[목표]
1. 네이버 뉴스 기사 데이터 ETL
- 데이터 수집 : 기존 Elasticsearch 적재되어 있는 네이버 뉴스 데이터 수집
- 데이터 변환 : 데이터 전처리 및 임베딩 수행
- 데이터 적재 : 임베딩 벡터를 포함한 데이터를 보유 서버에 적재
- 검색 기능 구현
- 키워드 검색, 벡터 검색, 하이브리드 검색 방식 구현
- Streamlit UI 구현
- 검색 화면 구현 및 검색 결과 및 소요 시간 표시
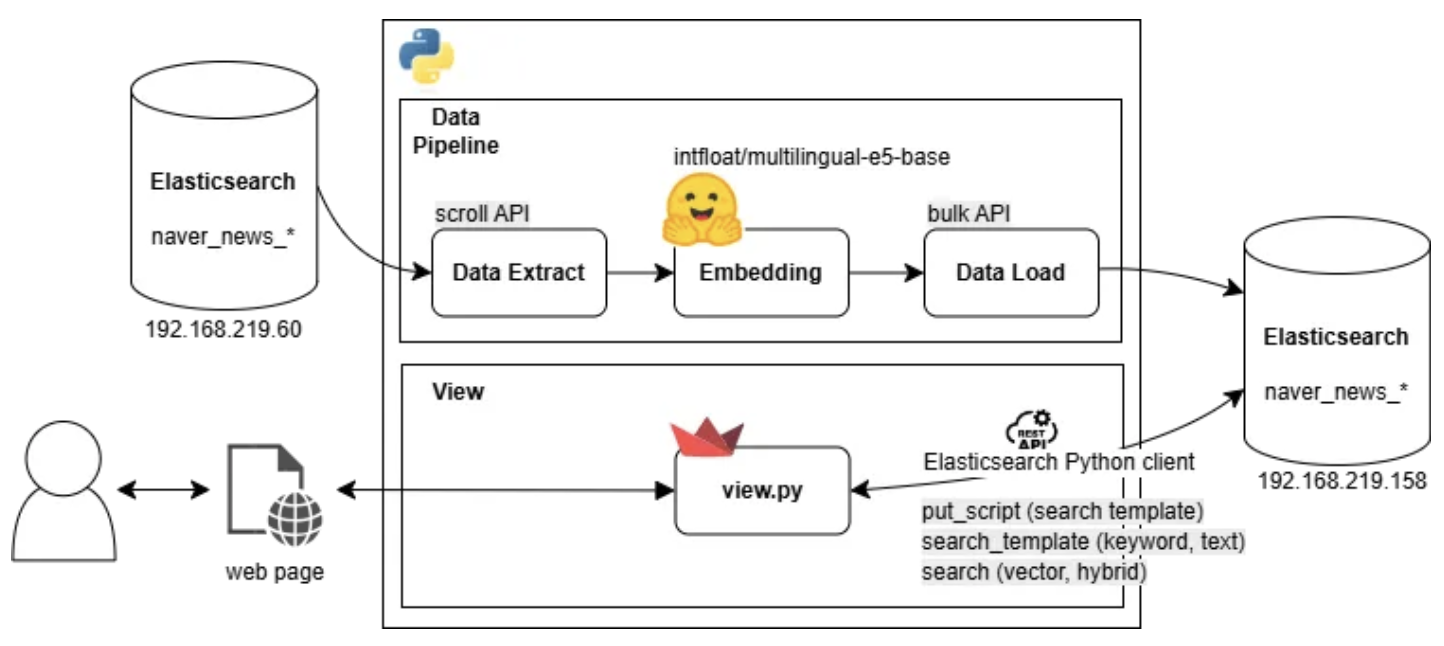
네이버 뉴스 기사 데이터 ETL
데이터 수집
- 전량 백업 & 클렌징 작업 (Scroll API)
remove_fields = ["title_vector", "content_vector", "title_with_content_vector"]
...
output_path = "naver_news_cleaned_full.jsonl"
with open(output_path, "w", encoding="utf-8") as f:
for doc in hits:
cleaned = clean_doc(doc)
...
while True:
scroll_res = requests.post(
f"{COMPANY_ES_HOST}/_search/scroll",
headers=headers,
auth=HTTPBasicAuth(USERNAME, PASSWORD),
...-
Elasticsearch Sroll API를 활용해 해당 데이터를 모두 순차적으로 가져와 벡터 필드 제거
-
리눅스 서버 내에서 회사 인덱스 데이터 -> JSONL 추출
데이터 변환
-
모델의 최대 시퀀스인 512 넘는 데이터 삭제
-
title_with_content 필드 임베딩
with open(input_path, "r", encoding="utf-8") as infile, open(output_path, "w", encoding="utf-8") as outfile: for line in tqdm(infile, desc="Reading"): doc = json.loads(line) text = doc.get("title_with_content") if text: batch.append((doc, text)) if len(batch) == batch_size: texts = [t for _, t in batch] vectors = model.encode(texts, convert_to_tensor=True, device=device).cpu().tolist() for (doc, _), vec in zip(batch, vectors): doc["title_with_content_vector"] = vec outfile.write(json.dumps(doc, ensure_ascii=False) + "\n" if batch: texts = [t for _, t in batch] ... -
Colab 과 리눅스 서버 내에서
title_with_content필드만 임베딩 시키는 과정. -
배치사이즈(1024) 가 되면 한 번에 모델에 넣고 벡터 임베딩 실행. texts는 임베딩 대상 문장들의
리스트. model_encode()로 768차원 벡터 임베딩 생성 -
JSONL → Elasticsearch Bulk 포맷(JSON) 변환
with open(input_path, "r", encoding="utf-8") as infile, open(output_path, "w", encoding="utf-8") as outfile:
for line in infile:
doc = json.loads(line)
doc_id = doc.get("url")
meta = {
"index": {
"_index": index_name,
"_id": doc_id
}
}
outfile.write(json.dumps(meta, ensure_ascii=False) + "\n")
outfile.write(json.dumps(doc, ensure_ascii=False) + "\n")- Elasticsearch의 Bulk API에 데이터를 넣을 때는 특정 포맷의 JSON Lines 형식을 그대로 쓰되, Bulk 포맷으로 변환 내에 적재하기 위한 과정. 이는 한번의 HTTP 요청으로 여러 개의 문서를 삽입할 수 있는 성능 최적화된 기능.
데이터 적재
- naver_news_embedded 인덱스 생성 (Kibana Dev Tool)
PUT /naver_news_embedded
{
"mappings": {
"properties": {
"title": { "type": "text" },
"content": { "type": "text" },
"title_with_content_vector": {
"type": "dense_vector",
"dims": 768,
"index": true,
"similarity": "cosine"
}
}
}
}-
Elasticsearch 인덱스(naver_news_embedded) 생성 후 dense_vector 필드 생성 과정
-
Bulk insert 실행 (Linux 서버에서 python으로 실행)
BATCH_SIZE = 1000 # 1000줄 (500문서)씩 처리
with open(bulk_path, "r", encoding="utf-8") as f:
buffer = []
line_count = 0
total_sent = 0
for line in f:
buffer.append(line)
line_count += 1
if line_count % BATCH_SIZE == 0:
res = requests.post(
f"{ES_HOST}/_bulk",
headers={"Content-Type": "application/json"},
...
)
if res.status_code != 200 or res.json().get("errors"):
print(res.text)
total_sent += BATCH_SIZE // 2
buffer = []
if buffer:
res = requests.post(
f"{ES_HOST}/_bulk",
...- 배치 전송 방식 사용. Bulk 포맷 된 데이터를 읽을 때, 잘라서 메모리에 올려 메모리 부담을 최소화.
- 에러 디버깅이 가능하여 어디서 실패 했는지 로그 모니터링이 가능.
if line_count % BATCH_SIZE == 0: 쌓인 문서를 모두 이어 붙여 Bulk 요청 본문으로 만들고 전송
검색 기능 구현
텍스트, 키워드 검색(Search template)
- Search template 등록
- Elasticsearch에 "text_search_template"라는 서치 템플릿(script)을 등록하는 작업으로, Mustache 템플릿 문법을 이용해 동적으로 검색 쿼리를 구성할 수 있음.
es.put_script(id='text_search_template', body={
"script": {
"size": "{{size}}{{^size}}3{{/size}}",
"lang": "mustache",
"source": {
"query" : {
"bool": {
"must": [{ "match": { "title_with_content": "{{search_word}}" }}],
"filter": [{
"range": {
"date": {
"gte": "{{start_date}}{{^start_date}}2023-01-01{{/start_date}}",
"lte": "{{end_date}}{{^end_date}}2023-12-31{{/end_date}}"
}}}]}}}}})- Elasticsearch Python Client API의
put_script기능을 통해 search template 등록. - Mustache 템플릿
{{varaible}}포맷으로 사용자 입력 변수 처리.{{variable}}{{^variable}}default_value{{/variable}}포맷으로 기본값 지정.
- 텍스트, 키워드 검색 요청 및 결과 반환
- Elasticsearch에서 등록된 Search Template을 활용하여 검색 실행.
def text_search(**params) -> tuple:
res = es.search_template(
id="text_search_template",
index="naver_news_*",
params=params
)
return res
...
def main()->None:
...
input_query = st.text_input("검색어를 입력하세요.", value = "네이버")
res = text_search(
search_word=input_query,
start_date=start_date.strftime('%Y-%m-%d'), # 날짜 형식 맞추기
end_date=end_date.strftime('%Y-%m-%d')
)
...벡터 검색(knn, script_score)
- Query embedding 수행
- Elasticsearch에서 Huggingface 모델을 활용한 임베딩 방식과 Elasticsearch 내장 모델을 활용한 방식을 모두 실험한 결과, 코사인 유사도의 차이는 크지 않았으며, 각각의 방식은 환경과 목적에 따라 선택할 수 있는 장단점이 존재함.
- ANN과 script_score으로 벡터 서치 수행
- Elasticsearch에서 벡터 유사도 기반 검색을 구현하기 위해 knn과 script_score 방식을 모두 실험한 결과, knn은 대규모 데이터셋에서 효율적인 ANN에 유리한 반면 script_score는 커스터마이징이 용이하나 성능 저하가 발생할 수 있음을 확인.
def vector_search(input_query:str) -> tuple:
script_query = {
"script_score": {
"query": {"match_all": {}},
"script": {
"source": "cosineSimilarity(params.query_vector, 'title_with_content_vector') + 1.0",
"params": {"query_vector": text_embedding(input_query)}
}
}
}
res = es.search(
...
query=script_query
)
return res['hits']['hits'], res['took']knnproperty 사용하지 않고, query_vector와 타겟 필드(title_with_content_vector)와의cosineSimilarity연산을 통해 도큐먼트들의 score를 계산.- 벡터 검색 scoring이나 Elasticsearch에서 음수를 허용하지 않는 경우를 처리하기 위해
+1.0을 통해 양수 값으로 전환.
하이브리드 검색(rrf, script_score)
- rank property의 rrf 활용
- Elasticsearch의 rank.rrf 기능을 활용하면 텍스트 검색(match + filter)과 벡터 검색(knn) 결과를 조합하여 하이브리드 검색을 간단하게 구현 가능. 실제 실험 결과, 단일 방식보다 검색 품질과 다양성 면에서 향상된 결과를 보여줌.
# hybrid search
def hybird_search(search_word:str, start_date:str='2023-01-01', end_date:str="2023-12-31") -> tuple:
res = es.search(
index='naver_news_*',
size=3,
query={
"bool": {
...
},
knn={ ... },
rank={'rrf': {}},
)
return res['hits']['hits'], res['took']
...
def main():
...
results, took = hybird_search(input_query)
... - script_score 활용
- script_score 쿼리는 문서 검색과 동시에, 각 문서에 대해 커스텀 스크립트로 점수를 계산하여 랭킹을 매길 수 있는 Elasticsearch의 기능. 즉, 필터링된 문서 집합에 대해 사용자가 정의한 점수(예: 코사인 유사도)로 스코어를 부여하여 원하는 방식으로 검색 결과를 정렬 가능.
def hybrid_script_score_search(...)-> tuple:
query_vector = text_embedding(search_word)
res = es.search(
index='naver_news_*',
size=3,
query={
"script_score": {
"query": {
"bool": {
"filter": [
{"range": {
"date": {"gte": start_date, "lte": end_date}
}},
{"exists": {"field": "title_with_content_vector"}}
]
}
},
"script": {
"source": "cosineSimilarity(params.query_vector, 'title_with_content_vector') + 1.0",
"params": {
"query_vector": query_vector
}}}})
return res["hits"]["hits"], res['took']
- query에 해당하는 문서들을 찾고, script에 따라 각각의 문서에 대해 score를 계산하는 방식.
UI 구현
Streamlit으로 웹 페이지 구현
- 검색 인터페이스
- 검색어와 검색 범위(뉴스 기사의 업로드일)를 입력 받을 수 있는 input field 구현.
- 각각 텍스트 검색(match), 벡터 검색(knn, script_score), 하이브리드 검색(rrf, script_score)에 걸린 시간과 결과 출력.
- 사이드 바에는 키워드 검색(term)창 구현.
Took 파라미터로 검색 수행 시간 추적
- Took Number : (integer) Milliseconds it took Elasticsearch to execute the request.
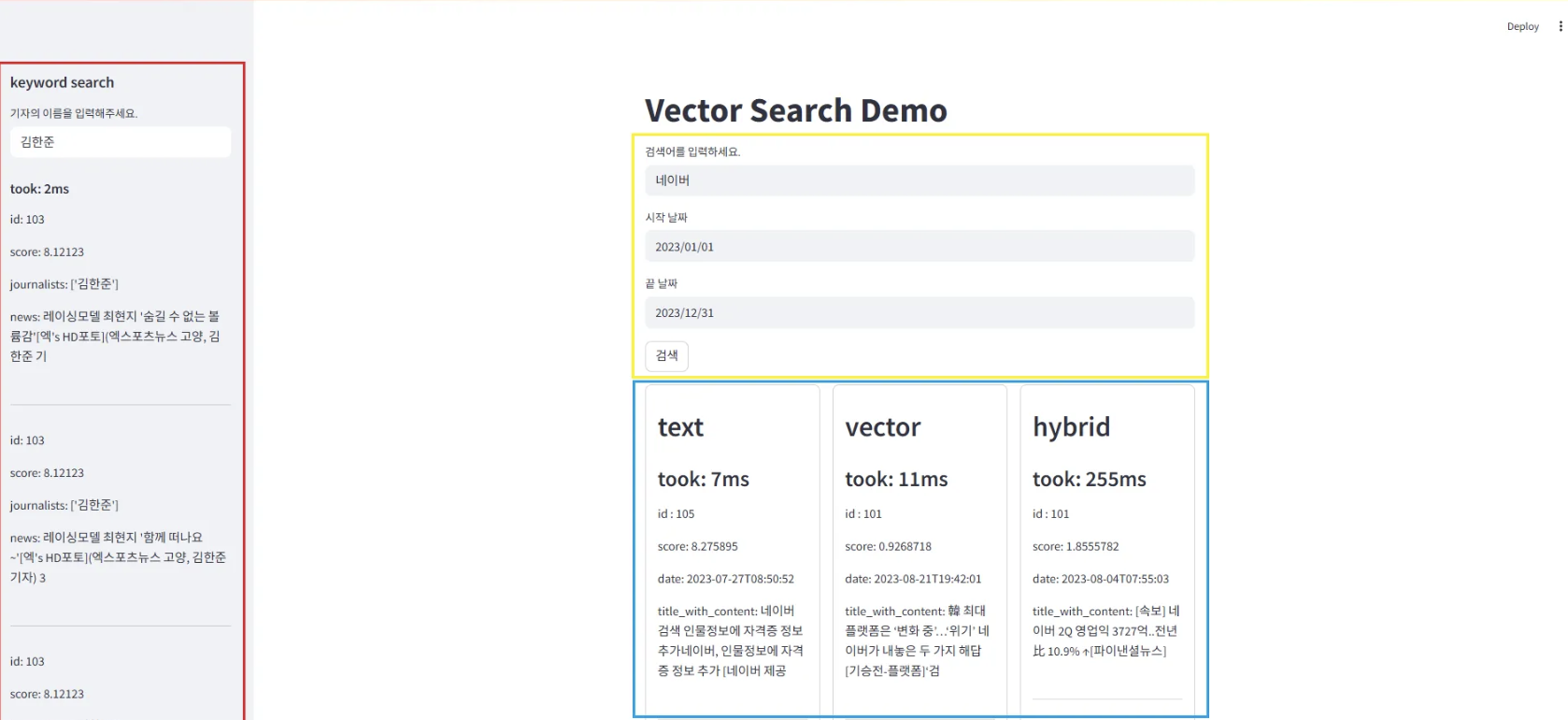
- Sidebar (키워드 검색) : 기자 이름을 입력하면 검색에 소요된 시간(took)과 해당 기자가 작성한 기사들의 id, score, 기자명, 기사 내용을 출력.
- Input fields (검색어, 검색 범위 - 날짜) : 사용자 입력으로 검색어와 검색 범위를 받아 검색 메서드들에 변수로 활용
- Output field (텍스트, 벡터, 하이브리드 검색) : Input fields에서 입력된 검색어와 범위를 통해 검색에 소요된 시간, 검색 결과인 기사들의 id, score, date, 기사 내용을 출력.
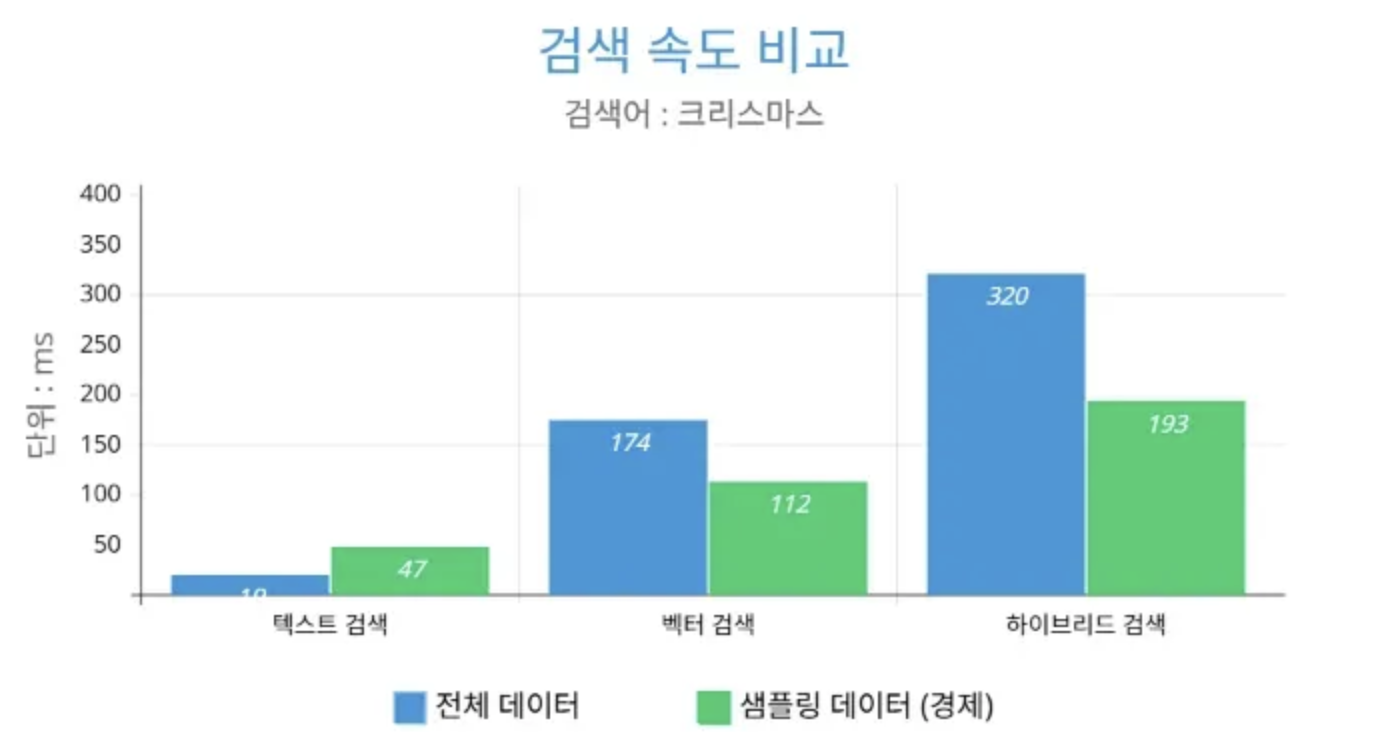
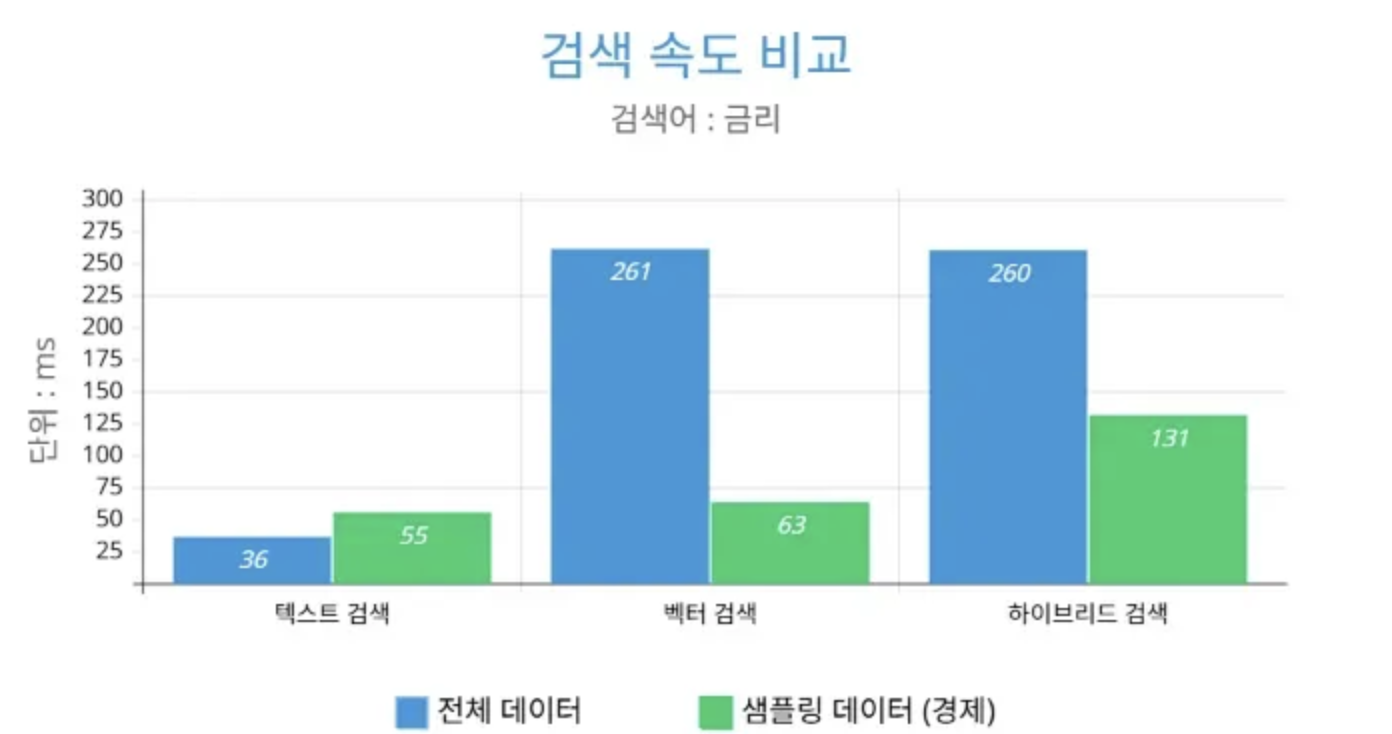
결과 분석
트러블슈팅
자원 활용 최적화
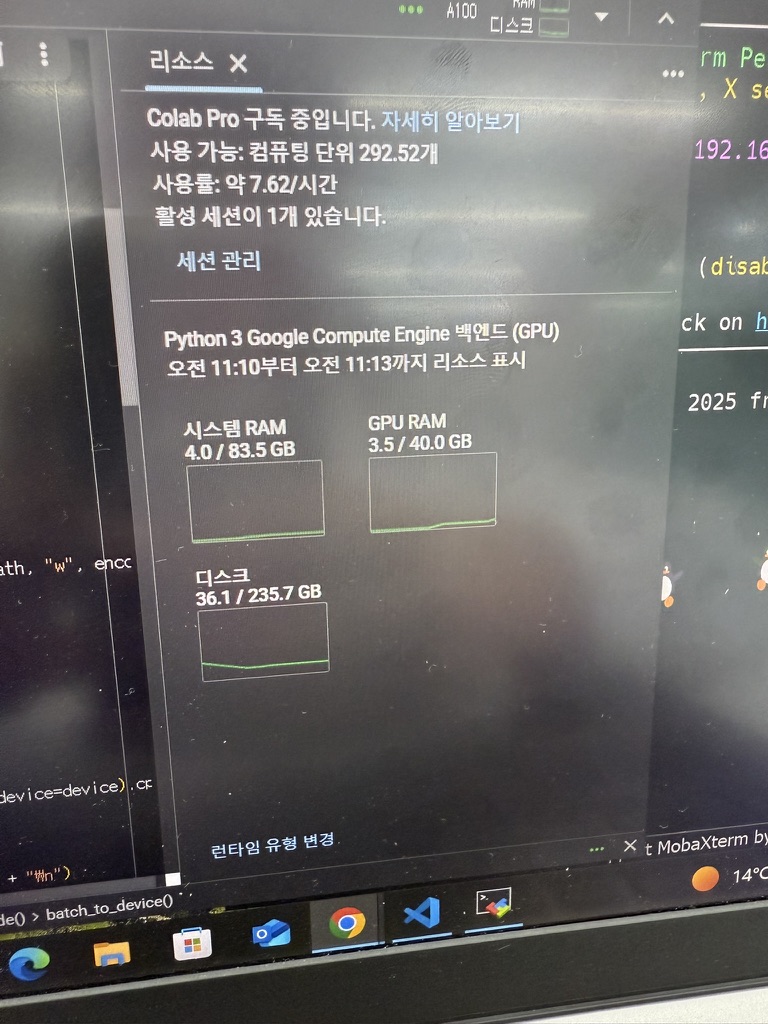
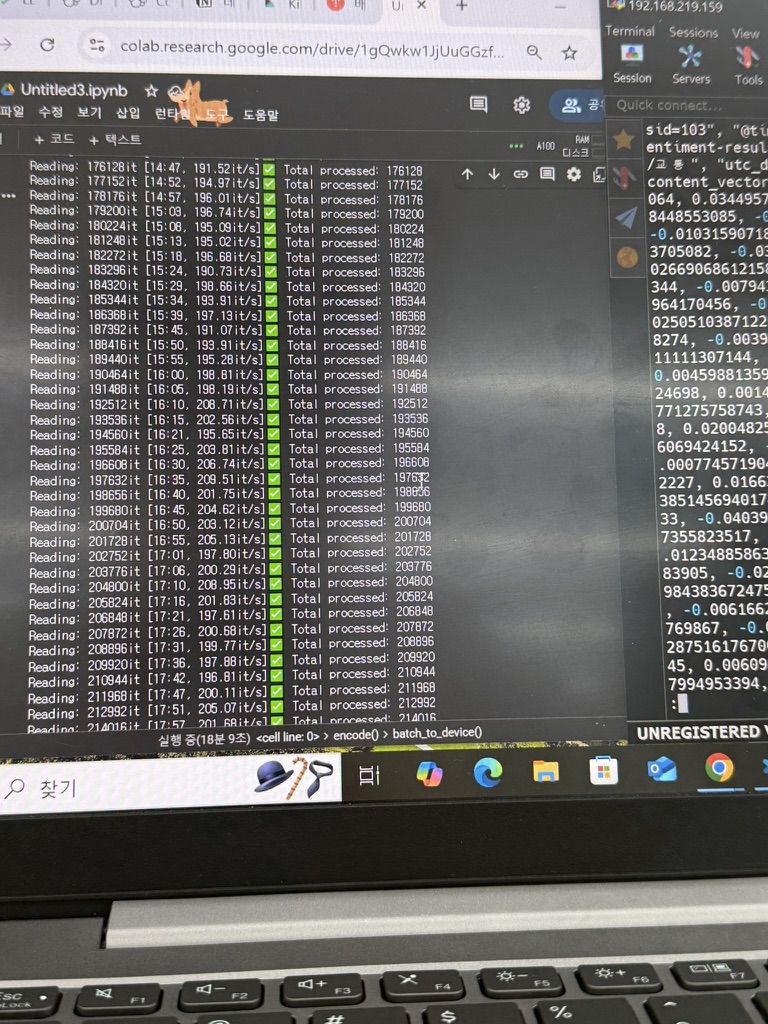
처음으로 RDB가 아닌 100 GB 데이터를 다뤄봣는데, 작다하면 작고 크다하면 큰 데이터를 임베딩 하는 작업이 너무 오래 걸렸다. 이를 위해서 CUDA 활용 및 데이터 병렬 처리 방식을 구사해 보았다. Google Colab Pro 를 구매 했는데, 역시 2만원으로 A100 를 사용하는 맛이란.. 이게 아니라면 일일이 잘라서 임베딩 하는 작업을 해야하는데, 이 역시 엔지니어의 숙명이랄까? 켜놓고 하룻밤 자고 오면 터지는 일이 많았음
데이터 핸들링
약 10만개의 데이터가 e5-base 모델의 최대 시퀀스인 512를 초과했다. 모델이 허용하는 최대 시퀀스 길이를 초과한 글자들의 손실이 발생하는데, 손실이 발생한 텍스트는 문맥이 끊겨서 모델이 문장 전체 의미를 오해하거나 왜곡된 출력을 생성할 수 있다. 이럴 땐 무결성을 보장하기 위해 최대 시퀀스(512)를 초과하는 데이터는 삭제하였다.
쑥스럽지만 코드를 공개해본다.
https://github.com/DillonLim-Jaewon/Search_demo
