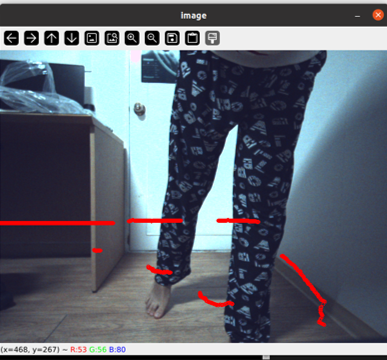
- 예쁜 나의 바지와 실험 결과
지난번 이론편에 이어서 실습편을 하려고 한다.
(이론편: https://velog.io/@jinhoyoho/%EC%9E%90%EC%9C%A8%EC%A3%BC%ED%96%89Camera-LiDAR-Calibration%EC%9D%B4%EB%A1%A0)
실습 코드는 github에 올라와있다.
https://github.com/jinhoyoho/rplidar_camera_calibration
실험 환경은 다음과 같다.
-
Ubuntu 20.04
-
ROS1 noetic
-
Intel Realsense D405

-
RPLiDAR S2M1-R2 (2D LiDAR)

-
kaggle notebook (Deep Learning)
-
카메라 위치 설정

Calibration의 결과를 명확하게 보고 싶어서 가깝게 붙이는 것이 아닌, 위 사진과 같이 위치시켰다.
(카메라와 라이다는 Perception study의 팀장님이신 석균님의 도움을 받았다!)
1. 목표 설정과 좌표계
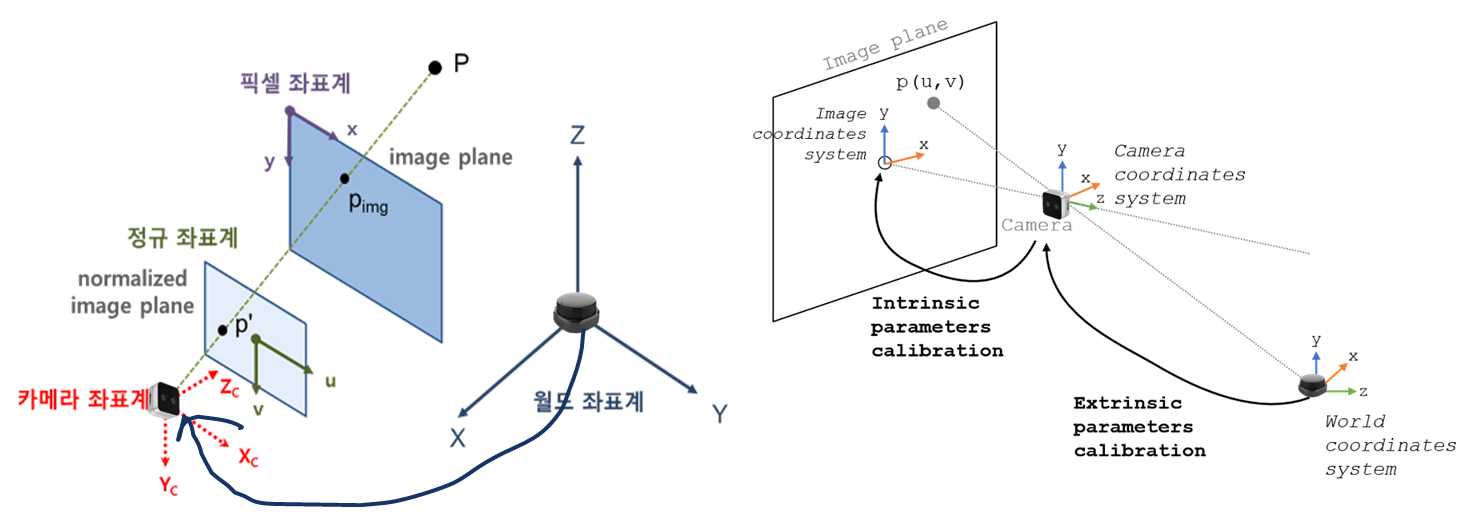
우리의 목적은 LiDAR의 점들을 이미지에 투영시키는 것이다. 즉, LiDAR의 월드 좌표를 이미지 좌표로 바꾸는 것이다.
이를 위해서는 LiDAR의 월드 좌표계를 카메라 좌표계와 일치시킨다. 이후에 카메라 좌표계를 이미지 좌표에 투영시킨다.

위 과정들을 식으로 표현하면 이와 같다. 우리가 구해야 할 것은 빨간색 네모, 즉 카메라의 내부 파라미터(Intrinsic Parameter)와 카메라와 LiDAR 사이의 외부 파라미터(Extrinsic Parameter)를 구하면 된다.
먼저 내부 파라미터부터 구해보자.
2. Intrinsic Parameter
내부 파라미터는 주점, 비대칭 계수, 초점거리 등 카메라 내부 요소들을 말한다. 카메라마다 내부 요소들이 다르기 때문에 같은 실험이라도 카메라에 따라서 다른 결과가 나올 수 있다. 카메라 내부 파라미터를 통한 정규 이미지 좌표계(Normalized Image coordinate)을 통해서 이 문제를 해결할 수 있다.
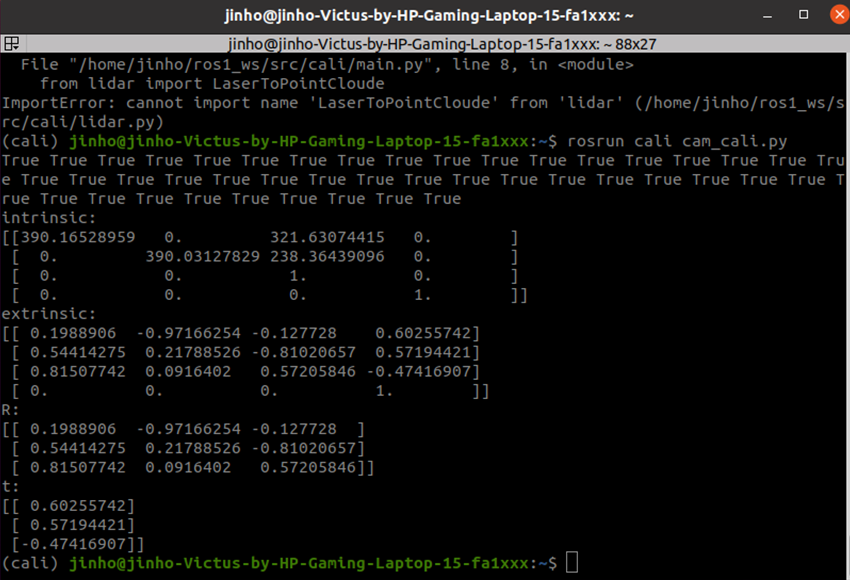
거두절미하고 내부 파라미터를 구해보자. 나는 OpenCV를 이용해서 내부 파라미터를 구했다.
우선 적당한 checkerboard를 구글에서 찾은 후 인쇄해준다.

OpenCV의 findChessboardCorners, cornerSubPix, calibrateCamera 코드를 통해서 checkerboard의 코너들을 검색하고 카메라의 내부 파라미터들을 계산한다.
코너를 찾은 결과를 시각화하면 다음과 같이 나온다.

이러한 checkerboard를 다양한 각도에서 여러 장 찍어야 정확한 값이 나온다.

3. 카메라와 LiDAR 간의 외부 파라미터 구하기
내부 파라미터를 구했으니 외부 파라미터 값을 구해야 한다.
구하는 방법은 여러가지가 있다. 나는 그중에서도 가장 원시적인 방법을 사용하였다. 바로 점들의 대응 위치를 직접 구하기.,..!
- LiDAR와 카메라 작동시키기
우선 RPLiDAR의 package를 다운 받고 roslaunch를 통해 작동시켜준다.
(RPLiDAR github: https://github.com/Slamtec/rplidar_ros)
카메라는 그냥 OpenCV를 이용해서 창을 띄워줬다.

- LiDAR와 이미지 간의 좌표 대응점 찾기
LiDAR의 월드 좌표를 아무 곳이나 찾는다. 그리고 이미지에서 이에 대응되는 픽셀 좌표를 찾는다. 예를 들면 다음과 같다.

Rviz 상에서 혼자 튀어나온 점이 있는데, 이는 이미지에서 책상의 다리 부분에 속한다. 이 점에 해당하는 LiDAR의 월드 좌표는 (1, 2, 0)고 이미지 픽셀좌표는 (325, 127)이다.
이런 식으로 대응하는 점들을 여러개 찾아준다.
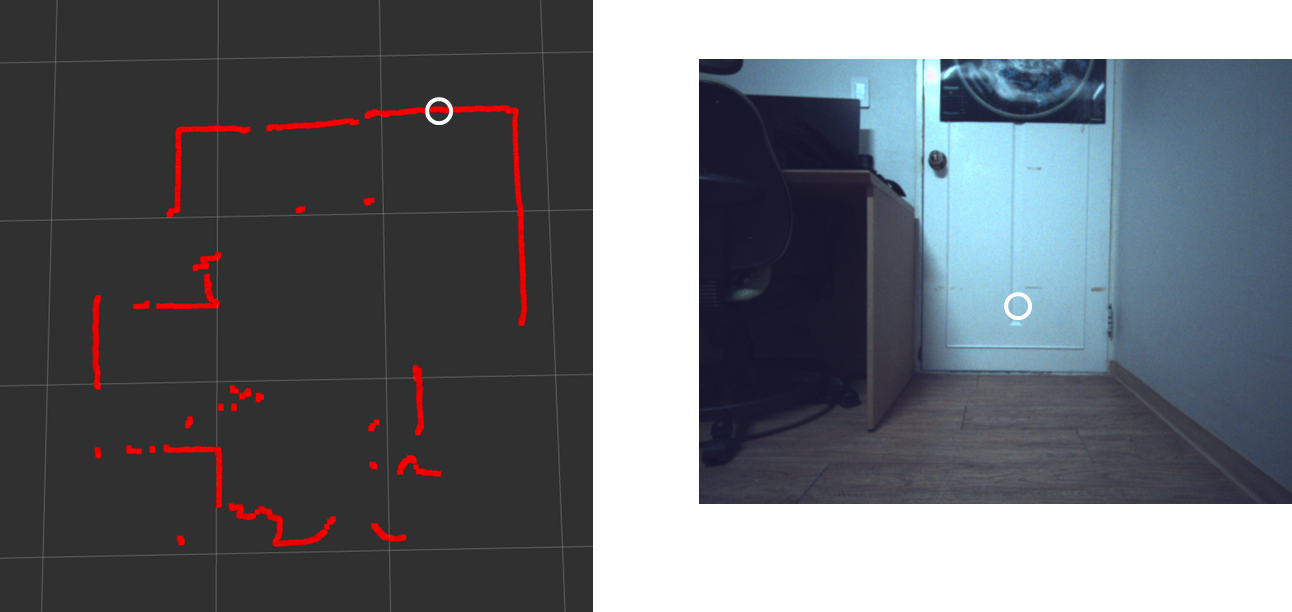

이런 식의 과정은 큰 단점이 있다. 직접 구하다보니 완전 정확하지는 않다는 것이다. 따라서 점의 위치가 조금만 다르거나 카메라, LiDAR의 위치가 틀어지게 되면 완전히 다른 값들이 나온다.
# 2D-image coordination
points_2D = np.array([
(155, 330),
(210, 280),
(320, 280),
(415, 280),
], dtype="double")
# 3D-World coordinations correspond to 2D-image coordinations
points_3D = np.array([
(-1.0732, -0.17268, 0),
(-1.6316, -0.17515, 0),
(-1.6426, 0.39314, 0),
(-1.6522, 0.68096, 0)
], dtype="double")순서에 맞게 대응되는 점을 나열한다. 점이 많으면 많을수록 견고해진다.
이 점들을 solvePnP함수를 통해서 외부 파라미터를 구해준다.
# using solvePnP to calculate R, t
retval, rvec, tvec = cv2.solvePnP(points_3D, points_2D, self.cameraMatrix,
self.dist_coeffs, rvec=None, tvec=None, useExtrinsicGuess=None, flags=None)solvePnP는 Perspective-n-Point로 카메라의 위치 및 방향을 구할 때 사용하는 함수이다.
최종적으로 내부와 외부 모두 파라미터를 구할 수 있다.
4. 구한 점 이미지에 투영시키기
최종적으로 cv2.projectPoints를 통해서 world 좌표를 이미지 좌표에 투영시켜준다. 구한 점들을 cv2.circle을 통해서 이미지에 시각화해준다.
img_points, jacobian = cv2.projectPoints(
objPoints, cam_cali.rvec, cam_cali.tvec, cam_cali.cameraMatrix,
np.array([0, 0, 0, 0], dtype=float))
for i in range(len(img_points)):
# Express Lidar points to image using circle
cv2.circle(frame, (int(img_points[i][0][0]), int(
img_points[i][0][1])), 3, (0, 0, 255), 1)- 라이다를 투영시킨 결과
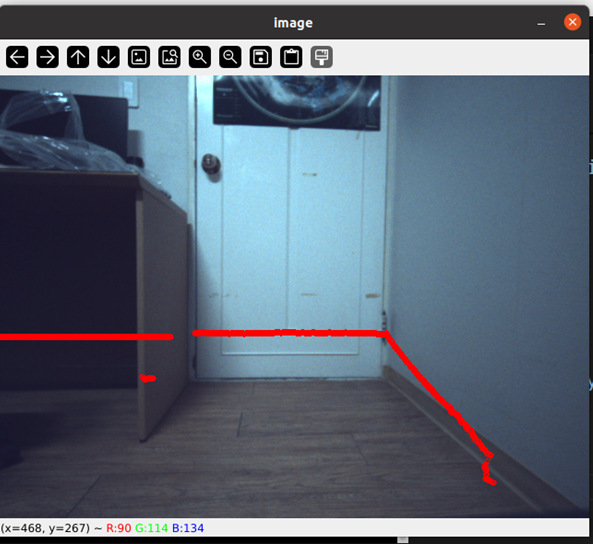
그러면 위와 같이 LiDAR와 카메라의 fusion을 완성할 수 있다!
주변 지형지물이 없어서 잘 한건지 못 한건지 확인이 어렵다. 때문에 앞에 서서 결과를 확인했다.
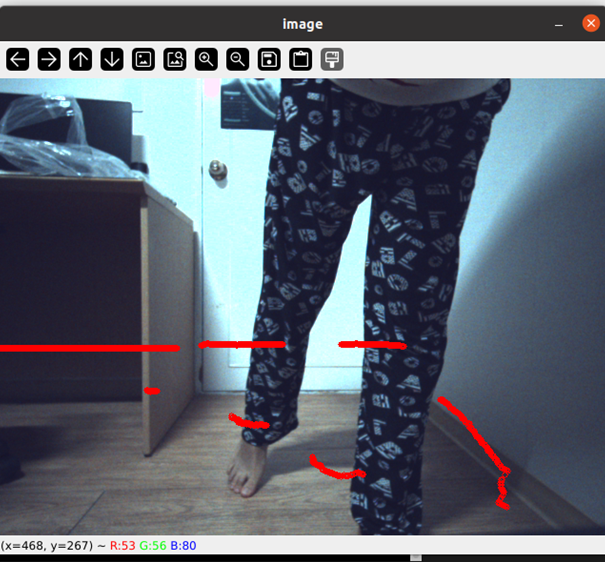
이런식으로 잘 되는 것을 확인할 수 있다!
여담이지만 집에서 잠옷입고 편하게 작업하다가 실험 결과를 보고 너무 기뻐서 그냥 이대로 찍어버렸다,...^^~
처음에 얼핏 봤을때는 결과가 이상하다고 생각했다. solvePnP의 점들을 직접 구하다보니 여러가지 시행착오가 있었기 때문이다. 그래서 점을 잘못 입력한건가 싶었다. 곰곰히 생각한 결과, LiDAR와 카메라의 위치 관계를 생각하면 괜찮은 결과인 것 같다.
- LiDAR와 카메라의 위치 관계
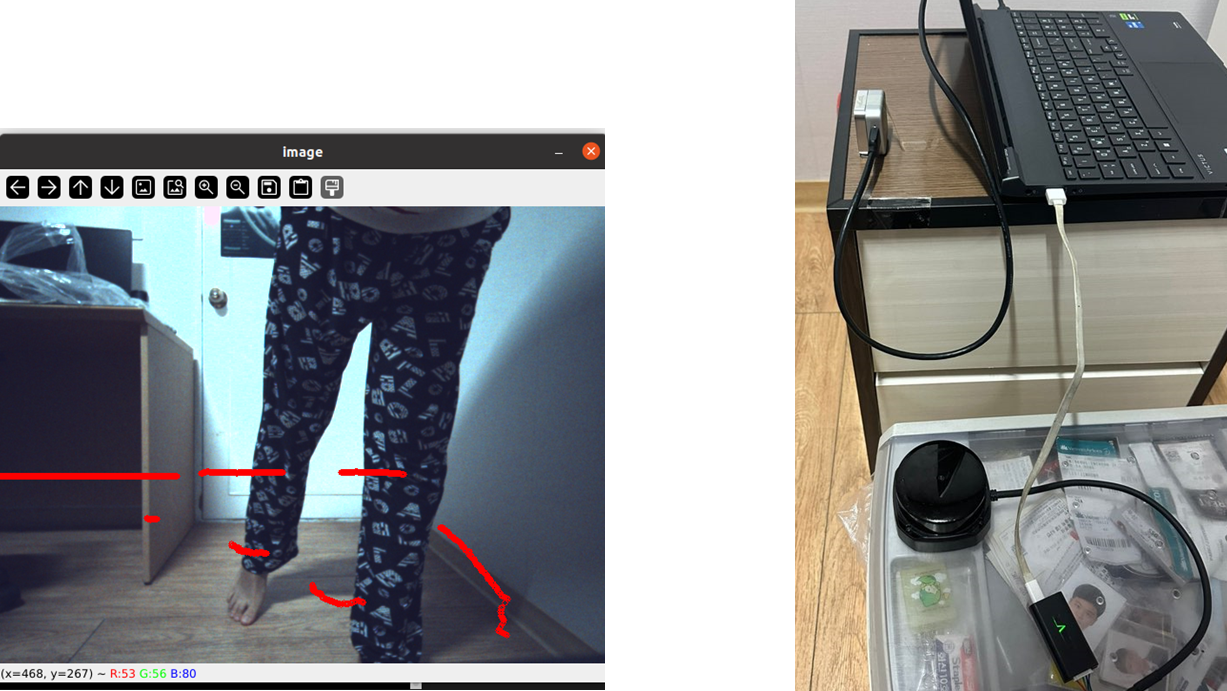
LiDAR는 카메라보다 왼쪽 아래에서 비추고 있기 때문에 해당 결과가 맞다고 생각한다.
5. Deep Learning
이미지를 딥러닝인 yolo 결과 이미지로 대체하기만 하면 쉬운 작업이다. 시간도 없었고 딥러닝 결과가 썩 좋지 않아서 이 부분은 빼기로 했다. 그래도 진행한 과정을 설명하려고 한다.
-
kaggle notebook
학습은 google colab보단 kaggle notebook을 이용했다. 16GB인 Tesla T4를 2대나 이용할 수 있고 colab보다 이용시간도 긴 것으로 알고 있다. (colab은 T4 1대) 따라서 인공지능 학습은 kaggle notebook을 추천한다! -
Yolov8 학습
input에 이미지를 넣고 단순히 터미널 명령어만 실행하면 yolo는 학습시킬 수 있다.
validation set에 대해서 예측한 결과

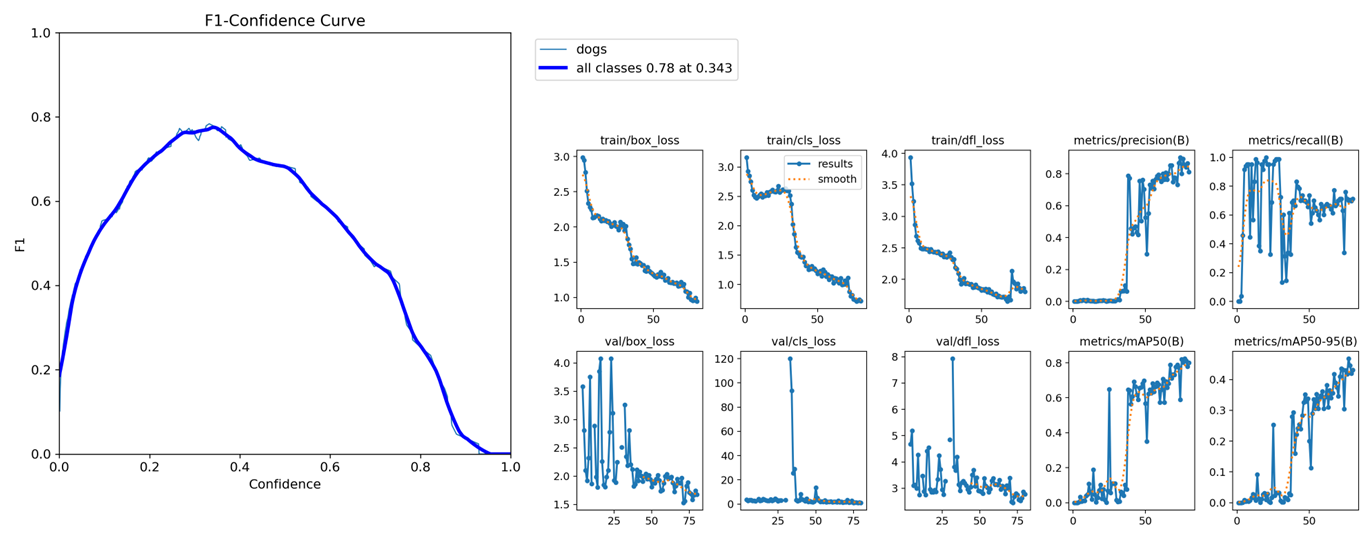
F1 score와 loss graph
원래는 강아지를 판별해서 몇 미터에서 접근중인지 알려주는 프로젝트를 하려 했다. 하지만 딥러닝이 결과가 아쉬워서 fusion을 했다는 것에 의의를 두었다. 역시 딥러닝은 데이터가 중요한 것 같다.
아무튼 이런식으로 객체 인식 이미지를 같이 fusion한다면 early fusion이 가능하다!
느낀점
시간이 좀 더 있었다면 어땠을까 하는 아쉬움이 남는다.
가장 먼저 시간을 많이 뺐긴 것은 RPLiDAR 연결이다. 석균님이 LiDAR와 더불어 케이블도 주셨는데 micro 5pin이 아닌 그냥 5pin을 주셨다.,,.. 5v 전원 케이블도 없었다. 때문에 집에 있는 케이블로 연결을 해야하는 상황이었다. (절대 석균님을 탓하는 것이 아닙니다!!!!!)

처음 써봐서 연결하면 이렇게 초록불이 들어오는지 몰랐다.
처음 연결했을 때, ubuntu랑 windows 모두 인식을 못 했다. 당연히 초록불도 안 들어왔었다. SDK도 깔아봤는데 역시 인식을 못했다. 열심히 구글링도 해봤다. 구글링 결과, 나처럼 시작부터 막힌 사람은 없는 것 같았다.,..ㅠㅠ 혹시나 하는 마음에 케이블을 바꿔봤지만 그대로였다. 집에 있는 모든 micro 5pin을 찾아서 연결한 결과, 딱 하나만 전원이 들어와서 프로젝트를 진행할 수 있었다.
나중에 찾아보니 RPLiDAR는 전력이 많이 딸리는 제품이라고 한다.
Ubuntu도 오랜만에 사용해서 ROS Package를 사용하는 것도 어색했다.
Vlp-16을 사용할 때는 topic이 pointcloud가 바로 들어와서 당연히 pointcloud로 들어오겠지 했는데 rplidar는 laser로 들어왔다.
딥러닝의 데이터도 검수할 시간이 없어서 바로 학습 시켰는데, 결과가 안 좋았던 부분도 아쉽다.
다음에는 카메라와 LiDAR의 위치 관계인 extrinsic parameter를 tilt, pan과 같이 다른 방식을 이용해서 구하고 싶다. 거리와 각도를 직접 측정해서 하는 방법도 있다.
그리고 3D LiDAR를 사용해서도 fusion을 해보고 싶다. 3D LiDAR는 비싸니깐 KITTI Dataset을 이용해서 하면 어떨까 싶다.
다음 게시글은 3D LiDAR의 전반적인 과정이나 카메라에 대한 자세한 설명하면 어떨까 싶다.
전체적인 코드는 깃허브에서 볼 수 있다.
https://github.com/jinhoyoho/rplidar_camera_calibration

rp lidar 가 아니라 yd lidar 로도 가능할까요?