8.17.4 버전에서 디스크 용량 부족(flood stage disk watermark) 경고가 뜬 상태임. 디스크가 꽉 차면서, 시스템 인덱스(.security-*) 에 저장된 중요한 shard가 손상됐거나 read-only 로 잠겼을 가능성이 높다. 그러면서 Elasticsearch 9.0.0 올리면서 문제 발생.
리눅스 서버 디스크 vs Elasticsearch 관점 디스크 용량 차이
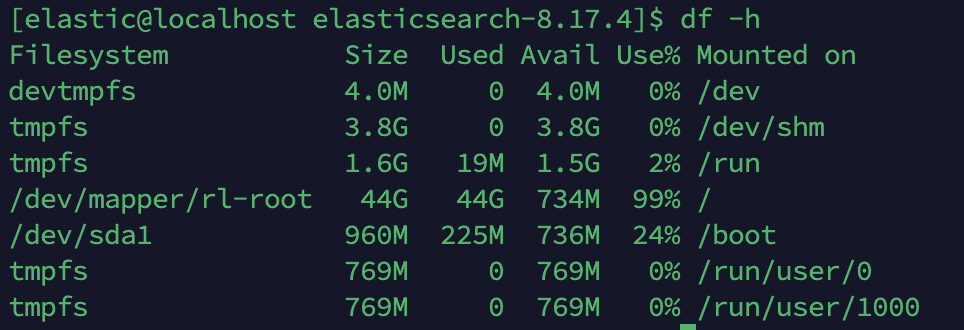
1. 리눅스 서버 전체 디스크 용량 확인
리눅스 서버의 전체 파일시스템 사용량을 보여줌. OS + 모든 앱 + 로그 + 데이터 합쳐서 총합
[elastic@localhost elasticsearch-8.17.4]$ df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 4.0M 0 4.0M 0% /dev tmpfs 3.8G 0 3.8G 0% /dev/shm tmpfs 1.6G 19M 1.5G 2% /run /dev/mapper/rl-root 44G 44G 733M 99% / /dev/sda1 960M 225M 736M 24% /boot tmpfs 769M 0 769M 0% /run/user/0 tmpfs 769M 0 769M 0% /run/user/1000
2. Elasticsearch 디스크 사용량
ES 가 저장하는 디렉토리만 기준으로 계산한 사용량. ES 인덱스 파일들이 차지하는 공간만 봄
[elastic@localhost elasticsearch-8.17.4]$ curl -k -u elastic:PASSWORD 'https://192.168.219.159:9200/_cat/allocation?v&h=shards,disk.percent,disk.total,disk.used,disk.avail,node'
shards disk.percent disk.total disk.used disk.avail node
0 98 43.9gb 43.2gb 733.5mb node-1
49 52 43.9gb 23.2gb 20.6gb node-2
49 49 43.9gb 21.5gb 22.3gb node-3- Elasticsearch 인덱스 삭제해서 공간확보 필요
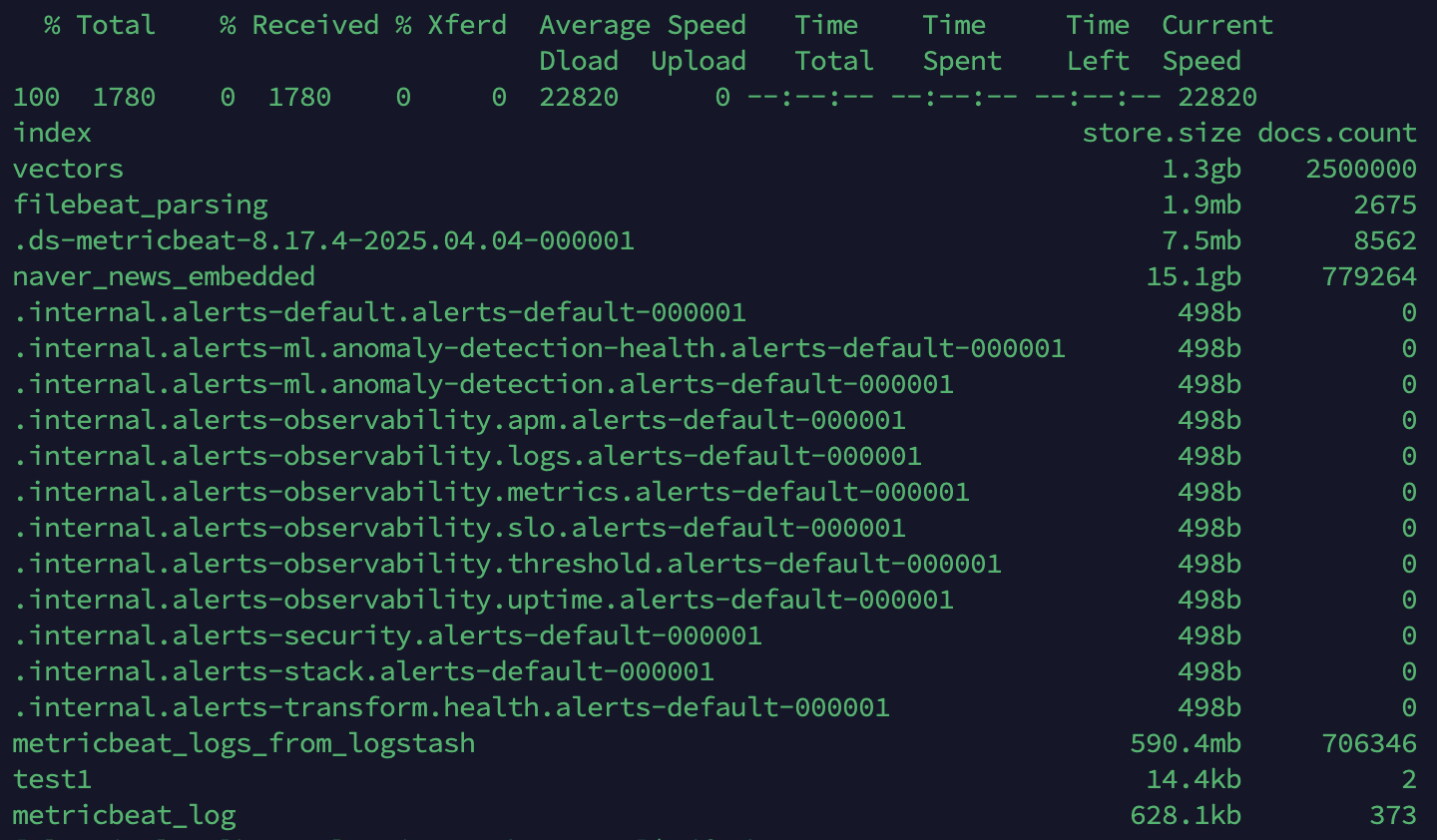
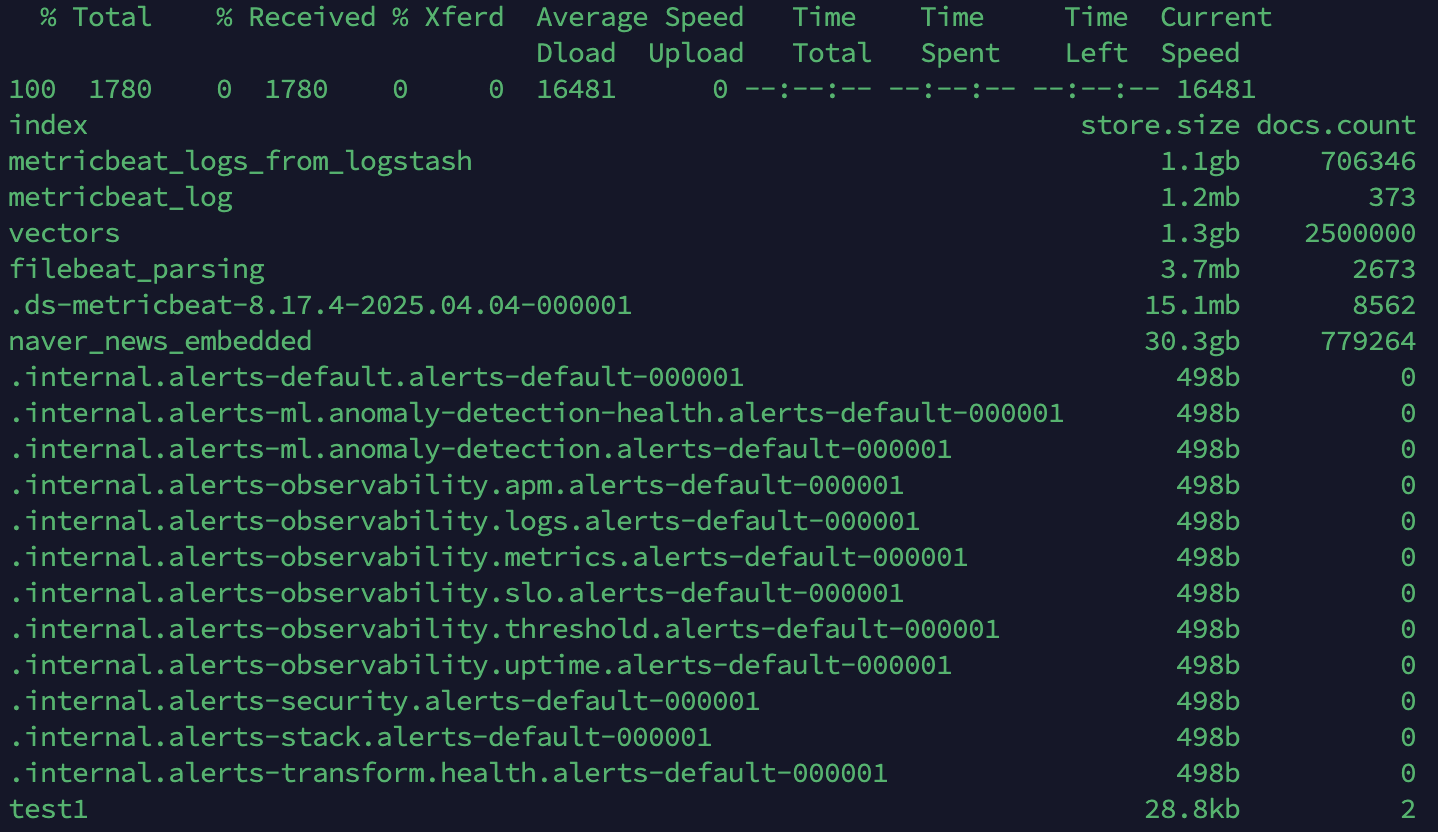
[elastic@localhost elasticsearch-8.17.4]$ curl -k -u elastic:PASSWORD "https://192.168.219.159:9200/_cat/indices?v&h=index,store.size,docs.count" | sort -k2 -h
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 1780 0 1780 0 0 16481 0 --:--:-- --:--:-- --:--:-- 16481
index store.size docs.count
metricbeat_logs_from_logstash 1.1gb 706346
metricbeat_log 1.2mb 373
vectors 1.3gb 2500000
filebeat_parsing 3.7mb 2673
.ds-metricbeat-8.17.4-2025.04.04-000001 15.1mb 8562
naver_news_embedded 30.3gb 779264
.internal.alerts-default.alerts-default-000001 498b 0
.internal.alerts-ml.anomaly-detection-health.alerts-default-000001 498b 0
.internal.alerts-ml.anomaly-detection.alerts-default-000001 498b 0
.internal.alerts-observability.apm.alerts-default-000001 498b 0
.internal.alerts-observability.logs.alerts-default-000001 498b 0
.internal.alerts-observability.metrics.alerts-default-000001 498b 0
.internal.alerts-observability.slo.alerts-default-000001 498b 0
.internal.alerts-observability.threshold.alerts-default-000001 498b 0
.internal.alerts-observability.uptime.alerts-default-000001 498b 0
.internal.alerts-security.alerts-default-000001 498b 0
.internal.alerts-stack.alerts-default-000001 498b 0
.internal.alerts-transform.health.alerts-default-000001 498b 0
test1 28.8kb 2Replica shard 줄이기(복제본 없애서 디스크 줄이기)
- Elasticsearch 디스크 사용량 = 인덱스 데이터 + 메타데이터 + 세그먼트 + 복제본 + Lucene 오버헤드 + 시스템 파일
- Primary 의 복제본. 장애가 발생하면 replica가 자동 승격. 서버 다운돼도 데이터 손실 없이 바로 서비스 가능. 디스크 용량 2배 소모되지만, 디스크 여유 없거나 테스트 서버에서는 replica 줄이는게 효율적
➡️ Replica 수를 줄여도 Linux 전체 디스크(df -h) 사용량은 바로 줄지 않음.
✅ 인덱스(Shard)의 복제본(replica)을 삭제했기 때문에, 클러스터 저장소 할당량(_cat/allocation)은 바로 줄어들 수 있음. 하지만, Linux 파일 시스템(df -h) 입장에서는 이미 만들어진 Lucene segment 파일들이 실제 디스크 공간을 점유하고 있기 때문에 자동으로 사라지지 않음. “Replica Shard 삭제” ≠ “디스크 물리 공간 바로 해방”
✅ Elasticsearch는 Lucene 기반이고, Lucene은 segment 파일 단위로 관리 Replica shard 삭제 = “샤드 복제본 메타데이터만 삭제”(segment 파일은 여전히 디스크에 있음). 파일 시스템 상에는 여전히 존재하고, Elasticsearch 내부 청소를 통해 정리해야함
✅ Force Merge (인덱스 내 삭제된 데이터, 불필요한 segment 파일 합치기)
Force Merge는 디스크 공간 최적화 작업(=디스크 공간 확보)이 아니라, segment 파일 수를 줄여 검색 효율을 높이는 작업(=검색 최적화)
# 특정 인덱스
curl -k -u elastic:PASSWOD -XPOST "https://192.XXX.XXX.159:9200/naver_news_embedded/_forcemerge?max_num_segments=1"
# 전체 인덱스
curl -k -u elastic:PASSWORD -XPOST "https://192.XXX.XXX.159:9200/_forcemerge?max_num_segments=1"
{"_shards":{"total":32,"successful":32,"failed":0}}- max_num_segments=1 -> 최대한 segment를 하나로 합쳐서 디스크 공간 줄이는 것
- Force Merge는 CPU, Disk I/O를 많이 먹기 때문에 서비스 중인 서버에서는 신중(시간오래 걸림)
🤔 Disk space는 왜 안 줄어들지?
Force merge가 정상적으로 완료되었지만, disk 용량은 줄어들지 않음.
1. Force merge는 segment 병합만 함
- 디스크에서 segment 파일을 삭제하는 게 아님
- merge 된 후에도 lucene은 파일을 한동안 유지함(일종의 soft-delete, garbage collection 이후 실제 삭제됨)
- Elasticsearch 내부 GC가 완료되기까지 시간이 걸릴 수 있음
- 또는 일부 인덱스에 삭제된 문서가 많지 않다면 효과가 적을 수 잇음
정리 전
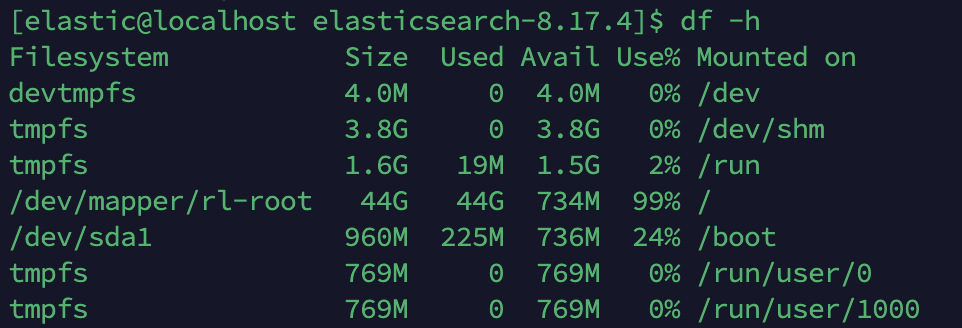

정리 후