Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
Paper_Review_object_detection
https://arxiv.org/pdf/1506.01497.pdf
본 연구는 seletive search와 같은 RoI를 위한 algoritm을 사용하지 않습니다. 해당 algorithm은 GPU가 아닌 CPU연산 이므로 느리다는 단점이 있습니다. 이부분에 대해 처음에는 왜 GPU에서는 못하는가 하고 의문이 있었습니다.
정확히 말하면 GPU에서 불가능 한것은 아닙니다. 다만 CPU와 GPU에서 속도 차이가 없으므로 CPU에서의 연산 이라고 표현 합니다. selective algorithm의 pseudo code를 보면 확실하게 이해가 되는데 병렬연산이 불가능 합니다. 하나의 이미지가 있다고 가정해 보겠습니다. 처음에 엄청 많고 작은 영역들을 기준을 정해놓고 비슷한 지역끼리 묶습니다. 묶는 것에는 순서가 있기 때문에 병렬 연산이 가능하게 algorithm을 짜는 것이 개념상 불가능 합니다. 따라서 GPU를 사용한다 하더라고 큰 이득이 없게 됩니다.
따라서 이 문제를 해결하고자 RPN을 제안합니다.
RPN의 N은 network입니다. 즉 딥러닝 알고리즘이므로 병령 연산이 가능하며 GPU의 장점을 이용할 수 있습니다.
또한 RPN은 FCN기반 sliding window 방식 입니다. 과거 R-CNN에서 sliding window 방식보다 selective search가 더 좋아 sliding window 방식을 사용하지 않았지만 다시 돌아 왔습니다.
하나 미리 알고 들어갈 것이 있습니다. 제가 계속 이해가 안되었던 부분입니다. 앞선 model들은 RoI를 뽑기 위해 selective search를 이용하였습니다. 이는 상당히 직관적입니다.그림을 보시면 RoI가 어떻게 뽑히는지 어떤 과정을 거쳤는지가 이해가 됩니다. 하지만 본 논문에서는 FCN 기반 신경망 입니다. 즉, convolution입니다. 처음 CNN을 봤을 때 어려웠던 것처럼 CNN을 통한 RoI 추출 이라는 부분이 이해가 안되었습니다. 이는 아래 RPN에서 다시 자세하게 설명합니다.
0. R-CNN, SPPNet, Fast R-CNN 간단한 요약
R-CNN의 계열 모델들이 새롭다기 보다는 전 모델을 수정해가는 방식이라 Faster R-CNN을 보기전에 간단하게 요약하고 넘어가겠습니다.
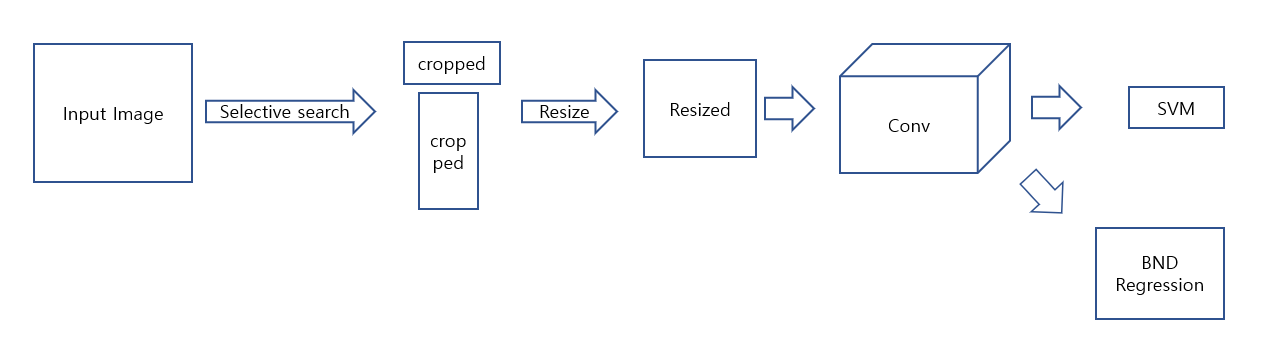
R-CNN
https://velog.io/@jj770206/Rich-feature-hierarchies-for-accurate-object-detection-and-semantic-segmentation-RCNN
1. Input image를 selective algorithm을 이용하여 RoI를 추출합니다.
2. 각각의 RoI를 독립적으로 Conv를 통과시킵니다.
3. Conv의 output인 feature map을 이용하여 SVM으로 classification을 진행하고 BND regressor로 RoI를 수정합니다.
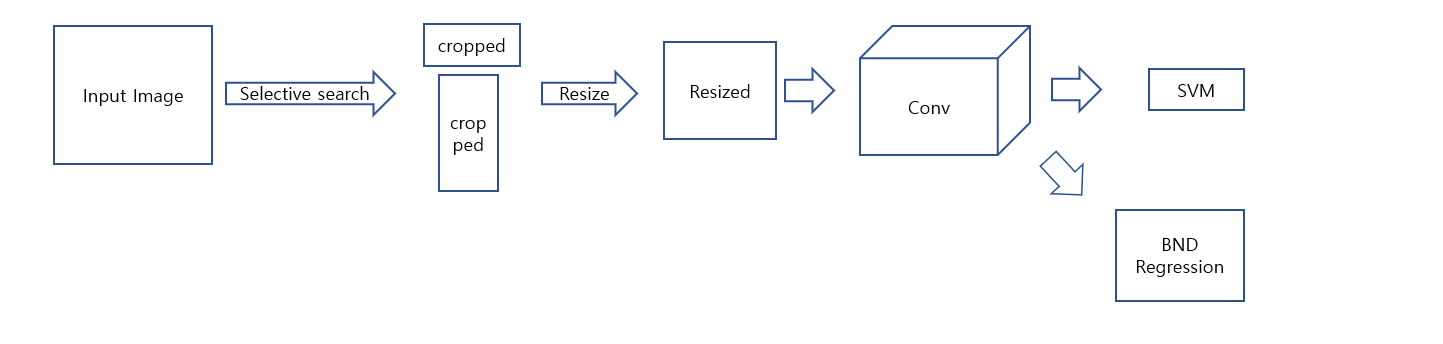
SPPNet
https://velog.io/@jj770206/Spatial-Pyramid-Pooling-in-Deep-ConvolutionalNetworks-for-Visual-Recognition-SPPNet
1. Input image를 selective search를 통해 RoI를 뽑습니다.
2. Input image를 Conv를 통과 시켜 feature map을 얻습니다.
3. feature map에 1번에서 뽑은 RoI를 mapping하여 crop 합니다.
4. SPP layer을 이용하여 fixed-length vetor로 만들어 줍니다.
5. fixed-length vetor를 이용하여 SVM으로 classification을 진행하고 BND regressor로 RoI를 수정합니다.
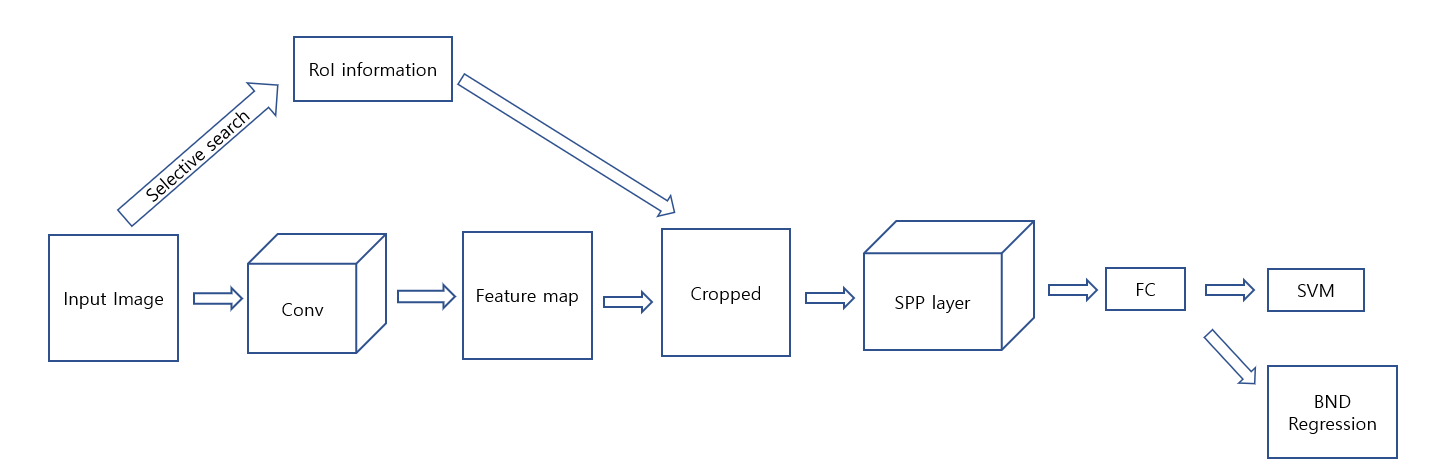
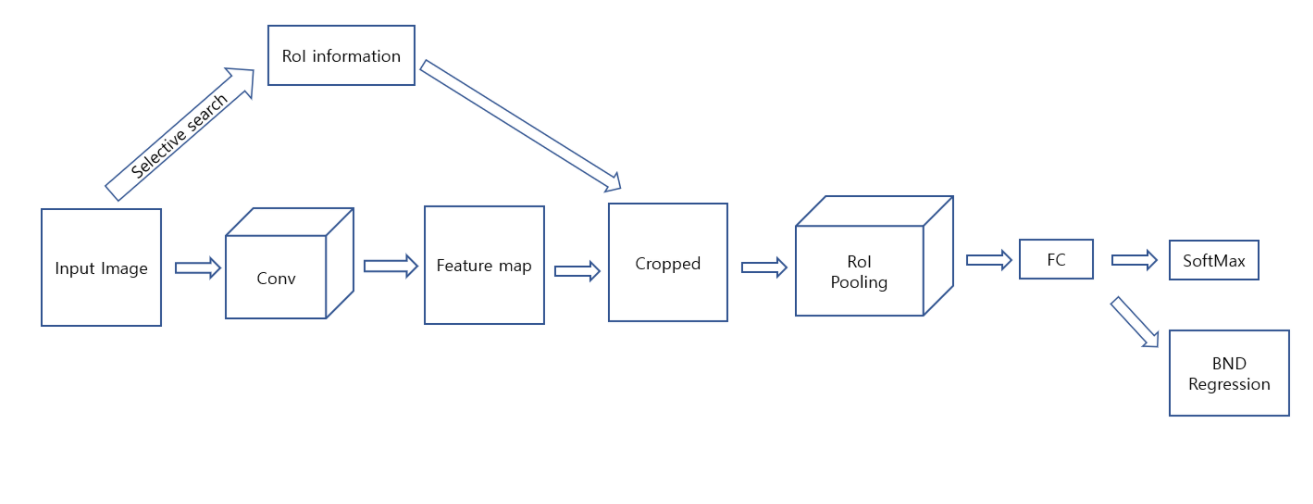
Fast R-CNN
https://velog.io/@jj770206/Fast-R-CNN
1. Input image를 selective search를 통해 RoI를 뽑습니다.
2. Input image를 Conv를 통과 시켜 feature map을 얻습니다.
3. feature map에 1번에서 뽑은 RoI를 mapping하여 crop 합니다.
4. RoI pooling을 이용하여 fixed-length vetor로 만들어 줍니다.
5. softmax classifier로 classification을 진행하고 regressor로 RoI를 수정을 동시에 진행합니다.
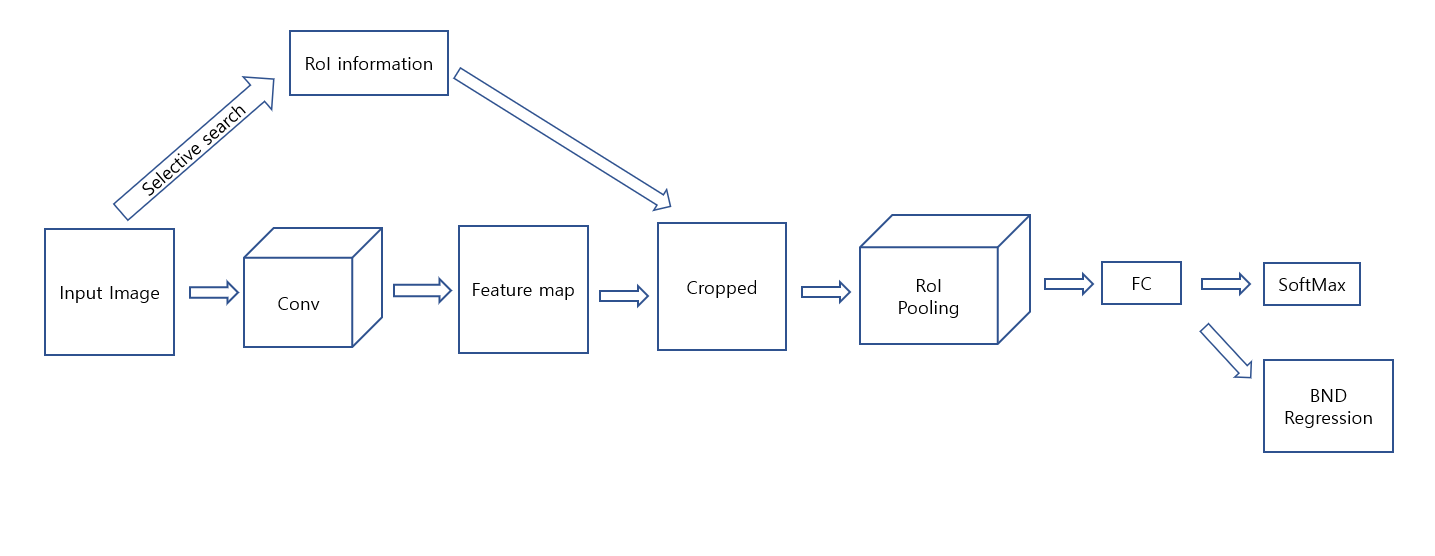
1. Introduce
sharing convolution
R-CNN, SPPNet, Fast R-CNN은 모두 seletive search algorithm을 이용합니다. 하지만 R-CNN에 비해 SPPNet과 Fast R-CNN은 상당한 속도의 향상을 보여주었습니다. 이부분을 논문에서는
their cost has been drastically reduced thanks to sharing convolutions across proposals라교 표현되어 있습니다. 즉, R-CNN의 경우에는 proposal은 독립적으로 진행되는 반면 SPPNet과 Fast R-CNN은 conv의 연산을 proposal에서도 sharing한다는 것입니다. 여기서 sharing라는 단어는 다음과 같이 이해하면 됩니다.
R-CNN의 경우 region propose를 진행 하여 2,000개의 cropped image를 뽑아내고 이를 독립적으로 Conv를 통과시킵니다. 즉, region proposal과 Conv과 완전하게 분리되어 있는 것입니다. 이는 직관적으로 이해 할 수 있는데 R-CNN에서늬 Conv는 Input으로 cropped image를 받는다는 것을 알고 나면 확실하게 regin proposal이 끝난 뒤 Conv를 진행 하는 즉, 두가지의 process가 완전히 독립적이라는 것을 알 수 있습니다.
반대로 SPPNet과 Fast R-CNN은 Input image에 region propose를 하여 bnd information을 저장합니다. 여기서 중요한 사실은 R-CNN은 information을 가지고 input image를 crop하지만 SPPNet과 Fast R-CNN은 input image를 crop하지 않습니다. Input image는 그대로 Conv에 들어가고 이후 나온 feature map을 앞에서 저장한 information을 feature map size에 mapping하여 feature map을 crop합니다. 따라서 시간을 상당히 줄일 수 있습니다. 이부부을 본 논문에서sharing이라고 표현 합니다.
위의 0에서 3가지 모델을 비교한 그림을 보시면 selective search가 추가적인 branch로 나와 있는 것을 볼 수 있는데 이를 표현한 것입니다.
2. Region Proposal Networks ; RPN
Faster R-CNN은 RPN(as RoI) + Fast R-CNN(as detector)으로 표현 가능합니다.
위에서 언급 했지만 RPN은 FCN 기반 신경망 입니다. selective search는 완전히 잊어야 편합니다.
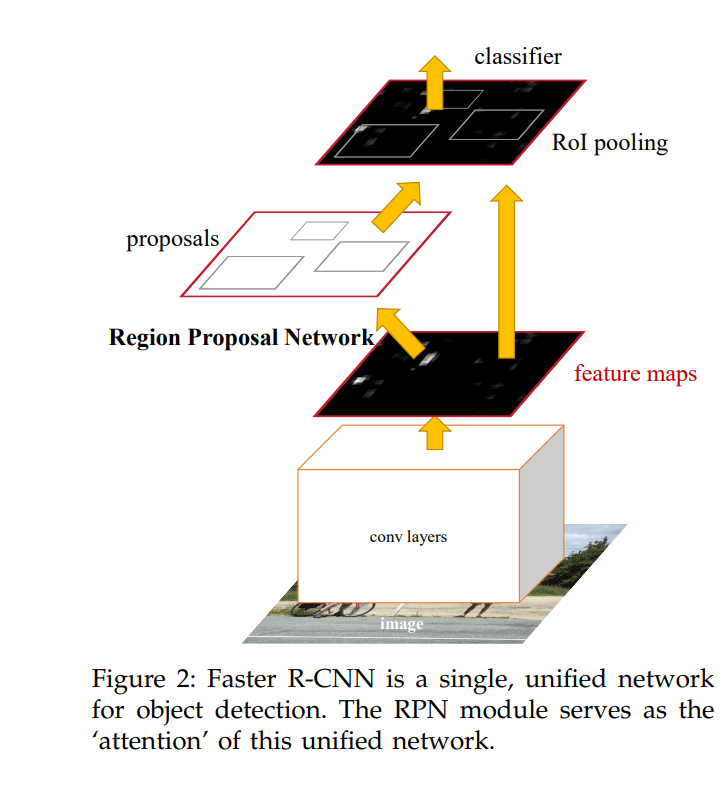
또한 RPN은 RoI를 추천해주는 network입니다. 이 부분에 대해서는 아래 그림을 보면 됩니다.
논문의 그림으로 논문에서는 RPN을 다음과 같이 설명합니다.
즉, attention 처럼 input image에 어디에 집중할지 알려주는 FCN based trainable network입니다.
그럼 이제 RPN에 대해 알아보겠습니다.

Anchor
RPN에 앞서 anchor를 먼저 보겠습니다. 기본의 model들은 sliding window대신 selective search를 사용하였습니다. 이는 시간은 느리지만 확실한 장점이 있기 때문 입니다. sliding window 방식을 사용하게 되면 하나의 size에 대한 RoI만 계산이 됩니다. 다음과 같은 예시를 보면 이해가 됩니다.
예를들어 사람은 세로로 긴 box이고 자동차는 가로로 긴 box입니다. 즉, 물체 마다 bound box의 크기와 비율이 다릅니다. 하지만 sliding window 방식은 같은 크기의 box를 sliding하면서 물체가 있는 곳을 탐지하므로 정확하지 않게 됩니다. 즉, 단일 box로 비율이 다른 물체를 판단한느 것입니다. 따라서 sliding window 방식은 좋지 않습니다.
하지만 sliding window는 convolution입니다. 즉 network로 GPU에서 가속화 됩니다. 따라서 sliding window 방식을 사용하면서 동시에 단일 box 문제를 해결 하기 위해 사용한 방식이 anchor입니다.
각각의 sliding window를 할 때 여러개의 RoI box들을 봅니다. 논문에서는 크기별 3개 비율별 3개 해서 총 9가지의 조합을 사용하였습니다. 따라서 한장의 input image에 대하 9개의 box를 통하여 RoI를 다양하게 계산 할 수 있습니다.
Conv로 VGG-16을 사용하는 경우를 생각해 보겠습니다.
Input image가 800×800이면 feature map size는 50×50이 됩니다. 그럼 50×50개는 모두 anchor입니다. anchor는 닻이라는 뜻입니다. 즉 기준이라고 생각하면 됩니다. 이제 50×50에 각각 9개의 anchor를 만드므로 총 50×50×9개의 anchor가 만들어집니다.
여기서 정확히 anchor란 22500×4의 vector입니다. 22500은 하나의 input image에 대한 anchor이며 각각에는 좌표에 관한 정보가 4개씩 들어가 있습니다. 즉 여기서도 주의해야 할 점이 anchor는 image 혹은 feature map이 아닙니다. 단순히 좌표일 뿐입니다.
이 과정을 anchor generating 이라 하겠습니다.
여기서 생기는 의문이 하나 있는데 끝쪽을 anchor로 잡으면 input image를 벗어나는 box가 생긴다는 것입니다. 이러한 anchor들은 제거합니다.
이 부분은 논문에서 다음과 같이 나와있습니다.
이렇게 선택된 anchor에는 물체가 항상 들어가 있다고 볼 수 없습니다. 오히려 negative가 더 많습니다. 따라서 세가지 기준에 의해 물체가 있는 positive anchor를 선택합니다.
1. IoU가 가장 높은 anchor
2. IoU가 0.7이상인 anchor
3. IoU가 0.3이하이면 non-positive 즉 negative
이때 1번과 2번은 or 입니다. 이렇게만 해도 충분 하지만 특정 상황에서는 0.2인데 positive로 판단 될 수 도 있어 이를 방지하기 위해 3은 and로 추가해 줍니다.
다음 256개의 RoI를 positive, negative를 1:1비율로 mini-batch를 만들어 줍니다. (한장의 image에 대해 RoI는 256보타 훨신 많습니다. 당연히 그중 random select입니다.)
이 과정을 anchor targeting 이라고 하겠습니다.
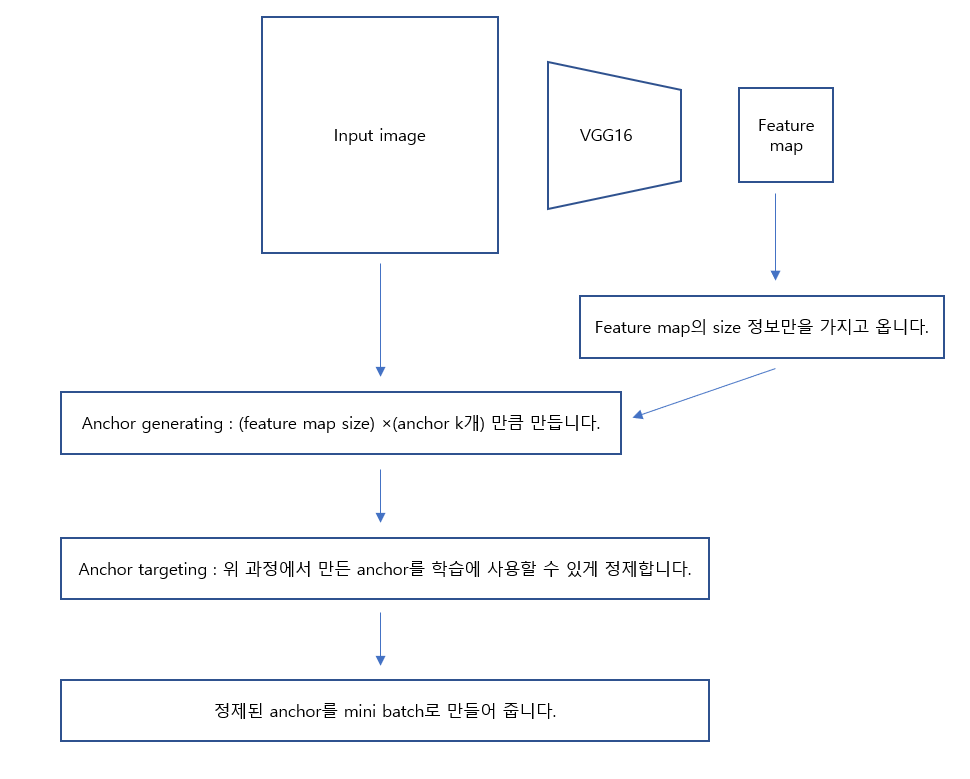
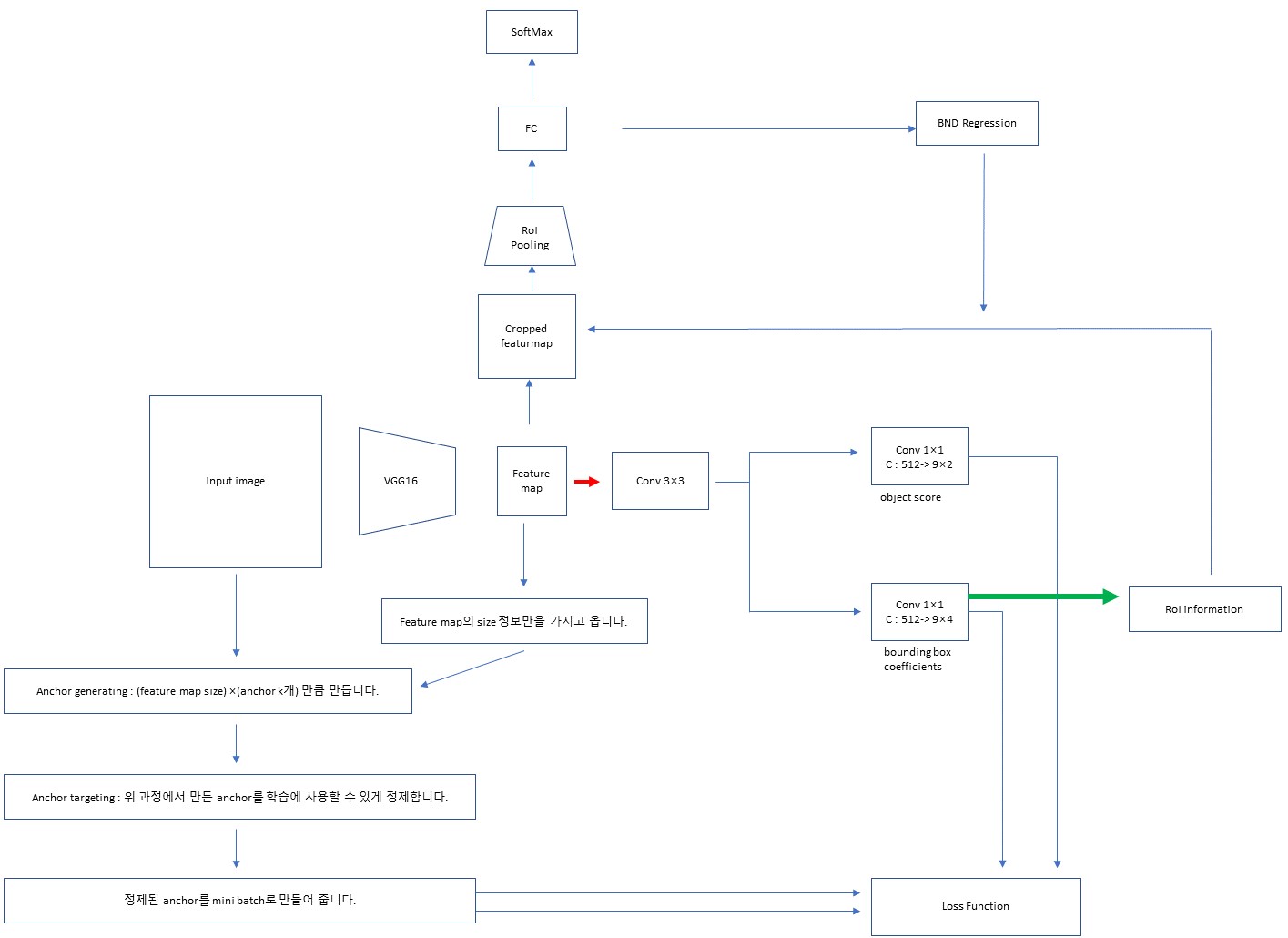
여기까지의 과정을 그림으로 표현 하면 다음과 같습니다.
여기서 VGG는 얼마나 줄어들지에 대한 정보만 필요한 것입니다. channel같은건 신경쓸 필요가 없습니다.
최종 결과는 anchor들의 좌표로 이루어진 mini-batch입니다.

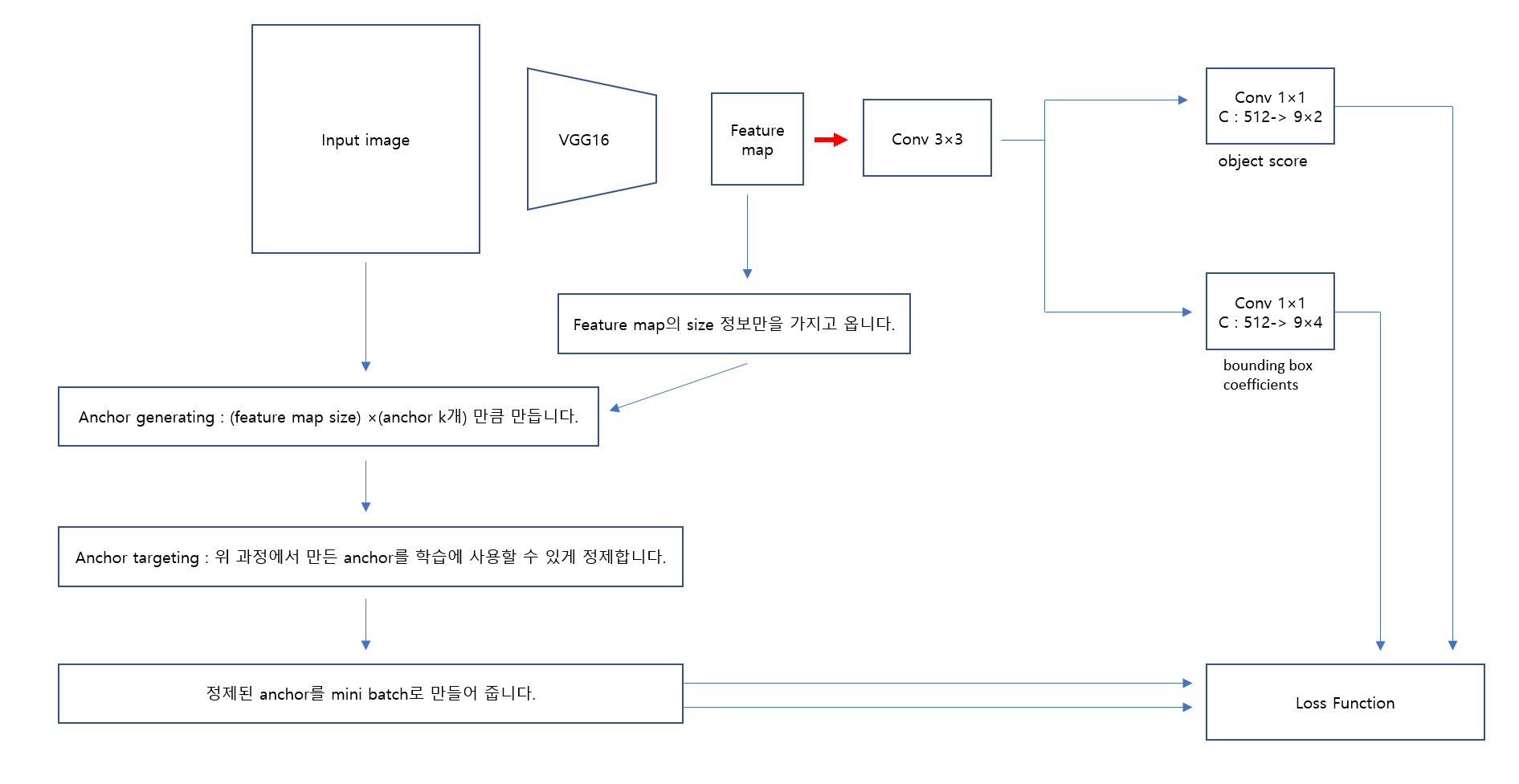
RPN
이제 RPN입니다.
그림을 보면서 설명하겠습니다.
빨간색 부분인 RPN의 시작입니다.
1. Conv를 거쳐 나온 feature map을 conv한번을 더 거칩니다.
2. 이후 FCN 개념인 1×1 conv를 활용하여 bounding box coefficient와 objectness score를 만듭니다.
3. 이후 앞에서 계산 했던 모든 정보를 Loss function에 넣어줍니다.
Loss Function
해당 loss function은 batch까지는 고려하지 않았습니다.
는 anchor index입니다.
앞에서 anchor를 mini-batch로 만드는 과정을 다루었습니다. 보면 하나의 batch에는 하나의 input image에만 mapping됩니다. 따라서 위의 Loss는 하나의 batch이며 이는 곧 하나의 image입니다. 즉, 한장의 iamge에서 나온 anchor는 로만 구분이 가능하다는 것입니다.
는 objectness score 입니다.
는 bounding box coefficient 입니다.
즉 이 둘은 model의 output입니다.
는 target score입니다. 이는 anchor의 positive여부에 따라 0또는 1을 갖게 됩니다.
는 bnd ground truth입니다.
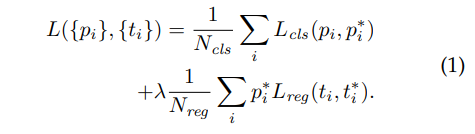
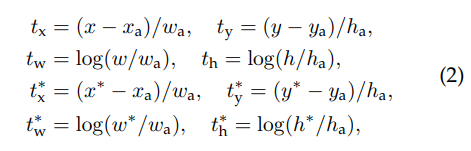
즉, anchor branch은 RPN의 정답을 뽑아주는 역할을 하는 것입니다.
그리고 이 정답에 의해 RPN의 conv들이 정답과 가깝게 output을 산출하게끔 학습되는 것입니다.
이렇게 학습된 RPN은 Input image를 넣었을 때 bounding box coefficient와 objectness score를 반환해 줍니다. 즉, . 여기서 non-maximum suppression (NMS) 을 추가로 적용해 주어 RoI를 줄일 수 있습니다. NMS는 확실하게 RoI의 개수를 줄여주지만 성능에는 별 차이가 없었다고 합니다.

이렇게 하여 Faster R-CNN안의 region proposal model인 RPN을 보았습니다.
3. Fast R-CNN
다시 Fast R-CNN을 보겠습니다.
이제 여기서 selective search를 제거 합니다. 이를 RPN으로 대체하면 됩니다. 이후에는 완전 Fast R-CNN입니다.
즉 간단하게는
입니다.
하지만 training과정까지 합하여 표현 한다면 다음과 같이 표현 됩니다.
원본 사진
https://drive.google.com/file/d/1rwZ1doraTrqDkjkXR-YbH3ZkK9RcpIjJ/view?usp=sharing
4. Training
model을 전체적으로 보면 Faster R-CNN = RPN + Fast R-CNN이라고 하였습니다.
하나 짚고 넘어갈 사실이 있습니다. 위 사진을 보면 VGG는 RPN과 Fast R-CNN학습 과정에 모두 학습가능하는 것입니다. 즉, 이를 공유할 수 있습니다.
Alternating training
번갈아 학습한다는 의미입니다.
우선 RPN을 학습합니다. 이렇게 하면 RoI를 추천해 주니까 이를 이용하여 Fast R-CNN을 학습합니다. 두 과정 모두 pre trained VGG가 fine tuning됩니다. 이를 계속 반복하여 학습니다.
5. 정리
복잡하므로 한번 더 정리해보겠습니다.
RPN
anchor branch에서는 target을 FCN 기반의 conv에서는 output을 산출하고 이를 loss function을 통하여 FCN 기반의 Conv가 학습 됩니다.
Fast R-CNN
trained RPN은 RoI를 output으로 줍니다. 이를 이용하여 feature map size에 맞게 mapping하여 feature map을 crop 합니다. RoI Pooling을 거쳐 fixed vector로 만들고 softmax classification과 bnd regression을 진행합니다.
.png)