Elasticsearch
1.[Elasticsearch] 엘라스틱서치 구성

ELK Stack 구성 beats(Data Collection) -> logstash(Data Aggregation&Processing) -> elasticsearch(Indexing&storage) -> kibana(Analysis&Visualization) beat
2.[Elasticsearch] Elasticsearch 설치

[버전] 8.17.4 tar [서버] 192.168.219.159 (master) : Elasticsearch, Kibana, Logstash, CA 인증서 192.168.219.157 (data) : Elasticsearch, Metricbeat 192.168.219
3.[Elasticsearch] Kibana 설치

버전 8.17.4 tar서버192.168.219.159 (master) : Elasticsearch, Kibana, Logstash, CA 인증서 192.168.219.157 (data) : Elasticsearch, Metricbeat192.168.219.158 (d
4.[Elasticsearch] Logstash 설치

버전 8.17.4 tar서버192.168.219.159 (master) : Elasticsearch, Kibana, Logstash, CA 인증서 192.168.219.157 (data) : Elasticsearch, Metricbeat192.168.219.158 (d
5.[Elasticsearch] Metricbeat 설치 및 연동

과제1\. metricbeats → ES(3 node cluster) → kibana discover 확인2\. metricbeats → logstash → ES(3 node cluster) → kibana discover 확인버전 8.17.4 tar서버192.168.
6.[Elasticsearch] ELK Stack 파이프라인 구축
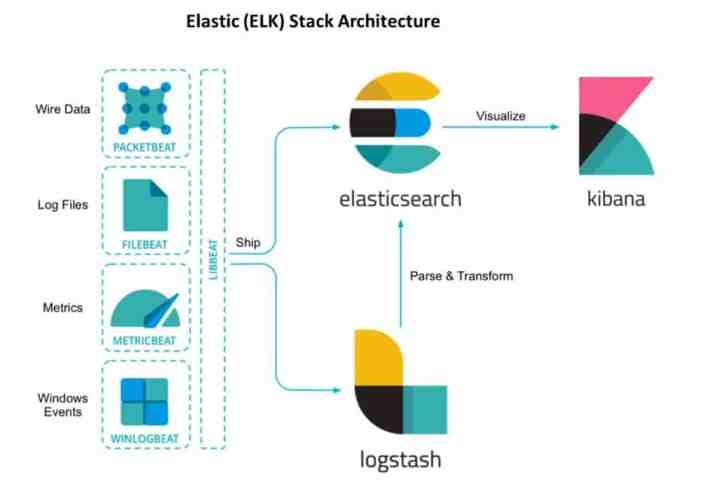
[과제] Metricbeat 가 수집한 시스템 메트릭을 Elasticsearch에 전송하고 Kibana 에서 Discover, Dashboard 시각화 할 수 있게 만드는 것 Metricbeat 가 수집한 시스템 메트릭을 Logstash를 거쳐 Elasticsearch
7.[Elasticsearch] 파일 동시 적재(pipeline)

과제1\. 여러 csv, json 동시 적재 진행해보고, metric beat & file beat도 pipeline 사용하여 동시 적재 진행해본다. 버전8.17.4 tar서버192.168.219.159 (master) : Elasticsearch, Kibana, Lo
8.[Elasticsearch] Beat 동시 실행(pipeline)
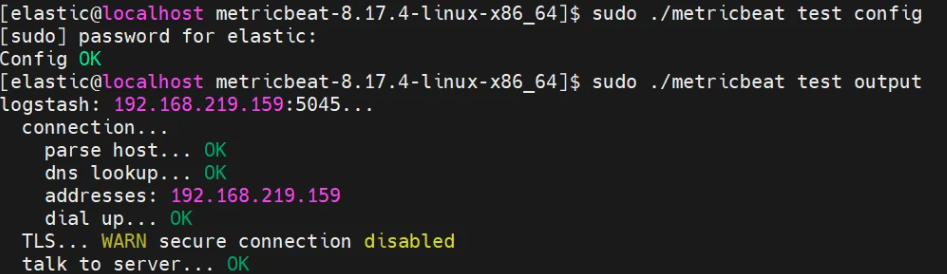
과제Metricbeat와 Filebeat는 실시간 로그/메트릭 수집 에이전트이고, logstash의 pipeline.yml에 각 beat 로 부터 들어오는 데이터를 처리할 파이프라인들을 등록하여 동시 실행한다.Metricbeat 의 포트번호 = 5045Filebeat
9.[Elasticsearch] 벡터서치 구현
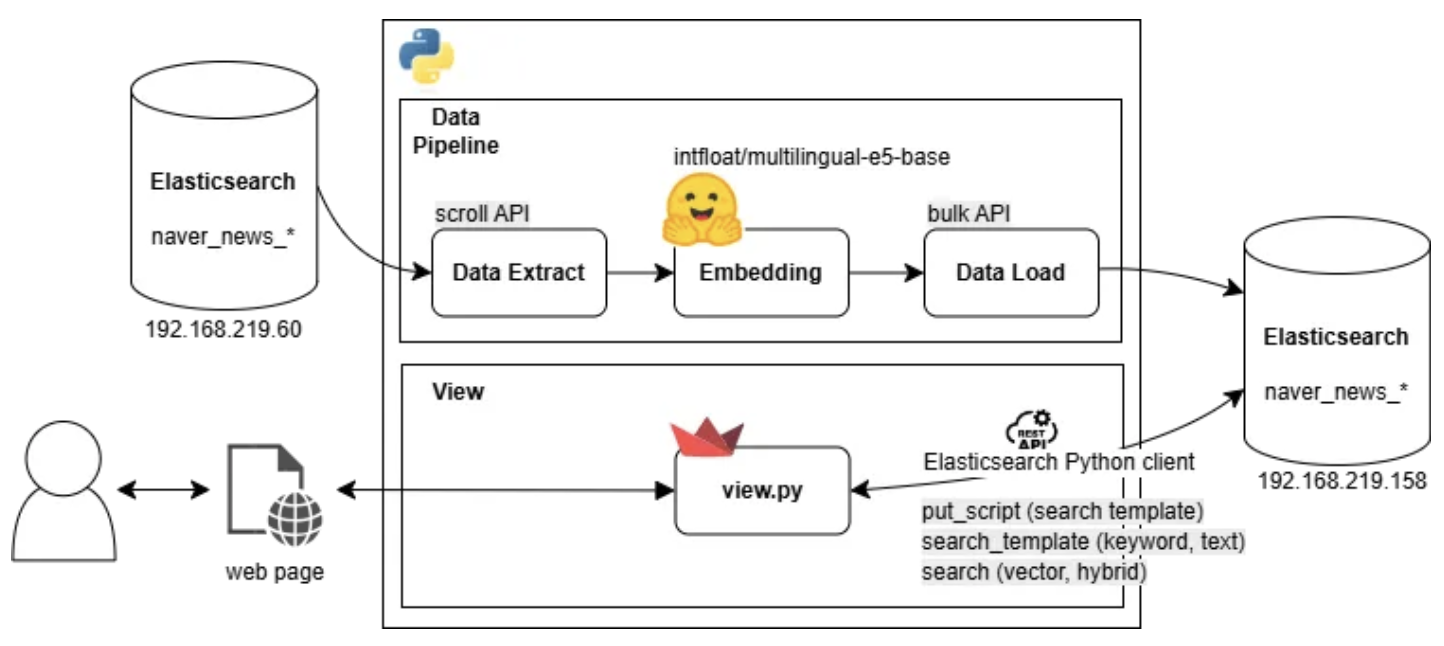
목표1\. 네이버 뉴스 기사 데이터 ETL 데이터 수집 : 기존 Elasticsearch 적재되어 있는 네이버 뉴스 데이터 수집데이터 변환 : 데이터 전처리 및 임베딩 수행데이터 적재 : 임베딩 벡터를 포함한 데이터를 보유 서버에 적재검색 기능 구현키워드 검색, 벡터
10.[Elasticsearch] Curl
logstash에 있는 실행된 conf 파일하나(bin/logstash -f config/metric/metric.conf)PID 34463 으로 kibana 실행중logstash와 다르게 grep node로 해줘야함!!잘 사용 안함(kibana를 굳이 귀찮게 curl
11.[Elasticsearch] 디스크 관리
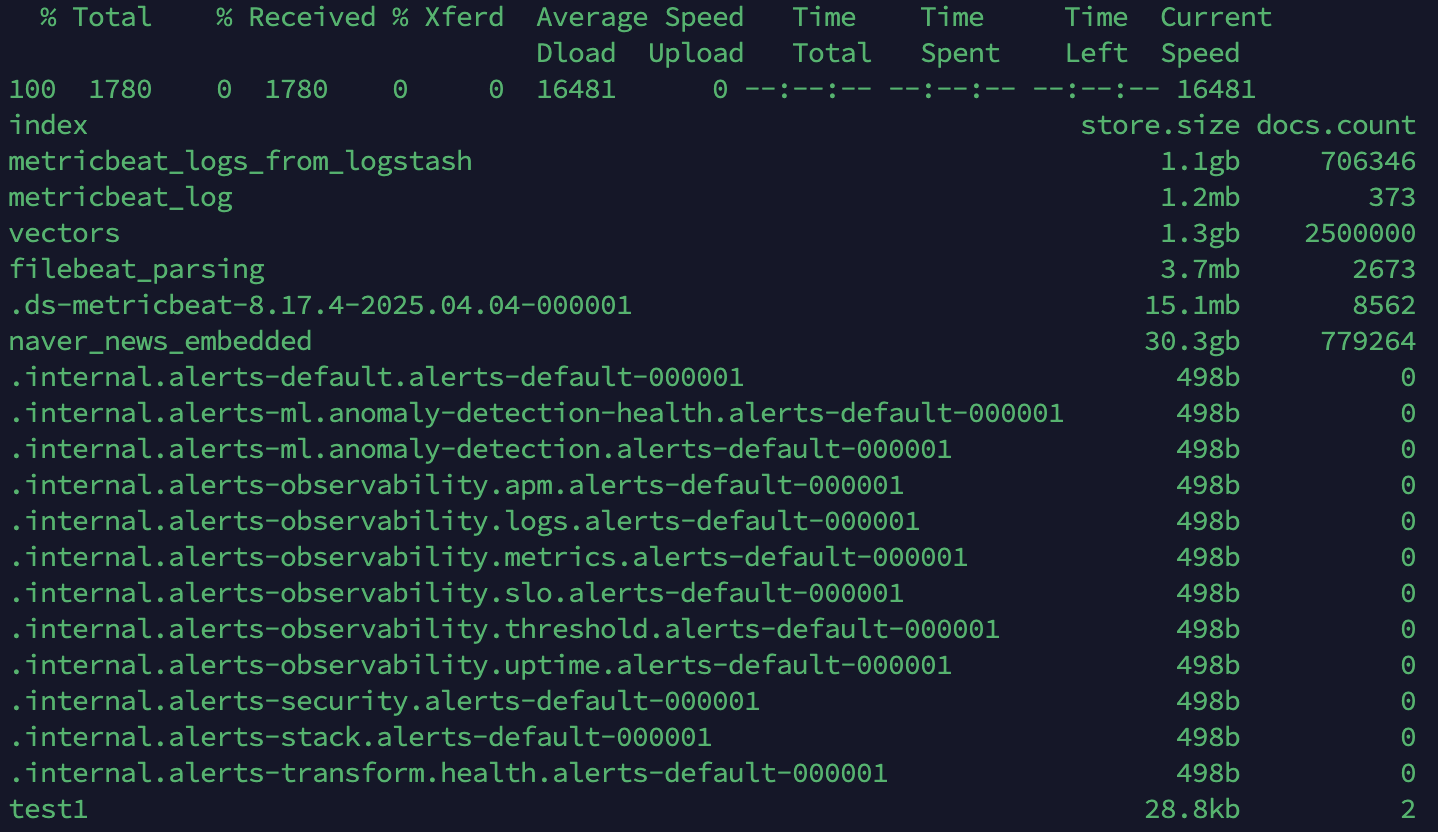
8.17.4 버전에서 디스크 용량 부족(flood stage disk watermark) 경고가 뜬 상태임. 디스크가 꽉 차면서, 시스템 인덱스(.security-\*) 에 저장된 중요한 shard가 손상됐거나 read-only 로 잠겼을 가능성이 높다. 그러면서 El
12.[Elasticsearch] esrally benchmark
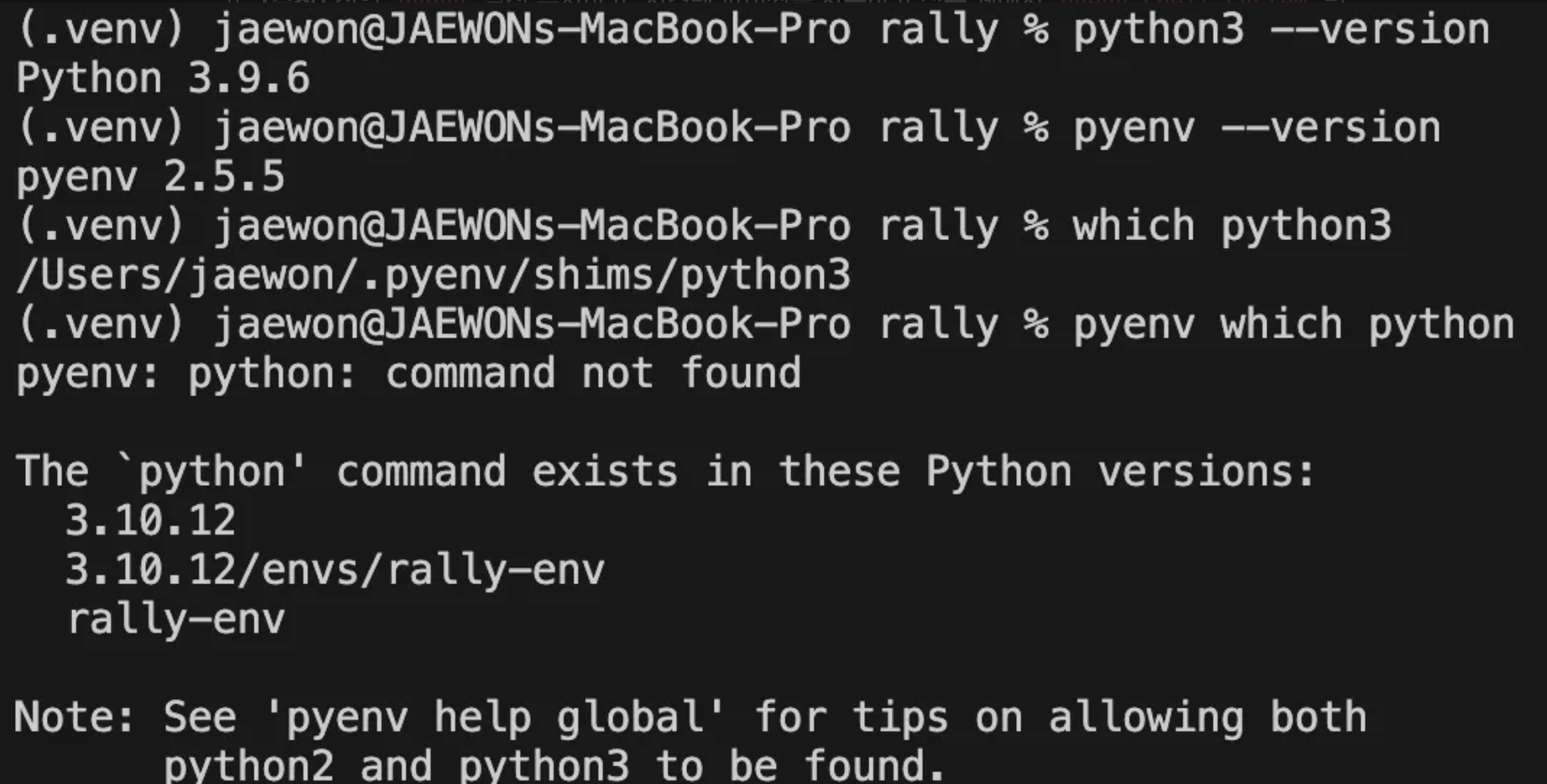
현재 버전(8.17.4)과 새로 나온 버전(9.0.0)의 성능 테스트를 위한 rally 오픈 소스를 통해 benchmark를 실행할 수 있다.homebrew를 통해서 pyenv 설치pyenv 설정 추가pyenv install 3.10.12 파이썬 버전 설치pyenv