Abstract
- Data-driven Model Predictive Control 이 model-free 보다 나은점
- 모델 학습을 통한 개선된 샘플 효율성(sample efficiency)의 잠재성
계획(planning)을 위한 계산 예산(computational budget)이 증가함에 따라 더 나은 성능을 제공
- 그러나 오랜 시간 범위에 걸쳐 계획하는 것은 비용이 많이 들며, 환경의 정확한 모델을 얻는 것은 어려운 과제
- 이 작업에서는 model-free 및 model-based 방법의 강점을 결합
- 우리는
task-oriented latent dynamics model을 사용하여- 짧은 시간 범위 내의 local trajectory optimization를 수행
learned terminal value function를 사용하여,- 장기적인 보상을 추정
- 이 두 가지 요소는
temporal difference learning에 의해 공동으로 학습- temporal difference learning: https://velog.io/@jk01019/temporal-difference-learning
- TD-MPC는 우수한 샘플 효율성과 점진적인 성능을 달성
Introduction
- model-based 방법에 대한 이전 연구는 주로 두 가지 방향으로 세분화
- 각각은 모델 기반 학습의 주요 이점을 활용
- (i) 계획(planning): 학습된 정책에 비해 이점을 갖지만, 오랜 시간 범위에 걸쳐 계획하는 것은 지나치게 비용이 많이 듦
- (ii)
학습된 모델을 사용하여 생성된 롤아웃에서 학습함으로써, model-free 방법의 샘플 효율성을 향상시키려고 함. - 그러나 이렇게 하면 모델 편향이 policy에도 전파될 가능성이 높음
- 따라서 모델 기반 방법은 과거에 연속 제어 작업에서 더 간단한 모델 무관 방법보다 우수한 성능을 내기 어려웠음
- 대신에 model-based 계획을 model-free 학습의 강점으로 보강할 수 있을까요?
- 오랜 시간 범위의 계획이 매우 비용이 많이 들기 때문에
- 모델 예측 제어(Model Predictive Control, MPC)는 더 짧은 유한 시간 범위 내에서 궤적을 최적화하며, 이는 시간적으로 지역적인 최적해만을 얻게 됨
- MPC는 계획 범위를 넘어선 discounted return을 추정하는
value function함수를 사용하여 전역적으로 최적의 해를 근사화할 수 있음 - 그러나 정확한 model과 value function를 얻는 것은 어려울 수 있습니다.
- 본 연구에서는 Temporal Difference Learning for Model Predictive Control (TD-MPC)라는 데이터 기반 MPC 프레임워크를 제안
- 이 프레임워크는
task-oriented latent dynamics model과learned terminal value function를 사용하여 temporal difference(TD) 학습을 통해 공동으로 학습하는 것 - 각 결정 단계에서 우리는
학습된 모델이 생성한 short-term reward estimates 를 사용하여 궤적 최적화를 수행- long-term return estimates에는 learned value function를 사용
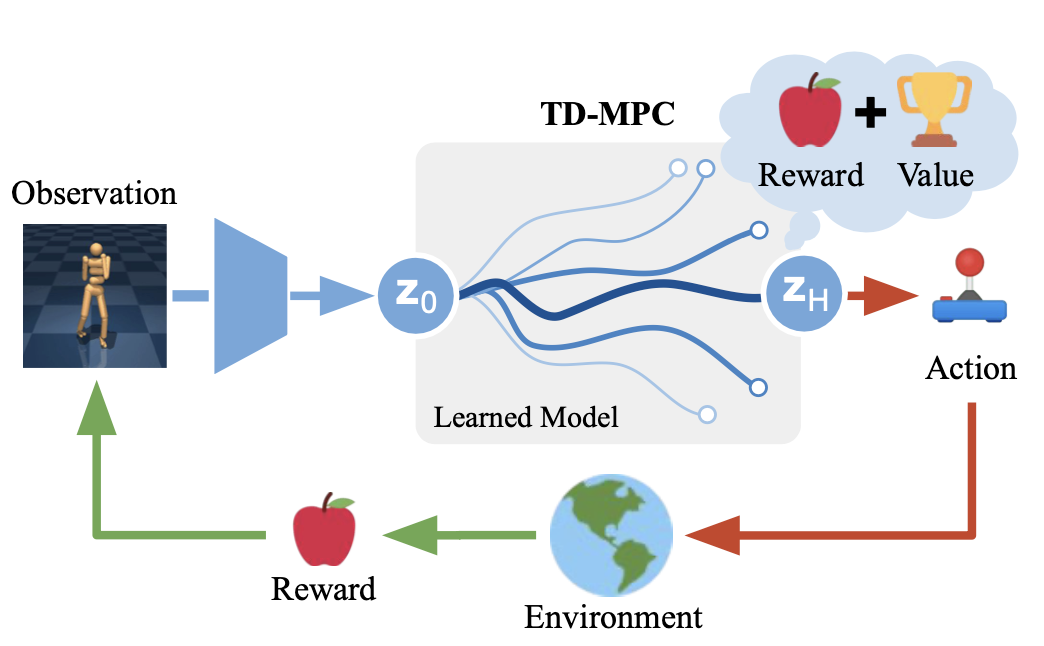
- 예를 들어 Figure 1에 나타난 Humanoid 이동 작업에서는
task-oriented latent dynamics model을 사용하여 정확한 관절 움직임을 계획하는 것이 유익할 수 있으며,- 더 높은 수준의 목표인 달리기 방향은 장기적인
learned terminal value function에 따라 안내될 수 있습니다.
- 주요 기술적 기여는 모델 학습 방식
- 이전 연구에서는
상태나 비디오 예측을 통해 모델을 학습하는 반면, 우리는 모든 것을 모델링하는 것이 효율적이지 않다고 주장- 이는 관련 없는 (그림자와 같은) 관련없는
quantities and visuals 요소를 포함하여 환경 전체를 모델링하는 것은 모델의 부정확성과 오차의 누적을 야기하기 때문
- 이전 연구에서는
- 이러한 도전을 극복하기 위해 모델 학습에 세 가지 주요 변경 사항을 도입
- 첫째, we learn the
latent representation of the dynamics modelpurely from rewards, ignoring nuances unnecessary for the task at hand.- 이는 상태/이미지 예측보다 학습이 더 샘플 효율적이게 만듦.
- 둘째, 우리는 reward 및 TD-objective 을 모델의 여러 롤아웃 단계에 걸쳐 역전파하여
- long horizons에서
reward and value predictions을 향상시킴. - 이는 롤아웃을 수행할 때 오류 누적을 줄여줍니다.
- long horizons에서
- 마지막으로, 우리는 (explicit state 혹은 image prediction 없이) learned representation에서
시간적 일관성을 강제하는, modality-agnostic(비구체적)latent space에서의 prediction loss을 제안 - Lastly, we propose a
modality-agnostic prediction loss in latent spacethat enforces temporal consistency in the learned representation without explicit state or image prediction.
- 첫째, we learn the

새로운 것이 들어오면 이미 있는 것과 충돌을 시도하라.