기계학습의 분류 – 지도 학습, 비지도 학습, 강화 학습
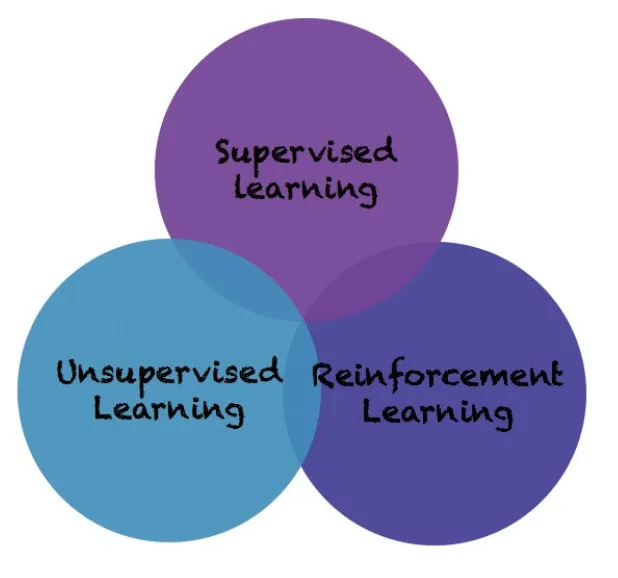
기계 학습이란, 문자 그대로 기계가 스스로 무언가를 배우는 과정을 뜻한다. 크게 아래 세 가지로 분류할 수 있다.
- 지도 학습 (Supervised Learning)
- 비지도 학습 (Unsupervised Learning)
- 강화 학습 (Reinforcement Learning)
1. 지도 학습
지도 학습은 정답(레이블)이 있는 데이터를 바탕으로 학습하는 방식이다.
예시)
민준이가 자전거를 배우는 상황. 아빠(지도자)에게 자전거 타는 법을 배우면서, 도움을 받아 점점 잘 타게 되는 구조.
2. 강화 학습
강화 학습은 정답을 알지 못한 채 시행착오를 통해 배우는 방식이다.
예시)
지윤이가 자전거를 혼자 타다가 넘어지고, 또 시도해보면서 스스로 요령을 터득해 가는 상황.
지도 학습과 강화 학습은 모두 기계학습의 하위 개념이라는 점에서 공통점이 있지만, 지도자 유무와 학습 방식에서 큰 차이를 보인다.
비지도 학습 예시
- 1. 생성 모델
예: 사람 얼굴 사진 1만 장을 학습한 후, 존재하지 않는 사람의 얼굴을 생성하는 모델 - 2. 클러스터링
예: 라벨이 없는 데이터들을 비슷한 성질끼리 자동으로 묶는 작업
🧠 지도 학습 예시: 성별 분류

남자/여자 사진 1만 장씩 학습시키면, 새로운 사람의 사진을 입력했을 때 성별을 맞히는 모델을 만들 수 있다.
- 학습에 사용된 데이터는 학습 데이터

다음과 같이 앞에서 학습한 모델을 이용해 각 사진에 대해 성별이 무엇일지 맞혀볼 수 있다.
이 때 어떤 경우에는 틀리기도 하고 맞히기도 할 것인데, 이처럼 정답을 모르지만 우리가 궁극적으로 정답을 맞히고자 하는 데이터를 테스트 데이터라고 한다. 여기서 중요한 점은 테스트 데이터는 지금까지 한 번도 본적이 없는 사진(학습 데이터에 겹치지 않는 사진)이어야 한다.
정리하면 이처럼 학습 데이터를 이용해 인풋과 정답 사이 관계를 학습하여 테스트 상황에서 정답을 맞힐 수 있는 인공지능을 학습하는 방식을 지도 학습이라고 부른다.
강화 학습의 핵심: 순차적 의사결정과 보상
지윤이처럼 혼자 자전거를 배우는 경우, 다음 두 가지가 학습의 핵심 요소가 된다.
-
1. 순차적 의사결정 문제
순서가 중요한 상황. 예: (샤워) 순서 바뀌면 안 됨 -
2. 보상
내가 잘하고 있는지를 간접적으로 알려주는 신호
강화학습의 목표는 결국 보상의 총합(누적 보상)을 최대화하는 것!
예: 자전거로 1m 갈 때마다 +1 보상을 받는 구조
보상의 3가지 특징
-
“어떻게”는 안 알려줌, “얼마나”만 알려줌
→ 높은 보상을 받으려면 스스로 시행착오를 통해 알아내야 함 -
스칼라
→ 보상은 하나의 수치로 표현됨 → 단일 목표만 설정 가능
→ 여러 요소가 있다면 가중치로 하나의 보상 값으로 합산해야 함 -
희소하고 지연됨
→ 어떤 행동에 대한 보상이 즉각적이지 않을 수도 있음
에이전트와 환경
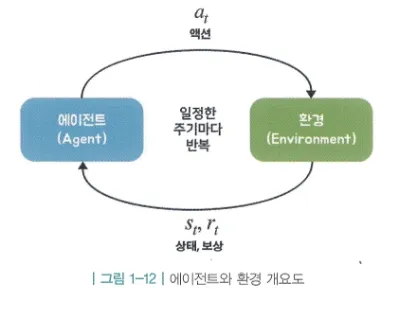
강화 학습에서는 학습 주체인 에이전트와 그것을 둘러싼 환경이 상호작용하며 학습이 진행됨.
- 에이전트: 자전거 타는 지윤이
- 환경: 자전거, 땅, 날씨 등 주변 모든 것
- 루프 구조: 상태 관찰 → 액션 결정 → 보상 받음 → 상태 변화
이 과정은 틱(tick) 또는 타임 스텝(time step) 단위로 반복된다.
에이전트가 하는 일 3단계

환경이 하는 일 4단계

에이전트와 환경이 한 번 상호작용하면 하나의 루프가 끝나는데, 이를 한 틱이 끝났다고 표현함.
또한 순차적 의사결정 문제에서는 시간의 흐름을 이산적으로 생각함. (시간의 단위 = 틱 or 타임 스텝)
강화학습의 위력
-
병렬성
→ 100명의 지윤이가 있다면, 각각의 시행착오를 공유해 빠르게 학습 가능 -
자가 학습
→ 시뮬레이션 환경에 던져두고 목표만 설정해두면 스스로 규칙을 깨우침
필요한 부분만 쓰고 싶은 대로 문체 바꾸면 되고, 내용 구조는 이대로 가져가도 좋다.
출처 - 바닥부터 배우는 강화 학습
