https://arxiv.org/abs/1504.08083
0. Drawbacks in R-CNN and SPPNet
R-CNN
- multi-stage pipeline입니다.
https://velog.io/@jj770206/Rich-feature-hierarchies-for-accurate-object-detection-and-semantic-segmentation-RCNN 의 중간 그림을 보면 학습이 총 세 단계로 끊어져 되는것을 볼 수 있습니다. 첫번째는 navie classification dataset으로 pretrain하는 것이고, 두번째는 pretrained CNN parameter를 object detection dataset으로 finetuning합니다. 이 두가지의 과정은 모두 softmax classifier를 사용합니다. 하지만 세번째 단계인 SVM에서 실질적인 classification이 일어나는데 이는 한번에 학습 할 수 없습니다. 즉, 앞의 두단계로 ConvNet을 학습한 뒤 마지막의 softmax classifier를 제거하여 세번째 단계에서는 Conv의 output인 feature vector를 SVM에 넣어 SVM만을 학습합니다. 따라서 실직적인 classifier인 SVM을 학습할 때는 Conv의 parameter가 update될 수 없습니다.
- Expensive & Slow
한장의 image에서 2,000장의 cropped image를 뽑습니다. 심지어 이를 모두 Conv에 넣는데 시간이 상당히 걸릴 뿐더러 메모리도 많이 차지합니다.
SPPNet
R-CNN의 위와 같은 단점들을 보완하기 위해 SPPNet이 제안되었습니다. R-CNN은 input image에서 selective search에 의해 제안된 RoI 2,000장을 모두 Conv연산을 하는 반면 SPPNet은 input image를 먼저 Conv에 통과 시킨 feature map에서 Input image에 selective serach를 적용한 RoI를 mapping하여 시간을 단축합니다.
시간을 단축했지만, 여전히 multi-stage pipeline으로 번거롭습니다.
1. Overall Fast R-CNN architecture
위 사진이 Fast R-CNN의 대략적인 architecture입니다.
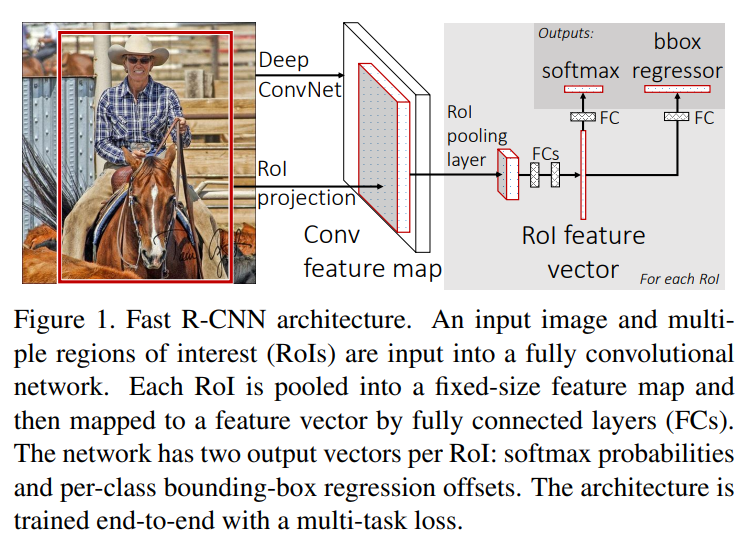
하나 먼지 짚고 넘어갈 부분은 RoI projection이라는 부분인데 이전 post인 SPPNet에서 caution으로 오해의 소지가 있는 부분으로 따로 다루었던 부분입니다. 본 논문에서는 굳이 RoI prejection이라고 표현을 해주어 헷갈리지 않게 해주었습니다. (내용에서 설명은 없고 그림에만 위와같이 언급되어 있습니다.)
전반적인 구조에 대해 간략한 설명을 해보겠습니다.
1. Input image를 selective search를 통해 RoI를 계산합니다.
2. Input image를 Conv를 통과시켜 feature map을 얻습니다.
3. feature map에 1에서 계산 해둔 RoI를 Conv에서의 비율에 맞게 RoI projection을 진행하여 feature map에서 crop합니다.
4. cropped feature map은 모두 different size이므로RoI Pooling Layer를 이용하여 fixed size vector로 만들어 줍니다.
5. 이를 FC-layer를 거쳐 한번 정제해 줍니다.
6. 이후 classification을 진행하는 softmax기반의 classifier로 들어갑니다.
7. 같은 vector가 bbox regression에도 사용됩니다.
SPPNet과 비교하자면 classifier로 SVM을 사용하지 않는다는 점과 SPP-layer대신 RoI Pooling Layer를 사용한다는 점 외에는 거의 동일합니다.
2. RoI Pooling layer
이는 Conv를 거친 feature map에서 Input image에 selective search를 적용한 RoI가 project되어 RoI를 만듭니다. 이는 size가 다양하므로 모두 같은 길이의vector를 만들어 주는 역할을 하는것이 RoI Pooling layer입니다.
이는 SPPNet의 SPP-layer와 상당히 유사합니다. 다만 완전하게 일치하지는 않습니다.
일단 이해를 위해서 SPP-layer에서는 여러개의 bin이 사용되었다면 RoI Pooling layer는 한개의 bin만 사용한다고 생각하면 됩니다.
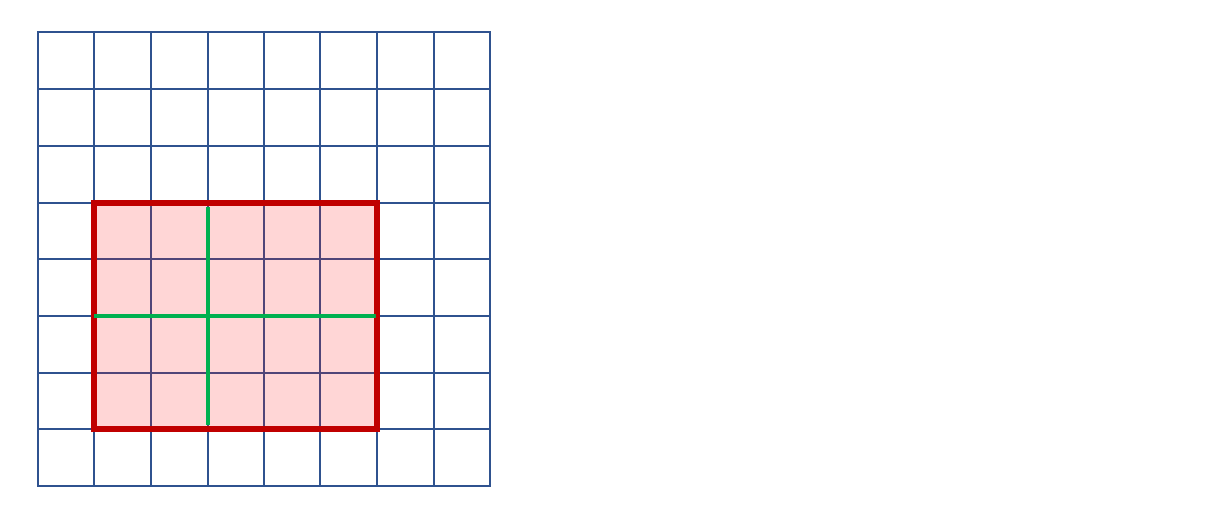
다음의 그림이 RoI Pooling layer를 잘 설명합니다.
전체의 사각형이 Conv의 output인 Feature vector입니다.
빨간색 사각형은 RoI prejection 입니다.
목표하는 fixed vector의 size가 2×2인 경우입니다.
그러면 초록색 선을 기준으로 총 4가지의 구역으로 나누어 각 역역별로 max-pooling을 진행하여 2×2로 만들수 있습니다.
이부분에 대해서 본 논문에서는 다음과 같이 설명합니다.
여기서 와 는 목표하는 size 입니다.
와 는 RoI입니다.
즉 위의 예시에서는 입니다.
따라서 이 됩니다.
이때 은 sub-window를 의미하여 논문에서 approximate라는 단어를 사용하여 자세한 부분은 다루지 않지만 대략적으로 위의 그림과 같이 분할이 되어 Max Pooling을 적용하면 됩니다.

SPP의 bin하나일때와 거의 유사하지만 SPP는 stride와 window를 이용하여 위와같은 예시처럼 정수로 떨어지지 않는 경우에는 겹치게 sliding하여 정확한 연산이 가능했던 반면 여기에서는 정확하게는 표현되어 있지 않습니다. 두경우의 연산이 완전히 같다고 할 수는 없으나 전체적인 결과에서는 영향을 미치지는 못할것 같습니다.
딱 떨어지지는 않지만 본 논문에서의 설명은 직관적으로 이해가 잘 된다는 장점이 있습니다.
가장 쉽게는 서로 다른 크기의 RoI를 정해진 개수의 vector만큼으로 넓이를 최대한 비슷하게 나눈다라고 생각하면 됩니다.
3. Conv
SPPNet과 마찬가지로 Conv에는 기존의 VGG같은 model들이 사용되었습니다.
이때 각 model들은 총 3가지의 변환을 통해 Fast R-CNN에 적용됩니다.
1. 마지막 Max Pooling층이 RoI pooling으로 대체됩니다. (예를들어 VGG16을 사용하는 경우에는 이라고 줍니다.)
2. 마지막 classifier가 없어지고 k+1의 classifier와 bounding box regression으로 대체됩니다.
3. Input image에 대한 RoI을 추가로 입력받게 변형됩니다.
4. Training strategy
아래 사진은 본 논문의 내용인데 정확하게 이해가 되지 않아 첨부합니다.
Fast R-CNN은 이전 모델과 다르게 전체 네트워크의 parameter를 역전파를 통하여 한번에 update가 가능합니다.
특히 SPPNet에서 SPP layer를 통한 역전파는 각각의 RoI들이 서로 다른 image에서 온 경우 상당히 비효율 적입니다. 또한 RoI들이 input image 전체일 수도 있으므도 더욱 비효율 적입니다.
(이부분이 살짝 이해가 안되는데 inefficiency의 이유가 RoI가 여러장에서 왔고 심지어 그 각각의 RoI들이 input image의 전체일 수도 있다라고 쓰여진것 같습니다.)
https://blahblahlab.tistory.com/104 여기를 참고하여 추가설명을 하면 R-CNN과 SPPNet은 batch 생성시 무작위로 가지고 왔다고 합니다.
따라서 본 논문에서는 더 효율적인 방법을 제안합니다.
mini batch를 만드는데 최대한 같은 image에서 RoI를 뽑게 합니다.
이를 hierarchically라고 표현하였습니다.
즉, 장의 input image를 뽑고 개의 image 각각에서 개의 RoI를 뽑습니다. 이렇게 하나의 mini batch를 만들면 mini batch는 총 개의 cropped image로 구성되며 이는 총 개의 image에서 crop 된 것입니다. 이때 본 논문에서는 로 하여 하나의 mini batch는 2장의 image 각각에서 64개의 RoI로 구성됩니다.
이렇게 하면 알고리즘 상으로는 빠르나 학습이 느리게 될 수 있습니다.
이부분은 추가설명을 하겠습니다.
기본적으로 딥러닝에서는 한 epoch을 학습할때 minibatch로 나누어 각 batch마다 parameter update를 진행합니다. 원래는 한 epoch당 update한번이 맞지만 memory의 문제도 있고 bottle neck문제도 있습니다. 따라서 epoch을 batch 단위로 나누어 진행하고 이렇게 하여 별 문제는 없습니다. 다만 본 논문에서 처럼 하면 학습이 편향될 수 있습니다. 왜냐면 하나의 batch에 전체 image중 단 2개만 들어가서 서로 연관이 있는 RoI만 학습되는 즉, 학습이 편향될 수 있습니다. 하지만 학습 결과 그러한 문제는 전혀 발견되지 않았다고 합니다.
또한 Fast R-CNN은 streamlined (간소화된) training process를 사용합니다. 이는 softmax classifier, bnd regressrion을 한번에 같이 학습하는 것을 의미합니다. R-CNN에서는 다 따로따로 진행하였습니다.
위에서 설명한 내용을 더 자세하게 설명해보겠습니다.
Multi-task loss
Conv이후 feature vector가 classifier와 regressor로 들어가는데 이를 sibling이라고 표현합니다.
첫번째 sibling ( classifier )은 RoI하나당 이산확률 를 output으로 합니다. 또한 이때 class의 개수는 background를 포함하여 K+1이 됩니다.
두번째 sibling ( regressor )은 즉, bounding-box regression을 output으로 합니다. 이때 는 개의 object class를 의미하는데 아래에서 자세하게 설명합니다.
또한 각각의 training RoI는 정답 class 와 정답 bound box 가 label됩니다.
이를 가지고 다음과 같이 classification과 bound-box regression을 같이 진행 할 수 있는 Loss function을 정의합니다.
+
는 log loss입니다.
는 model의 output이고 는 target입니다.
를 보겠습니다.
첫번째로 는 Loss function에서 regression을 얼마나 가중해서 볼것이냐로 이해 할 수 있습니다. 예를들어 가 커지게 되면 bound box regression을 더 중요하게 학습한다고 이해 하면 됩니다. 논문의 실험에서는 을 사용하였습니다.
두번째로 은 background에 대한 대응이라고 보면 됩니다. 뒤에 다시 나오지만 IoU가 과 사이의 값을 가지면 해당 RoI는 backgroud로 분류됩니다. background에 대한 class값을 0으로 하면 이부분은 background에 대해서는 classification은 진행하지만 regression은 진행하지 않게 해줍니다. 당연한 것이 background는 정답 data가 존재하지 않습니다. 식에 관해서는 indicator function이라고 보면 됩니다. 즉, 이를 자세하게 설명하고자 와 나누어 봤는데 사실 나누면 안됩니다.
마지막 세번째 에서 특히 에 classification의 정답인 가 포함되어 있습니다. 이부분은 가 왜 들어가 있는지 모르겠습니다. class별로 bound box가 다르게 적용된다면 이해하겠는데 심지어 정담 bound box에도 class에 대한 부분이 없는데 predeict부분에 굳이 들어가야 하는가 하는 생각이 듭니다. 는 다음과 같이 연산 됩니다.
이는 R-CNN과 SPPNet과는 다릅니다. https://velog.io/@jj770206/Rich-feature-hierarchies-for-accurate-object-detection-and-semantic-segmentation-RCNN (R-CNN의 loss는 L2에 regulation)
이는 L1 loss 네 smooth를 적용한 것이라고 보면 됩니다.
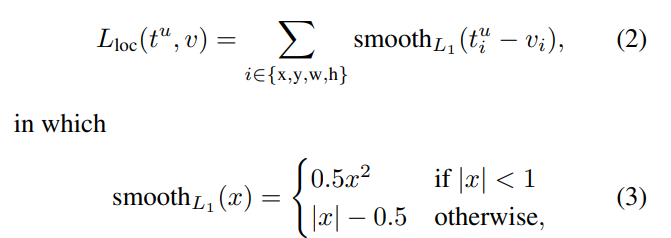
Mini-batch sampling
위에서도 설명 했듯이 본 논문에서는 , 을 사용합니다. 즉 하나의 mini batch에는 두장의 image에서 각각 crop한 64개의 RoI로 구성 됩니다. 또한 R-CNN과 마찬 가지로 64개의 RoI중 25%는 IoU가 0.5 이상인 즉, 가 1 이상인 것들로 구성 됩니다. 나머지 75%는 background즉, IoU가 0.1부터 0.5 사이의 것들로 구성 됩니다. 또한 augmentation 방법으로는 h flip만을 이용합니다.
.png)