🎯목표 설정
- Seaborn에서 제공되는 "anscombe" 데이터셋을 시각화하여 앤스컴 콰르텟 이해하기
👩🏻💻이해 과정
목차
1.import pandas, numpy, seaborn
2.load_dataset
3.seaborn 시각화
📍데이터 로드
import pandas as pd
import numpy as np
import seaborn as sns# 앤스컴 데이터셋 불러오기
df = sns.load_dataset("anscombe")# 데이터셋 구조 파악
df.shape
>>> (44, 3)📍Countplot 시각화
- 기본 값 :
count(count를 지정하지 않아도 자동 출력)- x 축 설정 : 범주형 데이터
sns.countplot(data=df, x="dataset")# 축 변경 sns.countplot(data=df, y="dataset")
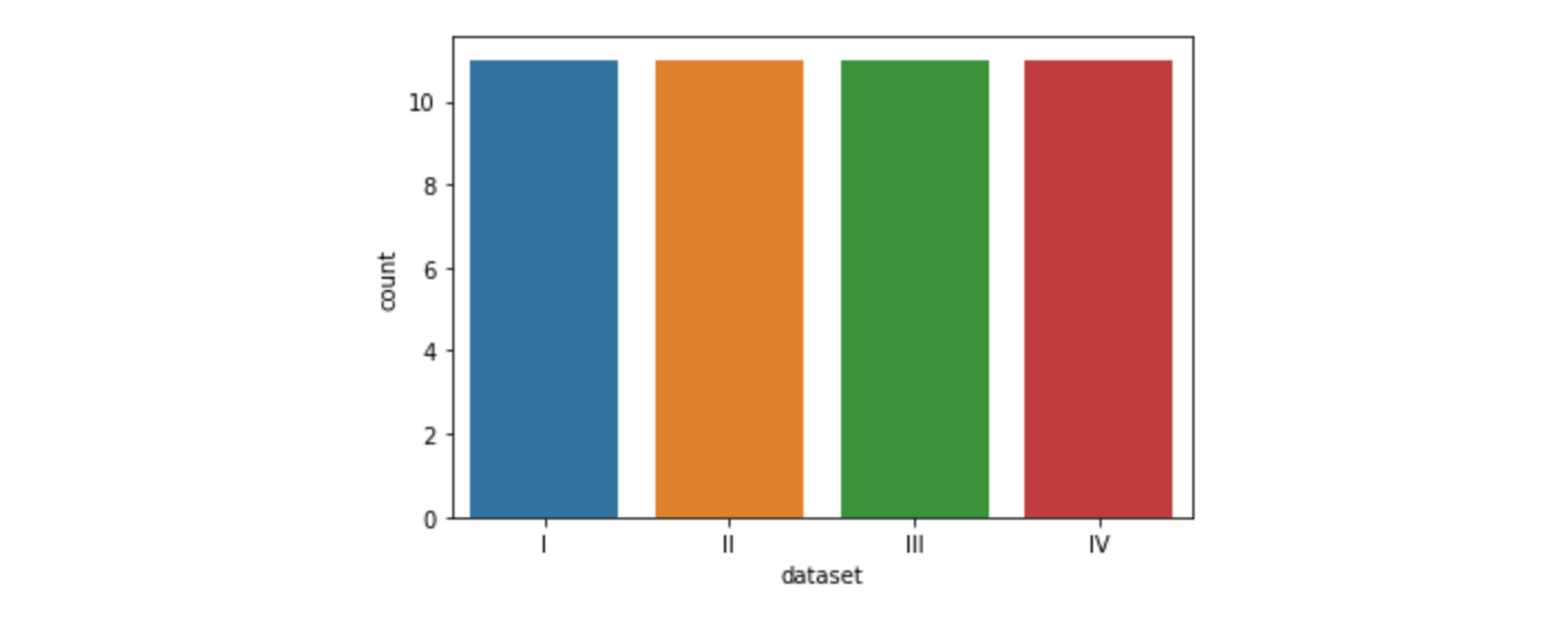
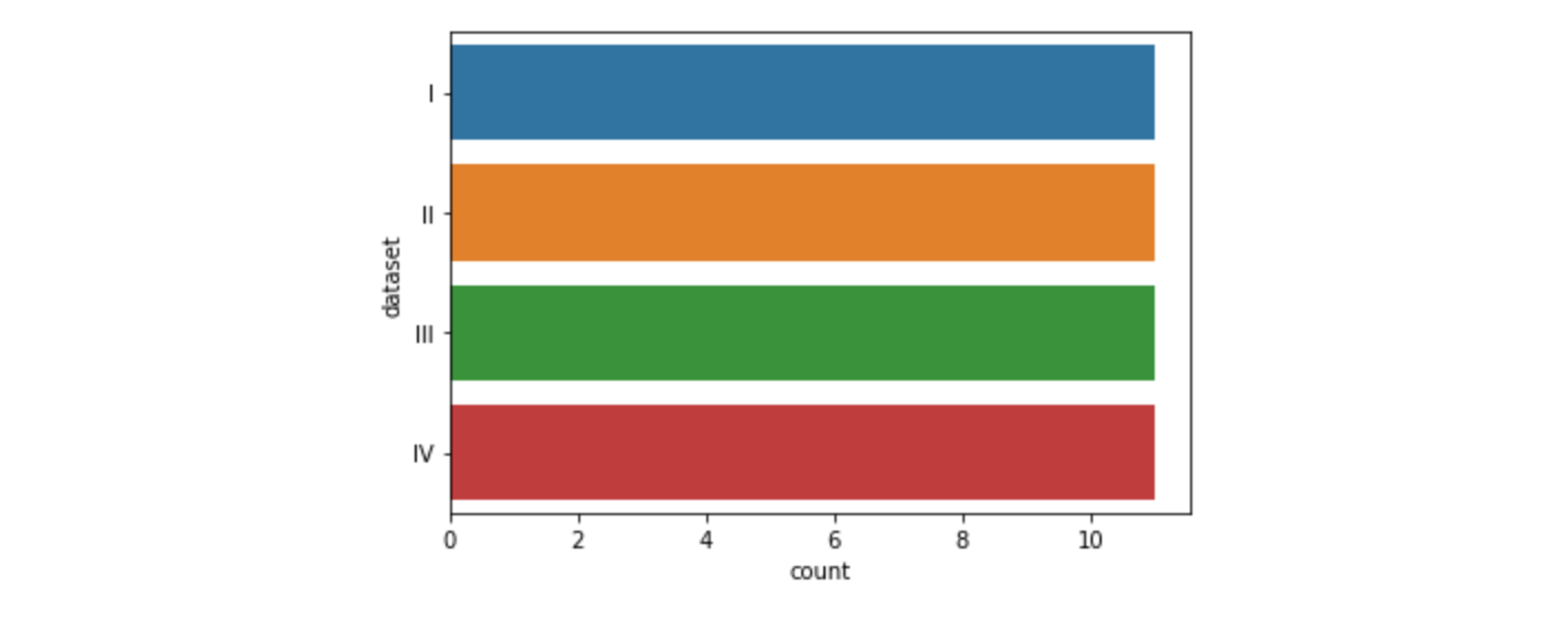
- 이산값을 나타내는 그래프 (각 범주에 속하는 데이터의 개수를 막대그래프로 나타냄)
- 학년별 인원 파악하는 그래프 등에 쓸 수 있음
📍Barplot 시각화
- 기본 값 :
평균(평균을 지정하지 않아도 자동 출력)- x 축 설정 : 범주형 데이터
- 검은 막대 : 신뢰구간
# 신뢰구간 자동 출력 sns.barplot(data=df, x="dataset", y="x") # y축 이름은 임의로 정함# 신뢰구간(ci) 제거 sns.barplot(data=df, x="dataset", y="x", ci=None)
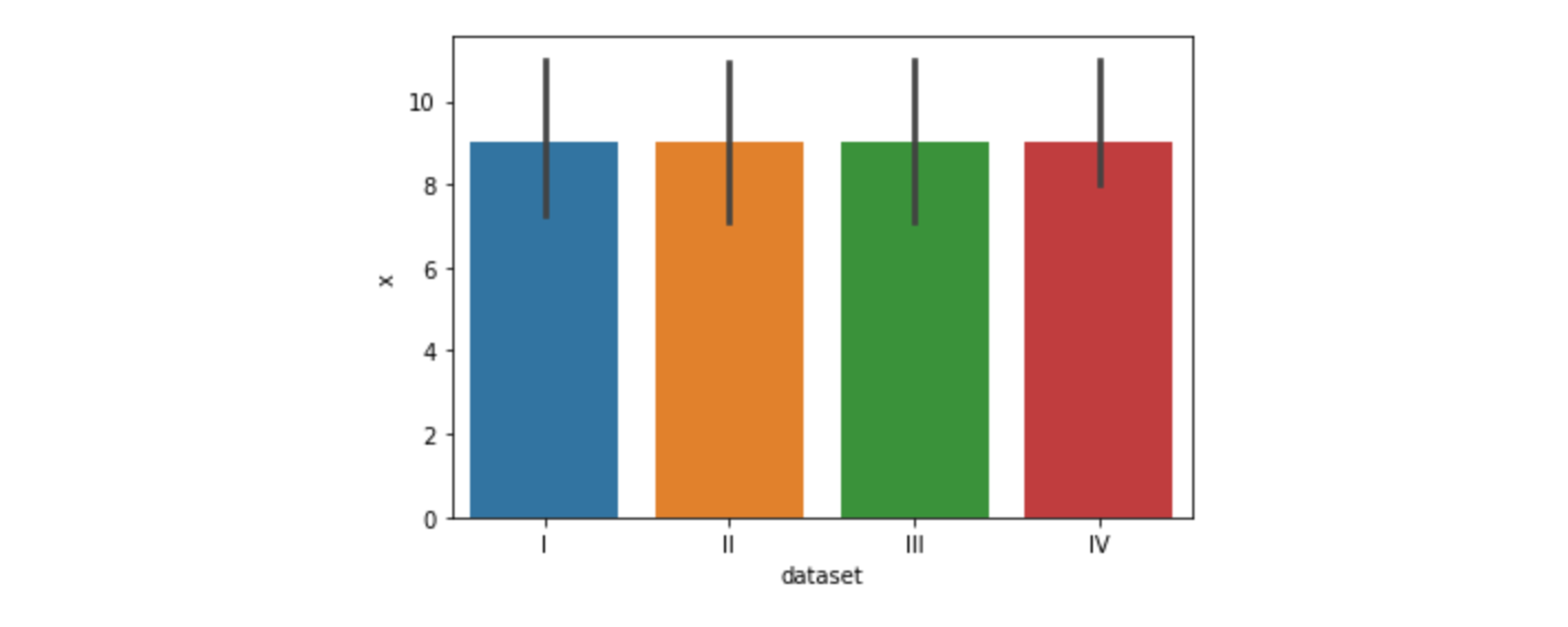
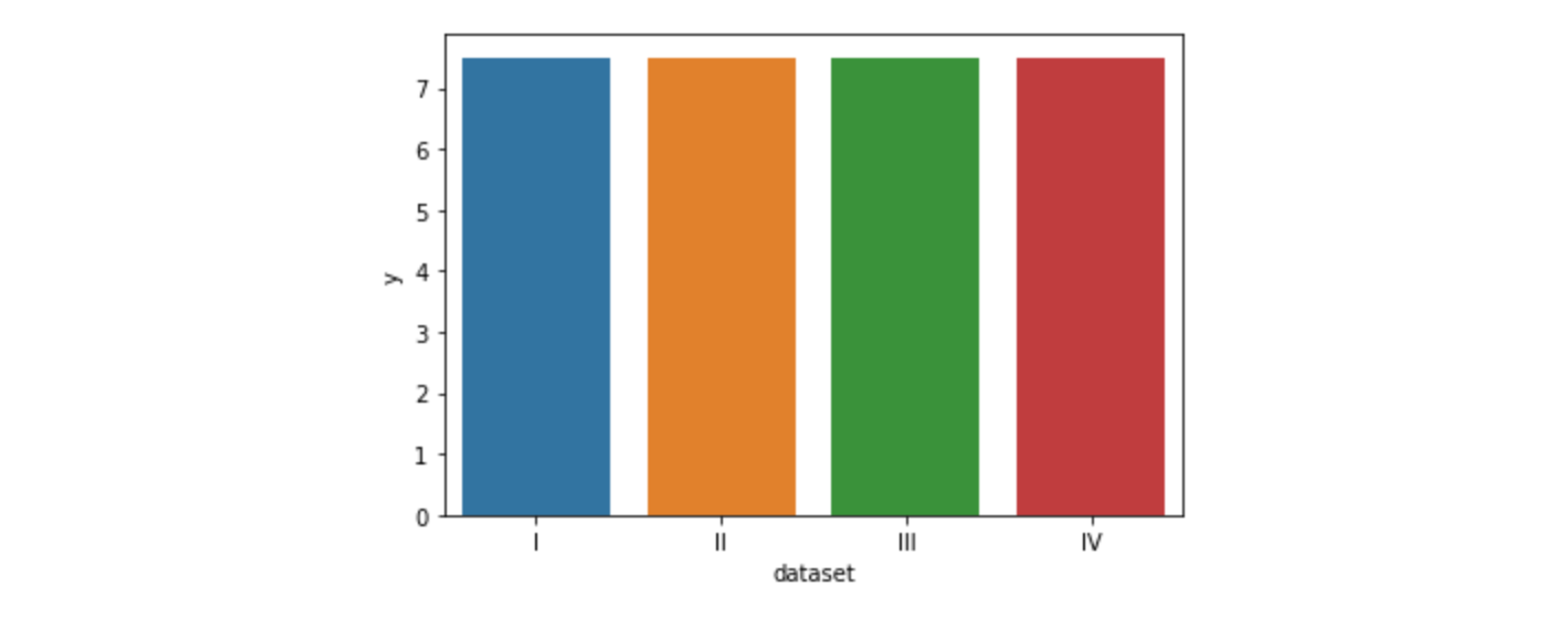
sns.barplot(data=df, x=“dataset”, y=“x”, ci=“sd”)에서sd: 표준편차n_boot: 표본을 몇 개 할 것인지 (defalt : 1000)- 큰 데이터를 시각화할 때,
ci넣으면 시간 오래 걸림 (표본 추출 과정 포함) - 대표값만 나타내기 때문에 자세한 표현이 어려움 (
boxplot이용하면 분포 확인 가능)
🔥 Groupby
# groupby 로 barplot의 x, y 평균 값 구하기 df.groupby("dataset")[["x", "y"]].mean()
dataset x y I 9.0 7.500909 II 9.0 7.500909 III 9.0 7.500000 IV 9.0 7.500909
📍Boxplot 시각화
- 기본 값 : 최솟값, 사분위값, 최댓값
- x 축 설정 : 범주형 데이터
- 검은 박스
♦︎: 이상치# 상자 수염 그림 sns.boxplot(data=df, x="dataset", y="y")
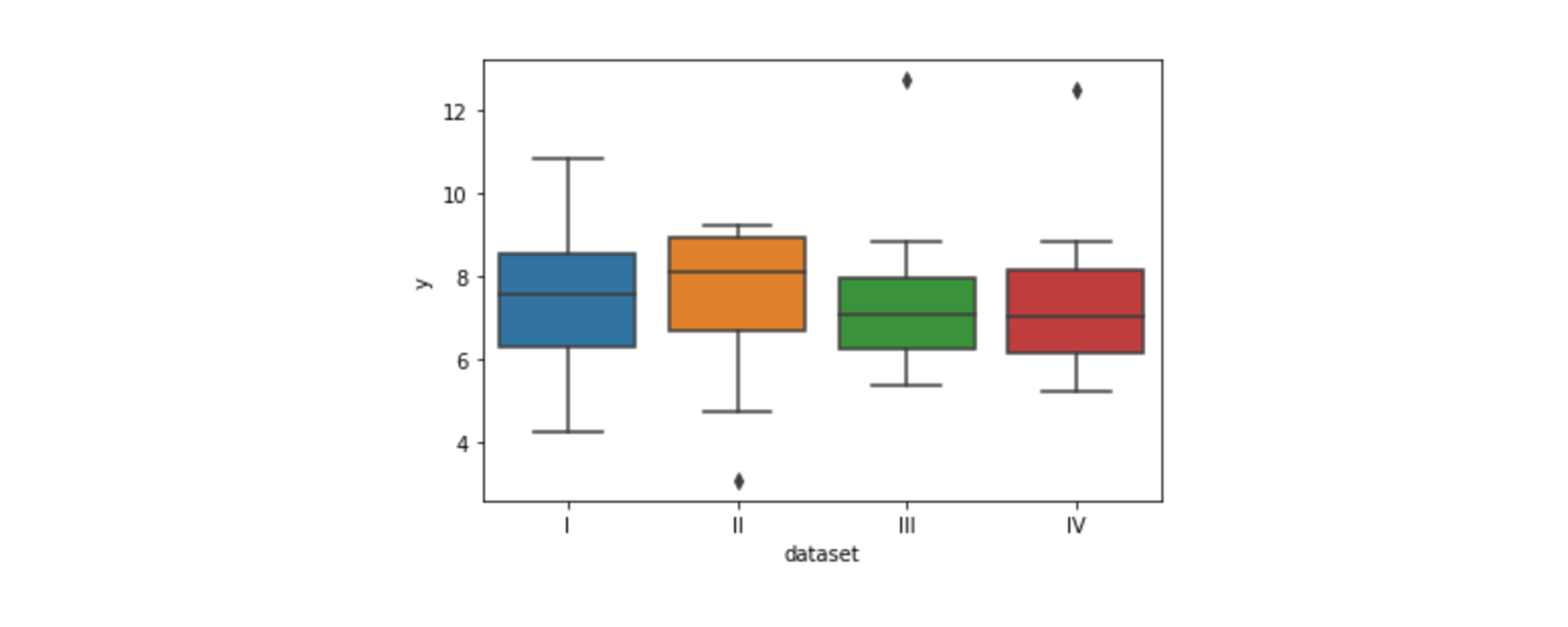
- 히스토그램과 비교 했을 때,
Robust함 - 중앙값은 잘 변하지 않음
- 값이 변해도 사분위수가 정해져있으면 변하지 않음
- 참고 1. Fig 8
- 참고 2. p17 부터
📍히스토그램 시각화
- 기본 값 : 데이터프레임의 (x, y)
# pandas에 내장되어있는 기능 df.hist()# bins : 막대 개수 (bins=1이면 막대 1개로 그림) df.hist(bins=1)
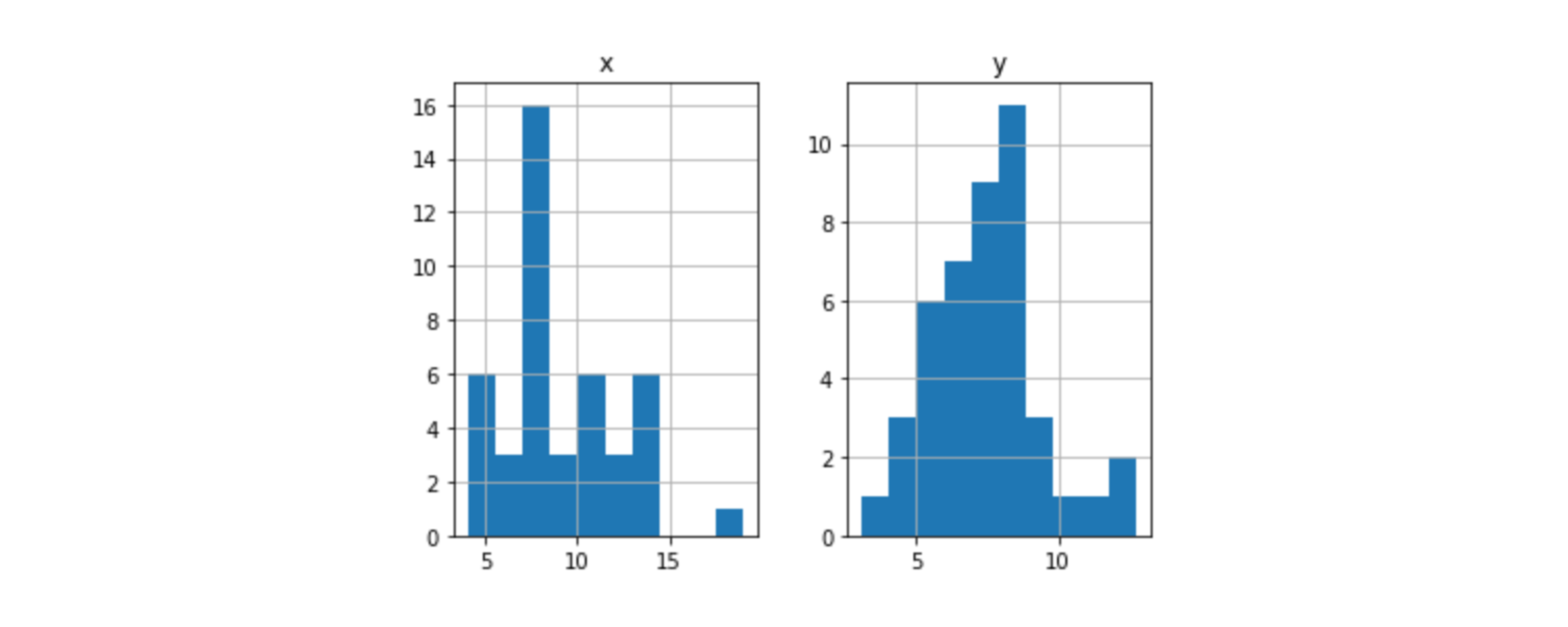
- 정해진 계급에 변량이 포함되어 있는 정도를 표로 나타낸 것
- 어떤 기준에 대한 수의 분포
📍Displot 시각화
- 기본 값 :
count(cout를 지정하지 않아도 자동 출력)히스토그램은 전체 데이터에 대한 그래프라면,Displot은 범주형 데이터별로 나누어 그래프를 그릴 수 있음# hue : 범주형 데이터를 색별로 나눔 (Group by 기능) # kde : 부드러운 곡선을 나타내줌 sns.displot(data=df, x="y", hue="dataset", kde=True)# col : 범주형에 따라 서브플롯을 만들어 줌 sns.displot(data=df, x="y", hue="dataset", kde=True, col="dataset")
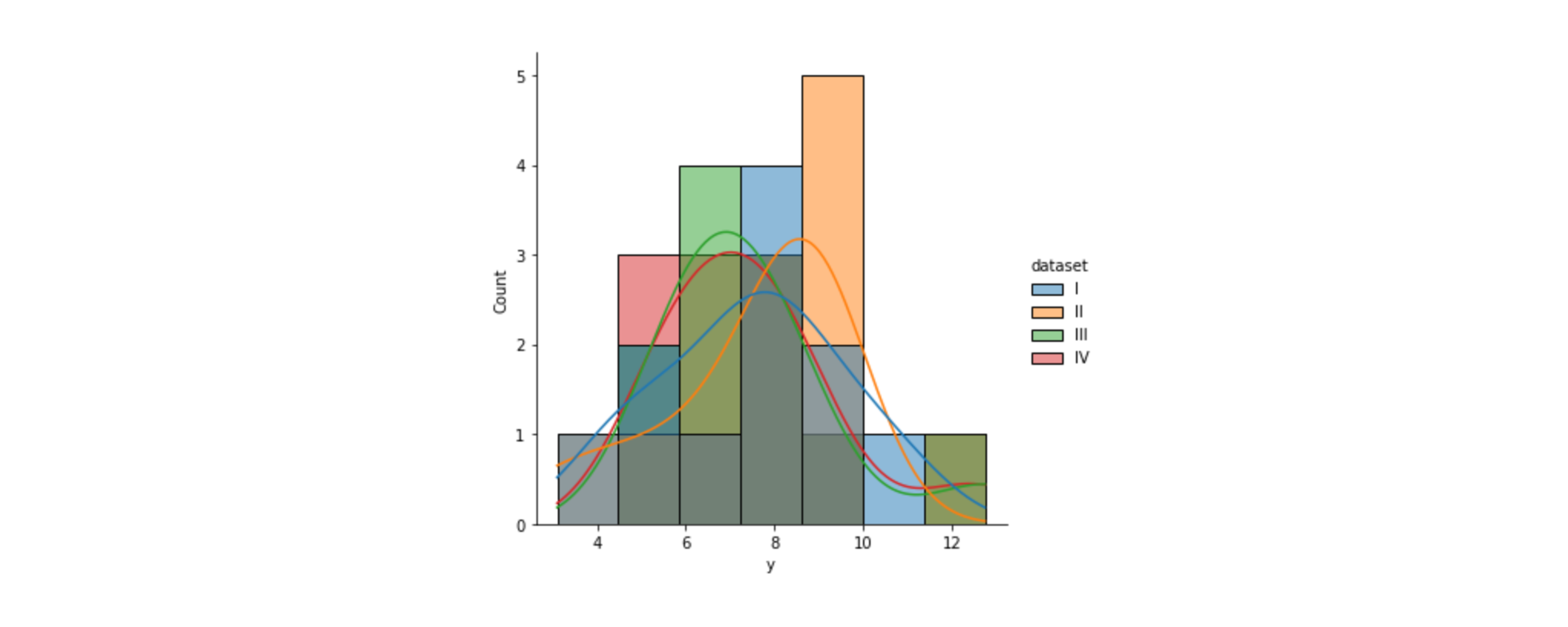
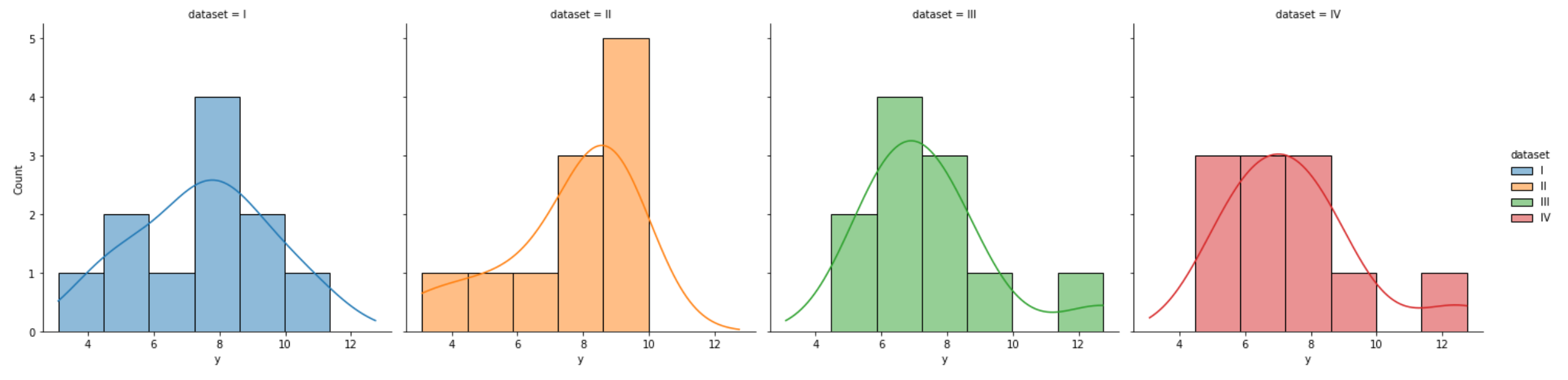
- 데이터셋에 대한
히스토그램확인 가능 히스토그램과kdeplot이 합쳐진 그래프 그릴 수 있음
📍Kdeplot 시각화
- 기본 값 :
Density(밀도를 지정하지 않아도 자동 출력)- 부드러운 곡선을 그려주는 도구
- 범주형 데이터에 따라 색 부여 가능(
hue)sns.kdeplot(data=df, x="y", hue="dataset")
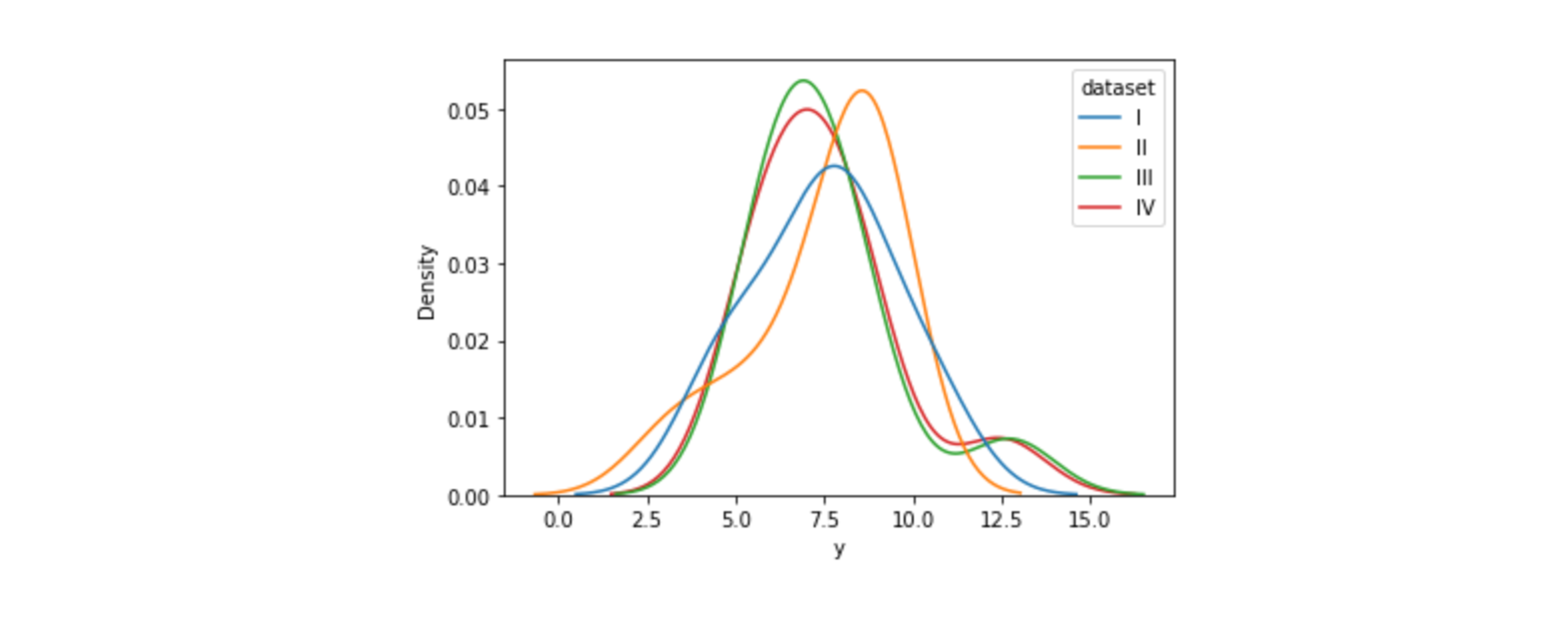
커널 밀도 추정(kernal density estimation)그래프히스토그램이 절대량(count)을 표현한다면kdeplot은 상대량(비율)을 시각화- 히스토그램과 마찬가지로 한 개 혹은 두 개의 변수에 대한 분포 그릴 수 있음
- 밀도 추정 그래프
📍Violinplot 시각화
kdeplot을 데칼코마니 하듯 마주보고 그린 값sns.violinplot(data=df, x="dataset", y="y")# 축 변경 sns.violinplot(data=df, x="dataset", y="y", orient="h")
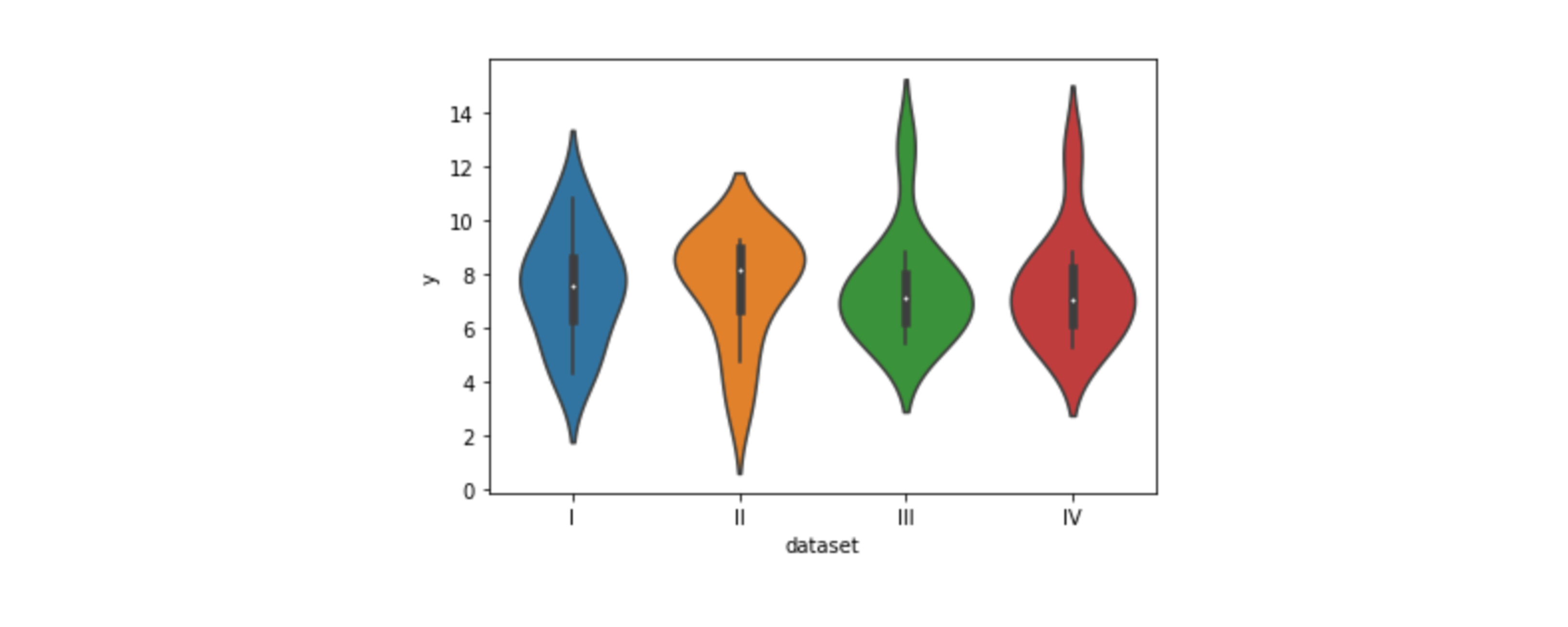
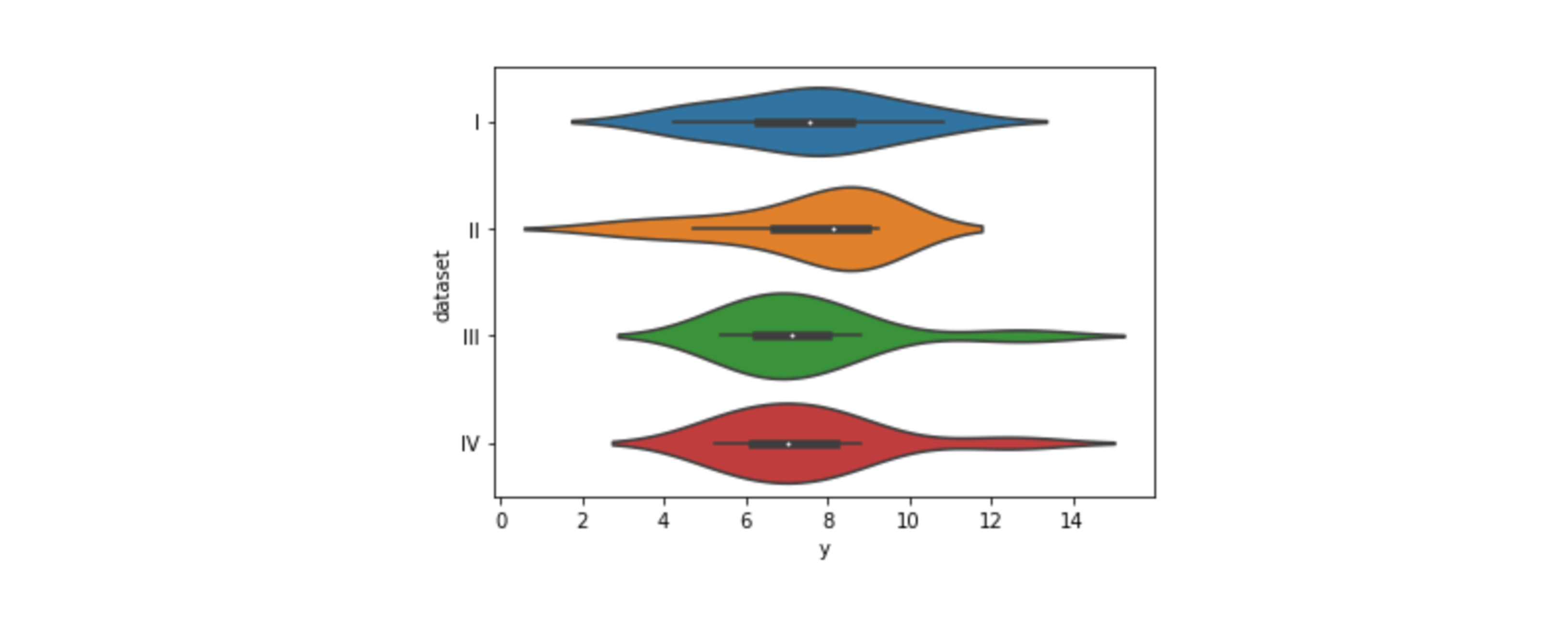
히스토그램의 밀도를 나타낸 것을 마주보고 그린 값kdeplot으로 그린 그래프를 x축을 기준으로 마주보고 그린 그래프- 어디에 많이 몰려있냐에 따라 그래프 모양이 달라짐
📍Scatterplot 시각화
x,y에 입력한 데이터로 그려지는 그래프- 범주형 데이터에 따라 색 부여 가능(
hue)sns.scatterplot(data=df, x="x", y="y", hue="dataset")
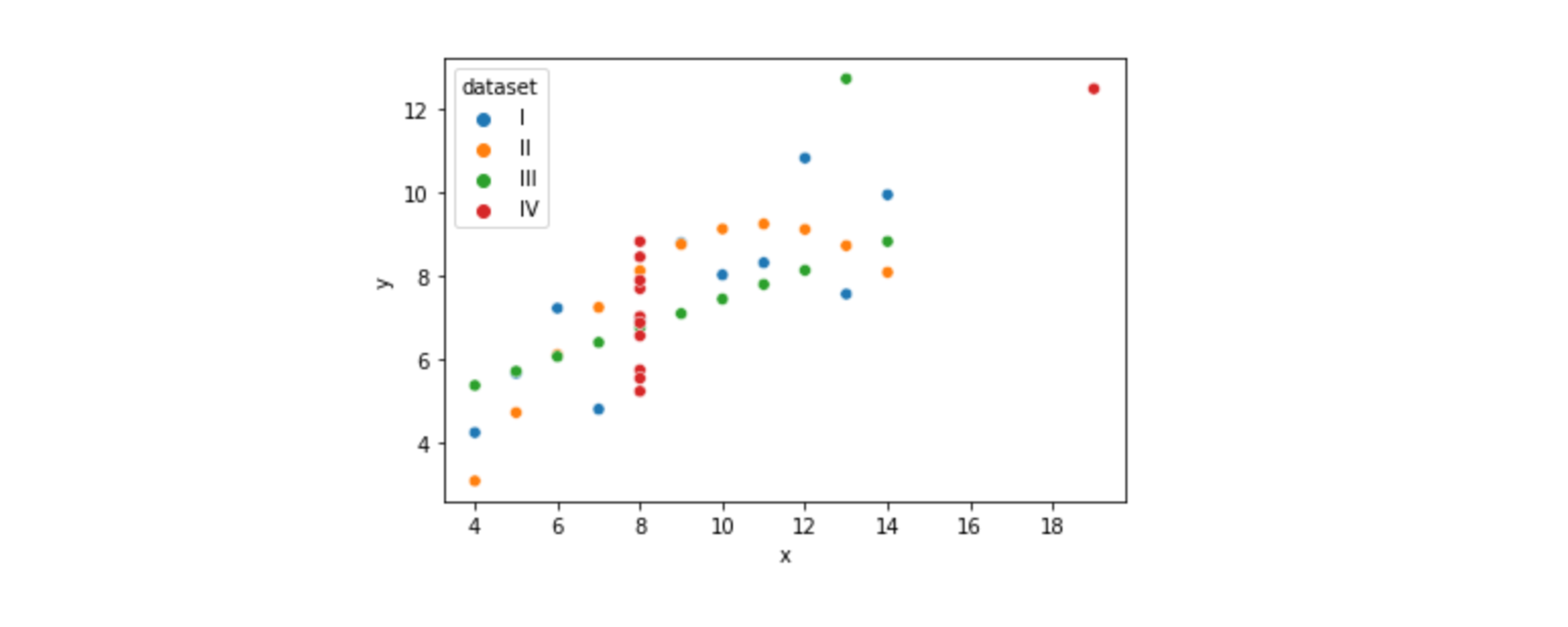
- 수치변수간의 분포를 확인하고자 할 때 사용
- 범주형 그래프에도 사용함 (권장 X)
📍Regplot 시각화
x,y에 입력한 데이터로 그려지는 그래프- 범주형 데이터에 따라 색 부여 불가능
- 반투명 영역 :
신뢰구간sns.regplot(data=df, x="x", y="y")
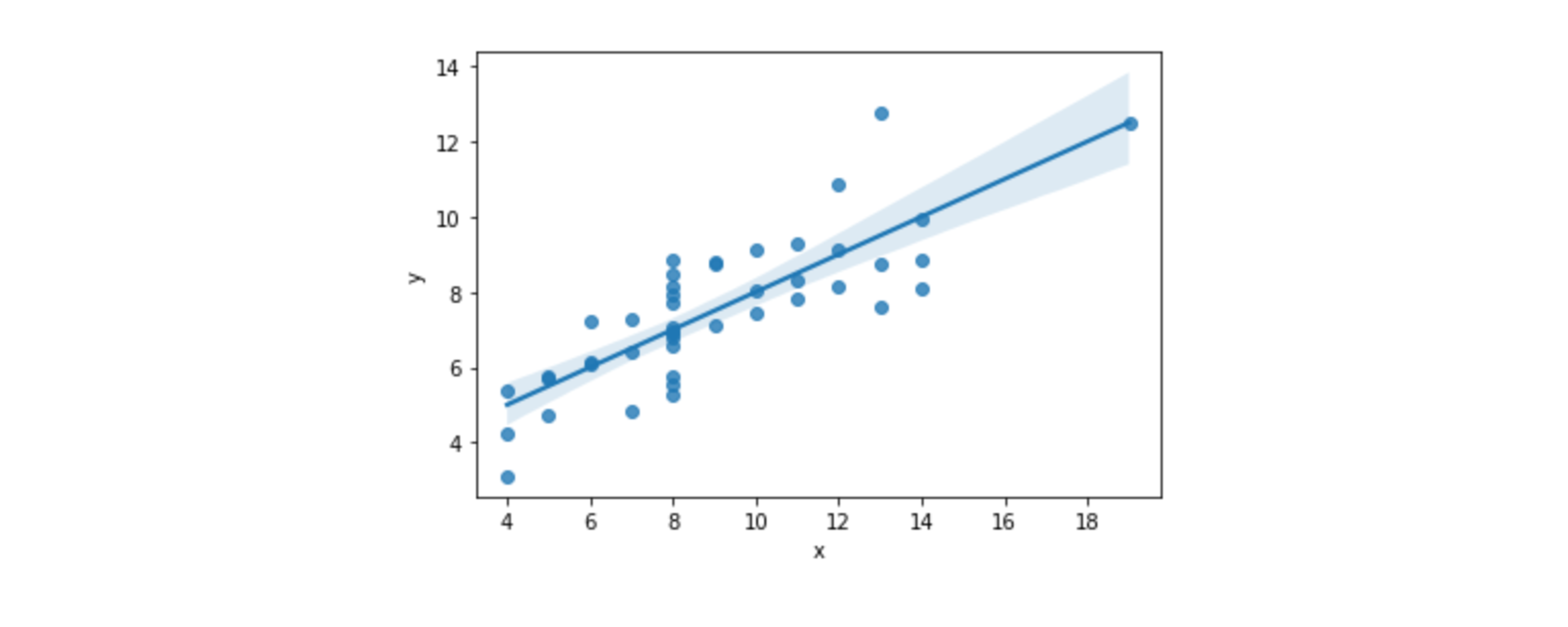
scatterplot에선hue지원하지만,regplot에선 지원 X- 데이터별 표현이 필요할 땐
lmplot사용
📍Lmplot 시각화
x,y에 입력한 데이터로 그려지는 그래프- 범주형 데이터에 따라 색 부여 가능(
hue)displot처럼 데이터별 분포 확인 가능- 반투명 영역 :
신뢰구간# col_wrap : 한 줄에 2개씩 정렬 sns.lmplot(data=df, x="x", y="y", hue="dataset", col="dataset", col_wrap=2)
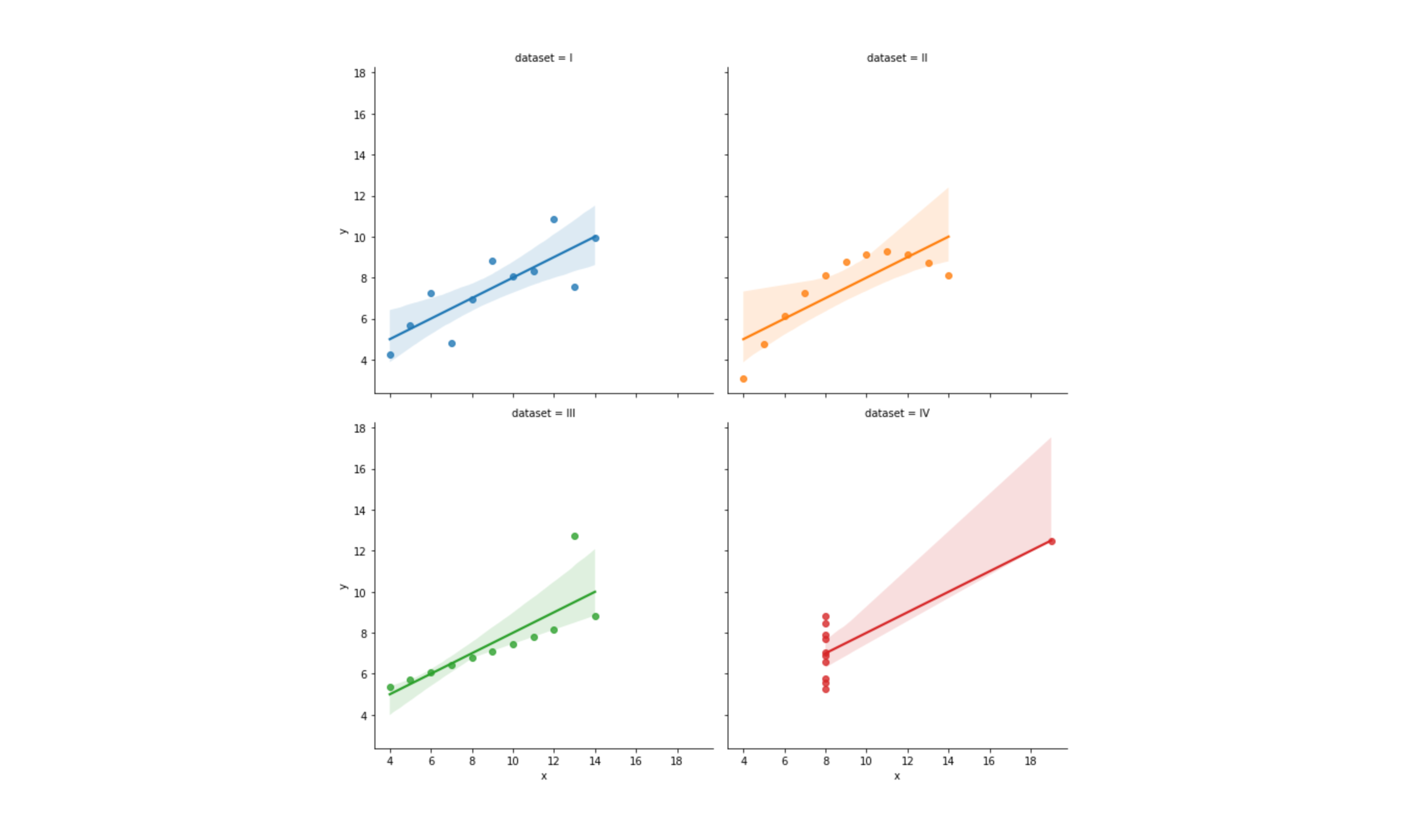
- 그래프
dataset = IV를 보면, 이상치 하나때문에 신뢰구간 넓게 형성됨 - 참고 1. Estimating regression fits
- 참고 2. p49 상관계수 관련
🤔느낀점
앤스컴 콰르텟(Anscombe's quartet) 데이터로 여러 그래프를 그려보았다. 실제로 데이터를 시각화 해보니, 범주형 데이터에선 어떤 그래프가 필요한지 수치형 데이터에선 어떤 그래프가 필요한지 조금 이해할 수 있었다.
하지만, 내가 다뤄본 데이터가 아직 하나여서 데이터 활용도에 대한 감을 높이기 위해선 여러 사례를 봐야할 것같다고 느꼈다!
주어진 데이터를 효율적으로 사용하기 위해 ! 오늘보다 더 발전한 내일을 위해 ! 모르는 것은 해결될 때까지 찾아보고 내 것으로 만들 수 있도록 노력해야겠다 !! 🔥
만약, 내게 지금 당장 공정 데이터가 주어진다면? 어떤 그래프를 그리면 좋을 지 생각해보았다. 공정 데이터가 단순한다면 scatterplot 이나 lmplot 으로 입력변수에 따른 결과치의 관계를 알아보지 않을까??
이 부분에 대해선 공부를 하면서 더 고민해봐야겠다!

데이터 분린이 :)