1. 자기회귀 모델(Auto-regressive Models)의 발전과 한계
- RNN 기반 자기회귀 모델의 특징: 지난 시간에 다룬 RNN은 시퀀스의 길이에 상관없이 고정된 수의 파라미터를 사용하여 이전의 문맥(Context)을 추적합니다. RNN은 이전까지 본 정보를 하나의 은닉 벡터(Hidden Vector, )에 요약하여 다음 토큰이나 픽셀을 예측하는 데 사용합니다.
- RNN의 주요 문제점:
- 정보 병목: 단 하나의 은닉 벡터가 이전의 모든 정보를 요약해야 하므로, 시퀀스가 길어질수록 전체 의미를 담아내기 어렵습니다.
- 학습 속도 저하: 확률 계산과 손실 함수 산출을 위해 계산 과정을 'Unroll(풀기)'해야 하므로 학습이 매우 느립니다.
- 그래디언트 문제: 장기 의존성(Long dependencies)으로 인해 그래디언트 폭주(Exploding) 또는 소실(Vanishing) 문제가 발생하기 쉽습니다.
2. 어텐션(Attention)과 트랜스포머(Transformer)
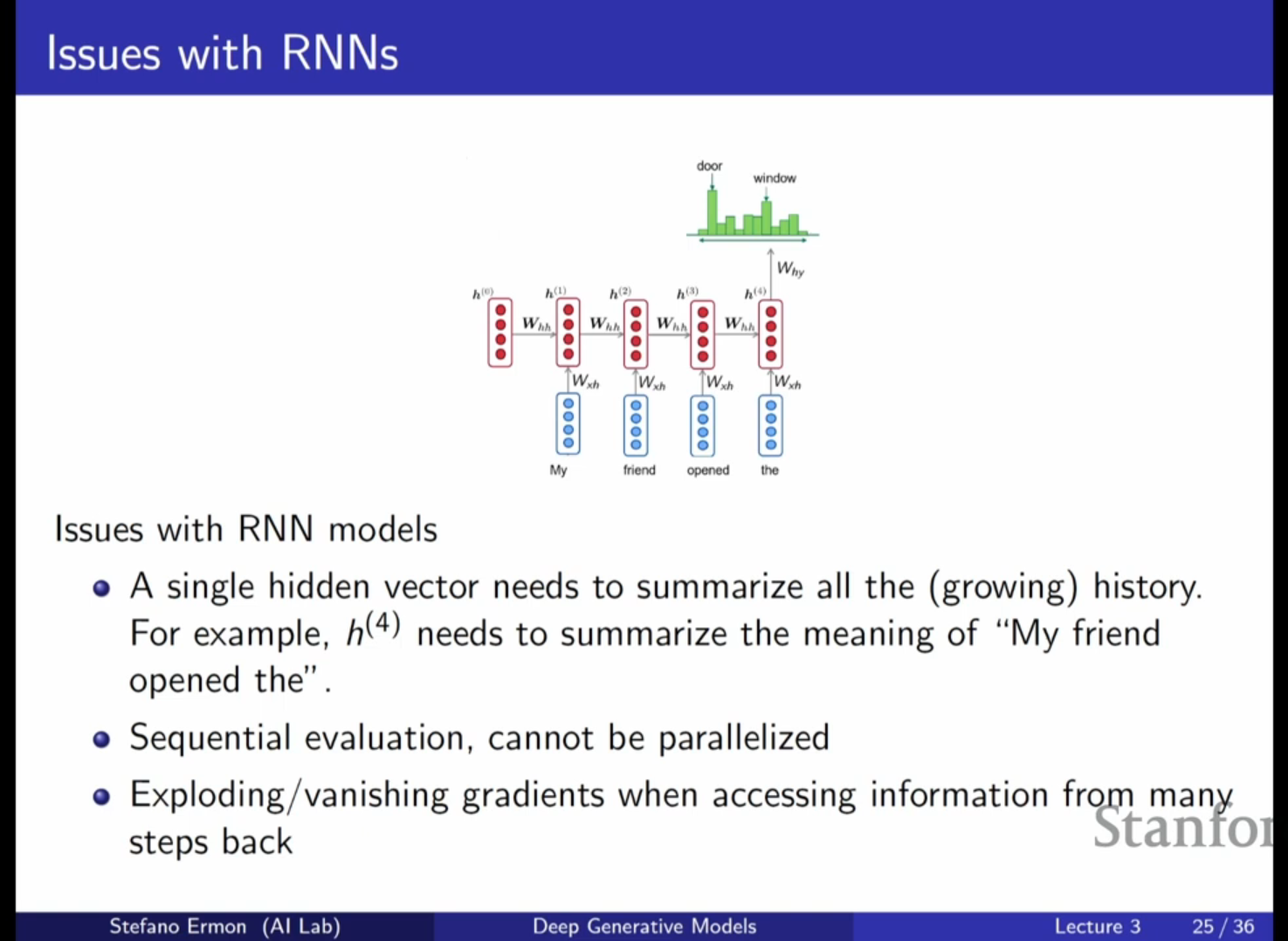
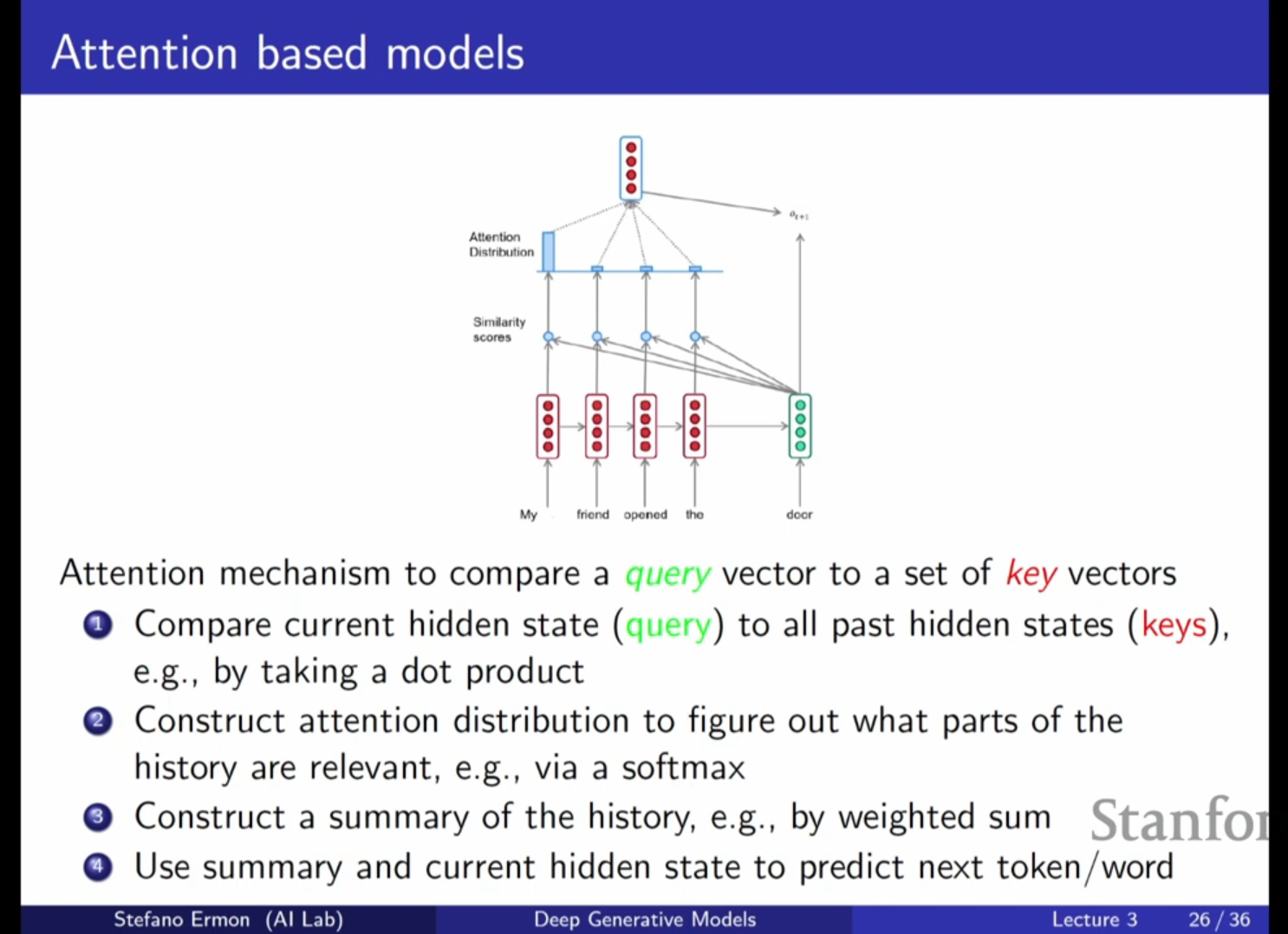
- 핵심 아이디어: 현대의 상태 최첨단(State-of-the-art) 모델들은 RNN 대신 어텐션(Attention) 메커니즘을 사용합니다. 이는 마지막 시점의 은닉 벡터만 사용하는 것이 아니라, 예측 시점에서 이전의 모든 은닉 벡터를 살펴보고 어떤 부분이 중요한지 결정하는 방식입니다.
- 어텐션 메커니즘의 작동:
- 데이터베이스 검색과 유사하게 쿼리(Query) 벡터와 키(Key) 벡터 간의 관련성을 계산합니다.
- 두 벡터 사이의 내적(Dot product) 등을 통해 유사도를 구하고, 이를 소프트맥스(Softmax) 함수에 통과시켜 어텐션 분포(Attention distribution)를 생성합니다.
- 트랜스포머의 장점:
- 병렬화(Parallelism): RNN과 달리 학습 시 모든 인덱스에 대해 병렬로 계산이 가능하여 GPU를 활용한 대규모 확장이 가능합니다.
- 장기 의존성 해결: 전체 히스토리를 직접 참조하므로 병목 현상이 없으며, 'it'과 같은 대명사가 무엇을 지칭하는지 등을 파악하는 데 매우 강력합니다.
- 심화 내용 - GPT와 LLM: GPT-2, 3, 4 및 Llama와 같은 거대 언어 모델(LLM)은 기본적으로 이 자기회귀 구조와 셀프 어텐션(Self-attention) 메커니즘을 기반으로 합니다. 이러한 모델들은 막대한 병렬 계산 능력을 통해 대규모 데이터셋에서 학습되어 뛰어난 성능을 보여주지만, 추론 시에는 여전히 시퀀스를 하나씩 생성해야 하는 순차적 특성을 가집니다.

3. 이미지 데이터로의 확장: PixelRNN과 PixelCNN
- 이미지의 자기회귀 모델링: 이미지를 픽셀의 시퀀스로 간주하여 왼쪽 상단에서 오른쪽 하단 방향으로 하나씩 생성할 수 있습니다.
- RGB 채널 처리: 각 픽셀 내에서도 빨강(R) → 초록(G) → 파랑(B) 순서로 의존성을 설정하여 조건부 확률을 정의합니다.
- PixelRNN: 픽셀 수준에서 RNN을 사용하여 이미지의 의존성을 캡처하지만, 계산이 매우 느리다는 단점이 있습니다.


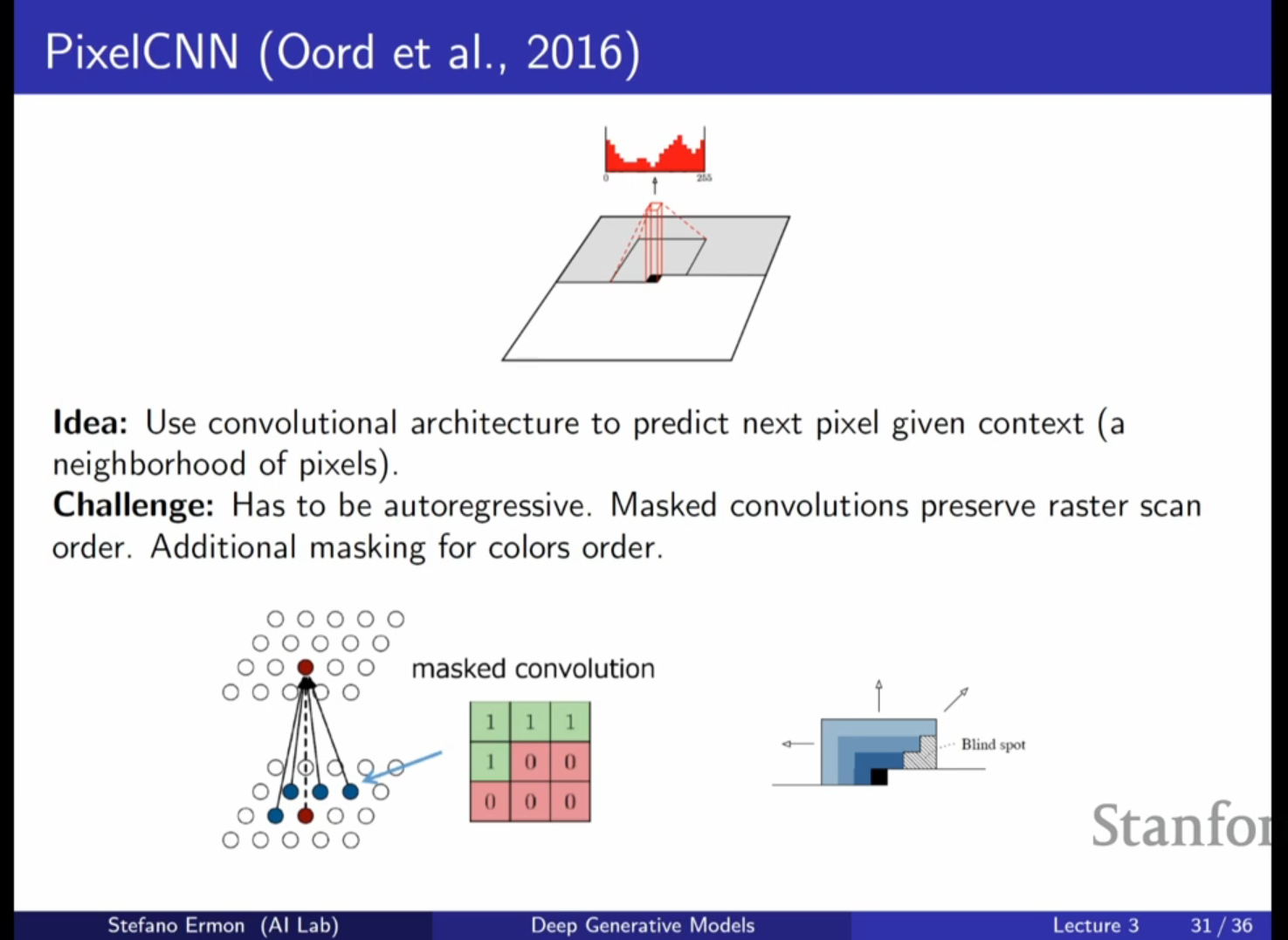
- PixelCNN: 학습 속도 향상을 위해 합성곱(Convolutional) 아키텍처를 사용합니다.
- 마스킹(Masking): 미래의 픽셀 정보를 보지 못하도록 커널의 특정 부분을 0으로 설정하여 인과성(Causality)을 유지합니다.
- 블라인드 스폿(Blind Spot): 단순 마스킹된 합성곱을 쌓으면 특정 영역을 보지 못하는 문제가 발생할 수 있어, 이를 해결하기 위한 정교한 아키텍처 설계가 필요합니다.
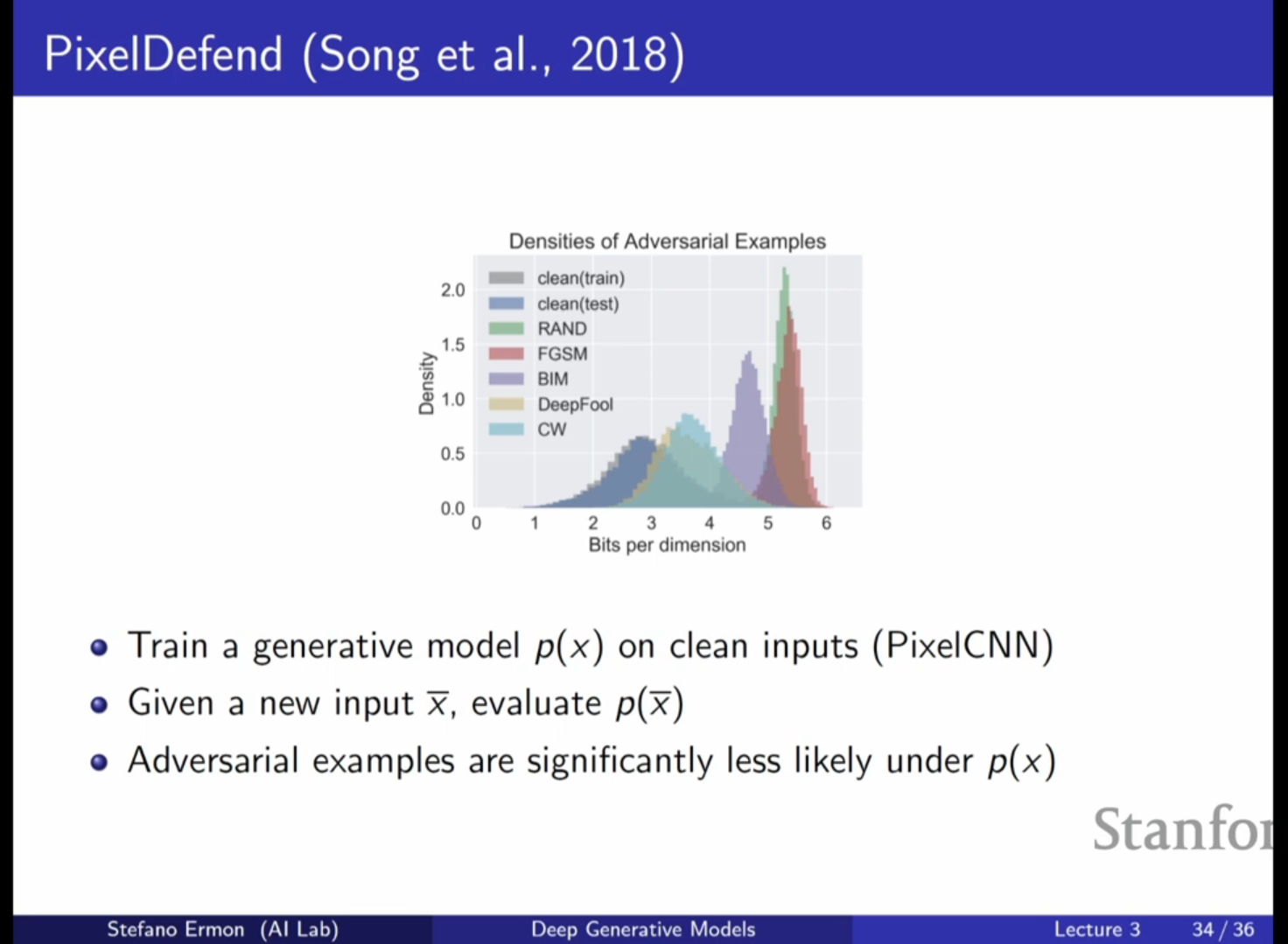
- 이상 탐지(Anomaly Detection): 잘 학습된 PixelCNN은 자연스러운 이미지에 높은 확률을 부여하고, 변형된 이미지(적대적 공격 등)에 낮은 확률을 부여함으로써 이상 탐지 도구로도 활용될 수 있습니다.


4. 최대 가능도 학습(Maximum Likelihood Learning)
- 학습의 목표: 미지의 데이터 분포 와 모델 분포 사이의 거리를 최소화하여, 모델이 데이터를 가장 잘 설명하도록 하는 파라미터 를 찾는 것입니다.

- KL 발산(KL Divergence): 두 확률 분포 사이의 유사성을 측정하는 지표로, 다음과 같이 정의됩니다.
- 이는 항상 0 이상이며, 두 분포가 같을 때만 0이 됩니다.
- 정보 이론적 해석: 데이터를 압축할 때 발생하는 비효율성을 의미하며, KL 발산을 최소화하는 것은 최적의 압축(Compression) 방식을 찾는 것과 같습니다.



- 최대 가능도 추정(MLE)으로의 유도: KL 발산 식을 분해하면 다음과 같습니다.
- 첫 번째 항(데이터의 엔트로피)은 와 무관한 상수이므로, KL 발산을 최소화하는 것은 두 번째 항인 로그 가능도(Log-likelihood)를 최대화하는 것과 동일합니다.

- 몬테카를로 추정(Monte Carlo Estimation): 실제 의 기댓값을 계산할 수 없으므로, 우리가 가진 학습 데이터셋 를 사용하여 평균 로그 가능도로 근사합니다.
- 데이터셋이 충분히 크다면 이 샘플 평균은 실제 기댓값에 수렴하며, 샘플 수가 늘어날수록 분산이 감소하여 더 정확한 추정이 가능해집니다.








5. 일반화와 모델의 복잡도 (Bias-Variance Tradeoff)
- 과적합(Overfitting): 모델이 학습 데이터를 단순히 암기해버리면, 학습 데이터에는 높은 확률을 부여하지만 새로운 데이터(Unseen data)에는 제대로 대응하지 못하게 됩니다.
- 편향-분산 트레이드오프(Bias-Variance Tradeoff):
- 편향(Bias): 모델이 너무 단순하여 데이터의 실제 경향성을 캡처하지 못하는 경우(Underfitting) 발생합니다.
- 분산(Variance): 모델이 너무 유연하여 데이터의 작은 변화에도 민감하게 반응하는 경우(Overfitting) 발생합니다.
- 해결 방안:
- 교차 검증(Cross-validation): 검증 데이터셋(Validation set)을 사용하여 학습 손실과 검증 손실 사이의 간격을 체크합니다.
- 정규화(Regularization): 더 단순한 모델을 선호하도록 페널티를 부여하거나 파라미터 수를 제한합니다.
QnA 섹션
Q1. 자기회귀 모델에서 조건부 독립(Conditional Independence) 가정이 포함되나요?
- A: 명시적인 조건부 독립 가정을 세우지는 않습니다. 하지만 특정 함수 형태(예: 마스킹된 합성곱)를 사용함으로써 모든 가능한 의존성을 다 완벽하게 캡처하지는 못할 수 있습니다. 명시적으로 독립 가정을 강하게 하면 성능이 급격히 떨어지는 경향이 있습니다.
Q2. 트랜스포머가 LSTM(RNN)보다 표현력(Representation power)이 더 강력하다고 할 수 있나요?
- A: 이론적으로 RNN은 튜링 완전(Turing complete)하기 때문에 어떤 함수든 구현할 수 있어 트랜스포머보다 약하다고 단정하기 어렵습니다. 트랜스포머의 성공은 표현력 자체보다는 학습의 효율성과 귀납적 편향(Inductive bias)의 차이에서 기인한 바가 큽니다.
Q3. 오늘날 여전히 RNN을 사용하는 이유가 있나요?
- A: 추론(Inference) 효율성 때문입니다. RNN은 이전까지의 정보를 작은 은닉 상태 벡터 하나에 유지하므로, 생성 시 과거의 모든 데이터를 다시 계산할 필요가 없습니다. 이 때문에 최근에는 추론 효율성을 위해 다시 RNN 스타일의 아키텍처를 도입하려는 시도들이 있습니다.
Q4. 이미지의 경우 어떤 순서로 생성하는 것이 가장 좋나요?
- A: 현재는 주로 '왼쪽 상단에서 오른쪽 하단' 순서를 사용하지만, 이것이 최적이라는 보장은 없습니다. 순서 자체를 학습하려는 연구도 있었으며, 심지어 언어 모델의 경우에도 오른쪽에서 왼쪽으로 모델링해도 어느 정도 성능이 나옵니다.
Q5. KL 발산의 순서를 바꾸면(Reverse KL) 어떻게 되나요?
- A: 는 데이터셋의 모든 부분을 커버하려는 성질(Recall 중심)이 있는 반면, 순서를 바꾼 는 모델이 특정 모드(Mode)에만 집중하는 성질(Precision 중심)을 보입니다. 하지만 역방향 KL은 계산적으로 다루기가 훨씬 어렵습니다.
💡 비유로 이해하기:
최대 가능도 학습은 마치 지도 제작자가 실제 지형()을 보고 최대한 똑같은 지도()를 그리려는 것과 같습니다. 지형 전체를 다 가볼 수 없으니 샘플(학습 데이터)을 채집하여 지도를 그리는데, 너무 세세한 돌멩이 하나까지 다 그리려다 보면 정작 중요한 길을 놓칠 수 있고(과적합), 반대로 너무 큰 길만 그리면 실제 지형과 너무 달라져 쓸모없는 지도가 됩니다(편향). 최적의 지도는 샘플을 통해 지형의 핵심 구조를 파악하면서도 적절히 단순화되어야 합니다.

AI 공부합니다