ResNet(Residual Network)
마이크로소프트에서 개발한 알고리즘으로, GoogleLeNet은 22개 층으로 구성됐지만, 7배 깊은 층, 152개를 사용하여 깊은 네트워크를 사용한 층을 갖는다.
단순히 네트워크 깊이만 깊어지면 성능이 좋아질까?
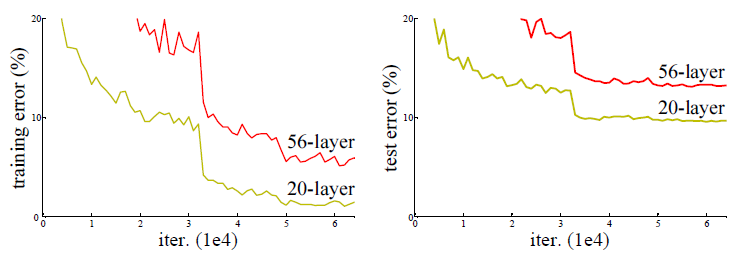
ResNet의 논문에는 56층의 네트워크가 20층의 네트워크보다 성능이 안좋은 것을 볼 수 있다.
Training 에서도, Test 에서도 성능이 좋지 않았기 때문에 우리는 이것이 Overfitting 때문이 아님을 알 수 있습니다.
무조건 네트워크가 깊다해서 성능이 좋아지는 것은 아니다. 그렇다면 어떻게 깊은 층을 구성하여 성능을 높였을까?
Residual block
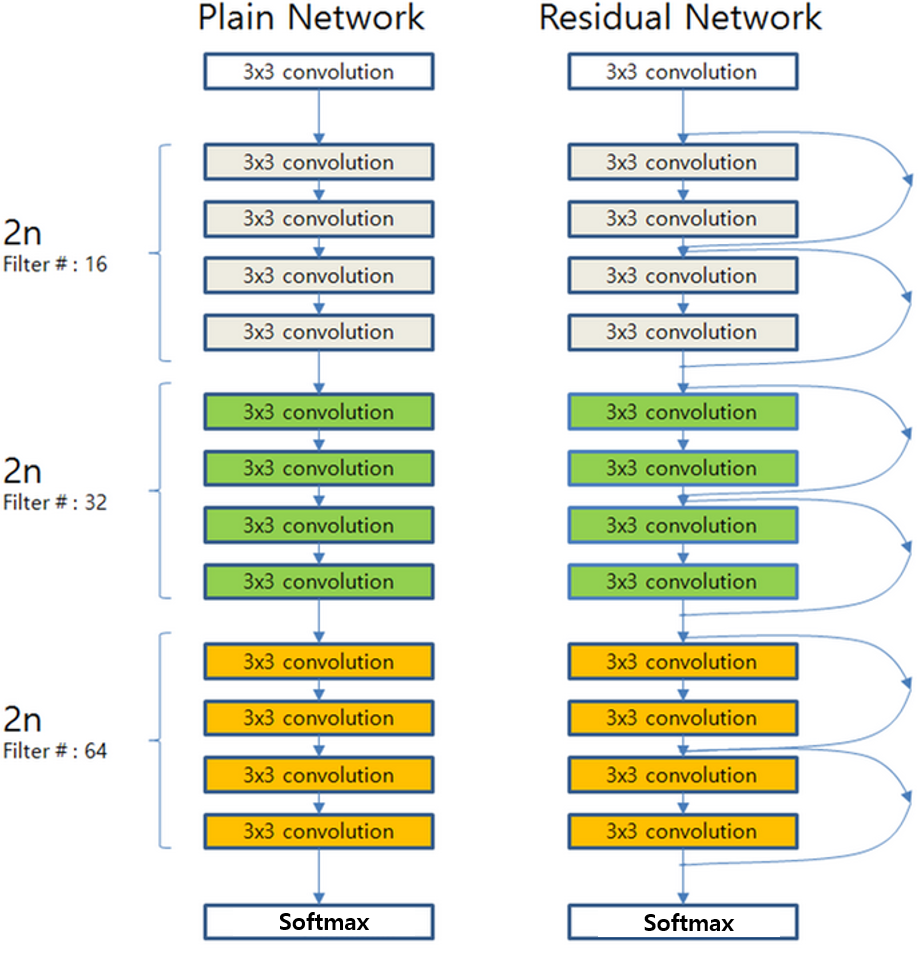
위의 그림에서도 볼 수 있듯이, Plain Network가 단순히 Convolution 연산을 쌓는다면, ResNet은 Block이 쌓인 구조를 가지고 있고, Block 단위로(Residual Block이라고 부름) Parameter를 전달하기 전에 이전의 값을 더하는 방식을 취한다.
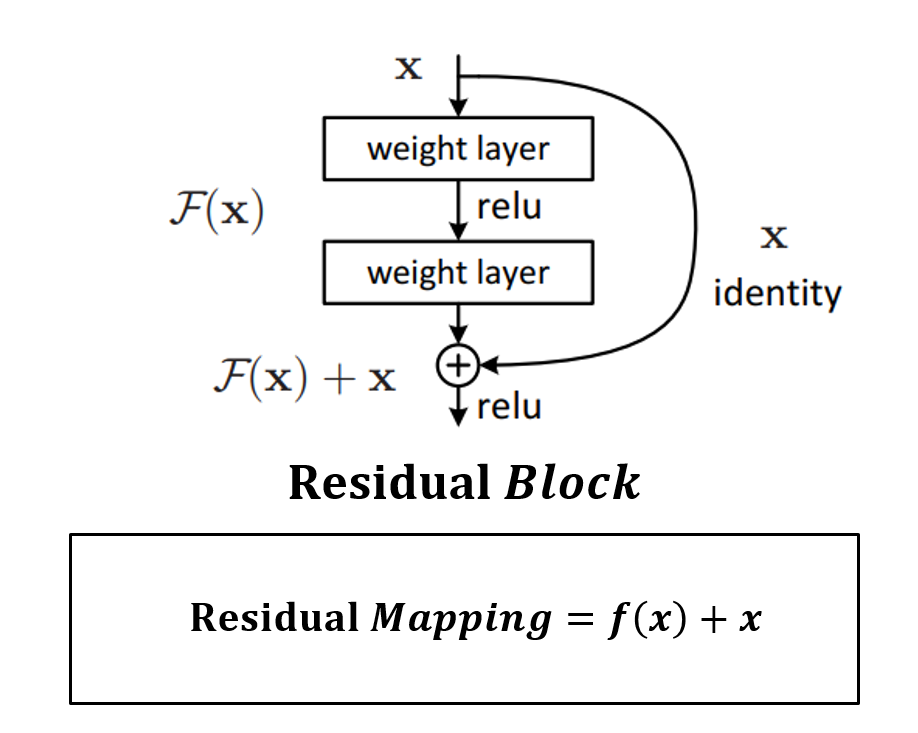
ResNet을 구성하는 Residual Block의 구조는 위와 같다. weight layer를 통과한 f(x)와 weight layer를 통과하지 않은 x의 합을 논문에서는 Residual Mapping이라고 한다.
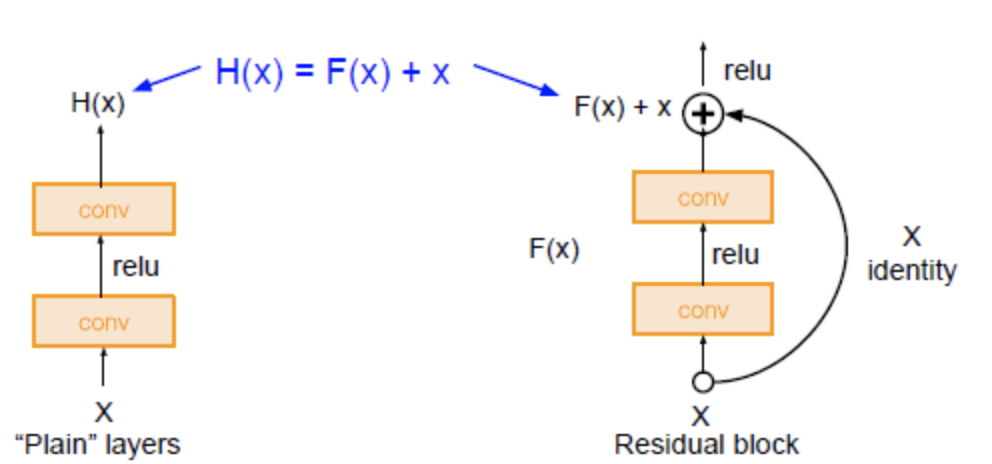
Residual Block을 plain layer과 비교하여 설명하자면, plain layer는 동일한 연산 f(x)를 수행하고 난 뒤 Input x를 더해주지 않지만, residual block에서는 동일한 연산 f(x)를 수행하고 난 뒤 Input x를 더해준다.
즉, plain layer와는 다르게 residual block에는 skip connection이 존재한다. (그림의 곡선 화살표 부분 Skip connection은 하나의 layer의 output을 몇 개의 layer를 건너띄고 다음 layer의 input에 추가되는 것을 의미한다.)
skip connection을 사용하게 되면 각각의 layer가 작은 정보들을 추가적으로 학습하도록 한다.(= 각각의 layer가 배워야 하는 정보량을 축소시킴)
