
ImageNet Classification with Deep Convolutional Neural Networks (2012) 논문을 읽고. .
이 논문에서는 AlexNet이라는 이름이 직접적으로 등장하지는 않지만, 이 논문이 말하고자 하는 모델이 AlexNet인 이유는 논문의 1차 저자인 Alex Krizhevsky의 이름을 땄기 때문이다.
ResNet이 핵심 아이디어인 잔차 학습(Resdual Learning)에서 이름을 따온 것 처럼 말이다.
1. Introduction
이전에는 객체 인식에 대한 접근은 머신러닝 방식을 꼭 필수적으로 이용해야 했다. 해당 접근 방식의 효율을 높이기 위해서는 더 큰 양의 데이터셋을 수집하고 더 강력한 모델을 사용해야 한다.
"Simple Recognition tasks can be solved quite well with datasets of this size, especially if they are augmented with label-preserving transformations."
단순 Recognition과 같은 경우에는 데이터 증강을 이용하여적은 양의 데이터로도 꽤 잘 해결될 수 있었다.
📌데이터 증강이란?
원본 데이터로부터 새로운 데이터를 만들어내는 것을 말한다. 이 때 새로운 데이터는 원본 데이터의 특성을 그대로 반영해야 하는데 사용하는 데이터의 종류에 따라 특성이 달라진다.
이미지 데이터 증강으로는 회전, 밝기 조절, 노이즈 삽입 등이 있다.
하지만 단순 Recognition말고 현실 세계에 있는 Object들을 Recognition하려면 더 다양한 요소들을 고려해야 하기 때문에 더 큰 Training Set을 필요로 한다.
때문에 적은 이미지 데이터셋의 단점은 널리 알려져 있는데 이를 위한 해결책으로 LabelMe나 ImageNet처럼 수십, 수백만 개의 이미지를 가진 대규모 데이터셋이 등장하여 AlexNet은 이런 거대한 데이터셋을 사용하여 뛰어난 성능을 도출한다.
몇백만개의 이미지에서 수천개의 object들을 검출하는 것을 알기 위해서는 우리는 대규모 학습이 가능한 model이 필요하다 그러나 Object Recognition작업의 복잡성은 이 문제가 ImageNet과 같은 대규모 데이터셋으로도 구체화를 할 수 없기에 대규모 학습 능력과 상당한 사전 지식을 갖춘 모델이 필요하다.
"To learn about thousands of objects from millions of images, we need a model with a large larning capacity. However, the immense complexity of the object recognition task means that this problem cannot be specified even by a dataset as large as ImageNet, so our model should also have lots of prior knowledge to compensate for all the data we don't have. "
여기서 말하는 사전 지식이란 모델이 이러한 한계를 극복하도록 개발자가 인간의 지식을 구조적으로 모델에게 심어준 것을 말한다.
CNN의 경우 이 사전 지식은 다음과 같은 구조적 설계에 해당한다.
- 합성곱 (Convolution)
- 풀링 (Pooling)
- 계층 구조
이러한 설계 자체가 바로 "이미지란 원래 이런 특성을 가지고 있다."는 인간의 사전 지식을 모델에 부여한 것이다. 덕분에 모델은 한정된 데이터로도 훨씬 더 효율적으로 학습하고 처음 보는 이미지에 대해서도 일반화하여 잘 예측을 수행한다.
CNN은 모델의 깊이와 넓이를 조정하여 model의 capacity가 컨트롤 될 수 있고 이미지의 본질에 대해 보다 더 정확하고 강력한 예측을 수행할 수 있다. 따라서 일반적인 FeedForward 신경망과 비교 했을 때 CNN은 connection과 파라미터가 더 적기 때문에 훈련하기에는 더 쉽다.
CNN의 이러한 매력적인 특성에도 불구하고 당시의 CPU 병렬 처리 능력으로는 고해상도 이미지에 대규모로 적용하기에는 계산 비용을 감당하기 힘들었을 것이다.
(수정 필요)본 논문은 이러한 한계를 극복하기 위해 고안된 AlexNet이라는 심층 합성곱 신경망에 대해 말한다. (수정 필요)
2. The Dataset
ILSVRC란?
- ILSVRC(Image Large-Scale Visual Recognition Challenge)는 ImageNet의 하위 집합 을 사용하며, 각 1000개 카테고리 당 약 1000개의 이미지를 포함한다.
총 약 120만개의 Train, 5만개의 Validation, 15만 개의 Test이미지로 구성된 데이터셋이다.- ImageNet 데이터셋을 사용하는데 최종적으로 256x256 사이즈의 down-sampled 된 이미지들을 얻기 위해서 다음과 같은 전처리를 사용한다.
- Rescaling
- Crop out the central
22,000개의 카테고리, 150만개의 이미지들로 구성된 ImageNet 데이터셋을 먼저 짧은쪽의 길이를 256 픽셀로 맞추는 Rescaling 과정을 거치고 가운데를 중심으로 Crop을 진행한다.
3. The Architecture
ReLU Nonlinearity
**AlexNet이 사용한 ReLU함수를 살펴보기 이전, Sigmoid와 Tanh함수를 살펴볼 필요가 있다.**
지금까지는 활성화 함수로 Sigmoid함수와 Tanh함수를 사용했다.
하지만 두 함수에는 Gradient Vanishing (기울기 소실) 문제가 발생한다.
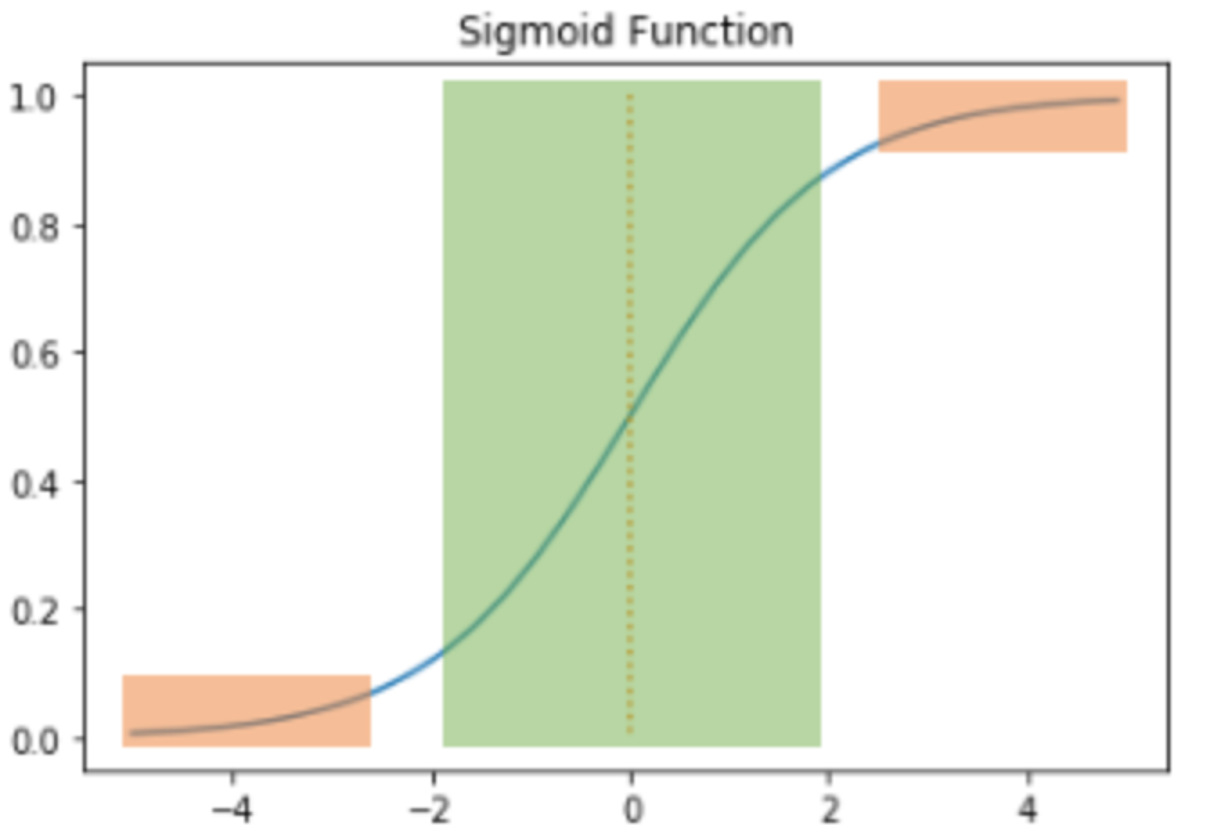
Sigmoid 함수
Sigmoid 함수의 출력값이 0 또는 1에 가까워지면, 그래프의 기울기가 완만해지는 현상이 나타난다.
주황색 : 기울기가 완만해지는 구간
초록색 : 그렇지 않은 구간
추황색 구간에서는 미분값이 0에 가까운 아주 작은 값이고 초록색 구간에서의 미분값은 최대값이 0.25이다.
다시 말해 Sigmoid함수를 미분한 값은 적어도 0.25이하의 값이다. Sigmoid를 활성화 함수로 하는 인공 신경망에 층을 쌓는다면 가중치와 편향을 업데이트 하는 과정인 역전파 과정에서 0에 가까운 값이 누적해서 곱해지면서, 앞단에는 기울기(미분값)가 전달되지 않게 된다.
그것이 바로 기울기 소실 (Gradient Vanishing) 현상이라고 말한다.
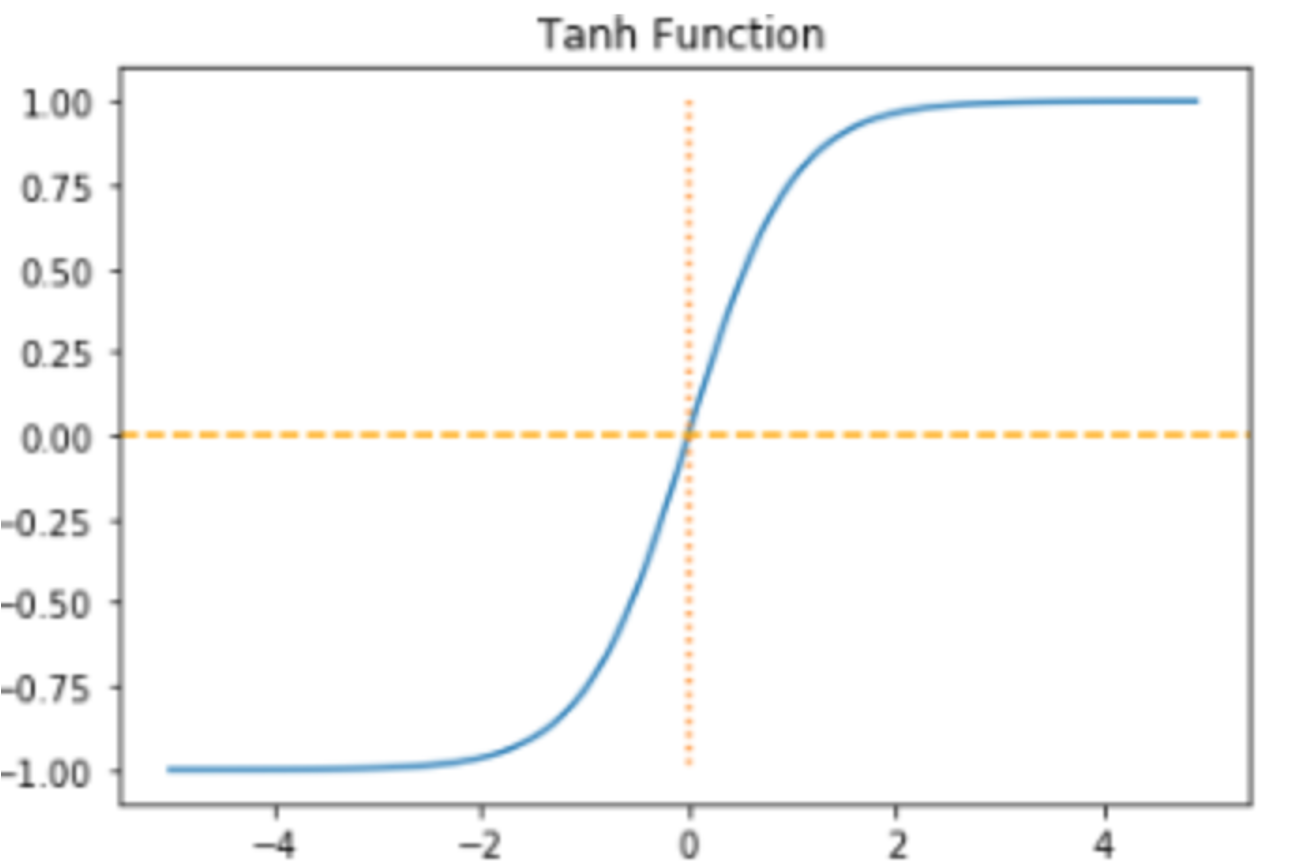
Tanh 함수
Tanh함수도 -1과 1에 가까운 출력값을 출력할 때 Sigmoid와 마찬가지로 같은 문제가 발생한다.
그러나 tanh같은 경우에는 sigmoid와 달리 0을 중심으로 하고 있으며 tanh를 미분했을 때의 최대값은 1로 sigmoid의 최대값이 0.25보다는 크다.
즉 미분했을 때 Sigmoid보다는 전반적으로 큰 값이 나오게 된다.
- Sigmoid보다는 기울기 소실 증상이 적은 편이어서 simgoid보다는 선호되는 함수이다.
ReLU 함수
Sigmoid 함수와 Tanh 함수는 위에서 언급했듯, 활성화 함수로 사용했을 때 Gradient Vanishing으로 인해 파라미터 업데이트 속도가 저하되어 학습 속도 또한 같이 저하되는 현상이 발생되었다.
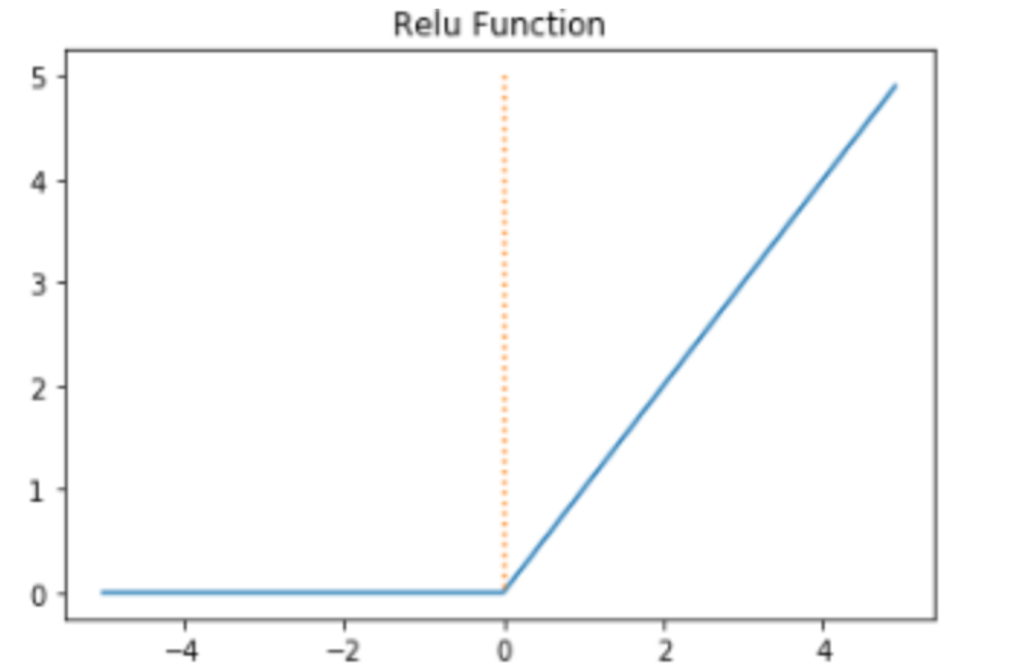
ReLU 함수는 로, 양수일 때 기울기가 항상 1이다. 다시 말해서 input-value가 양수일 때 output 을 input-value 그대로 반환하는 특성이 있다.
이는 Back Propagation 과정 시에 loss function에 대한 가중치 기울기 그대로 변환하여 sigmoid, tanh보다 빠른 성능을 보인다.
그럼 ReLU를 사용했을 때는?
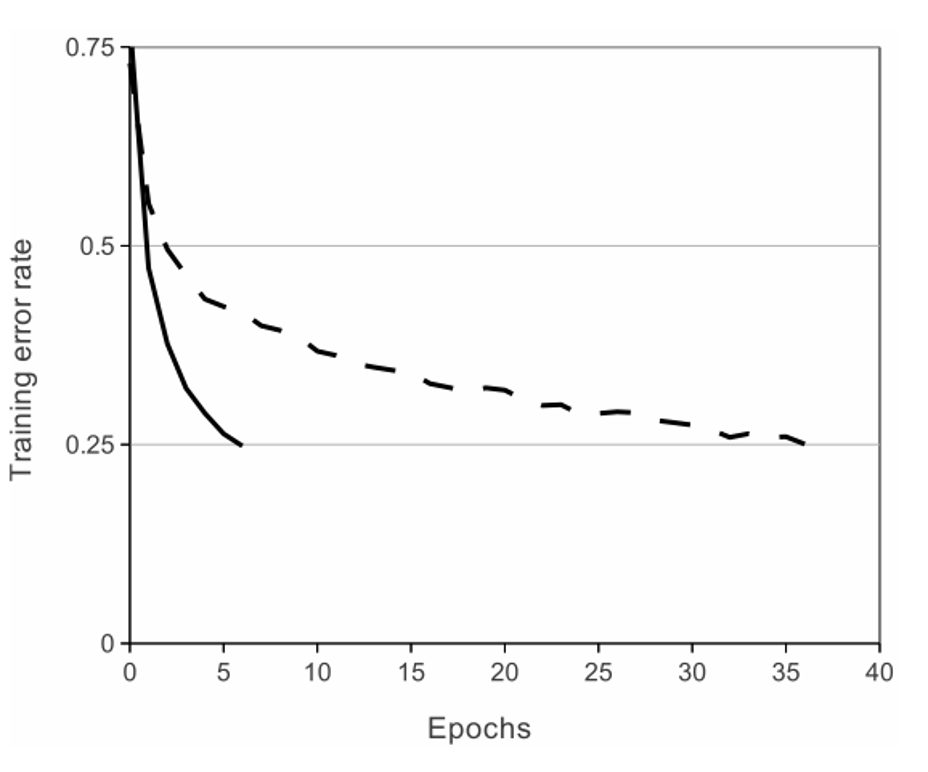
AlexNet이 사용한 ReLU함수를 사용했을 때와 Tanh함수를 사용했을 때의 성능차이를 알아보자.
다음은 Error Rate가 0.25. 즉, Accuracy가 75%에 도달하기 위해 필요한 Epoch의 수를 보인다.
실선은 ReLU, 점선은 Tanh함수인데 Tanh보다 ReLU가 약 6배 빠르게 수렴하는 것을 보인다.
3-1. Training on Multiple GPUs
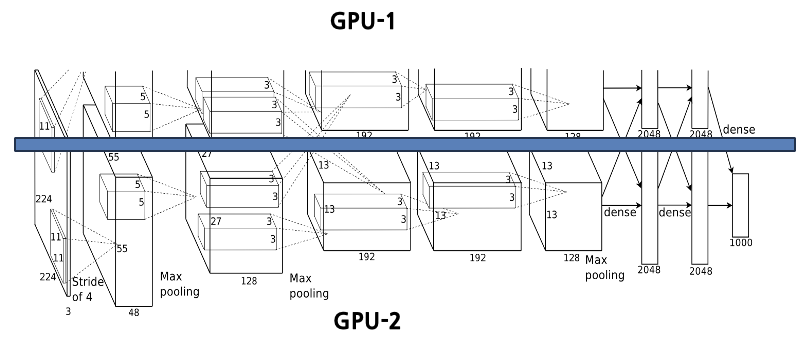
AlexNet은 메모리 한계라는 물리적 제약을 극복하고 잊껏 없던 큰 딥러닝 모델을 구현하기 위해 두개의 GPU 모델을 사용하였다.
두개의 모델을 사용하면서 생기는 변화와 상세한 아키텍쳐는 밑에서 추가로 설명하겠다.
3-2. Local Response Normalization (LRN)

LRN에 대해 설명하기 전에 먼저 위 그림을 한번 보자.
위 그림을 보면 검정색 사각형 말고 흰색 격자에 회색 점이 보이는 착시 현상이 생긴다.
이는 검정색이 눈으로 들어올 때 시각 정보가 자극적이기 떄문에 주변의 흰색 격자도 회색으로 보이는 현상이다.
실제 뇌세포의 증상으로, 강한 뉴런의 활성화가 근처 다른 뉴런의 활동을 억제 시키는 현상인데 LRN은 이 원리를 인공신경망에 그대로 적용하였다.
특정 Feature map에서 한 픽셀의 활성화 값이 유난히 클 경우, 그 주변 픽셀들의 활성화 값을 억제하여 해당 픽셀의 특징이 더욱 두드러지게 만드는 효과를 가져온다.
방금 위에서 ReLU함수를 설명할 때 input값 그대로 output값으로 반환하는 특성이 있다고 했다.
만약 ReLU함수가 막대한 크기의 input을 받으면 해당 input의 크기를 그대로 output으로 반환할 것이기 때문에 해당 증상과 연관 시켜서 이해하면 좋을 것이다.
Local Response Normalizatoin (LRN) 통해 모델의 일반화 성능을 높이고 과적합을 방지한다
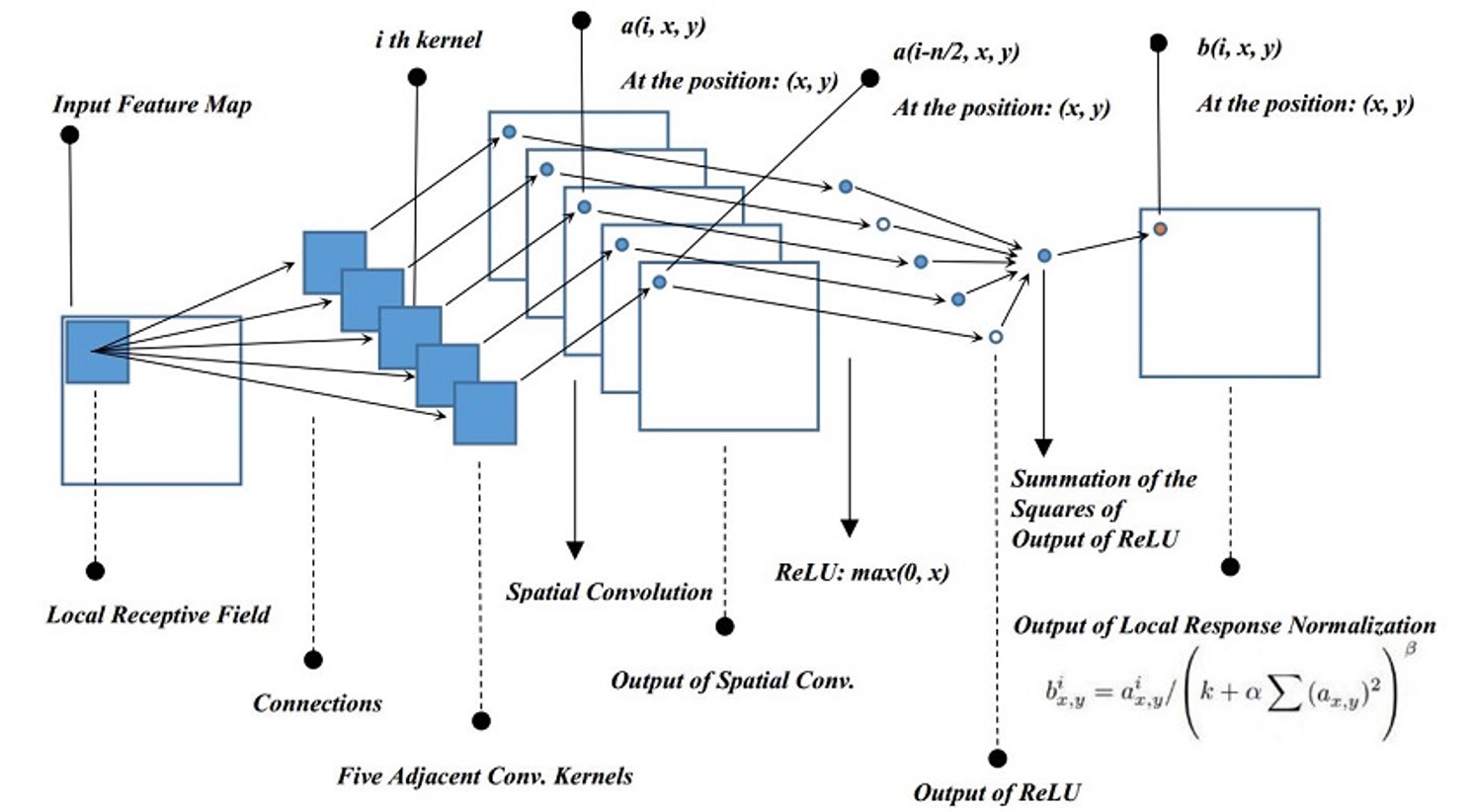 그림이 매우 복잡해 보이겠지만 현재 픽셀의 값을 주변 픽셀 값들의 제곱 합으로 나누어주는 방식이라고 이해하면 된다.
그림이 매우 복잡해 보이겠지만 현재 픽셀의 값을 주변 픽셀 값들의 제곱 합으로 나누어주는 방식이라고 이해하면 된다.
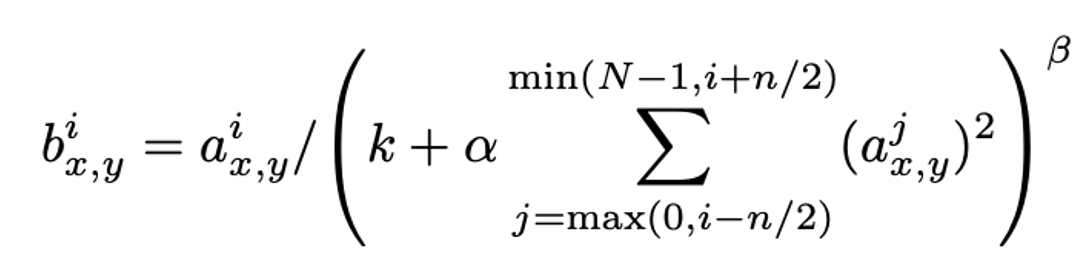
, , 은 모두 사용자가 정의하는 하이퍼파라미터 상수이다.
은 전체 채널의 개수이며, 해당 논문에서는 로 설정하였다.
3-3. Overlapping Pooling
논문에서 나온 Overlapping Pooling을 알아보기 전에 기본적인 Pooling의 개념을 간단히 말해보자면 Down Sampling의 한 종류로, Convolutional Layer를 통과한 후 얻은 Feature map의 크기를 줄이는 과정이다.
보통 Convolutional 층 뒤에 따르며 Max Pooling과 Avg Pooling으로 나눌 수 있다.
Feature map에는 인식이 불필요할 정도로 지나치게 상세한 내용이 많은데 풀링은 상세함을 줄이는 효과와 특징 맵의 크기를 줄여 신경망의 효율을 높이는 효과를 제공한다.
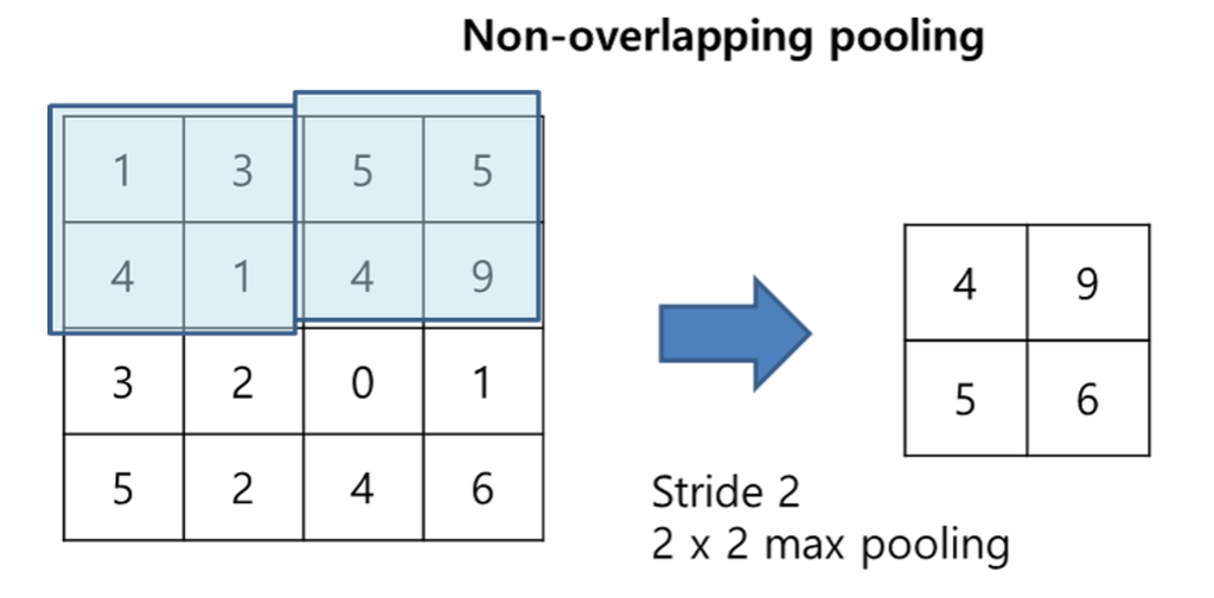
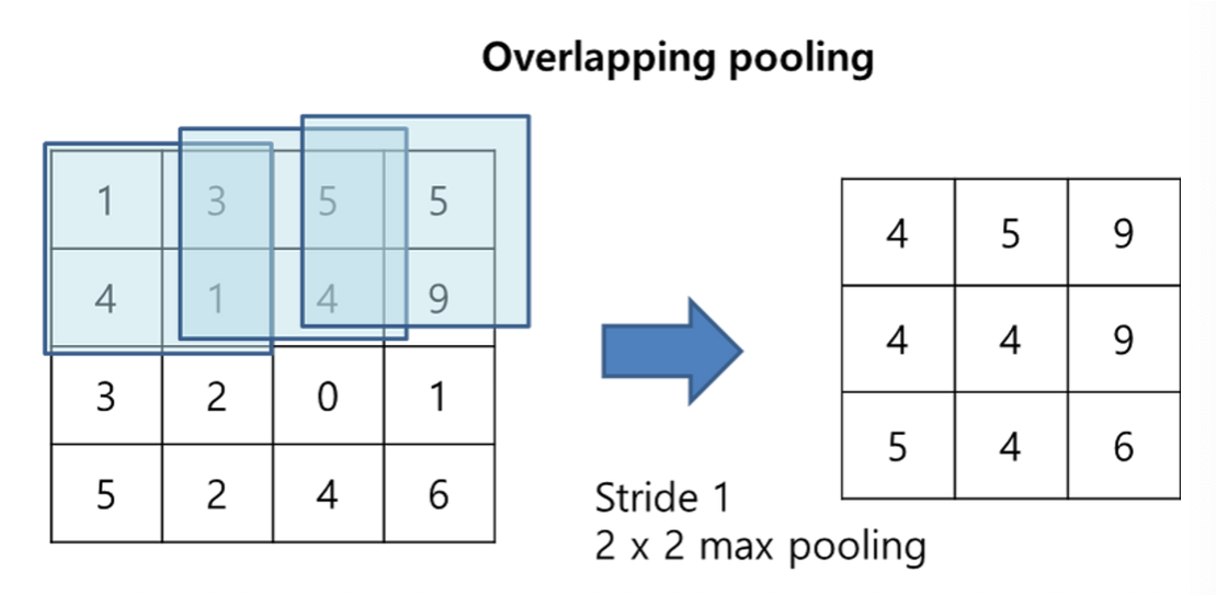
Stride란 Convolutional Filter 혹은 풀링 윈도우가 입력 데이터 위를 이동할 때 한번에 몇 칸을 건너 뛰며 움직이는지를 나타낸다. 이 또한 계산을 통해 구해지는 것이 아니라 하이퍼 파라미터이다.
그럼 왜 Overlapping Pooling을 사용했을까?
바로 과적합 감소와 정확도 향상의 목적이 있다.
📌과적합 감소 : 윈도우가 겹치면서 여러 번 계산에 포함되는 데이터가 생긴다. 이는 모델이 특정 픽셀의 위치에 너무 의존하지 않도록 만들어 정규화 효과를 준다.
📌정확도 향상 : 논문에서는 Overlapping Pooling을 사용하면 사용하지 않은 것보다 Top-1, Top-5 Error가 0.4, 0.3% 감소한 것을 확인하였다.
3-4. Overall Architecture
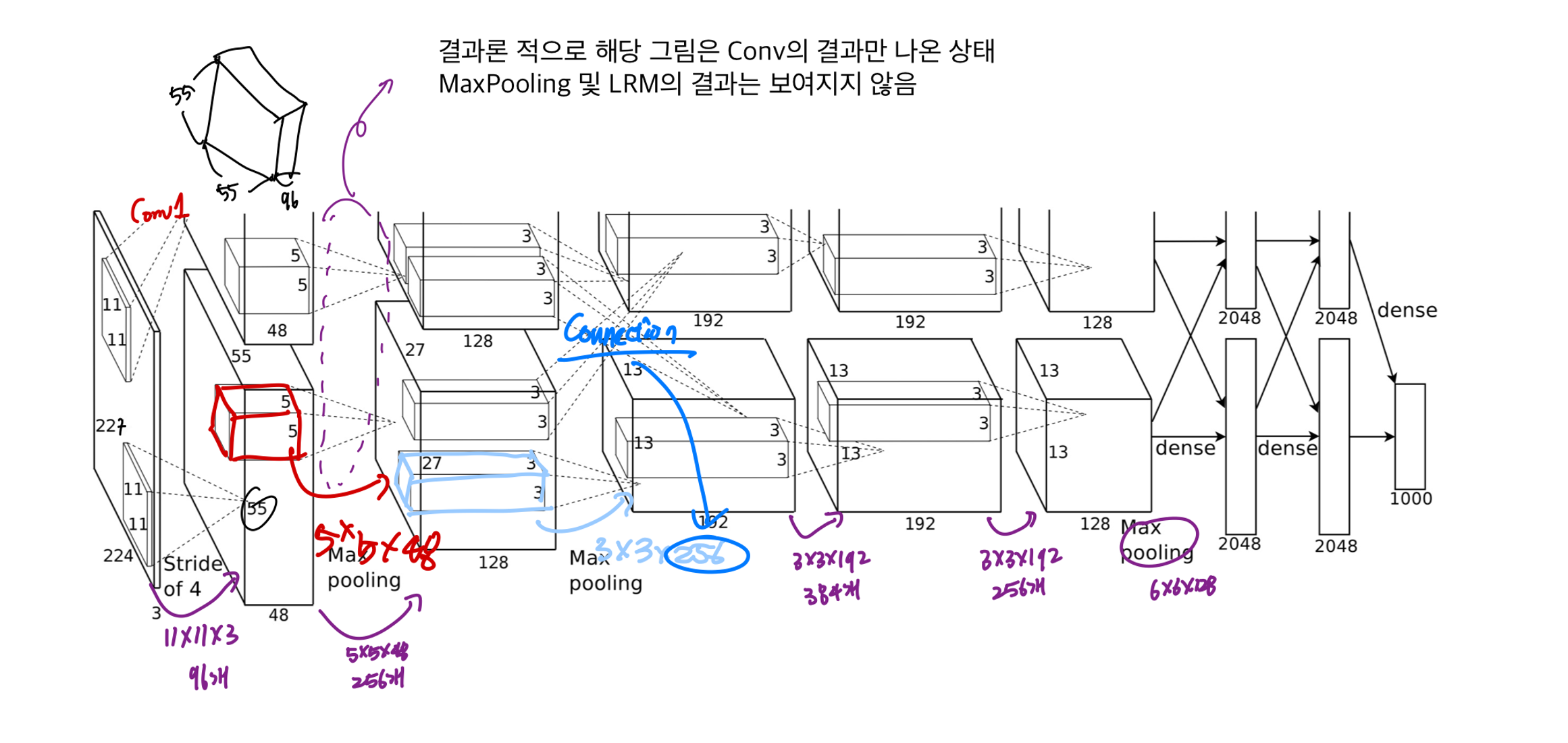
코드 구현
이번 실습은 AlexNet을 구현하는데에 그치지 않고 Batch Normalization(BN)의 유무에 따른 성능 차이를 비교해보겠습니다.
Datasets
!wget https://s3.amazonaws.com/fast-ai-imageclas/imagenette2-320.tgz
!tar -xzf imagenette2-320.tgzpreprocessing
train_transform = transforms.Compose([
transforms.RandomResizedCrop([227, 227]),
transforms.RandomHorizontalFlip(p=0.5),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
val_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(227),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])CustomDataset
class CustomDataset(Dataset):
def __init__(self, root_dir, mode='train', csv_file=None, transform=None, class_map=None, class_to_idx=None):
self.root_dir = root_dir
self.mode = mode
self.transform = transform
self.class_map = class_map # class_map을 인스턴스 속성으로 저장
self.class_to_idx = class_to_idx # class_to_idx를 인스턴스 속성으로 저장
self.data_list=[]
self.labels=[]
if self.mode=='train':
if self.class_map is None:
raise ValueError("class_map must be provided for 'train' mode.")
folder_key = list(self.class_map.keys())
for label_idx, folder_name in enumerate(folder_key):
class_path = os.path.join(self.root_dir, 'train', folder_name) # 'train' 디렉토리 추가
if not os.path.isdir(class_path): continue
image_names = [f for f in os.listdir(class_path) if f.endswith('.JPEG')]
for img_name in image_names:
full_path = os.path.join(class_path, img_name)
self.data_list.append(full_path)
self.labels.append(label_idx)
elif self.mode=='val':
if csv_file is None:
raise ValueError("csv_file must be provided for 'val' mode.")
if self.class_to_idx is None:
raise ValueError("class_to_idx must be provided for 'val' mode.")
csv_file_full_path = os.path.join(self.root_dir, csv_file)
df = pd.read_csv(csv_file_full_path)
# Filter out entries where class_name is not in class_to_idx
valid_entries = df[df['noisy_labels_0'].isin(self.class_to_idx.keys())]
# Corrected: Use 'path' column instead of 'filename'
self.data_list = [os.path.join(self.root_dir, f) for f in valid_entries['path']]
# Corrected: Use 'noisy_labels_0' as the label column based on observation
self.labels = [self.class_to_idx[class_name] for class_name in valid_entries['noisy_labels_0']]
def __len__(self):
return len(self.data_list)
def __getitem__(self, idx):
img_path = self.data_list[idx]
img = Image.open(img_path).convert("RGB")
if self.transform:
img=self.transform(img)
label = self.labels[idx]
return img, labelDataset & DataLoader
train_dataset = CustomDataset(root_dir = path, mode='train', transform=train_transform, class_map=class_map, class_to_idx=class_to_idx)
val_dataset = CustomDataset(root_dir=path, mode='val', csv_file='noisy_imagenette.csv', transform=val_transform, class_map=class_map, class_to_idx=class_to_idx)train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True, num_workers=2)
val_loader = DataLoader(val_dataset, batch_size=128, shuffle=False, num_workers=2)Network
class AlexNet_custom(nn.Module):
def __init__(self, num_classes=1000, use_bn=True):
super().__init__()
self.use_bn = use_bn
layers=[]
layers.append(nn.Conv2d(3, 96, kernel_size=11, stride=4, padding=0))
if self.use_bn: layers.append(nn.BatchNorm2d(96))
layers.append(nn.ReLU(inplace=True))
layers.append(nn.MaxPool2d(kernel_size=3, stride=2))
layers.append(nn.Conv2d(96, 256, kernel_size=5, stride=1, padding=2))
if self.use_bn: layers.append(nn.BatchNorm2d(256))
layers.append(nn.ReLU(inplace=True))
layers.append(nn.MaxPool2d(kernel_size=3, stride=2))
layers.append(nn.Conv2d(256, 384, kernel_size=3, stride=1, padding=1))
if self.use_bn: layers.append(nn.BatchNorm2d(384))
layers.append(nn.ReLU(inplace=True))
layers.append(nn.Conv2d(384, 384, kernel_size=3, stride=1, padding=1))
if self.use_bn: layers.append(nn.BatchNorm2d(384))
layers.append(nn.ReLU(inplace=True))
layers.append(nn.Conv2d(384, 256, kernel_size=3, stride=1, padding=1))
if self.use_bn: layers.append(nn.BatchNorm2d(256))
layers.append(nn.ReLU(inplace=True))
layers.append(nn.MaxPool2d(kernel_size=3, stride=2))
self.features = nn.Sequential(*layers)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return xBatch Normalization의 성능을 비교하기 위해, 두 개의 모델을 선언해주겠습니다.
model_with_bn = AlexNet_custom(num_classes=10, use_bn=True)
model_without_bn = AlexNet_custom(num_classes=10, use_bn=False)Optimizer & Loss Function
criterion = nn.CrossEntropyLoss()
optimizer_bn = torch.optim.SGD(model_with_bn.parameters(), lr=0.001, momentum=0.9, weight_decay=0.0005)
optimizer_without_bn = torch.optim.SGD(model_without_bn.parameters(), lr=0.001, momentum=0.9, weight_decay=0.0005)Train function
def train(model, train_loader, optimizer, criterion, epoch):
model.train()
running_loss = 0.0
correct = 0
total = 0
for batch_idx, (inputs, targets) in enumerate(train_loader):
inputs, targets = inputs.to(device), targets.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
if model == model_with_bn:
train_losses_bn.append(loss.item())
elif model == model_without_bn:
train_losses_without_bn.append(loss.item())
running_loss += loss.item() # To accumulate the loss value of each mini-batch into a running total.
_, predicted = torch.max(outputs.data, 1)# To get index of predicted class
# : return the index of maximum value of dim=1 (Each row)
# _ : the probability (the real value of maximum) is not usefull. -> Abandon
# predicted : This is the value what we need. (The index of Maximum value.)
total += targets.size(0) # accmulate the number of data of current batch.
correct += (predicted == targets).sum().item()
epoch_loss = running_loss / len(train_loader)
epoch_acc = 100 * correct / total
print(f"Epoch {epoch} : 평균 Loss : {running_loss / len(train_loader)}")
return epoch_loss, epoch_accValidation Function
def val(model, val_loader, criterion, epoch):
model.eval()
total_val_loss = 0.0 # Accumulator for total loss across batches
correct = 0
total = 0
with torch.no_grad():
for inputs, targets in val_loader:
inputs, targets = inputs.to(device), targets.to(device)
outputs = model(inputs)
loss = criterion(outputs, targets)
total_val_loss += loss.item() # Accumulate batch loss
_, predicted = torch.max(outputs.data, 1)
total += targets.size(0)
correct += (predicted == targets).sum().item()
avg_epoch_val_loss = total_val_loss / len(val_loader) # Average loss for the epoch
accuracy = 100 * correct / total
print(f"Validation Accuracy : {accuracy : .2f}%")
return avg_epoch_val_loss, accuracy # Return average loss and accuracyTest Function
def test(model, test_loader, criterion):
model.eval()
test_loss = 0.0
correct = 0
total = 0
with torch.to_grad():
for inputs, targets in test_loader:
inputs, targets = inputs.to(device), targets.to(device)
outputs = model(inputs)
loss = criterion(outputs, targets)
test_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += targets.size(0)
correct += (predicted == targets).sum().item()
accuracy = 100 * correct / total
print(f"Test Accuracy : {accuracy :.2f}%")
return accuracyTrain & Valid
import copy
best_acc_bn = 0.0
best_model_wts_bn = copy.deepcopy(model_with_bn.state_dict())
history_bn = {'train_loss': [], 'train_acc': [], 'val_loss': [], 'val_acc': []} # Added 'val_loss'
best_acc_nobn = 0.0
best_model_wts_nobn = copy.deepcopy(model_without_bn.state_dict())
history_nobn = {'train_loss': [], 'train_acc': [], 'val_loss': [], 'val_acc': []} # Added 'val_loss'
train_losses_bn = []
train_losses_without_bn = []
num_epochs = 20
for epoch in range(num_epochs):
print(f"\nExample Epoch {epoch+1}/{num_epochs}")
print(f"[Model 1: With BN]")
# Train
loss_bn, acc_bn = train(model_with_bn, train_loader, optimizer_bn, criterion, epoch)
# Validate
epoch_val_loss_bn, val_acc_bn = val(model_with_bn, val_loader, criterion, epoch) # Get both loss and accuracy
history_bn['train_loss'].append(loss_bn)
history_bn['train_acc'].append(acc_bn)
history_bn['val_loss'].append(epoch_val_loss_bn) # Append returned epoch val loss
history_bn['val_acc'].append(val_acc_bn)
if val_acc_bn > best_acc_bn:
best_acc_bn = val_acc_bn
best_model_wts_bn = copy.deepcopy(model_with_bn.state_dict())
print(f"[Model 2: Without BN]")
# Train
loss_nobn, acc_nobn = train(model_without_bn, train_loader, optimizer_without_bn, criterion, epoch)
# Validate
epoch_val_loss_nobn, val_acc_nobn = val(model_without_bn, val_loader, criterion, epoch) # Get both loss and accuracy
history_nobn['train_loss'].append(loss_nobn)
history_nobn['train_acc'].append(acc_nobn)
history_nobn['val_loss'].append(epoch_val_loss_nobn) # Append returned epoch val loss
history_nobn['val_acc'].append(val_acc_nobn)
if val_acc_nobn > best_acc_nobn:
best_acc_nobn = val_acc_nobn
best_model_wts_nobn = copy.deepcopy(model_without_bn.state_dict())
model_with_bn.load_state_dict(best_model_wts_bn)
model_without_bn.load_state_dict(best_model_wts_nobn)
print(f"최종 결과 - With BN Best Acc: {best_acc_bn:.2f}%")
print(f"최종 결과 - Without BN Best Acc: {best_acc_nobn:.2f}%")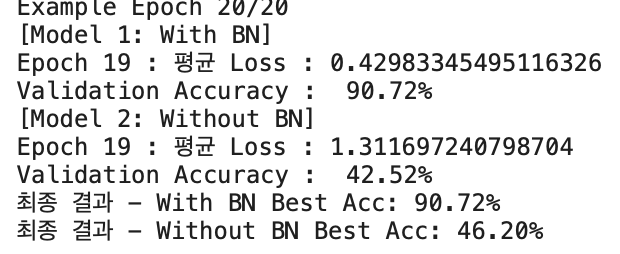
아래 구간 부터는 대화형 인공지능을 활용한 구간입니다.
- 본 데이터셋은 이미 정답지가 csv파일 형태로 제공되어 해당 csv파일을 통해 정답을 메기는 방식입니다.
- Kaggle, Dacon과 같이 채점을 맡길 수 있는 사이트가 없다고 판단되어 대화형 인공지능 GEMINI를 이용하여 해당 모델의 정확도를 판단하겠습니다.
- 따라서 아래 성능 추출 및 최종 결과 리포트까지 인공지능을 활용하여 코드를 작성하였습니다.
import pandas as pd
import numpy as np
import os
import torch
def get_predictions(model, loader, device):
model.eval()
preds_list = []
targets_list = []
with torch.no_grad():
for inputs, targets in loader:
inputs = inputs.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1)
preds_list.extend(predicted.cpu().numpy())
targets_list.extend(targets.cpu().numpy())
return preds_list, targets_list
print("Model 1 (With BN) 예측 중...")
preds_bn, targets_common = get_predictions(model_with_bn, val_loader, device)
print("Model 2 (Without BN) 예측 중...")
preds_nobn, _ = get_predictions(model_without_bn, val_loader, device)
full_file_paths = val_dataset.data_list
relative_file_paths = [p.replace(val_dataset.root_dir + os.sep, '') for p in full_file_paths]
submission_df = pd.DataFrame({
'file_path': relative_file_paths,
'target': targets_common,
'pred_with_bn': preds_bn,
'pred_no_bn': preds_nobn
})
acc_bn = (submission_df['target'] == submission_df['pred_with_bn']).sum() / len(submission_df) * 100
acc_nobn = (submission_df['target'] == submission_df['pred_no_bn']).sum() / len(submission_df) * 100 # Corrected column name
print("-" * 50)
print(f" - Model With BN 정확도 : {acc_bn:.2f}%")
print(f" - Model Without BN 정확도 : {acc_nobn:.2f}%")
print(f" - 성능 차이 : {acc_bn - acc_nobn:.2f}%p")
print("-" * 50)
submission_df.to_csv('comparison_result.csv', index=False)
print(submission_df.head())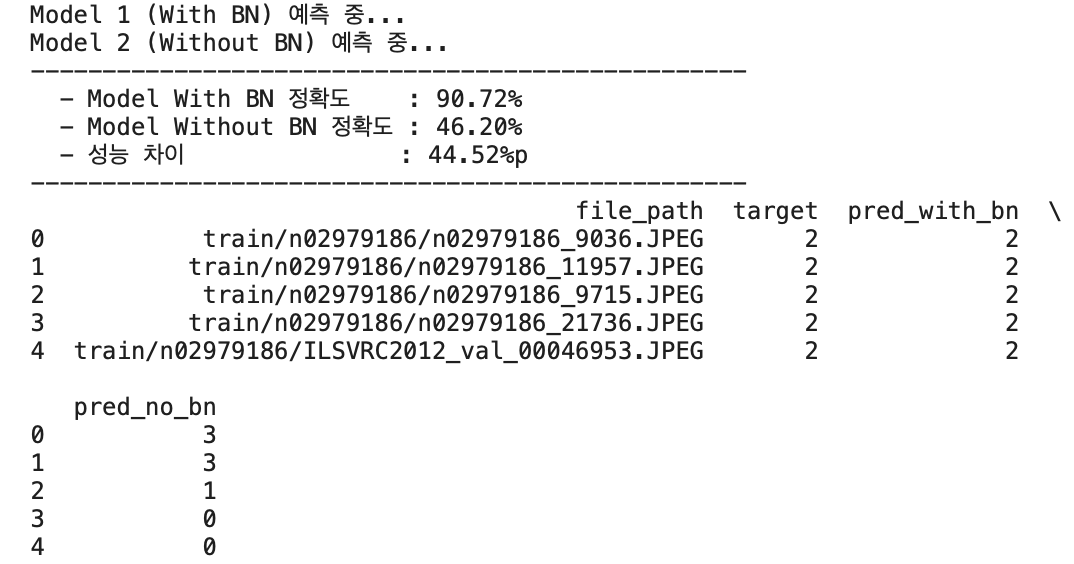
import numpy as np
targets_arr = np.array(targets_common) # 실제 정답
preds_bn_arr = np.array(preds_bn) # BN 모델 예측
preds_nobn_arr = np.array(preds_nobn) # No-BN 모델 예측
total_count = len(targets_arr)
correct_bn = (preds_bn_arr == targets_arr).sum()
acc_bn = correct_bn / total_count * 100
correct_nobn = (preds_nobn_arr == targets_arr).sum()
acc_nobn = correct_nobn / total_count * 100
print("-" * 45)
print(f"최종 비교 결과 리포트 (Best Models)")
print("-" * 45)
print(f"총 문제 수 : {total_count}개")
print("-" * 45)
print(f"Model 1: With Batch Norm]")
print(f"- 정답 개수 : {correct_bn}개")
print(f"- 오답 개수 : {total_count - correct_bn}개")
print(f"정확도 : {acc_bn:.2f}%")
print()
print(f"[Model 2: Without Batch Norm]")
print(f"- 정답 개수 : {correct_nobn}개")
print(f"- 오답 개수 : {total_count - correct_nobn}개")
print(f"정확도 : {acc_nobn:.2f}%")
print("-" * 45)
gap = acc_bn - acc_nobn
print(f"성능 차이 (BN 효과) : {gap:+.2f}%p")
print("-" * 45)
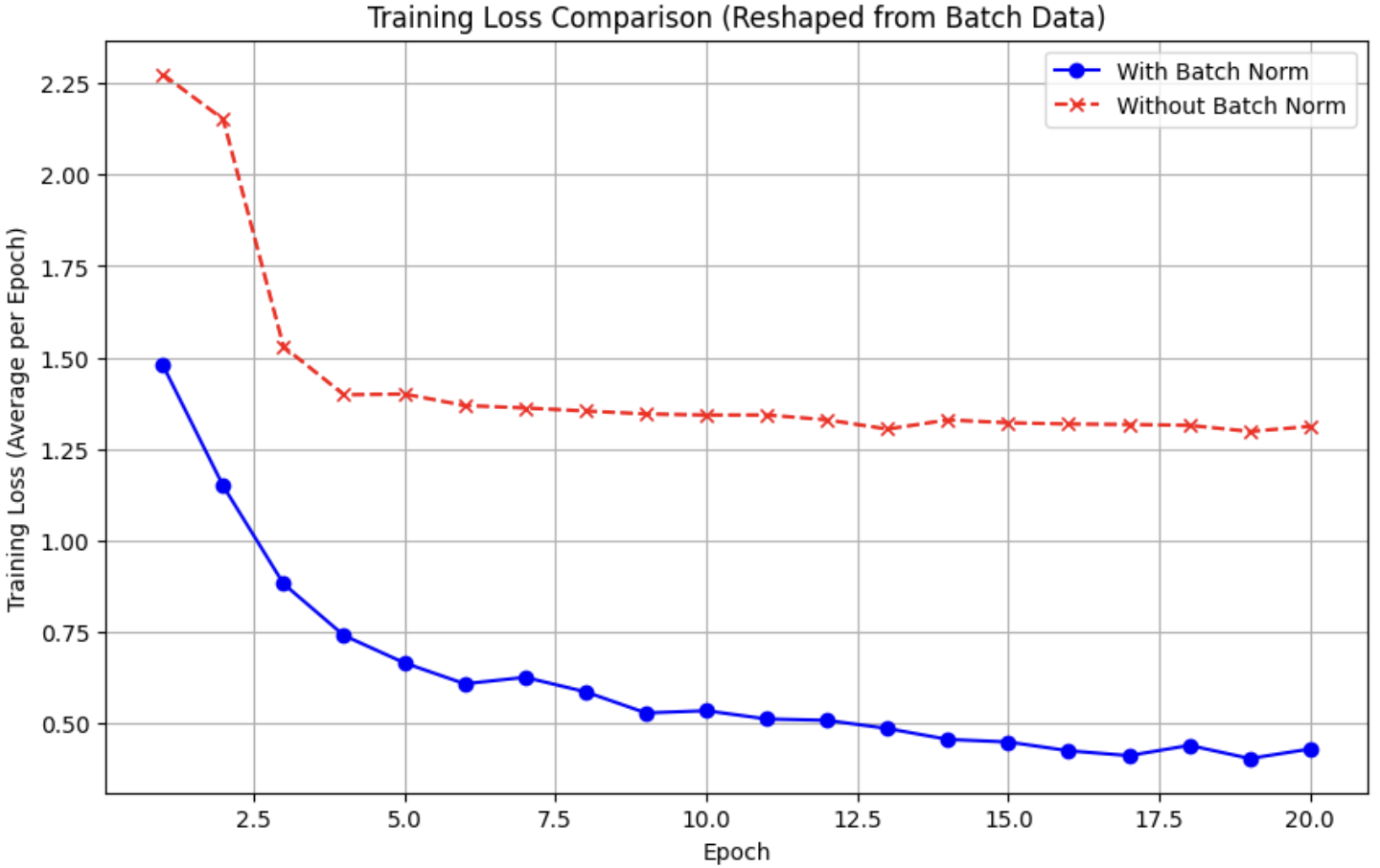
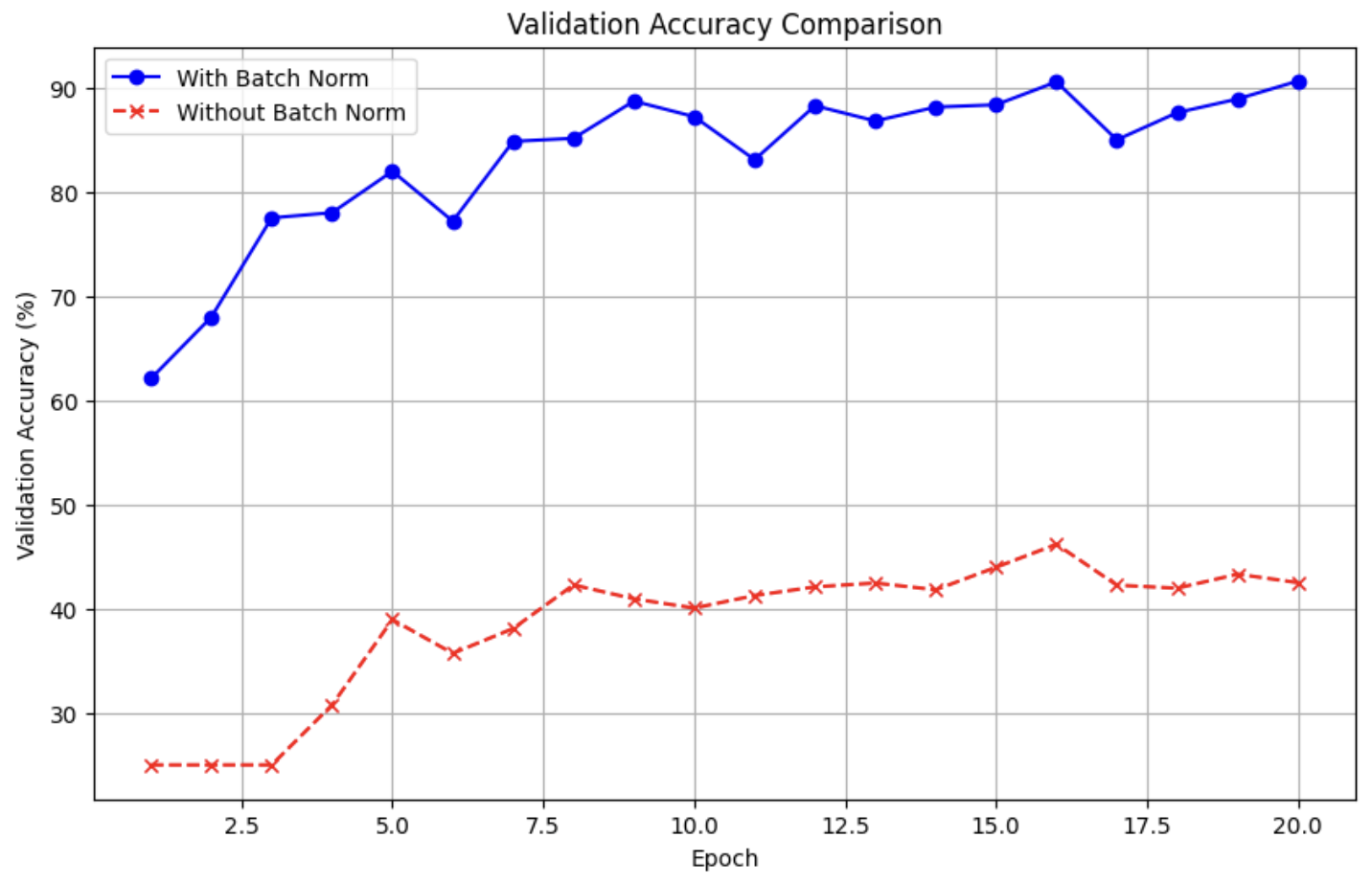
지금까지 AlexNet을 활용하여 Batch Normalization의 성능을 비교해보았습니다~~
