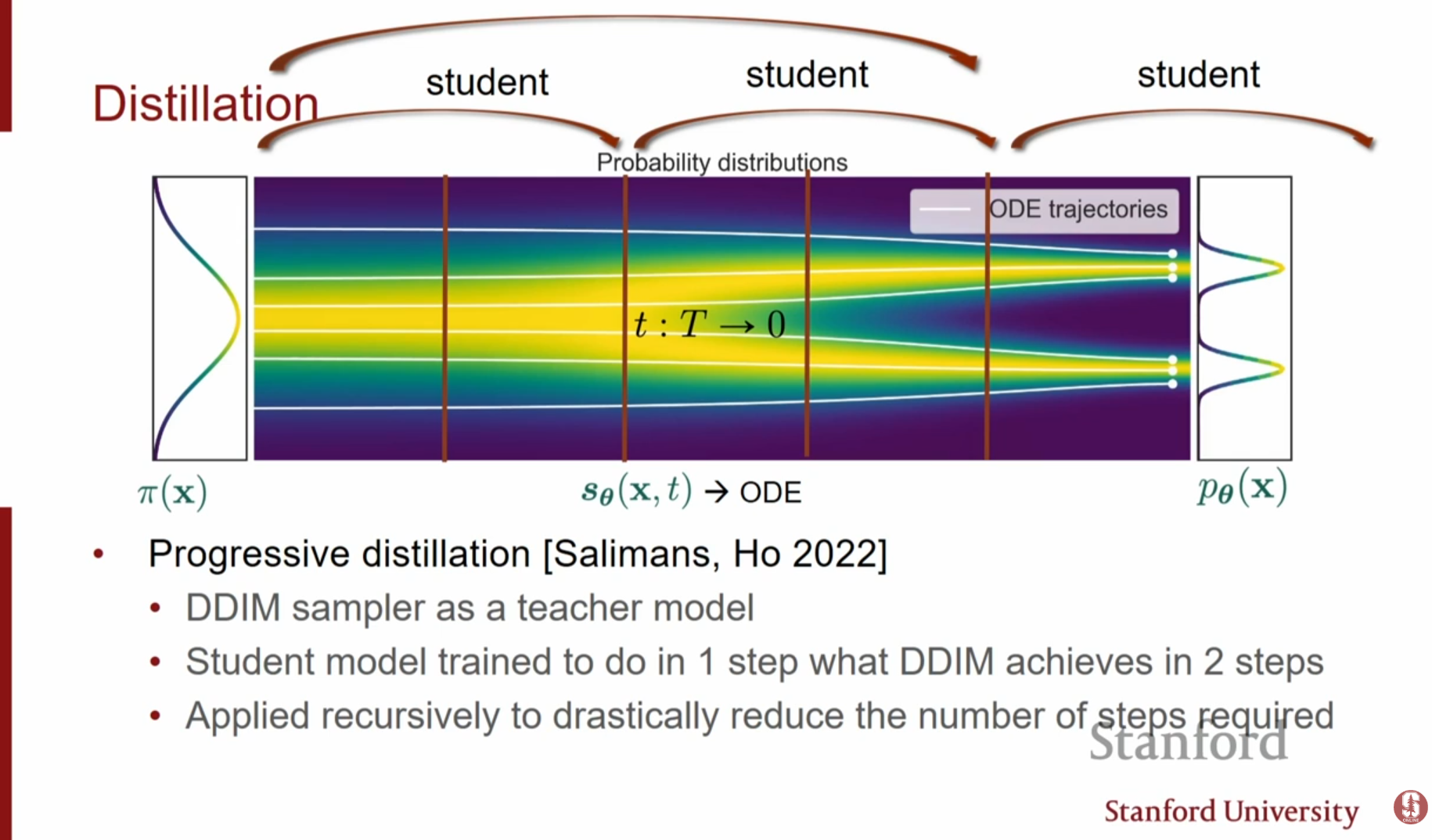
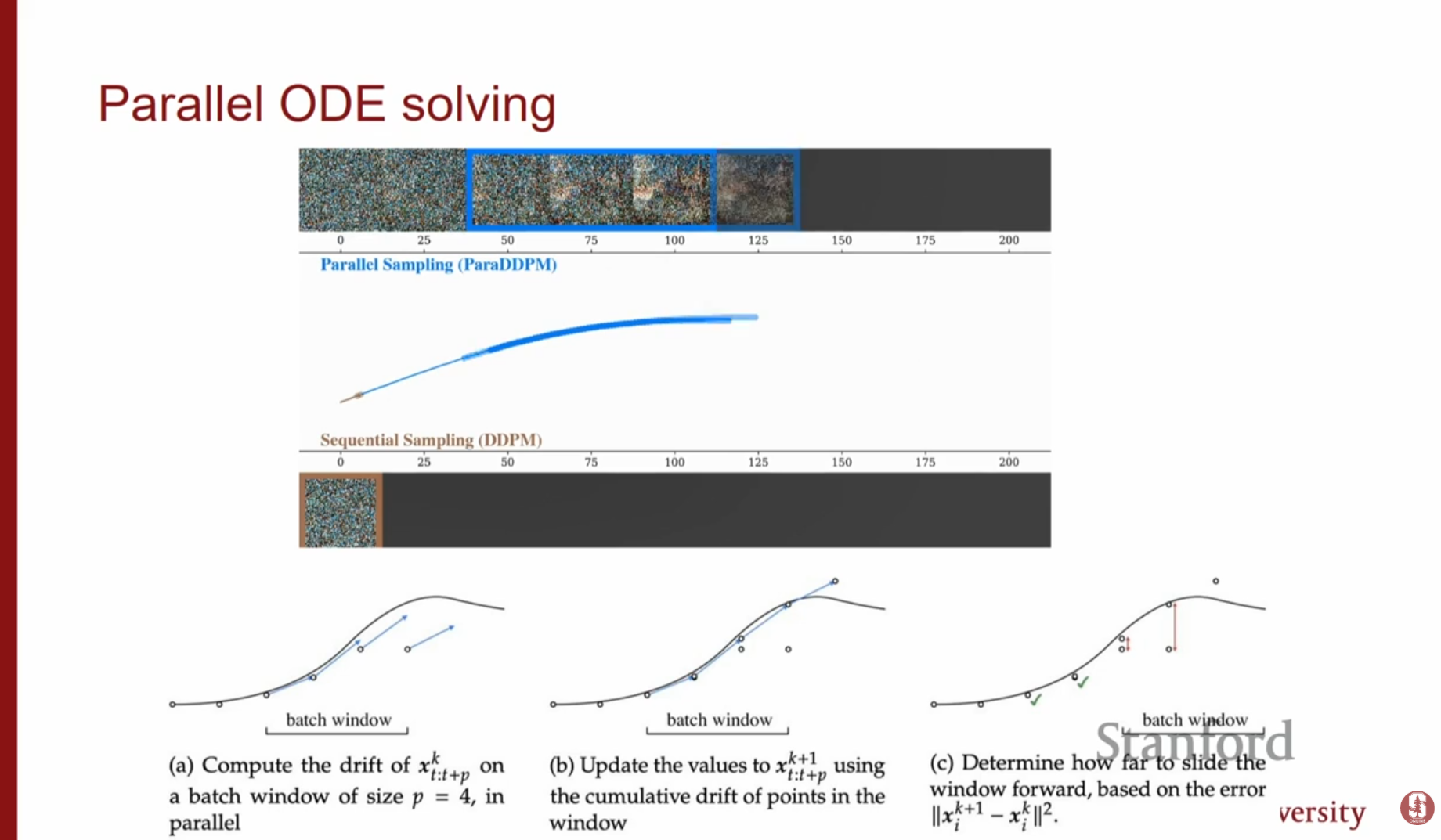
- Parallel Sampling: 여러 GPU를 활용하여 궤적의 전체 구간을 동시에 추정하는 방식입니다. 연산 자원을 더 많이 쓰는 대신, 실제 소요 시간(Wall-clock time)을 줄일 수 있습니다.: 'Teacher' 모델(예: 많은 step을 쓰는 DDIM)의 2 step을 1 step으로 모사하도록 'Student' 모델을 학습시키는 방식입니다. 이를 재귀적으로 반복하여 최종적으로 4~8 step 만에 이미지를 생성할 수 있습니다.
- Consistency Models: 아예 1 step 만에 생성을 시도하거나, 증류 과정을 극한으로 밀어붙여 실시간 생성을 가능하게 하는 모델들입니다.
{kind=link}
심화 내용: SDE vs ODE 샘플링 품질
ODE는 빠르고 효율적이지만, 근사 오차(Approximation Error)가 누적될 때 이를 보정할 방법이 없습니다. 반면 SDE는 매 단계 노이즈를 주입하므로(Langevin Dynamics), 이전 단계의 오차를 바로잡아주는 효과가 있어 더 높은 품질의 샘플을 생성할 수 있습니다. 반대로 ODE는 훈련 데이터 분포에서 벗어난 입력이 들어오면 에러가 증폭될 위험이 있습니다.
5. Latent Diffusion Models (LDM)
Stable Diffusion과 같이 고해상도 이미지를 효율적으로 다루기 위한 Latent Diffusion 전략입니다.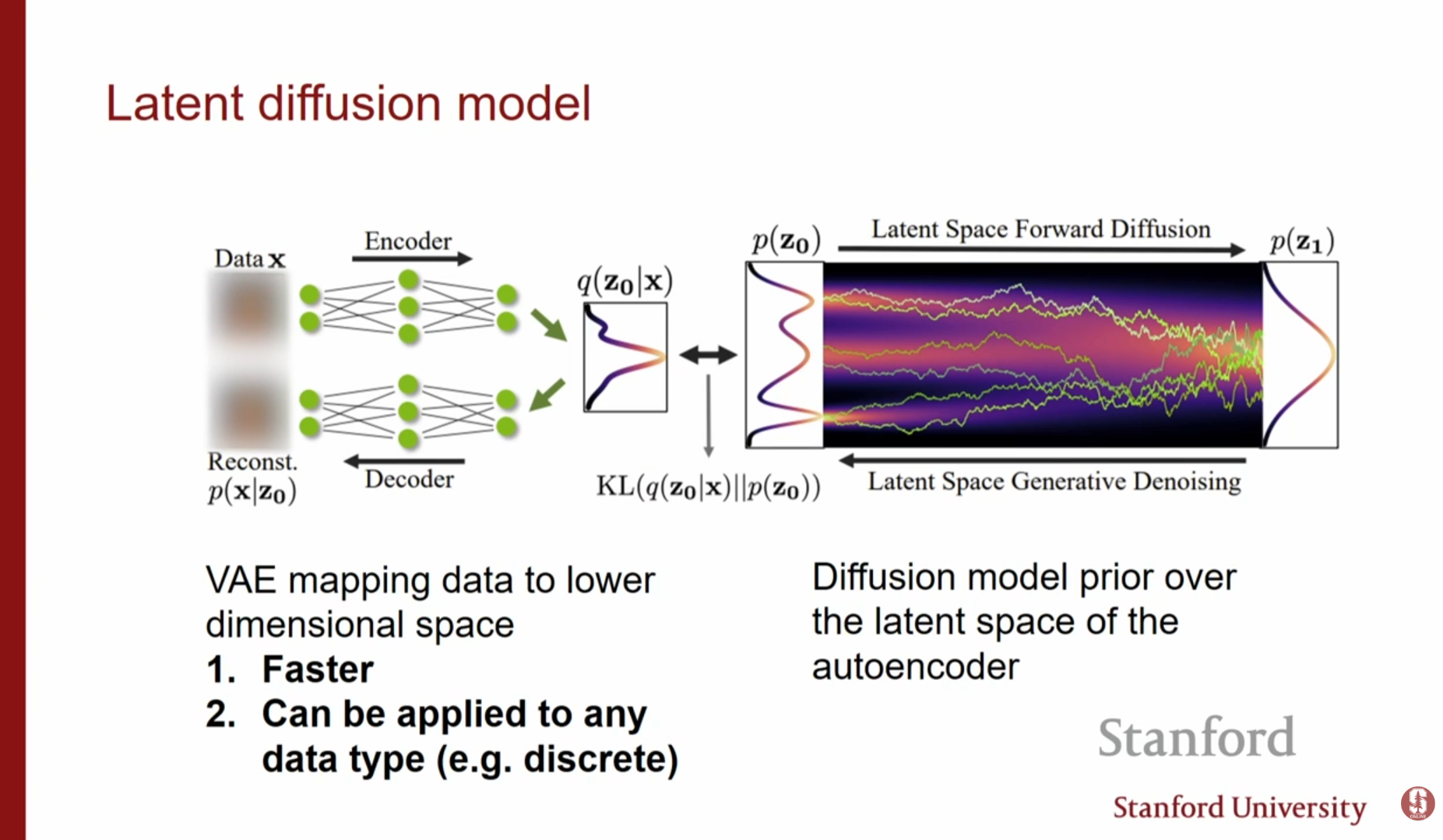
- Pixel Space의 한계: 고차원 픽셀 공간에서 Diffusion을 수행하는 것은 연산 비용이 매우 높습니다.
- 해결책:
- 사전 학습된 오토인코더(Autoencoder)를 사용해 이미지를 저차원 Latent Space로 압축합니다.
- 압축된 Latent Space 상에서 Diffusion Model을 학습합니다.
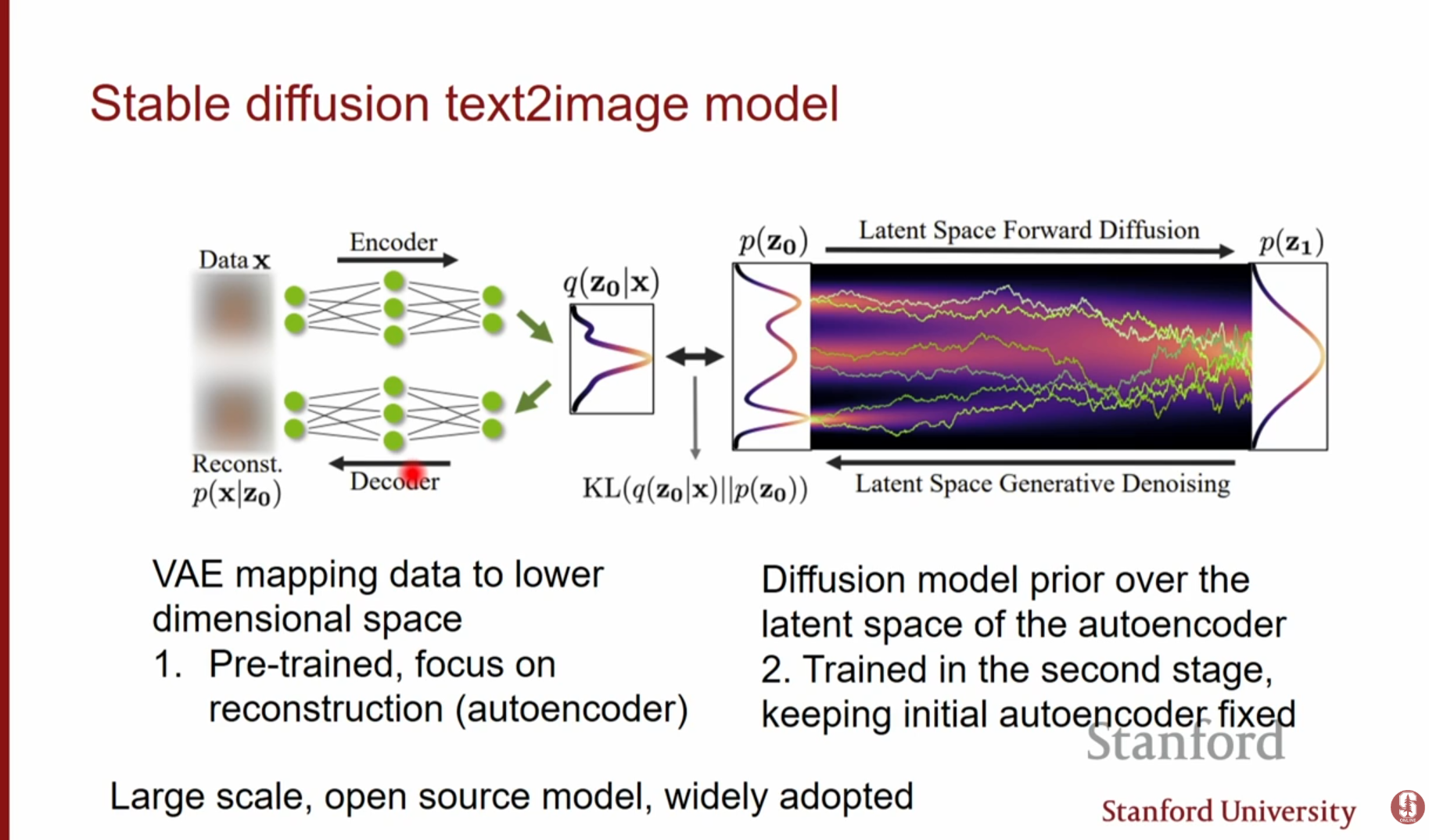
- 장점: 훈련 및 추론 속도가 훨씬 빠르며, 텍스트와 같은 다른 모달리티(Modality)를 조건으로 주기에 유리합니다. Stable Diffusion은 이 방식을 사용하여 대규모 데이터셋(LAION 등)에서 성공적인 결과를 얻었습니다.
6. 조건부 생성과 가이던스 (Conditional Generation & Guidance)
사용자가 원하는 특정 이미지(예: "강아지", 텍스트 캡션 등)를 생성하기 위한 제어 방법입니다.
- 기본적인 조건부 학습: 스코어 네트워크에 시간 , 이미지 와 함께 조건 정보 (예: 캡션)를 추가 입력으로 넣어 를 학습합니다.
- Classifier Guidance:
- 이미 학습된 생성 모델 와 별도의 분류기(Classifier) 를 결합하여 조건부 분포 에서 샘플링하는 방법입니다.
- 베이즈 정리를 이용하면, 사후 확률의 스코어는 (Prior의 스코어) + (Likelihood의 스코어)가 됩니다.
- 즉, 기존 Diffusion Model의 스코어(, 이미지 완성도)에 분류기의 그래디언트(Gradient)(, 특정 이미지화)를 더해줌으로써, 생성 과정(Drift)을 원하는 클래스 방향으로 유도할 수 있습니다.
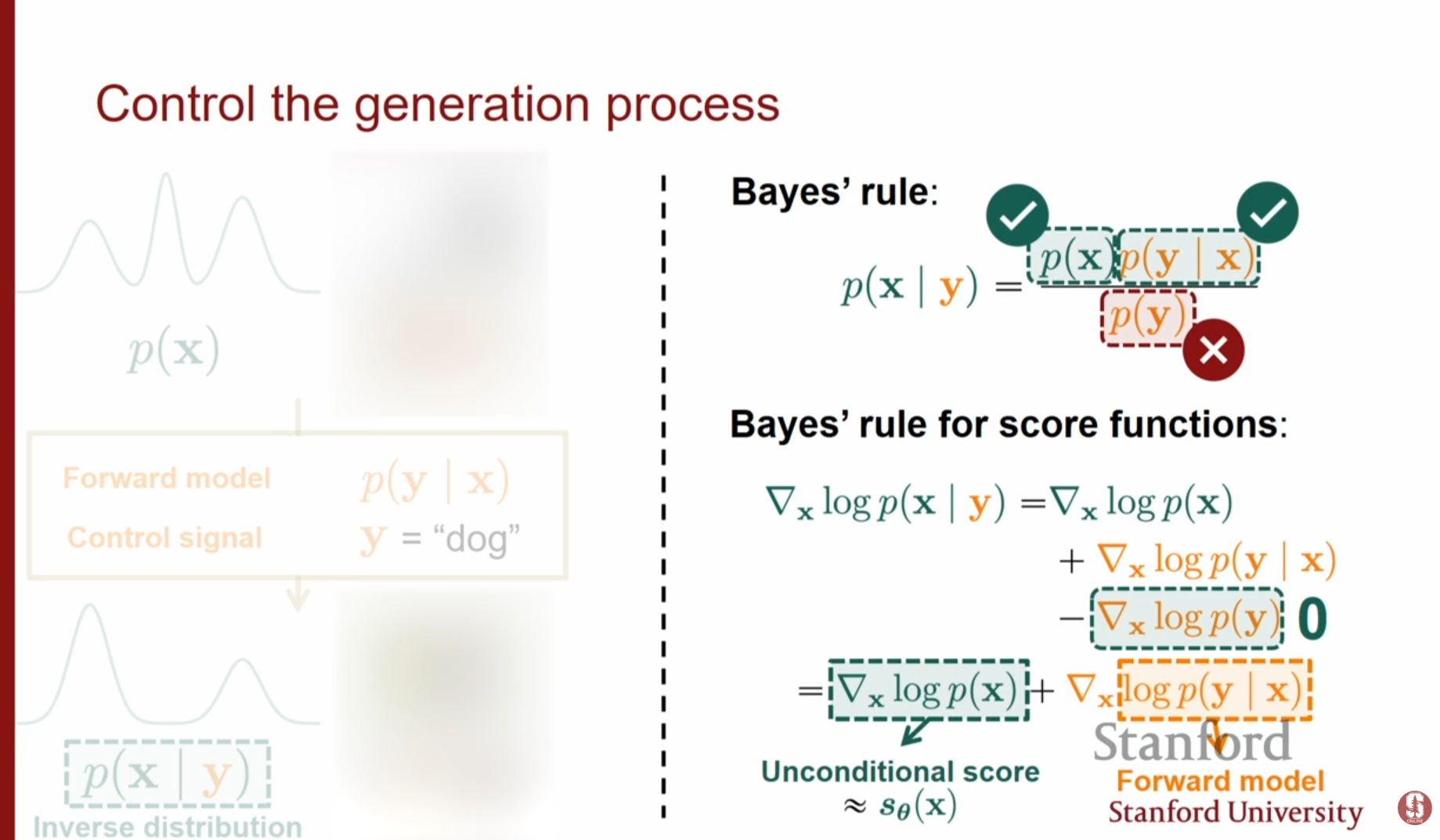
- Classifier-Free Guidance:
- 별도의 분류기를 학습하는 대신, 조건부 모델과 비조건부(Unconditional) 모델 두 가지를 학습(또는 하나의 모델로 두 가지를 수행)합니다.
- 두 모델의 출력 차이를 이용해 암시적으로 분류기 방향을 계산하여 가이던스를 줍니다. 현재 SOTA 모델들에서 널리 쓰이는 방식입니다.

Classifier Guidance vs. Classifier-Free Guidance의 핵심 차이
-
두 방식의 공통된 최종 목표는 모두 조건부 분포 를 따르는 방향으로 샘플링하는 것이다.
-
차이는 이 목표를 달성하기 위해 베이즈 정리의 어느 항을 직접 학습하고 활용하느냐에 있다.
-
Classifier Guidance는 비조건부 생성 모델이 근사한 사전 분포 와,
노이즈가 섞인 이미지 로부터 조건 를 예측하도록 별도로 학습된 분류기 를 사용한다.추론 시에는 베이즈 정리에 따라 조건부 분포의 스코어를 다음과 같이 구성한다.
즉, 생성 모델이 제공하는 이미지의 자연스러움 방향과 분류기가 제공하는 조건 만족 방향을 더해줌으로써 생성 과정을 직접적으로 방향으로 유도한다.
이 방식은 수식적으로 명확하지만, 모든 노이즈 단계에서 안정적으로 동작하는 분류기를 추가로 학습해야 한다는 부담이 있다.
-
반면 Classifier-Free Guidance는 분류기 를 명시적으로 학습하지 않는다.
대신 학습 단계에서 하나의 Diffusion 모델이 조건부 분포 와 비조건부 분포 를 모두 근사하도록 훈련한다.
은 가이던스가 적용된 최종 노이즈 예측값
추론 시에는 두 경우의 출력 차이를 이용해, 조건이 이미지에 미치는 영향을 암시적으로 분리하여 가이던스를 제공한다.
이때 두 모델 출력의 차이는 수학적으로 분류기 그래디언트와 유사한 역할을 하며,
별도의 분류기 없이도 생성 과정을 조건부 분포 를 따르는 방향처럼 동작하도록 만든다.
-
-
정리하면,
Classifier Guidance는 와 를 학습해 베이즈 정리를 직접 적용하는 방식이고,
Classifier-Free Guidance는 와 를 학습해 분류기 항을 우회적으로 구현하는 방식이다.두 방법은 구현과 학습 구조는 다르지만, 모두 사후 분포 의 스코어를 따르도록 생성 과정을 제어한다는 동일한 목표를 공유한다.
강의 중 QnA
Q: ODE와 SDE를 위한 스코어 함수가 따로 존재합니까?
A: 아닙니다. 단 하나의 스코어 함수만 존재합니다. 이 스코어 함수는 '데이터 밀도 + 노이즈'의 스코어이며, 이는 SDE 관점이든 ODE 관점이든 동일한 주변 확률 분포(Marginal)를 가지므로 같습니다. 학습 시에는 동일하게 스코어 매칭으로 학습하고, 추론(Inference) 단계에서 SDE로 풀지 ODE로 풀지 선택하는 것입니다.
Q: 원하는 클래스(예: 강아지)만 생성하려면 어떻게 합니까?
A: 분류기(Classifier)가 있다면 Classifier Guidance를 사용할 수 있습니다. 베이즈 정리를 통해 유도된 수식에 따라, 분류기가 해당 이미지를 '강아지'라고 판단할 확률을 높이는 방향(Gradient)을 기존 생성 과정의 Drift에 더해주면 됩니다. 이것이 수학적으로 올바른 조건부 샘플링 방법입니다.
핵심 내용
- SDE/ODE 통합 프레임워크: Diffusion Model은 무한한 노이즈 단계의 극한에서 SDE로 해석될 수 있으며, 이는 Probability Flow ODE로 변환 가능하여 Normalizing Flow와 같은 결정론적 샘플링 및 Likelihood 계산이 가능합니다.
- 샘플링 효율화: ODE Solver, DDIM, Distillation 등의 기법을 통해 Diffusion Model의 느린 샘플링 속도 문제를 획기적으로 개선할 수 있으며, Latent Space에서 수행함으로써 연산 효율을 더욱 높일 수 있습니다.
- 제어 가능한 생성(Guidance): 스코어 기반 모델의 강력함은 베이즈 정리를 활용해 사후 확률(Posterior)의 스코어를 쉽게 유도할 수 있다는 점입니다. 이를 통해 Classifier Guidance나 Classifier-Free Guidance를 구현하여 텍스트나 레이블 조건에 맞는 이미지를 정교하게 생성할 수 있습니다.
