Denoising Vision Transformers(2024)
Abstract
Problem definition
- Grid-like artifacts in ViTs' feature maps hurts the performance
- Positional embedding at the input stage is the cause.
Model introduction
- Novel noise model that applicable to all ViTs.
- 2 stage approach
Stage 1: Per-image optimization
- dissects ViT outputs into three components(1 semantic + 2 artifact-related conditioned on pixel location)
Stage 2: Learnable denoiser
- predict artifact-free features directly from unprocessed ViT outputs
- shows generalization capabilities to novel data
Model strength
- DVT does not require re-training (can apply to existing pre-trained Vit)
- Consistently and significantly improves existing sota models.
We hope our study will encourage a re-evaluation of ViT design, especially regarding the naive use of positional embeddings
Introduction

- Persistent noise is observable across multiple ViT models

- These noise hinders performance of downstream tasks. (like noise clusters in the above figure)
Main Research Question
Is it feasible to effectively denoise these artifacts in pre-trained ViTs, ideally without model re-training?
Key Contributions
- We identify and highlight the widespread occurrence of noise artifacts in ViT features, pinpointing positional embeddings as a crucial underlying factor.
- We introduce a novel noise model tailored for ViT outputs, paired with a neural field-based denoising technique. This combination effectively isolates and removes noise artifacts from features.
- We develop a streamlined and generalizable feature denoiser for real-time and robust inference.
- Our approach significantly improves the performance of multiple pre-trained ViTs in a range of downstream tasks, confirming its utility and effectiveness (e.g., as high as a 3.84 mIoU improvement after denoising).
Backgrounds
ViTs
- ViTs trained with diverse training objectives exhibit commonly observed noise artifacts in their outputs.
- This paper enhance the quality of local features, as evidenced by improvements in semantic segmentation and depth prediction tasks.
ViT artifacts
- Fundamental noise issue noticeable as noisy attention maps in supervised / unsupervised ViTs
- Previously noticed yet often unexplored.
- Recent work(Vision transformers need registers, 2023) explained them as 'high-norm' patches in low-informative background regions, suggesting that suggesting their occurrence is limited to large and sufficiently trained ViTs.
- But, this paper found a strong correlation between the artifacts and the PE.
Preliminaries
- ViT architecture largely remained consistent with its original design
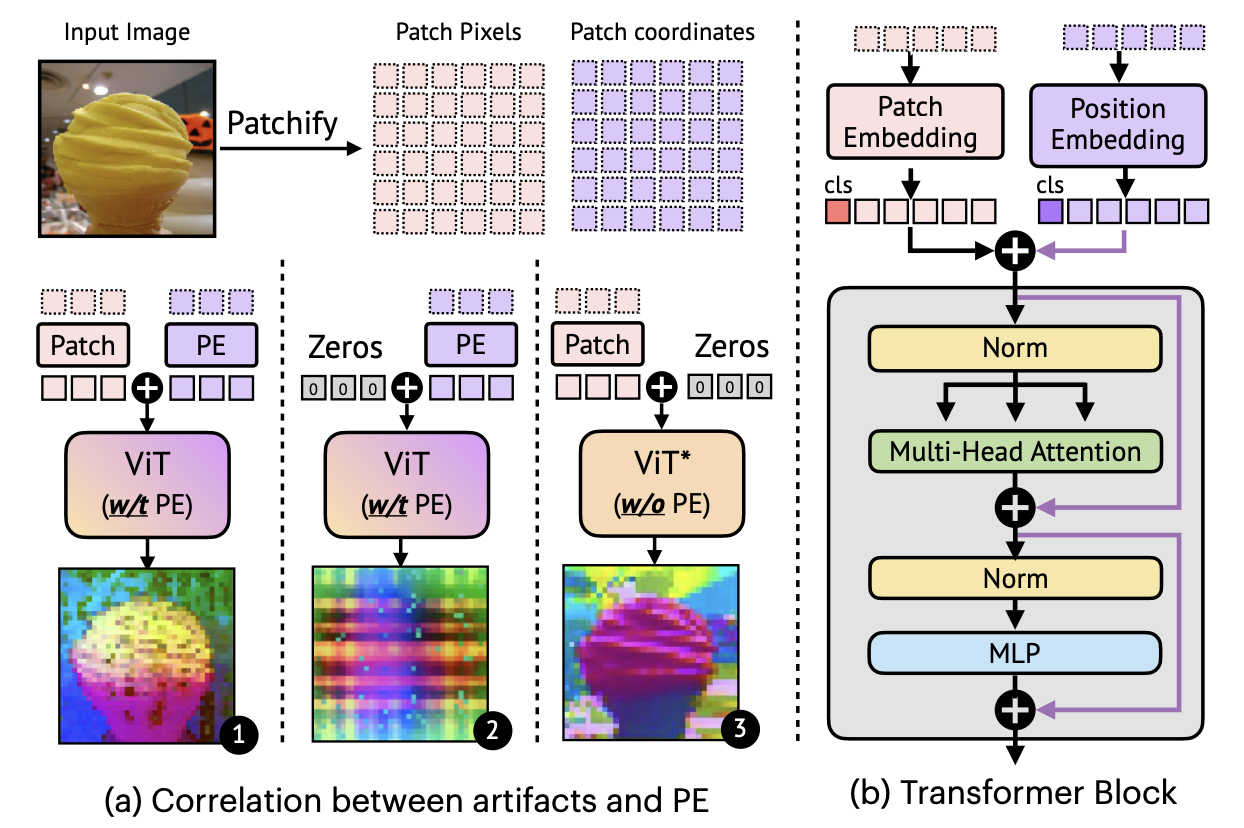
Denoising Vision Transformers
Factorizing ViT outputs
- While visual features should be translation and reflection invariant, ViTs interwine patch embeddings with positional embeddings, thus breaking the transformation invariance.
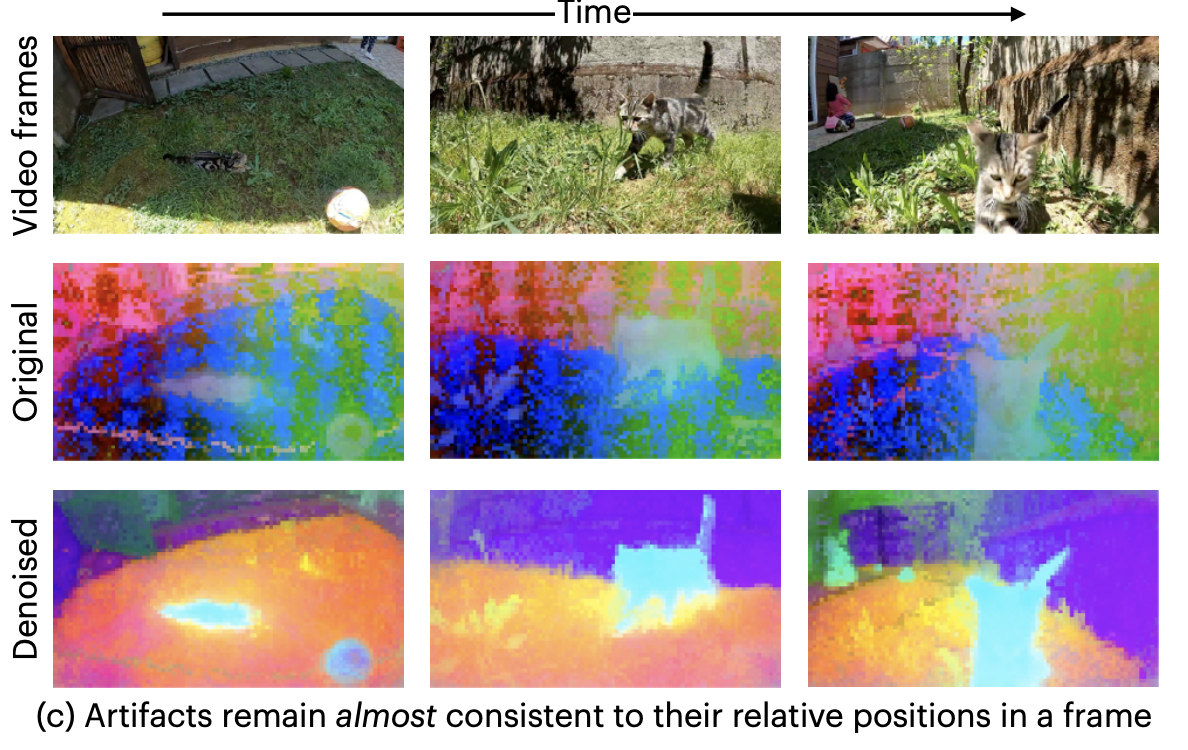
Above figure shows that artifacts remain almost consistent to their relative positions in a frame.
decomposing ViT outputs into three terms
- : input-dependent, noise-free semantics term
- : input-dependent artifact term related to spatial positions
- : residual term accounting for the co-dependency of semantics and positions.
- spatially invariant output feature map(no PE) => g and h become zero functions
- every feature is dependent on both position and semantics => f and g turn into zero functions
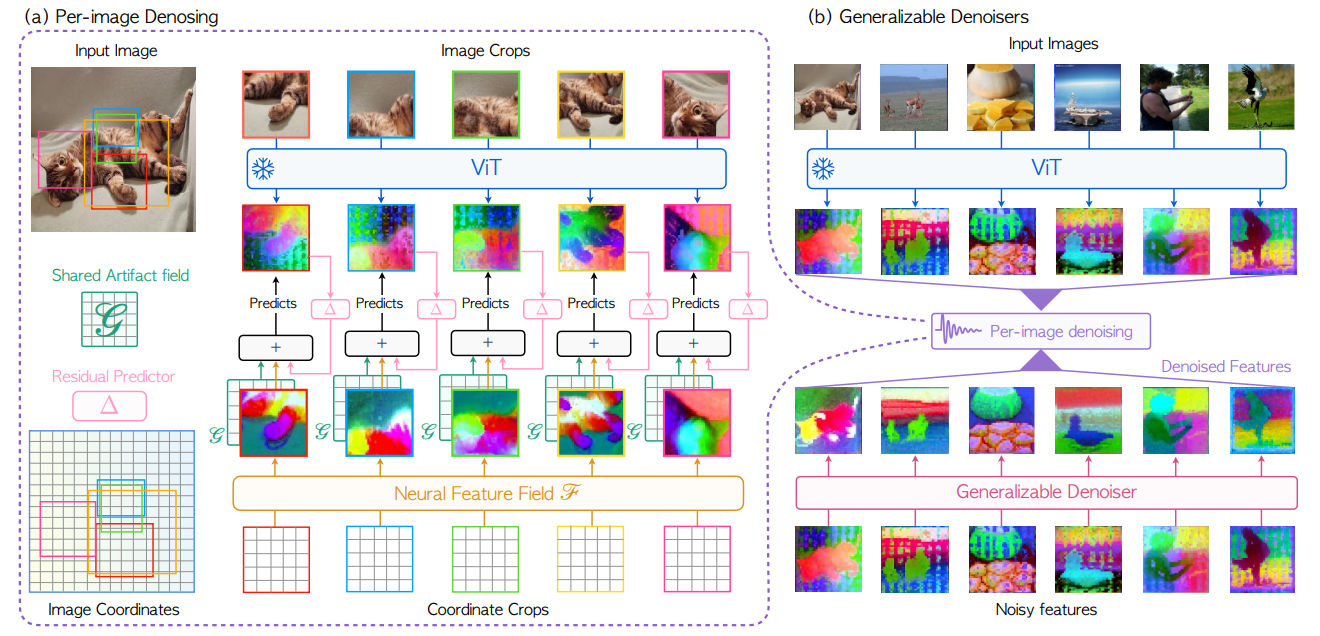
Per-image Denoising with Neural Fields
- Directly addressing above decomposition is hard.
- Cross-view feature and artifact consistencies
- Feature consistency: transformation invariance of visual features(even in case of spatial transformation, the essential semantic content remains invariant)
- Artifact consistency: input-independent artifact remains observable and constant across all transformation
Neural fields as feature mappings
- Semantics field and artifact field
- (holistic image semantics) for each individual image
- (spatial artifact feature representation) shared by all transformed views.
Learning the decomposition
- Learn semantics field , artifact field , residual term by minizing a regularized reconstruction loss
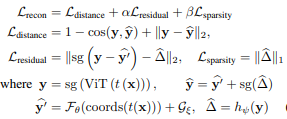
cos: cosine similarity, sg: stop-gradient, t: random transformation sampled from random augmentation, coords: pixel coordinates of the transformed views in the original image
Optimization
- Phase 1: train and using only
=> capture significant portion of the ViT outputs - Phase 2: freeze and continue to train and using
Generalizable Denoiser
- Per-image denosing method can effectively remove artifacts from ViT, but not run-time effciency and distribution shifts.
- Accumulate a dataset of pairs of noisy ViT outputs and their denoised counterparts after per-image denoising.
- Train denoiser network
- single Transformer block + additional learnable positional embedding

Experiments
Correlation between artifacts and positions
- Maximal information coefficient(MIC) between grid features and normalized patch index
Evaluation on Downstream Task Performance
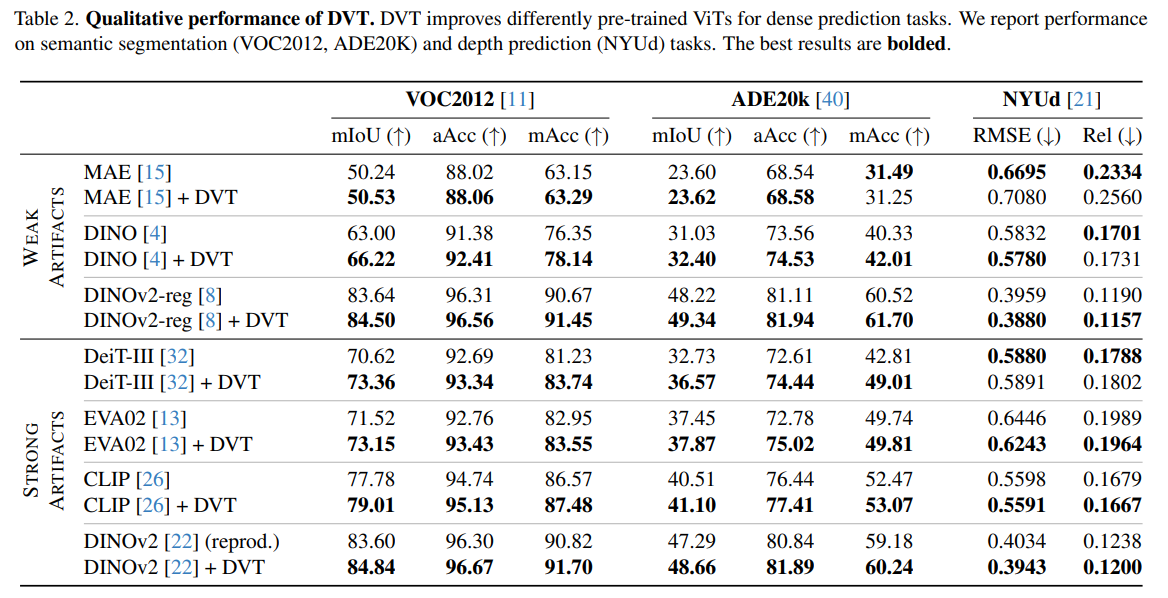
Qualitative results
Visual analysis of ViTs
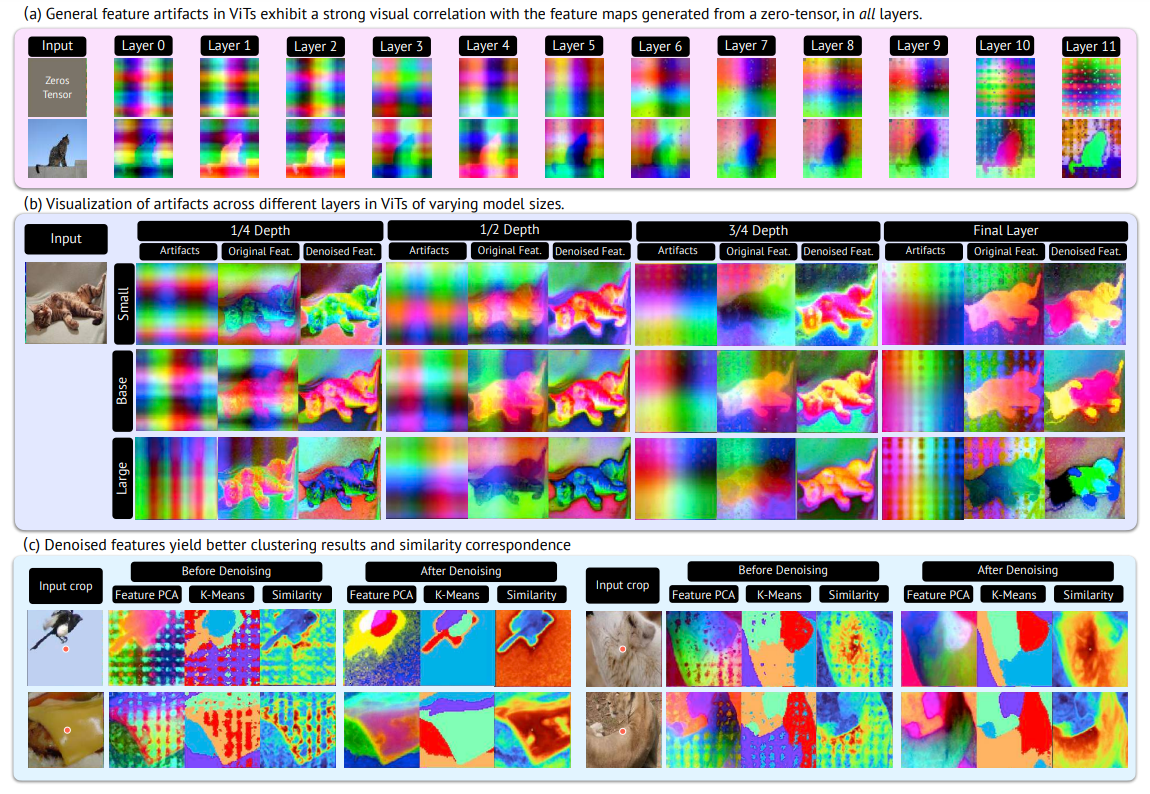
Emerged object discovery ability

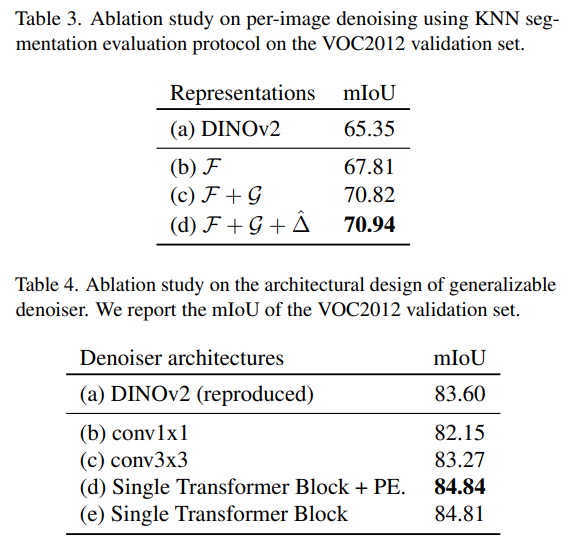
Ablation study
Future works
Alternative approaches for position embeddings
- The problems looks like positional embedding that are added to the input tokens
- non-adding embeddings like Rotary Positional Embeddings, bias to key-query in T5, ALiBi from LLM can be used.

Undergraduate student at SNU