생성 모델과 자기회귀 모델(Autoregressive Models)의 이해
생성 모델을 학습시키기 위해서는 데이터(IID 샘플)와 모델 패밀리, 그리고 데이터 분포와 모델 분포 사이의 유사성 또는 발산(Divergence)을 정의하는 과정이 필요합니다. 자기회귀 모델(Autoregressive Models)은 이러한 생성 모델의 한 종류로, 체인 룰(Chain Rule)을 사용하여 확률 분포를 표현하는 방식이며 ChatGPT와 같은 대규모 언어 모델(LLM)의 핵심 기술입니다.
- 생성 모델의 목적: 모델 분포를 데이터 분포에 최대한 가깝게 최적화하여 새로운 데이터를 생성하거나(Sampling), 데이터의 확률을 평가(Likelihood evaluation)하여 이상치 탐지(Anomaly detection) 및 비지도 표현 학습(Unsupervised representation learning)에 활용합니다.
- 확률 분포의 표현: 신경망을 사용하여 확률 분포의 매개변수()를 정의하며, 신경망이 충분히 깊다면 복잡한 조건부 확률도 효과적으로 근사할 수 있습니다.
1. 체인 룰(Chain Rule)과 모델 구조
모든 확률 분포는 변수의 순서와 상관없이 조건부 확률의 곱으로 분해될 수 있습니다.
- 수학적 정의: 개의 변수가 있을 때, 와 같이 표현됩니다.
- 순서(Ordering)의 중요성: 체인 룰은 어떤 순서로도 작동하지만, 데이터의 인과 구조에 맞는 적절한 순서를 선택하는 것이 모델링의 효율성에 영향을 줄 수 있습니다.
- 신경망 모델의 장점: 기존의 베이지안 네트워크(Bayesian Network)가 조건부 확률 테이블을 사용하여 확장이 어려웠던 반면, 신경망 모델은 이전 변수들의 할당값을 매개변수로 매핑하는 함수를 학습하여 더욱 유연하게 구조를 캡처합니다.
2. Fully Visible Sigmoid Belief Network (FVSBN)
가장 단순한 형태의 자기회귀 모델 중 하나로, 로지스틱 회귀를 사용하여 다음 픽셀을 예측하는 방식입니다.
- 구조: 이미지의 경우 래스터 스캔(Top-left to bottom-right) 순서를 주로 사용하며, 각 픽셀 는 이전의 모든 픽셀들에 의존합니다.
- 수학적 수식:
- 여기서 는 시그모이드(Sigmoid) 함수로, 선형 결합의 결과를 0과 1 사이의 확률값으로 변환합니다.
- 한계: 로지스틱 회귀는 픽셀 간의 복잡한 의존성을 캡처하기에는 충분히 강력하지 않아 생성된 이미지가 다소 흐릿한(Blob) 형태를 띠는 경향이 있습니다.


3. Neural Autoregressive Density Estimation (NADE)
FVSBN의 성능을 개선하기 위해 단일 계층 신경망을 도입한 모델입니다.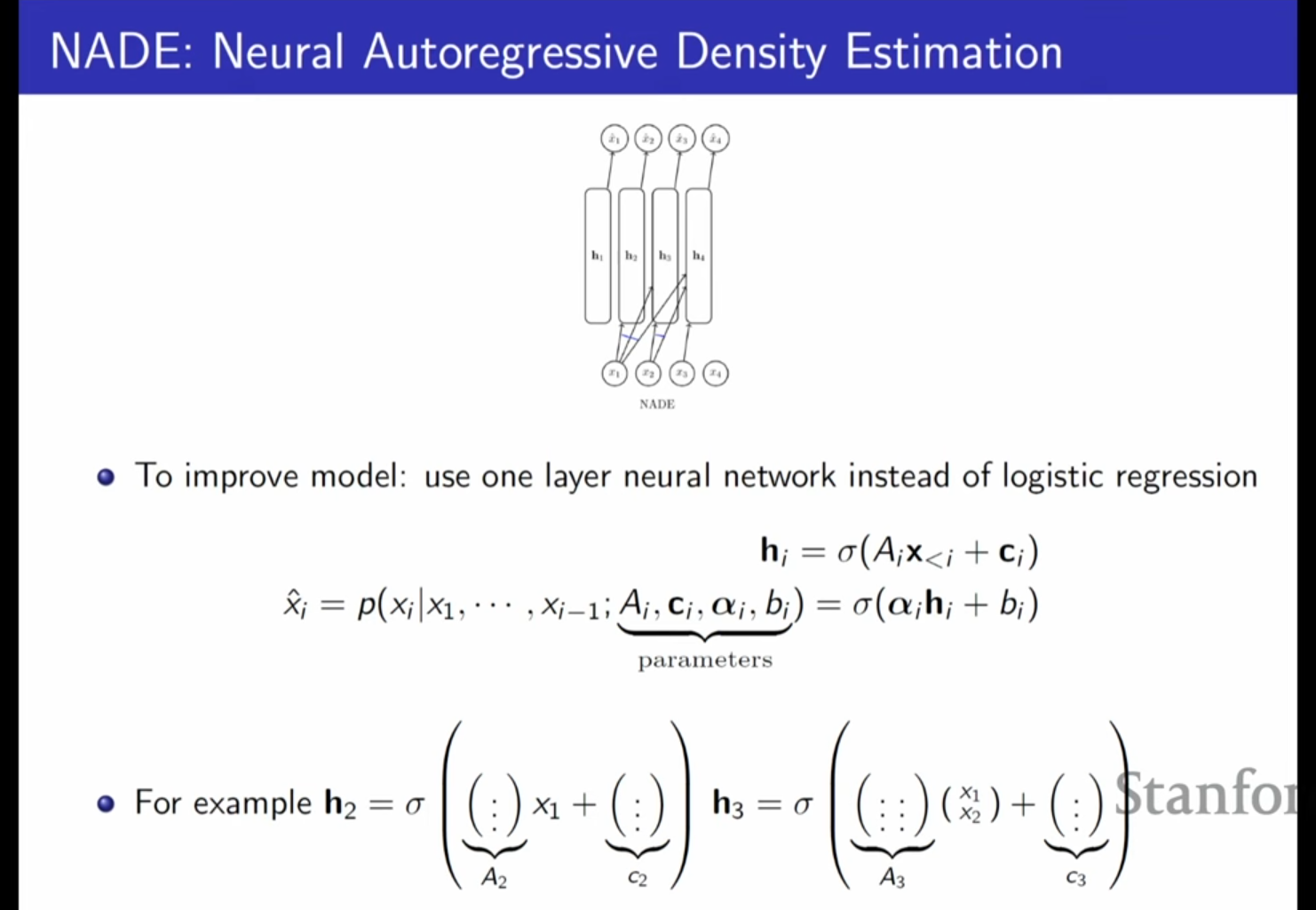
- 심화 내용 - 기술적 배경 및 혁신: NADE는 각 변수 예측을 위해 별도의 신경망을 학습시키는 대신 가중치 공유(Weight Tying) 기법을 사용합니다.
- 가중치 공유의 이점: 매개변수 수를 에서 으로 줄여 과적합을 방지하고 계산 속도를 높입니다.
- 또한, 이전 단계에서 계산된 점곱(Dot product) 결과를 재사용하여 확률 평가를 더 효율적으로 수행할 수 있습니다.

- 수학적 수식:
- 데이터 확장:
- 이산 데이터(Categorical): 소프트맥스(Softmax) 레이어를 사용하여 여러 범주에 대한 확률 분포를 출력합니다.

- 연속 데이터(Continuous): 가우시안 혼합 모델(Mixture of Gaussians)의 매개변수(평균, 표준편차)를 신경망의 출력으로 사용하여 복잡한 밀도 함수를 근사합니다.

- 이산 데이터(Categorical): 소프트맥스(Softmax) 레이어를 사용하여 여러 범주에 대한 확률 분포를 출력합니다.

4. Masked Autoencoder for Distribution Estimation (MADE)
오토인코더(Autoencoder) 구조에 자기회귀 속성을 부여하기 위해 고안된 모델입니다.


- 핵심 개념: 일반적인 오토인코더는 모든 입력이 모든 출력에 영향을 주어 자기회귀 조건(이전 변수만 참조)을 만족하지 못합니다. 이를 해결하기 위해 신경망의 연결망에 마스킹(Masking)을 적용합니다.
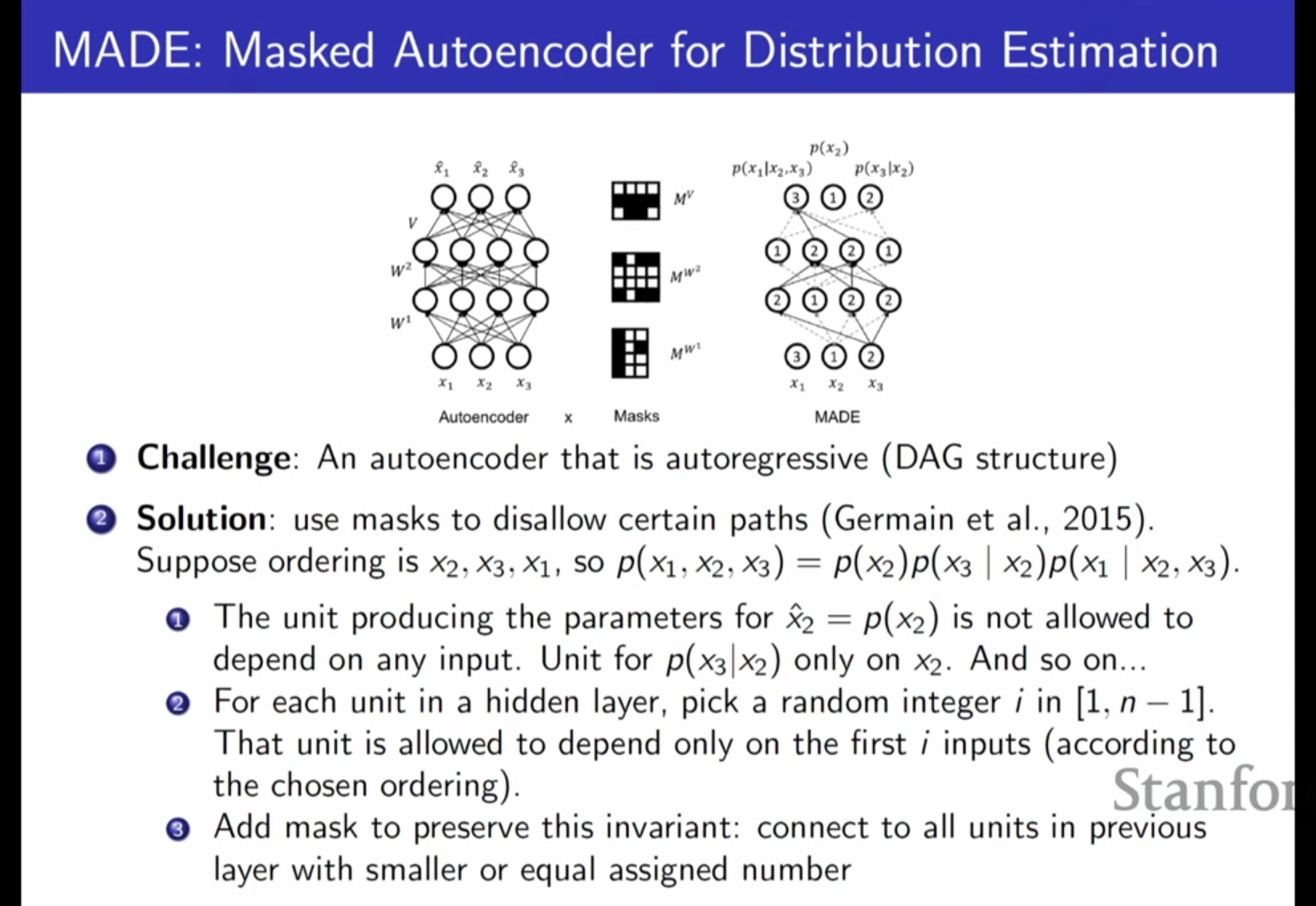
- 마스킹 규칙: 각 은닉 유닛에 번호를 부여하고, 해당 유닛이 이전 레이어에서 자신보다 낮거나 같은 번호를 가진 유닛으로부터만 입력을 받도록 제한하여 체인 룰에 따른 의존성을 강제합니다.
- 장점: 단 한 번의 순전파(Forward pass)로 모든 조건부 확률 매개변수를 얻을 수 있어 훈련 시 매우 효율적입니다.
5. 순환 신경망(RNN) 기반 자기회귀 모델
시퀀스 데이터의 이력을 요약하여 전달하는 방식입니다.
- 메커니즘: 은닉 상태(Hidden State) 를 사용하여 과거의 모든 정보를 요약하고 이를 재귀적으로 업데이트합니다.
- .

- .
- 심화 내용 - 최신 동향 및 한계점:
- 장점: 고정된 수의 매개변수로 임의의 길이를 가진 시퀀스를 처리할 수 있습니다,. Shakespeare 텍스트나 위키피디아 마크업 형식을 학습할 정도로 강력한 성능을 보여줍니다.
- 한계: 모든 과거 정보를 단일 벡터()에 압축해야 하는 정보의 병목 현상이 발생합니다. 또한, 훈련 시 시퀀스를 순차적으로 풀어야 하므로 GPU의 병렬 연산 기능을 활용하기 어려워 속도가 매우 느리다는 치명적인 단점이 있습니다.

QnA (질의응답)
- Q: NADE에서 은닉층 계산 시 시그모이드를 반드시 사용해야 하나요?
- A: 반드시 시그모이드일 필요는 없으며 ReLU 등 다른 비선형 활성화 함수를 사용할 수 있습니다. 예시에서는 설명을 위해 시그모이드를 사용했습니다.
- Q: 가중치 공유가 성능에 어떤 영향을 미치나요?
- A: 매개변수 수를 줄여 과적합(Overfitting)을 방지하고 일반화 성능을 높이는 데 기여하며, 계산 속도를 향상시킵니다.
- Q: 오토인코더에서 샘플링이 가능한가요?
- A: 일반적인 오토인코더는 생성 모델이 아니므로 샘플링이 어렵습니다. 하지만 MADE처럼 마스킹을 통해 구조를 변경하거나 VAE(Variational Autoencoder)와 같은 방식을 사용하면 샘플링이 가능해집니다.
- Q: MADE의 마스킹이 훈련과 추론 중 언제 적용되나요?
- A: 훈련 단계에서 마스킹된 아키텍처를 설정하여 모델이 미래의 데이터를 "컨닝"하지 못하도록 강제합니다. 단, 추론(샘플링) 시에는 여전히 순차적인 과정을 거쳐야 합니다.
- Q: RNN 기반 모델은 마르코프 가정을 따르나요?
- A: 아닙니다. 은닉 상태를 통해 과거의 모든 정보를 전달하려 하기 때문에 단순히 직전 상태에만 의존하는 마르코프 가정과는 다릅니다.
💡 비유로 이해하기: 자기회귀 모델은 마치 '릴레이 소설 쓰기'와 같습니다. 앞사람들이 쓴 내용을 모두 읽고(조건부 확률), 그 문맥에 가장 어울리는 다음 단어를 하나씩 이어 붙여(Sequential Sampling) 전체 이야기를 완성해 나가는 과정이기 때문입니다.

AI 공부합니다