생성 모델의 기초와 차원의 저주
- 생성 모델(Generative Model)이란 복잡한 데이터셋(이미지, 텍스트 등)의 기본이 되는 확률 분포를 학습하는 모델을 의미합니다.
- 우리가 다루는 데이터 포인트들은 알 수 없는 실제 확률 분포()로부터 샘플링되었다고 가정합니다.
- 생성 모델링의 핵심 목표는 이 알 수 없는 데이터 생성 과정()을 가장 잘 근사하는 모델 분포()를 찾아내는 것입니다.
- 만약 우리가 를 성공적으로 근사한 를 갖게 된다면, 이를 통해 새로운 텍스트나 이미지를 생성할 수 있으며, 특정 데이터가 모델에 의해 생성될 확률이 얼마나 높은지 판단하는 밀도 추정(Density Estimation)도 가능해집니다.
- 이러한 밀도 추정 기능은 이상치 탐지(Anomaly Detection)나 데이터의 공통 구조를 학습하는 비지도 학습(Unsupervised Learning)에서 매우 유용하게 사용됩니다.

- 하지만 고차원 데이터를 다룰 때 가장 먼저 마주하는 난관은 바로 차원의 저주(Curse of Dimensionality)입니다.
- 데이터의 차원(예: 이미지의 픽셀 수)이 증가함에 따라 가능한 상태 공간이 기하급수적으로 늘어나기 때문에, 이를 단순한 방식으로 표현하는 것은 불가능에 가깝습니다.
확률 분포의 표현과 매개변수의 폭발
- 확률 분포를 표현하는 가장 기본적인 단위는 베르누이 분포(Bernoulli Distribution)와 카테고리컬 분포(Categorical Distribution)입니다.
- 베르누이 분포는 동전 던지기와 같이 결과가 두 가지인 경우이며, 단 하나의 매개변수()로 모든 확률을 표현할 수 있습니다.
- 카테고리컬 분포는 개의 결과가 있는 경우로, 개의 매개변수가 필요합니다.
- 이 간단한 요소들을 조합해 이미지를 모델링하려고 하면 문제가 복잡해집니다. 예를 들어, 단 하나의 RGB 픽셀을 표현하기 위해 각 채널이 0~255의 값을 가진다면, 무려 개의 가능한 색상 조합에 대해 각각 확률을 할당해야 합니다.
- 흑백 이미지(개의 픽셀)의 경우, 가능한 이미지의 수는 개에 달하며, 이를 일반적인 테이블 형식으로 표현하려면 개의 매개변수가 필요합니다. 이는 우주의 원자 수보다 많아질 수 있는 수치로, 컴퓨터에 저장하거나 학습하는 것이 물리적으로 불가능합니다.
- 이를 해결하기 위한 가장 극단적인 가정은 모든 변수가 서로 독립(Independent)이라고 가정하는 것입니다.
- 이 경우 매개변수는 개로 획기적으로 줄어들지만, 픽셀 간의 관계를 전혀 고려하지 못하므로 이미지의 구조를 파악하는 데 실패하게 됩니다.
베이지안 네트워크와 조건부 독립
- 확률의 연쇄 법칙(Chain Rule of Probability)을 사용하면 결합 확률 분포를 조건부 확률의 곱으로 분해할 수 있습니다.
- 이 방식은 수학적으로 항상 성립하지만, 뒤로 갈수록 조건부 확률의 매개변수가 여전히 기하급수적으로 많아진다는 단점이 있습니다.
- 이를 효율화하기 위해 마르코프 가정(Markov Assumption)을 도입할 수 있습니다. 예를 들어 "내일의 날씨는 오직 오늘의 날씨에만 의존한다"고 가정하는 방식입니다.

- 베이지안 네트워크(Bayesian Network)는 이러한 아이디어를 일반화한 것으로, 방향성 비순환 그래프(DAG)를 사용하여 변수 간의 종속 관계를 정의합니다.
- 각 노드는 확률 변수를 나타내며, 각 변수는 오직 자신의 부모 노드(Parents)에만 의존합니다.
- 수식:
- 부모 노드의 수가 적을수록 모델은 경제적이며 학습이 용이해집니다.

생성 모델 vs 판별 모델

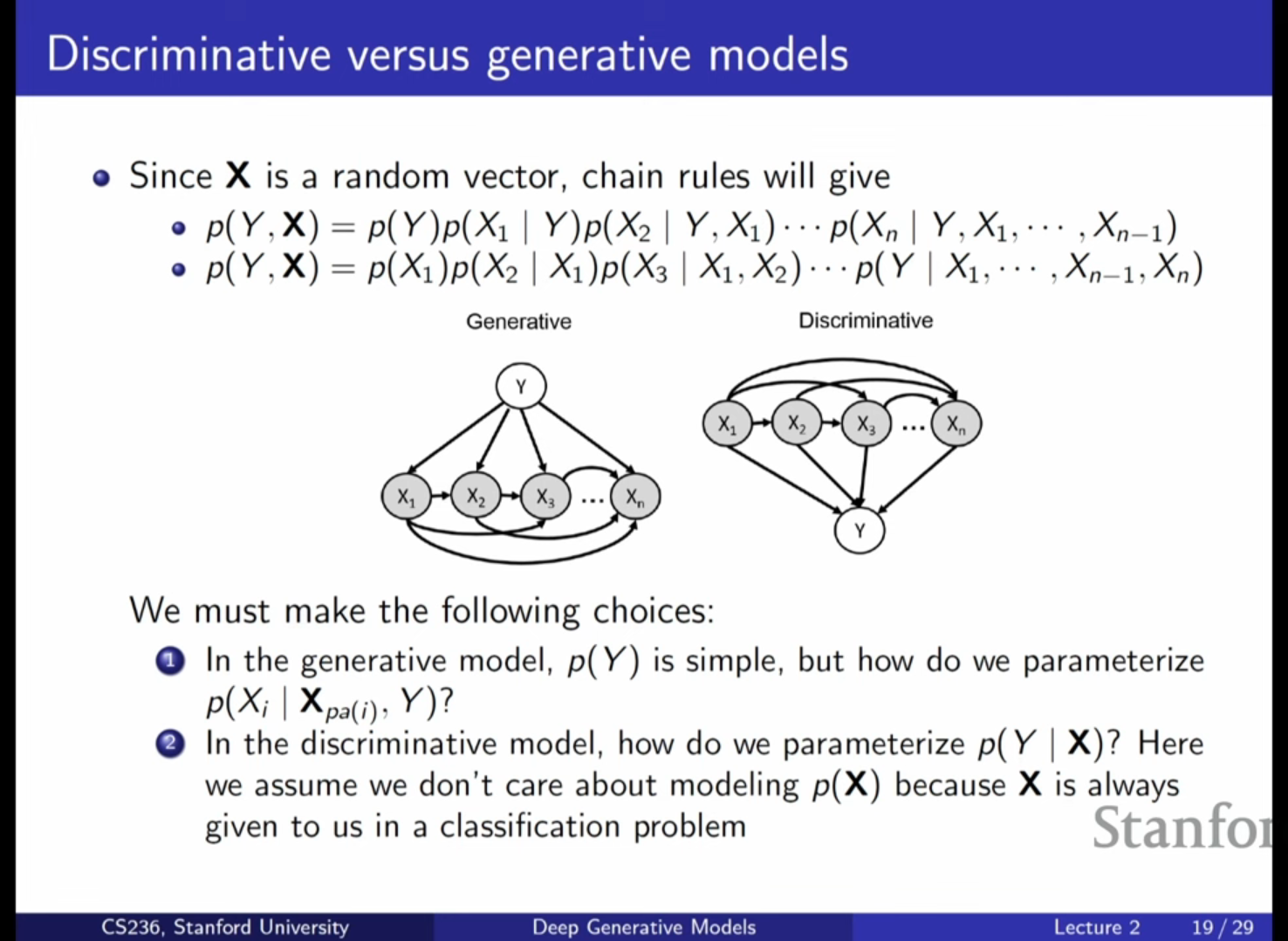
- 판별 모델(Discriminative Model)은 입력 가 주어졌을 때 라벨 가 나타날 조건부 확률인 만을 직접 모델링합니다.
- 이는 특징들() 사이의 관계를 학습할 필요가 없으므로 훨씬 효율적이지만, 입력 데이터 자체에 대해 추론하거나 빠진 데이터를 채워넣는 등의 작업은 불가능합니다.
- 생성 모델(Generative Model)은 즉, 전체 결합 분포를 모델링합니다.
- 이는 입력 데이터의 특징들 사이의 관계까지 모두 파악하므로 훨씬 어려운 문제이지만, 데이터에 대한 깊은 이해를 바탕으로 누락된 값 보정(Imputation) 등 다양한 추론이 가능합니다.
[심화] 나이브 베이즈와 로지스틱 회귀의 관계
- 나이브 베이즈(Naive Bayes)는 대표적인 생성 모델로, 라벨 가 주어졌을 때 모든 특징 들이 서로 독립이라고 가정합니다().
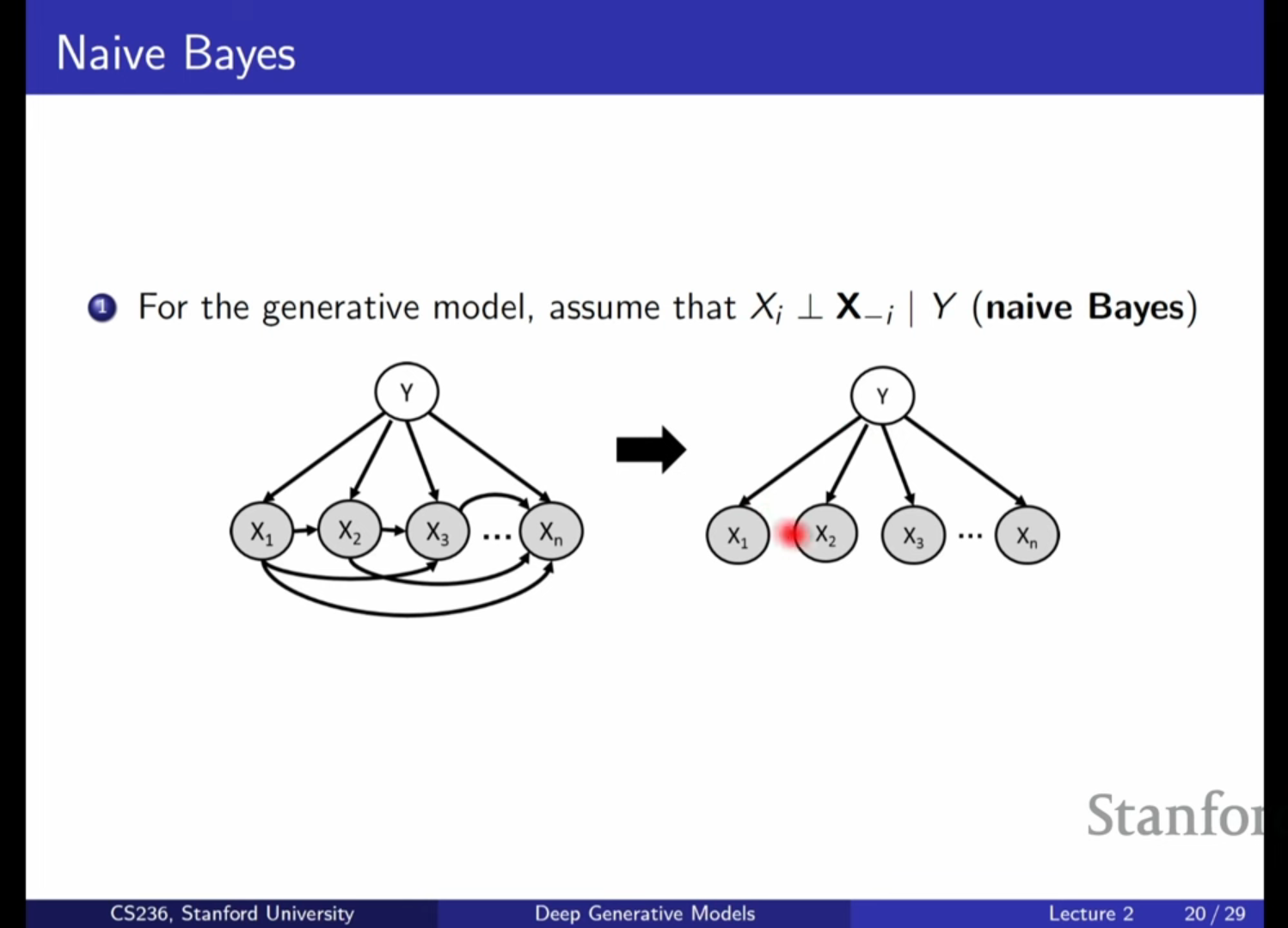
- 반면 로지스틱 회귀(Logistic Regression)는 판별 모델로, 를 선형 결합과 시그모이드 함수로 직접 모델링합니다.

- 나이브 베이즈의 가정이 성립한다면 는 로지스틱 회귀와 동일한 함숫값을 갖게 되지만, 로지스틱 회귀는 특징 간의 독립성을 명시적으로 가정하지 않으므로 데이터가 충분할 때 더 강력한 성능을 보이는 경향이 있습니다.

딥 뉴럴 네트워크를 활용한 생성 모델
- 로지스틱 회귀와 같은 단순한 선형 의존성은 현실의 복잡한 데이터 관계를 담아내기 부족합니다.
- 이를 보완하기 위해 신경망(Neural Networks)을 도입하여 변수 간의 비선형적인 관계를 학습합니다.
- 입력 를 행렬 와 바이어스 를 이용해 변환한 뒤 비선형 활성화 함수를 적용하는 과정을 여러 번 거쳐 매우 복잡한 함수를 근사할 수 있습니다.


- 오토레그레시브 모델(Auto-regressive Model)(예: 대규모 언어 모델, LLM)은 이 신경망을 확률의 연쇄 법칙과 결합한 형태입니다.
- 각 시점의 조건부 확률 를 신경망이 예측하도록 설계하여, 이전 단어들을 바탕으로 다음 단어를 예측하는 구조를 가집니다.
연속형 변수와 심화 생성 모델
- 현실의 데이터는 연속적인 값을 갖는 경우가 많습니다. 이때는 확률 질량 함수 대신 확률 밀도 함수(PDF)를 사용합니다.
- 연속형 변수에서는 테이블 형식을 아예 사용할 수 없으므로, 가우시안 분포(Gaussian Distribution)와 같은 특정 함수 형태를 가정해야 합니다.
- 혼합 가우시안 모델(Mixture of Gaussians, MoG)은 베이지안 네트워크의 구조를 빌려, 이산형 잠재 변수 에 따라 서로 다른 가우시안 분포에서 를 샘플링하는 방식으로 더 유연한 분포를 표현합니다.


[심화] 변분 오토인코더(VAE)의 기술적 배경
- VAE(Variational Autoencoder)는 베이지안 네트워크와 신경망을 결합한 고도의 생성 모델입니다.
- VAE의 생성 과정은 다음과 같습니다:
- 잠재 변수 를 단순한 가우시안 분포에서 샘플링합니다. ()
- 신경망()이 이 를 입력받아 데이터 가 가질 평균과 분산을 계산합니다.
- 계산된 매개변수를 가진 가우시안 분포에서 최종적으로 를 샘플링합니다.
- 이는 복잡한 데이터 분포를 단순한 잠재 공간에서의 변환으로 설명하려는 시도이며, 딥러닝 기반 생성 모델의 핵심적인 축 중 하나입니다.
QnA 내용 요약
Q1: 선형 독립 가정을 하는 것이 베이지안 네트워크에서 X들이 서로 독립이고 결합 분포가 주변 분포의 곱으로 표현된다는 것과 같은 의미인가요?
- A: 나이브 베이즈와 같은 모델에서 조건부 독립 가정을 하면 가 로지스틱 회귀와 같은 특정 함수 형태를 갖게 되지만, 그 역은 반드시 성립하지 않습니다. 로지스틱 회귀는 결합 분포가 주변 분포의 곱이라는 강한 가정을 하지 않기 때문에 나이브 베이즈보다 더 약한 가정을 사용하는 셈이며, 실무에서 더 강력한 성능을 발휘하는 이유이기도 합니다.
Q2: 연쇄 법칙에서 마지막 항이 반드시 이어야 하나요?
- A: 마르코프 모델이라면 그렇겠지만, 일반적인 경우에는 신경망의 구조에 따라 달라집니다. 어떤 모델은 를 예측할 때 에만 의존한다고 가정할 수도 있고(비록 이상한 가정이겠지만), 연쇄 법칙을 단순화하기 위해 특정 변수들에 대한 의존성을 제거함으로써 다양한 그래프 구조의 베이지안 네트워크를 만들 수 있습니다.
Q3: 신경망 모델에서 왜 여전히 알파()와 같은 최종 매개변수가 필요한가요?
- A: 신경망이 아무리 깊어도 마지막에는 출력값을 단일 스칼라(확률값)로 매핑해야 하기 때문입니다. 이 과정은 다차원 벡터를 최종 확률로 변환하는 소프트맥스(Softmax) 함수의 역할과 유사하며, 모델을 일반화된 형태로 유지하기 위해 명시적으로 표현된 것입니다.

AI 공부합니다