So far, we have studied various techniques (ex- train/test-split, GridSearchCV, Standardization, Normalization, Data Preprocessing) to enhance our machine learning model and to evaluate the performance based on accuracy. However, accuracy is not the only metrics to evaluate the model. There are many other evaluation metrics used for different types of models, and today we will be studying the loophole of accuracy in certain situation.
Types of Evaluation Metrics
Confusion Matrix
Precision / Recall
F1-Score
ROC AUC
Accuracy
ratio of features classified correctly out of total number of features
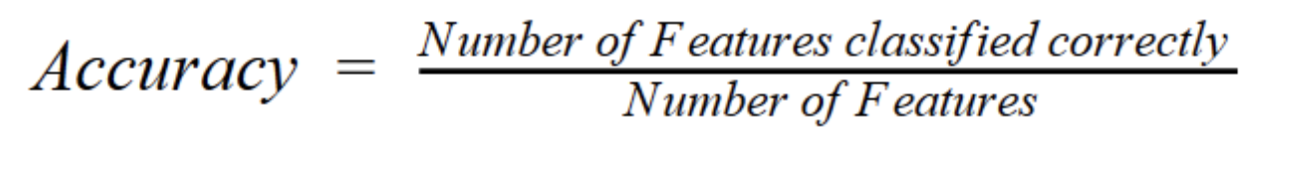
Accuracy is a metrics which can intuitively evaluate the model. However, in regards to the binary classification, accuracy alone can distort the performance of the machine learning model. We will now check how accuracy can misrepresent the evaluation of the model.
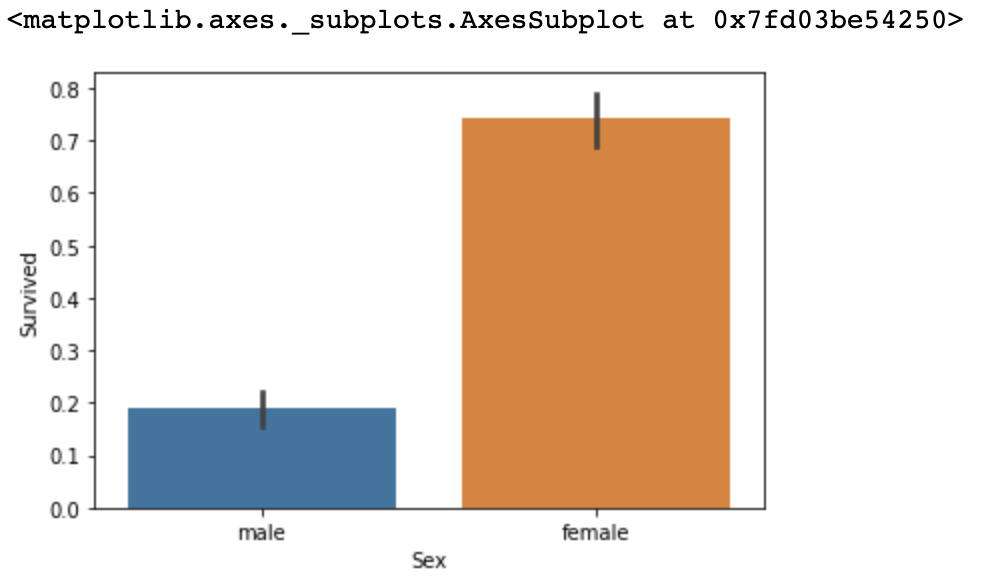
The plot above shows the survival rate of Titanic survivors by Sex. Looking at the data, we may start to suspect that a simple model which classifies survived for females and dead for males can return a relatively high accuracy-score.
We will use scikit-learn's BaseEstimator to create a customized form of estimator to do so.
Input
import sklearn
from sklearn.base import BaseEstimator
import numpy as np
class MyDummyClassifier(object):
def fit(self, X, y=None):
pass
def predict(self, X):
pred = np.zeros((X.shape[0], 1))
for i in range(X.shape[0]):
if X['Sex'].iloc[i] == 1:
pred[i] = 0
else:
pred[i] = 1
return predNow, we will perform the survivor prediction using the MyDummyClassifier() we created above.
Input
from sklearn.preprocessing import LabelEncoder
import pandas as pd
# data preprocessing
def fillna(df):
df['Age'].fillna(df['Age'].mean(),inplace=True)
df['Cabin'].fillna('N',inplace=True)
df['Embarked'].fillna('N',inplace=True)
df['Fare'].fillna(0,inplace=True)
return df
def drop_features(df):
df.drop(['PassengerId','Name','Ticket'],axis=1,inplace=True)
return df
def format_features(df):
df['Cabin'] = df['Cabin'].str[:1]
features = ['Cabin','Sex','Embarked']
for feature in features:
le = LabelEncoder()
le = le.fit(df[feature])
df[feature] = le.transform(df[feature])
return df
def transform_features(df):
df = fillna(df)
df = drop_features(df)
df = format_features(df)
return dfInput
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
titanic_df = pd.read_csv('titanic_train.csv')
y_titanic_df = titanic_df['Survived']
X_titanic_df = titanic_df.drop('Survived', axis=1)
X_titanic_df = transform_features(X_titanic_df)
X_train, X_test, y_train, y_test = train_test_split(X_titanic_df, y_titanic_df, test_size=0.2, random_state=0)
myclf = MyDummyClassifier()
myclf.fit(X_train, y_train)
pred = myclf.predict(X_test)
print('MyDummyClassifier Accuracy : {0:4f}'.format(accuracy_score(y_test, pred)))Output
MyDummyClassifier Accuracy : 0.787709
We see that the dummy classifier with barely-none algorithm returns accuracy of 78%. Hence, we now learn that accuracy is not suitable evaluation metrics when it comes to a dataset with imbalanced label values.
Now, we will work on one more example with MNIST data set and converting it to an imbalanced label set. After loading the data using load_digits() API, we will classify True only for the label value with 7 and False otherwise.
In other words, our dataset will have imbalanced label distribution of 10% True and 90% False. Hence, when our dummy model simply predicts every outcomes to be False, our model will have accuracy-score of 90%.
Input
# MNIST Dataset
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.base import BaseEstimator
from sklearn.metrics import accuracy_score
import numpy as np
import pandas as pd
# fake classifier - equals 1 only when digit is 7
class MyFakeClassifier(BaseEstimator):
def fit(self, X, y):
pass
def predict(self, X):
return np.zeros((len(X), 1), dtype=bool)
# load digits dataset
digits = load_digits()
# change True to 1 if target equals 7
y = (digits.target == 7).astype(int)
X_train, X_test, y_train, y_test = train_test_split(digits.data, y, random_state=11)
fakeclf = MyFakeClassifier()
fakeclf.fit(X_train, y_train)
pred = fakeclf.predict(X_test)
print('Label Test Set Size : ', y_test.shape)
print('Distribution of Test Set Label 0 & 1')
print(pd.Series(y_test).value_counts())
print('MyFakeClassifier Accuracy : {0:3f}'.format(accuracy_score(y_test, pred)))Output
Label Test Set Size : (450,)
Distribution of Test Set Label 0 & 1
0 405
1 45
dtype: int64
MyFakeClassifier Accuracy : 0.900000
It is hard to believe that the model which simply predicts zero for entire label data has 90% accuracy rate. As we have seen in Titanic and MNIST examples, we now know that accuracy score should not be used when evaluating the performance of model imbalanced dataset.
