앤스컴 콰르텟(Anscombe's quarter)는 기술통계량은 유사하지만 분포나 그래프는 매우 다른 4개의 데이터셋이다.
각 데이터셋은 11개의 (x, y) 좌표로 이루어진다.
1973년, 통계학자인 프란시스 앤스컴이 데이터분석 전 1) 시각화의 중요성과 2) 특이치 및 주영향관측값의 영향을 보여주기 위해 만들었다.
목적 : "숫자 계산은 정확하지만, 그래프는 거칠다"는 통계학자들의 통념을 상쇄
🎯목표 설정
- Seaborn에서 제공되는 "anscombe" 데이터셋으로 앤스컴 콰르텟 이해하기
👩🏻💻이해 과정
목차
1. import pandas, numpy, seaborn
2. 데이터 로드
3. 데이터 형태 확인
4. 데이터 기본 정보 확인
5. 데이터 기술통계 구하기
5. 데이터셋 나누기
6. 데이터셋 별 기술통계, 상관계수, 빈도수 구하기
📍데이터 로드
# 1. 라이브러리 로드 import pandas as pd import numpy as np import seaborn as sns# 2. 데이터 로드 df = sns.load_dataset("anscombe")# 3. 데이터 형태 파악 df.head()

- 데이터는 (44, 3)으로 행이 44개, 열이 3개로 구성되어 있다.
- dataset의 범위는 I ~ IV 이며 각 11개의 데이터를 포함한다.📍데이터 정보
# 4. 기본 정보 확인 print(df.info())

- 총 44개의 데이터가 있으며, 결측치(NULL) 값은 없다.
- dataset은 object type이고, x와 y는 float64 type이다.📍데이터 기술통계
# 5. 기술 통계값 # 수치형 데이터의 기술 통계 print(df.describe())# 범주형 데이터의 기술 통계 print(df.describe(include="object"))
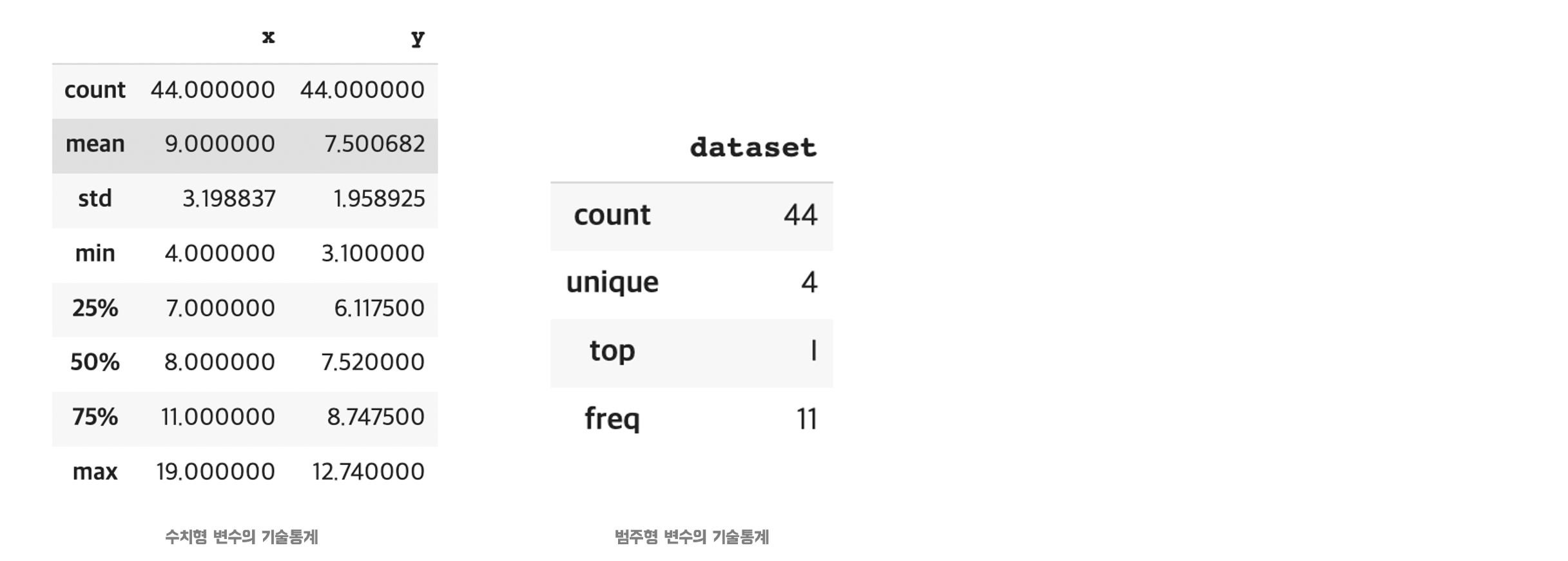
📍dataset 나누기
# dataset의 unique값 찾기 df["dataset"].unique() >> array(['I', 'II', 'III', 'IV'], dtype=object)# bool indexing df_1 = df[df["dataset"] == "I"] df_2 = df[df["dataset"] == "II"] df_3 = df[df["dataset"] == "III"] df_4 = df[df["dataset"] == "IV"]
📍dataset별 기술통계 비교
# 데이터셋 별 기술 통계 print(df_1.describe()) print(df_2.describe()) print(df_3.describe()) print(df_4.describe())그림5. 데이터셋 별 기술 통계값
1. COUNT, MEAN, std(표준편차), 4분위값은 거의 동일
2. MIN, MAX 값은 다르지만 각 기술 통계값은 동일📍dataset별 상관관계 비교
# 각 데이터셋에 대한 상관계수 df_1.corr() df_2.corr() df_3.corr() df_4.corr()그림6. 데이터셋 별 상관계수
1. 상관계수를 알아볼 때, 옵션을 지정하지 않으면 피어슨 상관계수가 사용된다.
- -1 ~ +1 사이의 값을 가짐
- +1에 가까우면 양의 상관을 가짐 (= x축 증가 시, y축 증가하는 경향 = 대각선에 가깝게 그려짐)
2. 데이터셋의 상관계수 값을 보면 알 수 있는 점
- 각 데이터셋 별로 대각선으로 같은 값을 가짐 (자기 자신과의 상관 관계)
- 4개의 데이터셋은 소수점 아래 세자리까지의 값이 모두 일치📍데이터 빈도수
# dataset의 빈도수 구하기 df["dataset"].value_counts()# dataset의 빈도수 normalize 비율 구하기 df["dataset"].value_counts(normalize=True)

📍그룹별 기술통계
# Groupby를 통한 데이터셋 별 기술통계 구하기 df.groupby("dataset").describe()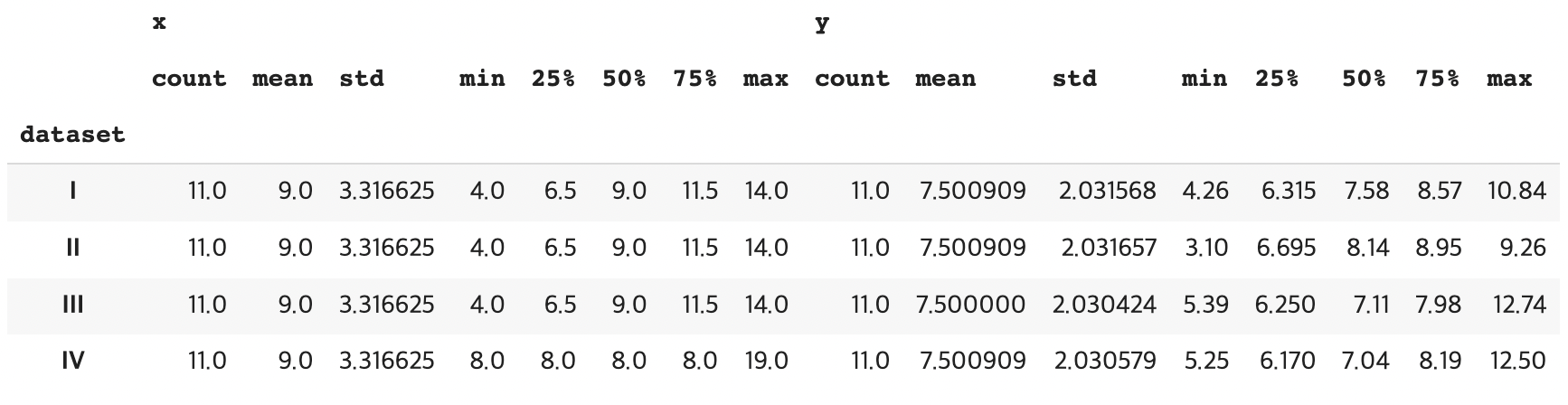
📍그룹별 상관계수
# Groupby를 통한 데이터셋 별 상관계수 구하기 df.groupby("dataset").corr()

🤔느낀점
여러 데이터 셋의 평균, 사분위값, 표준편차 등의 기술통계값이 동일한 값을 가져도 동일한 데이터가 아니라는 점을 기억해야겠다고 생각했다. Seaborn에서 가져온 데이터셋을 출력해보면 I ~ IV 의 (x, y) 는 동일하지 않다.
만약 각 데이터 셋의 (x, y) 리스트를 알지 못한 상태에서, 평균, 사분위값, 표준편차 등의 기술통계값이 동일함을 접한다면 유사한 그래프를 가진다고 생각했을 것이다.
앤스컴 콰르텟(Anscombe's quartet) 데이터 셋을 통해 데이터 분석 전 ! 1) 시각화의 중요성, 2) 특이치 및 주영향관측값의 영향을 잘 고려해야겠다고 느꼈다.
다음엔 위 데이터를 이용해 시각화를 해보아야겠다.

데이터 분린이 :)