
기획/마케팅 팀원 합류
 약 6개월간의 운영 과정과 여러 이벤트들을 통해 운영상의 변수를 많이 줄여왔기에, 이제는 본격적으로 기획과 마케팅을 전담하여 담당해주실 팀원분의 필요성을 느껴 새로운 팀원분을 팀에 영입하였다.
약 6개월간의 운영 과정과 여러 이벤트들을 통해 운영상의 변수를 많이 줄여왔기에, 이제는 본격적으로 기획과 마케팅을 전담하여 담당해주실 팀원분의 필요성을 느껴 새로운 팀원분을 팀에 영입하였다.
또한 현재까지 마케팅 팀원분과 말씀을 나눈 내용은 아래와 같다.
- 마케팅적인 측면에서는 KPI에 대한 전/후 데이터가 필요하다
- 현재 서비스와 가장 적합한 마케팅 방안은 인스타그램 등의 홍보 수단이다
- 이를 위해서는 다른 서비스들에 비해서 현재보다 더 명확한 차별성을 지녀야 한다.
따라서 우선 현재 서비스 차별화를 위해 개발중인 v2를 시작으로 점진적으로 서비스를 실제 비즈니스 환경에 맞게 개선시켜나아갈 계획이다.
 또한 일반적인 Google Analytics나 Grafana등으로 확인할 수 있는 트래픽/사용자 지표 이외에도 실질적인 비즈니스화 방안을 모색하고자 위와 같이 현재로서는 가장 현실적인 Google Ads를 서비스에 추가하는 방안을 팀원분들께 여쭤보았다.
또한 일반적인 Google Analytics나 Grafana등으로 확인할 수 있는 트래픽/사용자 지표 이외에도 실질적인 비즈니스화 방안을 모색하고자 위와 같이 현재로서는 가장 현실적인 Google Ads를 서비스에 추가하는 방안을 팀원분들께 여쭤보았다.
언제볼까의 방향성은 기술적으로 무겁지 않으면서 수요가 있는 기능을 지닌 서비스를 구현해, FE/BE/Infra 파트의 세부적인 사항들을 강화하고 사이드 프로젝트 형태로 상시로 진행됨에도 사람들의 약속 상황을 더욱 간편하게 만들 수 있는 유효한 성과를 만들어내는 것이다.
Openstack Instance SHUTOFF 원인 파악
$ openstack server list
...
| ... | k8s-worker-2 | SHUTOFF | ... | Rocky Linux 9 Generic Cloud | k8s.worker |
| ... | k8s-worker-1 | SHUTOFF | ... | Rocky Linux 9 Generic Cloud | k8s.worker |
+---+--------------+---------+--------+-----------------------------+------------+이전부터 Openstack Instance가 주기적으로 SHUTOFF 상태로 전환되어 K8s Worker Node가 DOWN 상태로 배포가 불가능해지는 문제가 발생하였었다.
확인 결과 K8s 자체에는 문제가 존재하지 않으나, 위와 같이 Openstack 인스턴스가 지속적으로 Down되는 문제로 파악하였다.
$ openstack server start k8s-worker-1
$ openstack server start k8s-worker-2인스턴스를 다시 시작해주면 되지만, 주기적으로 발생하는 문제이기에
이전까지는 우선적으로 Toleration을 추가해 Master Node에서 서비스를 배포하는 것이 가능하게 하였지만 추후 서비스 확장과 비즈니스 목표 달성을 위해서 해당 문제를 해결해야만했다.
반복적으로 SHUTOFF 즉, 자동 종료되는 경우, 원인은 크게
- 게스트 내부 전원 OFF
- 호스트 자원 부족 (OOM/디스크/CPU)
- Nova/libvirt 오류
- 스케줄러/쿼터 정책 충돌
네 가지로 나뉘기에 우선 위 원인들 중 어떠한 것이 SHUTOFF를 일으키는지 파악하고자 한다.
[root@controller ~]# openstack versions show
+-------------+---------------+---------+-----------+------------------------------+------------------+------------------+
| Region Name | Service Type | Version | Status | Endpoint | Min Microversion | Max Microversion |
+-------------+---------------+---------+-----------+------------------------------+------------------+------------------+
| RegionOne | placement | 1.0 | CURRENT | http://controller:8778/ | 1.0 | 1.39 |
| RegionOne | network | 2.0 | CURRENT | http://controller:9696/v2.0/ | None | None |
| RegionOne | image | 2.0 | SUPPORTED | http://controller:9292/v2/ | None | None |
| RegionOne | image | 2.1 | SUPPORTED | http://controller:9292/v2/ | None | None |
| RegionOne | image | 2.2 | SUPPORTED | http://controller:9292/v2/ | None | None |
| RegionOne | image | 2.3 | SUPPORTED | http://controller:9292/v2/ | None | None |
| RegionOne | image | 2.4 | SUPPORTED | http://controller:9292/v2/ | None | None |
| RegionOne | image | 2.5 | SUPPORTED | http://controller:9292/v2/ | None | None |
| RegionOne | image | 2.6 | SUPPORTED | http://controller:9292/v2/ | None | None |
| RegionOne | image | 2.7 | SUPPORTED | http://controller:9292/v2/ | None | None |
| RegionOne | image | 2.9 | SUPPORTED | http://controller:9292/v2/ | None | None |
| RegionOne | image | 2.15 | CURRENT | http://controller:9292/v2/ | None | None |
| RegionOne | identity | 3.14 | CURRENT | http://controller:5000/v3/ | None | None |
| RegionOne | compute | 2.0 | SUPPORTED | http://controller:8774/v2/ | None | None |
| RegionOne | compute | 2.1 | CURRENT | http://controller:8774/v2.1/ | 2.1 | 2.93 |
| RegionOne | block-storage | 3.0 | CURRENT | http://controller:8776/v3/ | 3.0 | 3.70 |
+-------------+---------------+---------+-----------+------------------------------+------------------+------------------+우선 위와 같이 이전에 설치한 Openstack의 버전을 확인하였다.
[root@controller ~]# openstack --os-compute-api-version 2.90 \
server event list k8s-worker-1
+------------------------------------------+--------------------------------------+--------+----------------------------+
| Request ID | Server ID | Action | Start Time |
+------------------------------------------+--------------------------------------+--------+----------------------------+
| req-d59eac56-66ed-433a-8b02-d487499ad30c | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | stop | 2025-06-30T07:19:53.000000 |
| req-c9a8fc3a-eae9-4c15-bb40-c5ba44157374 | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | start | 2025-06-30T07:06:52.000000 |
| req-11b42f25-e920-4b11-aca0-45fabb7e8d41 | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | stop | 2025-06-30T07:03:01.000000 |
| req-2ec04326-3ac8-4f07-9eea-ca2b2a6d44cc | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | resize | 2025-06-30T06:48:04.000000 |
| req-5488f56b-3a25-4db1-b246-7c12d6be332f | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | resize | 2025-06-30T06:47:41.000000 |
| req-19ff5d56-007e-4a55-8dab-38b6b1c1e8fd | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | resize | 2025-06-30T06:44:00.000000 |
| req-f46af1b8-d290-4299-8444-922fedbf6d54 | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | start | 2025-06-30T06:43:57.000000 |
| req-74a4d9a3-7097-4753-9831-b4ae71b66266 | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | resize | 2025-06-30T06:43:44.000000 |
| req-3f8fd8be-d102-4031-ab97-e214485b33a2 | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | resize | 2025-06-30T06:41:28.000000 |
| req-23201200-66f4-4525-a093-6c88ed055d85 | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | resize | 2025-06-30T06:40:34.000000 |
| req-ec7127e6-54de-4cba-a067-8aa15fe82893 | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | resize | 2025-06-30T06:37:58.000000 |
| req-3feb8ef7-e35e-44d6-9c42-9927453464dc | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | resize | 2025-06-30T06:36:06.000000 |
| req-cf674d81-520a-416b-871d-451f4ea041ff | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | stop | 2025-06-21T10:08:53.000000 |
| req-75cd67e1-7986-44a0-b3f5-ba6f4452e527 | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | start | 2025-06-18T07:55:05.000000 |
| req-45edd104-84de-454f-850b-1aa9c09b8c45 | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | stop | 2025-05-14T08:44:51.000000 |
| req-fff65d4f-d671-4c50-9903-eeeb4a5ed882 | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | start | 2025-05-14T03:03:18.000000 |
| req-20f8eb7a-b8b5-4c7a-a7b4-67f25b26a5d2 | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | stop | 2025-05-14T02:55:09.000000 |
| req-1c4a7c82-153b-44e5-828a-c36244c78296 | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | start | 2025-05-14T02:52:22.000000 |
| req-203ed228-1b85-4352-a111-97da540c8e35 | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | stop | 2025-05-13T23:03:06.000000 |
| req-716e0e1f-52aa-48f3-aaac-873aa6651901 | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | start | 2025-05-13T13:27:09.000000 |
| req-272b9bd1-282e-4d4d-8a48-93d354dd87b0 | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | stop | 2025-04-29T18:02:27.000000 |
| req-f700c471-91b0-44b4-b39d-2807d05cb8a8 | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | start | 2025-04-28T03:43:40.000000 |
| req-42a92648-6d1d-40d7-a83f-f44fb639b03a | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | stop | 2025-04-20T07:56:03.000000 |
| req-33433530-35df-417f-8604-5c105e02d61b | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | start | 2025-04-11T03:58:00.000000 |
| req-457a474c-6fb7-4114-895d-f1bbaa8ecdc7 | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | stop | 2025-04-09T09:30:53.000000 |
| req-a41129aa-7a2e-4734-94c9-c80b2887fd8e | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | start | 2025-04-09T05:32:26.000000 |
| req-88dbfbc7-5c2b-4557-845e-66d5376dbc6a | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | stop | 2025-04-02T10:04:40.000000 |
| req-91863b64-8f5f-46a1-aec1-91c6df0ad446 | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | start | 2025-03-29T03:49:14.000000 |
| req-d6e2a79d-73da-43de-9744-24645b9b2476 | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | stop | 2025-03-29T03:45:05.000000 |
| req-b3a70d74-cb2c-4810-a075-52adee405664 | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | start | 2025-03-28T10:56:51.000000 |
| req-8b07774b-daa5-49bd-943d-710492d94bb3 | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | stop | 2025-03-28T10:56:27.000000 |
| req-80a9f987-0d15-46e8-85fc-e4f9bd24347a | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | start | 2025-03-28T10:55:32.000000 |
| req-c21bee35-17e5-4b11-a72d-07c3802d7aa7 | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | stop | 2025-03-28T10:53:02.000000 |
| req-004c9deb-89b1-4fd0-9ca7-d01b91d7791e | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | start | 2025-03-16T06:50:23.000000 |
| req-6dd19ffb-218b-4c62-8d31-5e99c1578fac | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | stop | 2025-03-14T05:46:53.000000 |
| req-6b6b1fda-e977-47c7-8d78-0aecec55a082 | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | start | 2025-03-11T11:54:22.000000 |
| req-976b8ec1-1bae-4ab8-8104-336ddacc09aa | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | stop | 2025-03-11T06:18:55.000000 |
| req-1d94b198-f2dd-4394-bce0-5b1061b70233 | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | start | 2025-03-03T07:35:34.000000 |
| req-86abbb4f-94ec-4754-9ab5-3ad81fc2ef47 | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | stop | 2025-03-03T07:35:20.000000 |
| req-63df5623-40fe-4dc5-98d4-3f5b0fd06e6e | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | start | 2025-03-03T06:51:06.000000 |
| req-e64bc0c5-5095-45d9-8e51-ad28f90427c9 | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | stop | 2025-03-03T03:20:37.000000 |
| req-52d24fd7-4e1f-4aac-8d83-9f484e6cb4fc | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | reboot | 2025-03-01T13:14:10.000000 |
| req-8223523e-378b-4248-80e7-e87787f3bf86 | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | start | 2025-03-01T08:13:30.000000 |
| req-3363f2b2-acca-48be-ad06-9f60d4982993 | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | stop | 2025-03-01T06:18:35.000000 |
| req-c43ea36a-f2c6-4cea-a7d6-f77d5f514ee9 | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | start | 2025-02-25T02:30:40.000000 |
| req-ee293006-c121-419a-81a8-b6e302853ebe | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | stop | 2025-02-25T02:27:29.000000 |
| req-1032fb68-f94f-419c-b094-7250935b9b42 | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | start | 2025-02-22T07:10:55.000000 |
| req-03a167ab-db7b-4a2a-95ed-855ee43fc2a9 | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | stop | 2025-02-22T07:08:52.000000 |
| req-cac0adb5-25f8-472d-82ae-a2d5905d6861 | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | start | 2025-02-22T04:16:52.000000 |
| req-bf664197-44a6-4879-bb3c-860b2c312a85 | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | stop | 2025-02-21T02:48:29.000000 |
| req-397f79fd-aeb4-4d7d-a774-f86732465541 | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | start | 2025-02-20T06:09:04.000000 |
| req-c1fab34c-4a35-463f-963a-932297e37f0b | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | stop | 2025-02-20T04:04:26.000000 |
| req-e6cd478d-a891-4fac-9fef-1dcc697c1d8d | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | create | 2025-02-18T04:59:30.000000 |
+------------------------------------------+--------------------------------------+--------+----------------------------+이후 위와 같이 Nova 이벤트 스트림을 확인해본 결과 stop 이력 다수 존재했기에, Nova API·Scheduler의 문제일 것이라 예상하여
openstack server event show k8s-worker-1 req-d59eac56-66ed-433a-8b02-d487499ad30c
+---------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Field | Value |
+---------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| action | stop |
| events | [{'event': 'compute_stop_instance', 'start_time': '2025-06-30T07:20:08.000000', 'finish_time': '2025-06-30T07:20:08.000000', 'result': 'Success', 'traceback': None}] |
| instance_uuid | 6c59b812-2d8d-4da5-92d6-6bbe527926d6 |
| message | None |
| project_id | None |
| request_id | req-d59eac56-66ed-433a-8b02-d487499ad30c |
| start_time | 2025-06-30T07:19:53.000000 |
| user_id | None |
+---------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------+server event를 조회한 뒤 user_id / project_id = None이기 때문에 Nova API나 클라이언트가 내린 stop 명령이 아님을 확인하였고
compute_stop_instance 이벤트만 남고 원인 메시지가 없으므로, libvirt/qemu 프로세스가 먼저 종료되고 Nova가 "stop" 이벤트만 기록한 상황 즉, Nova는 “내부 stop 이벤트”만 기록하고, 사용자-ID가 없으므로 원인은 호스트 측에 있을 것이라 판단하였다.
[root@openstack-host ~]# top
top - 03:57:24 up 122 days, 24 min, 4 users, load average: 1.32, 1.11, 1.10
Tasks: 284 total, 1 running, 283 sleeping, 0 stopped, 0 zombie
%Cpu(s): 3.1 us, 7.7 sy, 0.0 ni, 88.3 id, 0.0 wa, 0.5 hi, 0.5 si, 0.0 st
MiB Mem : 15654.8 total, 628.2 free, 13778.5 used, 1776.6 buff/cache
MiB Swap: 8024.0 total, 3541.7 free, 4482.2 used. 1876.3 avail Mem
[root@controller ~]# top
top - 03:58:31 up 122 days, 25 min, 1 user, load average: 0.36, 0.18, 0.11
Tasks: 252 total, 1 running, 251 sleeping, 0 stopped, 0 zombie
%Cpu(s): 4.3 us, 2.9 sy, 0.0 ni, 92.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 5668.1 total, 755.2 free, 4602.6 used, 667.1 buff/cache
MiB Swap: 4096.0 total, 2956.6 free, 1139.4 used. 1065.4 avail Mem
[root@compute ~]# top
top - 03:57:40 up 3 days, 39 min, 1 user, load average: 0.01, 0.02, 0.00
Tasks: 214 total, 1 running, 213 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 1.0 sy, 0.0 ni, 98.0 id, 0.0 wa, 1.0 hi, 0.0 si, 0.0 st
MiB Mem : 7683.6 total, 6465.9 free, 1099.7 used, 401.1 buff/cache
MiB Swap: 6898.0 total, 6898.0 free, 0.0 used. 6583.8 avail Mem| 노드 | Mem(GB) | Free(GB) | Swap Used(GB) | Uptime |
|---|---|---|---|---|
| openstack-host | 15.3 | 0.6 | 4.4 | 122 일 |
| controller VM | 5.5 | 0.7 | 1.1 | 122 일 |
| compute VM | 7.5 | 6.3 | 0 | 3 일 |
따라서 각 KVM 그 호스트 머신의 메모리와 Uptime을 확인해보았을 때 openstack-host의 물리적 메모리 부족으로 OOM Killer가 qemu-kvm 프로세스를 강제 종료시켜 compute VM만 재부팅되어 해당 VM에 탑승해 있던 nested 인스턴스인 k8s-worker-1/2가 SHUTOFF되었을 것이라고 판단하였다.
[root@openstack-host ~]# sudo dmesg -T | grep -i 'oom-killer\|Out of memory'
[root@openstack-host ~]# sudo journalctl -u libvirtd -S '-7days' | grep -E 'qemu.*killed|oom|Out of memory'
[root@openstack-host ~]# sudo journalctl -u libvirtd -S '-7days' | grep -i 'I/O error'하지만 OOM,I/O 로그가 전혀 남아 있지 않기에 메모리 강제 종료나 디스크 오류 가능성을 어느정도 배제하였다.
즉, 물리 호스트의 RAM 이나 Swap 메모리 사용률은 높지만 커널이 OOM Killer를 발동한 흔적이 없고 compute VM만 uptime 3 일이기 때문에 VM 내부 원인 혹은 qemu 프로세스 crash 로 재부팅된 가능성일 수도 있을 것이라 판단하였다.
[root@openstack-host ~]# ls /var/log/libvirt/qemu/
cirros-test.log
compute.log
compute.log.0
compute.log.1
compute-test.log
controller.log
controller-test.log
[root@openstack-host ~]# sudo cat /var/log/libvirt/qemu/compute.log.0 | tail -n 10
ERROR cluster 261192 refcount=0 reference=1
ERROR cluster 261193 refcount=0 reference=1
ERROR cluster 261194 refcount=0 reference=1
ERROR cluster 261195 refcount=0 reference=1
ERROR cluster 261196 refcount=0 reference=1
ERROR cluster 261197 refcount=0 reference=1
ERROR cluster 261198 refcount=0 reference=1
ERROR cluster 261199 refcount=0 reference=1
ERROR cluster 261200 refcount=0 reference=1
ERROR cluster 261201 refcount=0 reference=1
[root@openstack-host ~]# sudo cat /var/log/libvirt/qemu/compute.log.1 | tail -n 10
ERROR cluster 213868 refcount=0 reference=1
ERROR cluster 213869 refcount=0 reference=1
ERROR cluster 213870 refcount=0 reference=1
ERROR cluster 213871 refcount=0 reference=1
ERROR cluster 213872 refcount=0 reference=1
ERROR cluster 213873 refcount=0 reference=1
ERROR cluster 213874 refcount=0 reference=1
ERROR cluster 213875 refcount=0 reference=1
ERROR cluster 213876 refcount=0 reference=1
ERROR cluster 213877 refcount=0 reference=1
[root@openstack-host ~]# sudo cat /var/log/libvirt/qemu/compute.log | tail -n 10
-device '{"driver":"virtserialport","bus":"virtio-serial0.0","nr":1,"chardev":"charchannel0","id":"channel0","name":"org.qemu.guest_agent.0"}' \
-audiodev '{"id":"audio1","driver":"none"}' \
-global ICH9-LPC.noreboot=off \
-watchdog-action reset \
-device '{"driver":"virtio-balloon-pci","id":"balloon0","bus":"pci.5","addr":"0x0"}' \
-object '{"qom-type":"rng-random","id":"objrng0","filename":"/dev/urandom"}' \
-device '{"driver":"virtio-rng-pci","rng":"objrng0","id":"rng0","bus":"pci.6","addr":"0x0"}' \
-sandbox on,obsolete=deny,elevateprivileges=deny,spawn=deny,resourcecontrol=deny \
-msg timestamp=on
char device redirected to /dev/pts/0 (label charserial0)따라서 우선 /var/log/libvirt/qemu/compute.log들을 통해 compute이미의 로그를 확인하였다.
ERROR cluster refcount=0 reference=1 메시지는 QCOW2의 refcount 테이블 불일치 시 출력되며, 이미지가 일시적으로 읽기 전용 혹은 Pause 되었다가 libvirt가 destroy 할 수 있다.
블록 장치가 순간 BLOCK_IO_ERROR 를 내면 QEMU가 VM을 Pause/Eject, nova-compute는 “destroy successfully”만 남기는 지금의 현상과 동일함을 확인할 수 있었고
이는 즉, compute VM의 가상 디스크가 손상되어 있고, 손상 정도에 따라 QEMU가 크래시되거나 I/O 오류를 일으켜 VM이 재부팅 혹은 종료된 것으로 해석할 수 있었다.
sudo virsh shutdown compute
# compute 이미지 백업
cp /home/libvirt/images/compute.qcow2 /home/libvirt/images/compute.qcow2.bak
# 이미지 무결성 검사/자동 수리
[root@openstack-host ~]# sudo qemu-img check -r all /home/libvirt/images/compute.qcow2따라서 위와 같이 compute VM를 정지시킨 뒤 qemu-img check -r all을 통해 이미지의 무결성을 검사하고 자동적으로 수리하였다.
[root@openstack-host ~]# virsh edit compute
...
<devices>
<emulator>/usr/libexec/qemu-kvm</emulator>
<disk type='file' device='disk'>
<driver name='qemu' type='qcow2' cache='none' discard='unmap'/>이후 부가적인 오류를 방지하기 위해 쓰기 캐시를 호스트 커널에 맡겨 손상 가능성 감소시키고
vim /usr/local/bin/restart-shutoff-workers.sh
: << "END"
# OpenStack 환경 변수 로드
source /root/admin-openrc
# 점검할 인스턴스 목록
WORKERS=("k8s-worker-1" "k8s-worker-2")
for name in "${WORKERS[@]}"; do
# 상태 조회
status=$(openstack server show "$name" -f value -c status 2>/dev/null)
if [[ "$status" == "SHUTOFF" ]]; then
echo "$(date +'%Y-%m-%d %H:%M:%S') - $name is SHUTOFF, starting..." >> /var/log/restart-workers.log
openstack server start "$name" >> /var/log/restart-workers.log 2>&1
fi
done
END
sudo chmod +x /usr/local/bin/restart-shutoff-workers.sh
sudo touch /var/log/restart-workers.log
sudo chown root:root /var/log/restart-workers.log
sudo chmod 600 /var/log/restart-workers.log
sudo crontab -e
* * * * * /usr/local/bin/restart-shutoff-workers.sh추후 혹여나 현제 서비스가 구동되는 도중 지금과 다른 원인으로 문제가 발생한다면 controller VM에서 1분마다 openstack server list를 조회해, SHUTOFF 상태인 워커 노드를 자동으로 기동하도록 스크립트를 작성하였고
[root@controller ~]# openstack server stop k8s-worker-1
[root@controller ~]# openstack server list
+--------------------------------------+--------------+---------+------------------------------------------------+-----------------------------+------------+
| ID | Name | Status | Networks | Image | Flavor |
+--------------------------------------+--------------+---------+------------------------------------------------+-----------------------------+------------+
| 61b0f46e-651b-4564-bc37-0185ff7f18b2 | k8s-worker-2 | ACTIVE | ext-net=192.168.100.29; private-net=10.0.0.107 | Rocky Linux 9 Generic Cloud | k8s.worker |
| 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | k8s-worker-1 | SHUTOFF | ext-net=192.168.100.44; private-net=10.0.0.28 | Rocky Linux 9 Generic Cloud | k8s.worker |
+--------------------------------------+--------------+---------+------------------------------------------------+-----------------------------+------------+
[root@controller ~]# cat /var/log/restart-workers.log
2025-07-03 07:01:04 - k8s-worker-1 is SHUTOFF, starting...
[root@controller ~]# openstack server list
+--------------------------------------+--------------+--------+------------------------------------------------+-----------------------------+------------+
| ID | Name | Status | Networks | Image | Flavor |
+--------------------------------------+--------------+--------+------------------------------------------------+-----------------------------+------------+
| 61b0f46e-651b-4564-bc37-0185ff7f18b2 | k8s-worker-2 | ACTIVE | ext-net=192.168.100.29; private-net=10.0.0.107 | Rocky Linux 9 Generic Cloud | k8s.worker |
| 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | k8s-worker-1 | ACTIVE | ext-net=192.168.100.44; private-net=10.0.0.28 | Rocky Linux 9 Generic Cloud | k8s.worker |
+--------------------------------------+--------------+--------+------------------------------------------------+-----------------------------+------------+
[root@master k8s]# k get nodes
NAME STATUS ROLES AGE VERSION
k8s-worker-1.novalocal Ready worker 133d v1.32.2
k8s-worker-2.novalocal Ready worker 133d v1.32.2
master Ready control-plane 133d v1.32.2이후 해당 스크립트를 위와 같이 성공적으로 테스트할 수 있었다.
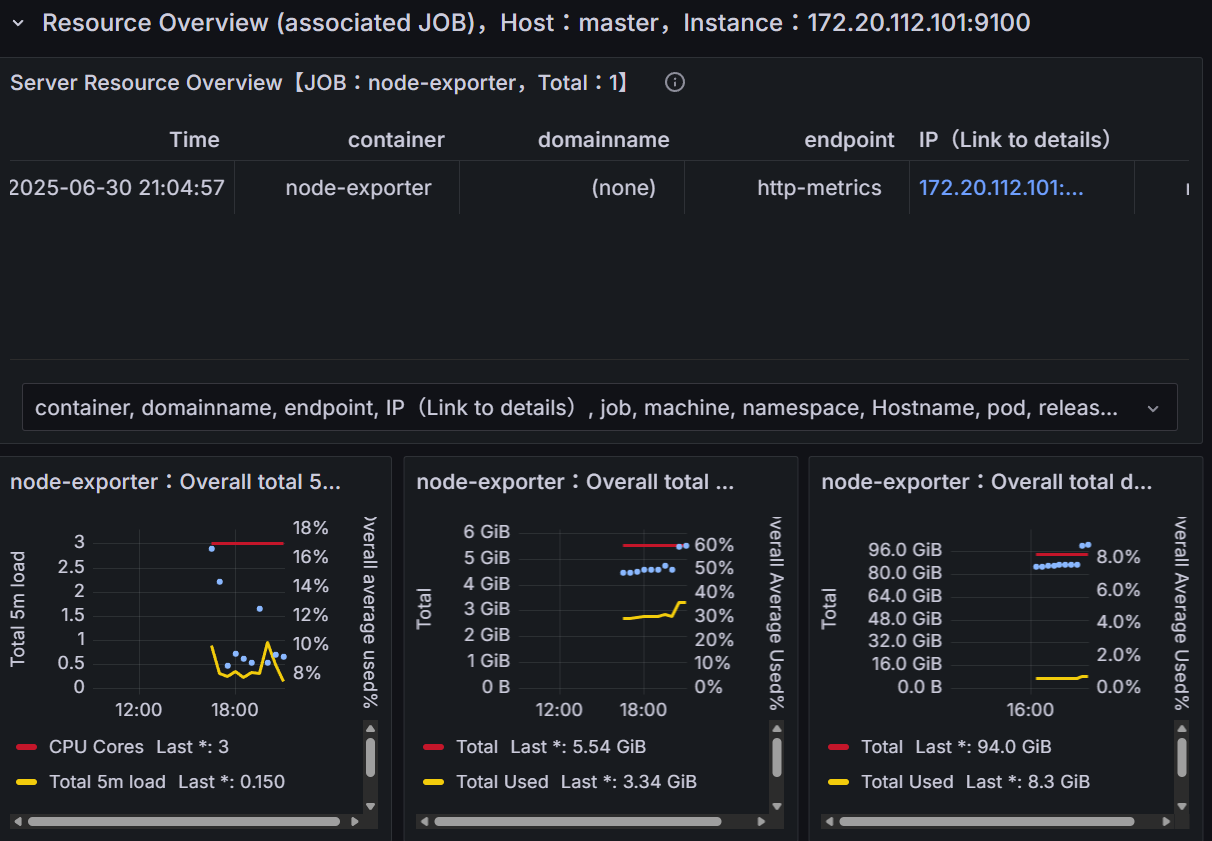
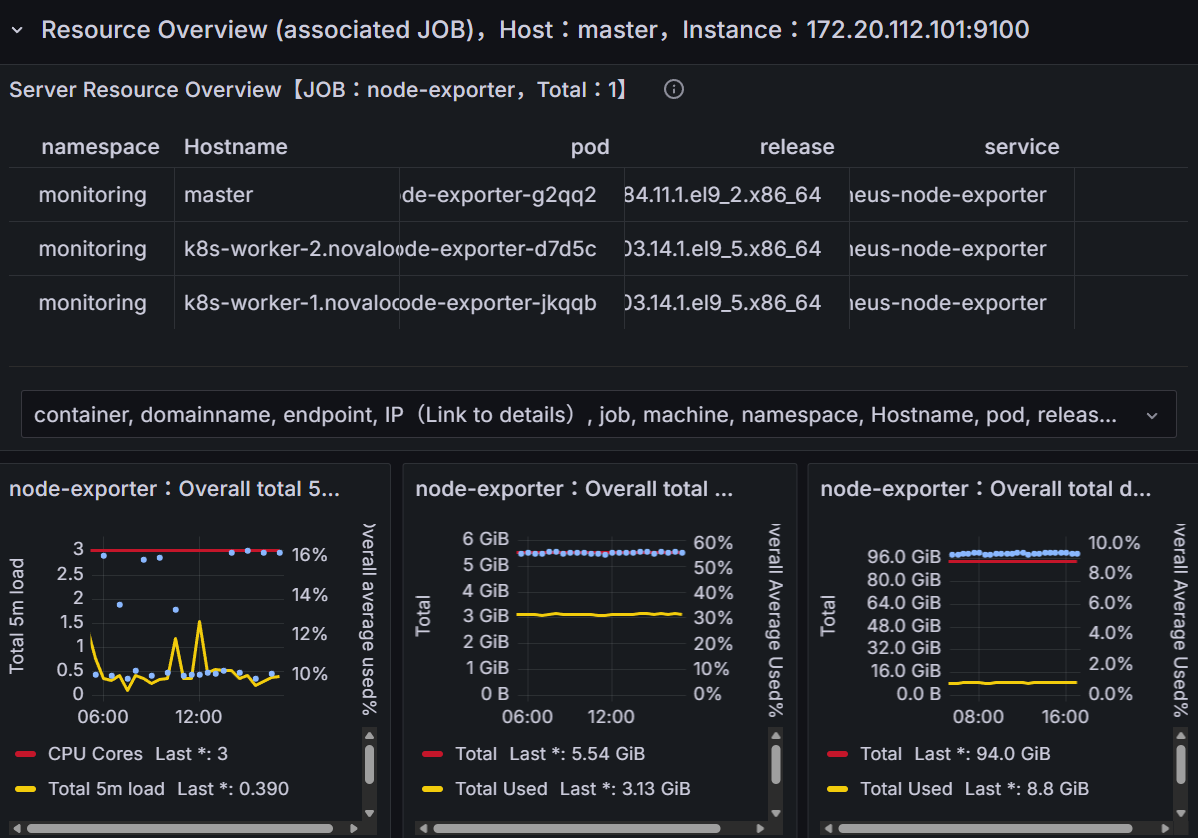 현재 정상적으로 Kubernetes 클러스터가 복구된 상태를 확인할 수 있으며, 추후 libvirt와 qemu의 로깅 수준을 높이고 Prometheus의 AlertManager를 연결하여 동일한 문제의 발생에 대비할 계획이다.
현재 정상적으로 Kubernetes 클러스터가 복구된 상태를 확인할 수 있으며, 추후 libvirt와 qemu의 로깅 수준을 높이고 Prometheus의 AlertManager를 연결하여 동일한 문제의 발생에 대비할 계획이다.
호스트 머신 CPU 온도 관리
 또한 이후 여러 방향성으로 접근해본 결과 기존에 설치된 냉각을 위한 팬이 여름으로 들어서면서 제 기능을 발휘하지 못해 90도 이상까지 CPU의 온도가 올라가는 현상을 포착하고, Compute 노드가 중지하는 원인이 온도 때문일 수도 있을 것이라 판단하였다.
또한 이후 여러 방향성으로 접근해본 결과 기존에 설치된 냉각을 위한 팬이 여름으로 들어서면서 제 기능을 발휘하지 못해 90도 이상까지 CPU의 온도가 올라가는 현상을 포착하고, Compute 노드가 중지하는 원인이 온도 때문일 수도 있을 것이라 판단하였다.
따라서 추가적인 팬을 구매해 설치하고 해당 팬들의 각도를 조정하여 위와 같이 CPU 사용률 20%이내에서 60도 내외의 온도를 유지할 수 있게 하였다.
여러 호스트 머신들의 온도의 경우에도 지속적으로 모니터링할 게획이다.
[TroubleShooting] nova-compute:1069 blocked for more than 245 seconds
[root@master wwwm]# k get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
wwwm-mysql-6b74788df8-vcszk 2/2 Running 0 7d1h 10.244.0.63 master <none> <none>
wwwm-spring-be-deployment-58589d7bdc-r98zf 1/1 Running 1 119m 10.244.1.155 k8s-worker-1.novalocal <none> <none>[root@compute ~]# [12289.195649] INFO: task nova-compute:1069 blocked for more than 122 seconds.
[12289.195694] Not tainted 5.14.0-503.23.1.el9_5.x86_64 #1
[12289.195715] "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
[12289.195723] task:nova-compute state:D stack:0 pid:1069 tgid:1069 ppid:1 flags:0x00000002
[12289.195740] Call Trace:
[12289.195746] <TASK>
[12289.195756] __schedule+0x229/0x550
[12289.195778] schedule+0x2e/0xd0
[12289.195783] kvm_async_pf_task_wait_schedule+0xf3/0x180
[12289.195792] __kvm_handle_async_pf+0x53/0xb0
[12289.195799] exc_page_fault+0x7d/0x150
[12289.195805] asm_exc_page_fault+0x22/0x30
[12289.195810] RIP: 0033:0x7fda2f937a34
[12289.195858] RSP: 002b:00007ffc09e20fc0 EFLAGS: 00010202
[12289.195861] RAX: 00007fd9e4783000 RBX: 00007fda2e2d8cc0 RCX: 00007fda2fb931a0
[12289.195864] RDX: 0000000000000ff0 RSI: 00007fda0806f000 RDI: 00007fda2fb78fd0
[12289.195866] RBP: 00007fda2e2a29d0 R08: 00007fda2fb96e40 R09: 0000000000000000
[12289.195868] R10: 00007fda2fb78f60 R11: 0000561d3074d490 R12: 00007fda2e2a4080
[12289.195870] R13: 00007fd9e47834b0 R14: 00007fda2e2a15d0 R15: 0000561d3074bb00
[12289.195876] </TASK>
[12412.075582] INFO: task nova-compute:1069 blocked for more than 245 seconds.
[12412.075602] Not tainted 5.14.0-503.23.1.el9_5.x86_64 #1
[12412.075616] "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
[12412.075623] task:nova-compute state:D stack:0 pid:1069 tgid:1069 ppid:1 flags:0x00000002문제의 현상을 일시적으로 완화할 수 있었지만, 지속적인 모니터링을 통해 발견한 task nova-compute blocked 로그는 문제의 근본 원인이 다른 곳에 있음을 시사하였다.
해당 로그는 nova-compute 서비스가 스토리지 I/O 작업을 기다리다가 응답 불능 상태에 빠졌음을 의미하며 이는 이전의 QCOW2 이미지 손상과도 깊은 관련이 존재하였다.
task:nova-compute state:D: nova-compute 프로세스가 D 상태(Uninterruptible Sleep)에 빠졌으며 프로세스가 디스크 I/O나 특정 커널 자원 해제를 기다리며, 스스로 중단될 수도 없고 시그널을 받아 종료될 수도 없는 '완전 정지' 상태임을 의미exc_page_fault: KVM 가상 머신(VM) 내부에서 메모리 접근 시 'Page Fault'가 발생__kvm_handle_async_pf: KVM이 이 페이지 폴트를 비동기적으로 처리하려고 하며 이는 VM이 요청한 메모리 페이지가 현재 RAM에 없고, 디스크에 저장된 이미지 파일(QCOW2 등)에서 읽어와야 함을 의미kvm_async_pf_task_wait_schedule: 바로 이 지점에서 프로세스가 멈췄으며 커널이 스토리지에 데이터 읽기를 요청했지만, 스토리지가 245초 이상 응답하지 않아 무한정 대기하고 있는 로그
결론적으로 KVM이 VM을 실행하는 데 필요한 데이터를 스토리지에서 읽어오지 못하자, nova-compute 서비스 전체가 멈춰버린 상황임을 파악할 수 있었다.
[root@compute ~]# vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 3565668 1640 469252 0 0 99 4 341 388 4 1 94 0 0
0 0 0 3565896 1640 469252 0 0 0 0 2806 3029 5 2 93 0 0
0 0 0 3567480 1640 469252 0 0 0 0 1486 1641 3 1 96 0 0
1 0 0 3567736 1640 469252 0 0 0 0 1663 1628 4 1 94 0 0
0 0 0 3567512 1640 469252 0 0 0 14 1991 2241 5 1 94 0 0compute 호스트 자체의 문제가 I/O 성능에 영향을 줄 수 있기에 호스트 메모리가 부족해 스왑을 과도하게 사용하면 디스크 I/O가 폭증하여 시스템 전체가 느려질 수 있어 이 vmstat 1을 통해 si (swap-in), so (swap-out) 컬럼을 확인해 우선 메모리 Swapping에는 문제가 없음을 확인하였다.
sudo dnf update
...
(384/384): linux-firmware-20250513-151.1.el9_6. 6.2 MB/s | 477 MB 01:16
--------------------------------------------------------------------------------
Total 7.8 MB/s | 899 MB 01:54
[ 3121.583458] Kernel panic - not syncing: Host injected async #PF in kernel mode
[ 3121.584500] CPU: 0 PID: 3053 Comm: dnf Kdump: loaded Not tainted 5.14.0-503.23.1.el9_5.x86_64 #1
[ 3121.585678] Hardware name: Red Hat KVM/RHEL, BIOS 1.16.3-2.el9_5.1 04/01/2014
[ 3121.586967] Call Trace:
[ 3121.587430] <TASK>
[ 3121.587792] dump_stack_lvl+0x34/0x48
[ 3121.588507] panic+0x107/0x2bb
[ 3121.589099] ? restore_regs_and_return_to_kernel+0x22/0x22
[ 3121.590100] __kvm_handle_async_pf+0xaa/0xb0
[ 3121.590981] exc_page_fault+0x7d/0x150
[ 3121.591715] asm_exc_page_fault+0x22/0x30
[ 3121.592473] RIP: 0010:__put_user_8+0xd/0x20
[ 3121.593317] Code: 89 01 31 c9 0f 01 ca c3 cc cc cc cc 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 48 89 cb 48 c1 fb 3f 48 09 d9 0f 01 cb <48> 89 01 31 c9 0f 01 ca c3 cc cc cc cc 66 0f 1f 44 00 00 90 90 90
[ 3121.596877] RSP: 0018:ffffb6cfc1d63cb8 EFLAGS: 00050206
[ 3121.597841] RAX: 0000000000000000 RBX: 0000000000000000 RCX: 00007ff25f20a0e8
[ 3121.599123] RDX: 0000000000000000 RSI: 0000000000000000 RDI: ffff8d24c7c10000
[ 3121.600294] RBP: ffffb6cfc1d63d30 R08: ffff8d24c49ca810 R09: ffff8d2637cf3a80
[ 3121.601413] R10: 000000000007aa3c R11: 000000000000b389 R12: 0000000000000000
[ 3121.602445] R13: 00007ff25ead9267 R14: ffffb6cfc1d63f58 R15: 0000000000000000
[ 3121.603542] rseq_ip_fixup+0x6e/0x1a0
[ 3121.604138] __rseq_handle_notify_resume+0x26/0xb0
[ 3121.604946] exit_to_user_mode_loop+0xd9/0x130
[ 3121.605615] exit_to_user_mode_prepare+0xb9/0x100
[ 3121.606355] syscall_exit_to_user_mode+0x12/0x40
[ 3121.606982] do_syscall_64+0x6b/0xf0
[ 3121.607565] ? syscall_exit_to_user_mode+0x19/0x40
[ 3121.608345] ? do_syscall_64+0x6b/0xf0
[ 3121.608947] ? syscall_exit_work+0x103/0x130
[ 3121.609622] ? syscall_exit_to_user_mode+0x19/0x40
[ 3121.610373] ? do_syscall_64+0x6b/0xf0
[ 3121.611001] ? syscall_exit_work+0x103/0x130
[ 3121.611663] ? syscall_exit_to_user_mode+0x19/0x40
[ 3121.612443] ? do_syscall_64+0x6b/0xf0
[ 3121.613027] ? syscall_exit_work+0x103/0x130
[ 3121.613619] ? syscall_exit_to_user_mode+0x19/0x40
[ 3121.614364] ? do_syscall_64+0x6b/0xf0
[ 3121.614925] ? clear_bhb_loop+0x25/0x80
[ 3121.615477] ? clear_bhb_loop+0x25/0x80
[ 3121.616058] ? clear_bhb_loop+0x25/0x80
[ 3121.616609] ? clear_bhb_loop+0x25/0x80
[ 3121.617234] ? clear_bhb_loop+0x25/0x80
[ 3121.617848] entry_SYSCALL_64_after_hwframe+0x78/0x80
[ 3121.618678] RIP: 0033:0x7ff25ead9267
[ 3121.619266] Code: 00 00 00 f3 0f 1e fa 64 48 8b 04 25 10 00 00 00 45 31 c0 31 d2 31 f6 bf 11 00 20 01 4c 8d 90 d0 02 00 00 b8 38 00 00 00 0f 05 <48> 3d 00 f0 ff ff 77 39 41 89 c0 85 c0 75 2a 64 48 8b 04 25 10 00
[ 3121.621927] RSP: 002b:00007fff33c25a78 EFLAGS: 00000246
[ 3121.622744] RAX: 0000000000000c05 RBX: 0000000000000000 RCX: 00007ff25ead9267
[ 3121.623858] RDX: 0000000000000000 RSI: 0000000000000000 RDI: 0000000001200011
[ 3121.624981] RBP: 0000000000000001 R08: 0000000000000000 R09: 00007ff25f1b47c0
[ 3121.626121] R10: 00007ff25f209a10 R11: 0000000000000246 R12: 0000000000000001
[ 3121.627552] R13: 0000000000000008 R14: 00007fff33c25a80 R15: 00007ff25af86a10
[ 3121.628798] </TASK>이후 드물지만 커널이나 드라이버 버그 원인을 방지하기 위해 compute 노드에서 sudo dnf update를 수행하자 새로운 오류가 발생함을 확인할 수 있었다.
[TroubleShooting] Kernel panic - not syncing: Host injected async #PF in kernel mode
업데이트를 진행하자마자 Kernel panic이 발생했다.
이는 compute 노드가 실행되고 있는 물리 호스트(Hypervisor)의 스토리지 시스템에서 복구 불가능한 I/O 에러가 발생하여, 호스트가 VM을 강제로 중지시킨 상황이며 업데이트 과정의 대량 디스크 쓰기 작업이 이 문제를 촉발시켰음을 예상할 수 있었다.
Kernel panic: 운영체제가 더 이상 안전하게 실행을 계속할 수 없어 스스로 시스템을 멈춘, 가장 심각한 수준의 오류Host injected: 이 오류는 VM 내부에서 시작된 것이 아니며 VM을 실행하는물리 호스트(Hypervisor)가 VM에게 치명적인 오류 신호를 '주입(inject)'했다는 의미async #PF: 이전 task blocked 로그에서 보았던 '비동기 페이지 폴트(Asynchronous Page Fault)'와 동일한 메커니즘이며 VM이 디스크에서 데이터를 읽어오려 했으나 실패했다는 의미
위 로그를 정리하자면 VM이 dnf 업데이트를 위해 디스크 읽기/쓰기를 요청하자, 물리 호스트의 스토리지가 이 요청을 처리하다가 복구 불가능한 심각한 오류에 직면했으며 호스트는 더 이상 작업을 진행할 수 없다고 판단하여, 게스트 VM의 커널에 강제로 페이지 폴트 예외를 주입했고, 게스트 VM은 이를 처리하지 못하고 즉시 패닉 상태에 빠진 것으로 볼 수 있었다.
sudo smartctl -a /dev/nvme0n1S.M.A.R.T.(Self-Monitoring, Analysis and Reporting Technology)은 하드디스크나 SSD가 스스로 상태를 점검하여 이상 징후를 기록·보고하는 기술이며, smartctl은 이 정보를 조회·관리할 수 있는 대표적인 커맨드라인 도구
따라서 우선 /dev/nvme0n1의 디스크 건강 상태를 smartctl로 점검하였다.
[ 1.211202] Running certificate verification ECDSA selftest
[ 1.213033] Loaded X.509 cert 'Certificate verification ECDSA self-testing key: 2900bcea1deb7bc8479a84a23d758efdfdd2b2d3'
[ 1.232719] clk: Disabling unused clocks
[ 1.233783] md: Waiting for all devices to be available before autodetect
[ 1.233792] md: If you don't use raid, use raid=noautodetect
[ 1.233795] md: Autodetecting RAID arrays.
[ 1.233799] md: autorun ...
[ 1.233802] md: ... autorun DONE.
[ 1.233821] List of all partitions:
[ 1.233822] No filesystem could mount root, tried:
[ 1.233823]
[ 1.233824] Kernel panic - not syncing: VFS: Unable to mount root fs on unknown-block(0,0)
[ 1.239868] CPU: 3 PID: 1 Comm: swapper/0 Not tainted 5.14.0-570.23.1.el9_6.x86_64 #1
[ 1.241151] Hardware name: Red Hat KVM/RHEL, BIOS 1.16.3-2.el9_5.1 04/01/2014
[ 1.242241] Call Trace:
[ 1.242622] <TASK>
[ 1.242919] dump_stack_lvl+0x34/0x48
[ 1.243466] panic+0x107/0x2bb
[ 1.243942] mount_root_generic+0x1c6/0x1d9
[ 1.244550] ? mount_root+0x134/0x176
[ 1.245126] prepare_namespace+0x1ae/0x1f5
[ 1.245801] kernel_init_freeable+0x182/0x1a7
[ 1.246416] ? __pfx_kernel_init+0x10/0x10
[ 1.247033] kernel_init+0x16/0x136
[ 1.247572] ret_from_fork+0x29/0x50
[ 1.248111] </TASK>
[ 2.302753] Shutting down cpus with NMI
[ 2.303463] Kernel Offset: 0x1cc00000 from 0xffffffff81000000 (relocation range: 0xffffffff80000000-0xffffffffbfffffff)
[ 2.304886] ---[ end Kernel panic - not syncing: VFS: Unable to mount root fs on unknown-block(0,0) ]---하지만 점검 직후 VM을 다시 기동하고자 했을 때 위와 같이 Kernel panic 또 다시 발생하였다. 이는 전형적인 부하 시에만 드러나는 하드웨어 결함 시나리오이다.
smartctl -a 명령은 단순히 로그를 읽는 것이 아니라, 물리 디스크에 직접 ATA/SCSI 명령을 보내 상태 정보를 요청하고 자가 진단을 수행하며 이 과정에서 디스크와 스토리지 컨트롤러에는 평소보다 더 많은 저수준(low-level) I/O 부하가 걸리게 된다.
이때 만약 물리 디스크나 스토리지 컨트롤러, 혹은 SATA/SAS 케이블에 미세한 결함이 있다면, 평소에는 문제없이 작동하다가 smartctl 명령으로 인해 순간적으로 늘어난 부하를 견디지 못하고 일시적으로 정지할 수 있다.
이때 물리 호스트에서 smartctl이 점검하며 부하를 주는 순간, 디스크 위에 파일 형태로 존재하는 Compute VM의 가상 디스크(instance-xxx.qcow2 등)에 대한 접근이 QEMU/KVM에 의해 시도되지만 디스크가 smartctl의 부하로 인해 순간적으로 응답하지 못하자, QEMU는 VM의 가상 디스크 파일을 읽는 데 실패한 상황이라고 볼 수 있다.
이는 즉, 게스트 VM(Compute 노드) 입장에서는 부팅에 필요한 자신의 루트 디스크가 갑자기 사라진 것과 같은 상황이 된 것과 동일하다.
이러한 특성들이 바로 간헐적인 하드웨어 결함의 가장 까다로운 특징이며 오류가 시스템 로그에 기록될 만큼 충분히 심각하거나 지속적이지 않고, 특정 부하 조건에서만 순간적으로 발생했다가 정상으로 돌아오는 특성을 지녀 디스크 컨트롤러나 펌웨어 수준에서 오류를 제대로 처리하거나 상위 운영체제에 보고하지 못하는 경우도 많아 이를 파악하기 어렵다.
[root@openstack-host ~]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 4.0M 0 4.0M 0% /dev
tmpfs 7.7G 0 7.7G 0% /dev/shm
tmpfs 3.1G 304M 2.8G 10% /run
/dev/mapper/rl-root 70G 63G 7.4G 90% /
/dev/nvme0n1p1 1014M 676M 339M 67% /boot
/dev/mapper/rl-home 398G 32G 367G 8% /home
tmpfs 1.6G 4.0K 1.6G 1% /run/user/0
[root@openstack-host ~]# ls /home/libvirt/images/
compute.qcow2
compute.qcow2.bak
compute.qcow2.broken
[root@openstack-host ~]# sudo smartctl -a /dev/nvme0n1
smartctl 7.2 2020-12-30 r5155 [x86_64-linux-5.14.0-503.26.1.el9_5.x86_64] (local build)
Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Number: SAMSUNG MZVLB512HBJQ-000
Serial Number: S50HNF0MC03089
Firmware Version: EXF71K2Q
PCI Vendor/Subsystem ID: 0x144d
IEEE OUI Identifier: 0x002538
Total NVM Capacity: 512,110,190,592 [512 GB]
Unallocated NVM Capacity: 0
Controller ID: 4
NVMe Version: 1.3
Number of Namespaces: 1
Namespace 1 Size/Capacity: 512,110,190,592 [512 GB]
Namespace 1 Utilization: 322,146,443,264 [322 GB]
Namespace 1 Formatted LBA Size: 512
Local Time is: Mon Jul 7 11:48:23 2025 EDT
Firmware Updates (0x16): 3 Slots, no Reset required
Optional Admin Commands (0x0017): Security Format Frmw_DL Self_Test
Optional NVM Commands (0x005f): Comp Wr_Unc DS_Mngmt Wr_Zero Sav/Sel_Feat Timestmp
Log Page Attributes (0x03): S/H_per_NS Cmd_Eff_Lg
Maximum Data Transfer Size: 512 Pages
Warning Comp. Temp. Threshold: 84 Celsius
Critical Comp. Temp. Threshold: 85 Celsius
Supported Power States
St Op Max Active Idle RL RT WL WT Ent_Lat Ex_Lat
0 + 8.00W - - 0 0 0 0 0 0
1 + 6.30W - - 1 1 1 1 0 0
2 + 3.50W - - 2 2 2 2 0 0
3 - 0.0760W - - 3 3 3 3 210 1200
4 - 0.0050W - - 4 4 4 4 2000 8000
Supported LBA Sizes (NSID 0x1)
Id Fmt Data Metadt Rel_Perf
0 + 512 0 0
=== START OF SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
SMART/Health Information (NVMe Log 0x02)
Critical Warning: 0x00
Temperature: 51 Celsius
Available Spare: 100%
Available Spare Threshold: 10%
Percentage Used: 4%
Data Units Read: 87,654,825 [44.8 TB]
Data Units Written: 60,504,814 [30.9 TB]
Host Read Commands: 1,452,109,776
Host Write Commands: 1,038,125,773
Controller Busy Time: 4,125
Power Cycles: 4,721
Power On Hours: 5,410
Unsafe Shutdowns: 83
Media and Data Integrity Errors: 0
Error Information Log Entries: 2,787
Warning Comp. Temperature Time: 0
Critical Comp. Temperature Time: 0
Temperature Sensor 1: 51 Celsius
Temperature Sensor 2: 53 Celsius
Thermal Temp. 1 Transition Count: 99
Thermal Temp. 2 Transition Count: 1
Thermal Temp. 1 Total Time: 8726
Thermal Temp. 2 Total Time: 192
Error Information (NVMe Log 0x01, 16 of 64 entries)
Num ErrCount SQId CmdId Status PELoc LBA NSID VS
0 2787 0 0x0010 0x4004 - 0 0 -부팅이 정상적으로 진행되지 않는 문제는 기존에 백업해둔 이미지를 통해 dnf update를 수행하기 이전으로 KVM을 복구하여 해결하였으며, 이전과는 다르게 문제의 근원을 파악하였기 때문에 다시금 smartctl -a /dev/nvme0n1를 통해 이미지가 존재하는 디스크를 분석하였다.
위 결과를 자세히 살펴보면,
Critical Warning: 0x00: 치명적인 경고는 존재하지 않음Temperature: 51 Celsius: 온도는 매우 안정적입니다. 과열 문제는 아님Available Spare: 100%, Percentage Used: 4%: SSD의 수명은 거의 새것과 같은 상태
위와 같은 상태 정보는 SSD의 메모리 셀 자체는 건강하다는 뜻이며 이 때문에 SMART overall-health 결과가 PASSED로 나온 것이다.
하지만
Error Information Log Entries: 2,787
위 수치는 정상적인 드라이브에서 0이어야 하지만 현재 2,787이라는 수치는 이 드라이브가 내부적으로 수천 번의 오류를 기록했다는 뜻이며, 이는 명백한 하드웨어 결함 신호라고 결론내릴 수 있었다.
이는 SSD의 데이터 저장 공간(NAND 플래시)이 아니라, SSD의 동작을 총괄하는 즉 컨트롤러나 펌웨어에 결함이 있음을 예상할 수 있었다. 컨트롤러가 불안정하면 I/O 요청을 처리하다가 순간적으로 멈추는 freezing 현상이 발생하거나 내부 오류를 내뱉는데, 이러한 증상들은 현재까지 간헐적으로 Openstack의 인스턴스들이 SHUTOFF 상태에 돌입한 증상과 유사하다.
또한 I/O 부하가 심한 Compute 노드에서만 문제가 발생하고, 상대적으로 부하가 적은 Controller 노드에서는 문제가 발생하지 않고 일반적인 상황에서는 Compute 노드가 정상 기동하다가 Kubernetes 명령을 수행할 때 즉, 부하가 높을 때만 SHUTOFF 상태에 돌입한 증상과도 유사하다.
[Scenario 1] Bad Sector
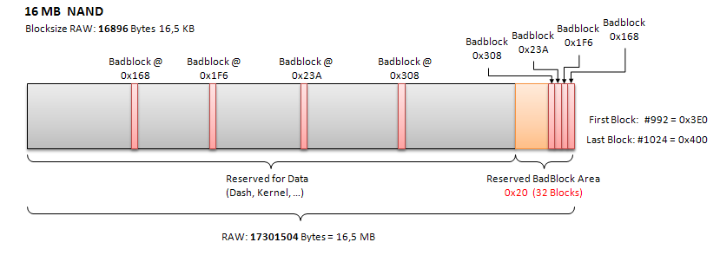
badblocks 유틸리티
이 도구는 디스크의 모든 블록에 직접 데이터를 읽고 써보면서 물리적으로 손상된 블록인 배드섹터을 찾아 목록으로 만들어주는 역할을 합니다.
1. badblocks 명령으로 디스크 파티션을 전체 스캔하여 손상된 블록 번호 목록을 파일로 저장합니다.
2. e2fsck (파일 시스템 점검 도구)에 이 목록 파일을 전달하여 파일 시스템이 해당 블록들을 '사용 중'으로 영구히 표시하도록 만듭니다.
3. 결과적으로, 파일 시스템은 그 손상된 블록들을 비어있는 공간으로 인식하지 않으므로, 앞으로 어떤 데이터도 그곳에 할당하려고 시도하지 않게 됩니다. 마치 도로의 파인 곳(pothole)을 미리 발견하고 장애물로 표시해두어 차들이 피해 가게 만드는 것과 같습니다.
이를 해결하기 위해 배드섹터를 설정하는 방법을 고려하였지만 badblocks를 실행해봐도 smartctl 진단이 PASSED로 나온 것처럼 아무런 배드섹터를 찾지 못할 것이고, 설령 찾는다 해도 드라이브 전체가 멈추는 현상은 막을 수 없다는 결론을 내렸다.
[Scenario 2] Downgrade Compute Node I/O Performance
VM이 한 번에 과도한 I/O 요청을 보내 스토리지 장애를 유발하는 상황을 막기 위해, Cgroups를 사용해 VM의 최대 I/O 사용량을 인위적으로 제한하는 시나리오를 적용해보았다.
[root@compute ~]# ls -l /dev/vda
brw-rw----. 1 root disk 253, 0 Jul 21 04:13 /dev/vda우선 VM 이미지가 저장된 디스크 장치의 Major/Minor 번호를 확인한다.
[root@compute ~]# systemd-cgtop
Control Group Tasks %CPU Memory Input/s Output/s
/ 322 - 3143049216 - -
dev-hugepages.mount - - 16384 - -
dev-mqueue.mount - - 8192 - -
init.scope 1 - 40312832 - -
machine.slice 13 - 2000859136 - -
machine.slic…nstance\x2d0000001c.scope 13 - 2000842752 - -
machine.slic…x2d0000001c.scope/libvirt - - 2000826368 - -
sys-fs-fuse-connections.mount - - 4096 - -
sys-kernel-config.mount - - 4096 - -
sys-kernel-debug.mount - - 36864 - -
sys-kernel-tracing.mount - - 4096 - -
system.slice 116 - 864739328 - -
system.slice/NetworkManager.service 3 - 12337152 - -
system.slice/auditd.service 2 - 7004160 - -
system.slice/boot.mount - - 4096 - -
system.slice/chronyd.service 1 - 4657152 - -
system.slice/crond.service 1 - 1269760 - -
system.slice/dbus-broker.service 2 - 2748416 - -
system.slice/dhclient-br-ex.service 1 - 4534272 - -이후 systemd-cgtop를 통해 VM의 cgroup scope 이름과 디스크 장치 번호 확인하고
[root@compute ~]# pgrep qemu-kvm
2325
[root@compute ~]# systemctl status 2325
● machine-qemu\x2d1\x2dinstance\x2d0000001c.scope - Virtual Machine qemu-1-inst>
Loaded: loaded (/run/systemd/transient/machine-qemu\x2d1\x2dinstance\x2d00>
Transient: yes
Active: active (running) since Mon 2025-07-21 05:06:10 EDT; 2h 48min ago
Tasks: 13 (limit: 16384)
Memory: 1.8G
CPU: 38min 7.641s
CGroup: /machine.slice/machine-qemu\x2d1\x2dinstance\x2d0000001c.scope
└─libvirt
└─2325 /usr/libexec/qemu-kvm -name guest=instance-0000001c,debug>
Jul 21 05:06:10 compute systemd[1]: Started Virtual Machine qemu-1-instance-000>정확한 Cgroup Scope 이름을 위와 같이 확인한다.
# 디스크 Major/Minor 번호
TARGET_DEVICE_MAJ_MIN="253:0"
# systemctl status 출력에 나온 Cgroup Scope 이름 그대로 감싸서 사용
TARGET_SCOPE='machine-qemu\x2d1\x2dinstance\x2d0000001c.scope'
# 초당 I/O 대역폭을 50MB로 제한
sudo systemctl set-property $TARGET_SCOPE "IOReadBandwidthMax=$TARGET_DEVICE_MAJ_MIN 50M"
sudo systemctl set-property $TARGET_SCOPE "IOWriteBandwidthMax=$TARGET_DEVICE_MAJ_MIN 50M"위 명령을 실행하시면 해당 VM의 I/O 대역폭이 제한되며 시스템을 며칠간 지켜보시면서 멈춤 현상이 완화되는지 관찰하도록 하였다.
또한 해당 유닛은 Transient Unit(Transient: yes)이므로, VM이 재시작되면 사라지거나 다른 이름으로 변경될 수 있기에 만약 해당 시나리오가 현 상황을 확정적으로 완화시킨다면 이를 추후 영구히 적용하는 방안을 찾아야 한다.
[Scenario 3] Limit PV, PVC on K8s Master
[root@kubernetes-host ~]# smartctl -a /dev/nvme0
smartctl 7.2 2020-12-30 r5155 [x86_64-linux-5.14.0-503.26.1.el9_5.x86_64] (local build)
Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Number: Micron_2450_MTFDKBA512TFK
Serial Number: 2208355B1B54
Firmware Version: V5MA010
PCI Vendor/Subsystem ID: 0x1344
IEEE OUI Identifier: 0x00a075
Controller ID: 0
NVMe Version: 1.4
Number of Namespaces: 1
Namespace 1 Size/Capacity: 512,110,190,592 [512 GB]
Namespace 1 Formatted LBA Size: 512
Namespace 1 IEEE EUI-64: 00a075 01355b1b54
Local Time is: Mon Jul 7 22:16:06 2025 EDT
Firmware Updates (0x14): 2 Slots, no Reset required
Optional Admin Commands (0x0017): Security Format Frmw_DL Self_Test
Optional NVM Commands (0x005f): Comp Wr_Unc DS_Mngmt Wr_Zero Sav/Sel_Feat Timestmp
Log Page Attributes (0x1e): Cmd_Eff_Lg Ext_Get_Lg Telmtry_Lg Pers_Ev_Lg
Maximum Data Transfer Size: 64 Pages
Warning Comp. Temp. Threshold: 83 Celsius
Critical Comp. Temp. Threshold: 85 Celsius
Supported Power States
St Op Max Active Idle RL RT WL WT Ent_Lat Ex_Lat
0 + 5.50W - - 0 0 0 0 0 0
1 + 2.40W - - 1 1 1 1 0 0
2 + 1.92W - - 2 2 2 2 0 0
3 - 0.0700W - - 3 3 3 3 1000 1000
4 - 0.0050W - - 4 4 4 4 10000 40000
Supported LBA Sizes (NSID 0x1)
Id Fmt Data Metadt Rel_Perf
0 + 512 0 0
=== START OF SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
SMART/Health Information (NVMe Log 0x02)
Critical Warning: 0x00
Temperature: 37 Celsius
Available Spare: 100%
Available Spare Threshold: 5%
Percentage Used: 0%
Data Units Read: 3,429,865 [1.75 TB]
Data Units Written: 4,749,613 [2.43 TB]
Host Read Commands: 46,523,451
Host Write Commands: 130,239,570
Controller Busy Time: 94
Power Cycles: 141
Power On Hours: 3,274
Unsafe Shutdowns: 73
Media and Data Integrity Errors: 0
Error Information Log Entries: 0
Warning Comp. Temperature Time: 0
Critical Comp. Temperature Time: 0
Temperature Sensor 1: 37 Celsius
Error Information (NVMe Log 0x01, 16 of 63 entries)
No Errors Logged현재 Openstack이 위치한 머신과는 별도의 호스트 머신인 kubernetes-host의 NVMe는 PCIe 인터페이스를 사용하여 기존 SATA SSD보다 훨씬 높은 대역폭과 낮은 지연 시간을 제공하고 Kubernetes 환경에서 컨테이너 이미지 로딩, 컨테이너 시작, 로그 쓰기, 볼륨 I/O 등 모든 I/O 집약적인 작업에서 탁월한 성능을 발휘한다.
따라서 K8s 클러스터의 PV, PVC의 쓰기 작업을 모두 Master로 제한하는 방안을 고려해보았다.
아때 Worker 노드에서 발생하는 쓰기 작업은 아래와 같이 크게 두 개로 나뉘게 된다.
-
애플리케이션 데이터 (PV/PVC)
데이터베이스나 사용자가 업로드한 파일처럼, Pod가 영구적으로 저장해야 하는 데이터이며 이 부분은 Master 노드를 NFS 서버로 만들고, Worker 노드들이 이 NFS를 사용하도록 StorageClass를 설정하면 구현할 수 있다.
즉, 이전이 가능하다. -
시스템 / 컨테이너 런타임 데이터
컨테이너 이미지 레이어: 파드를 시작하기 위해 내려받는 이미지 파일들컨테이너 로그: 파드가 stdout/stderr로 출력하는 모든 로그들입Kubelet 상태 데이터: 노드와 파드의 상태를 관리하기 위해 kubelet이 사용하는 파일들
이 파일들은 컨테이너 런타임인
containerd,cri-o등과kubelet이 로컬 디스크에 쓰는 것을 전제로 설계되었으며/var/lib/containerd,/var/log/pods경로들을 통째로 네트워크 드라이브로 마운트하는 것은 기술적으로는 시도해볼 수 있으나, 엄청난 지연 시간과 불안정성 때문에 정상적인 클러스터 운영이 불가능해지는 것을 예상해볼 수 있어 위 데이터들은 이전이 불가능하다.
설령 애플리케이션 데이터만 Master로 옮기는 데 성공하더라도, 이러한 아키텍처는 아래와 같은 더 큰 문제를 지닐 것으로 예상된다.
-
네트워크 지연으로 인한 성능 저하
모든 데이터 쓰기 작업이 네트워크를 거쳐야 합며 로컬NVMe SSD의 응답 시간은 마이크로초(µs) 단위지만, 네트워크를 통하면밀리초(ms)단위로 늘어난다.
데이터베이스 애플리케이션의 경우, 성능이 수십 배에서 수백 배까지 느려져 사실상 사용이 불가능해질 수 있다. -
Master 노드의 과부하 및 SPOF
과부하: Master 노드는 원래 클러스터를 관리하는 역할이지, 모든 Worker의 I/O를 감당하도록 설계되지 않았다. 모든 쓰기 요청이 Master로 몰리면 Master의 CPU, 메모리, 네트워크가 병목이 되어 클러스터 컨트롤 플레인 자체가 불안정해질 수 있다.단일 장애점: 만약 Master 노드나 Master와 Worker 사이의 네트워크에 문제가 생기면, 모든 Worker 노드의 애플리케이션이 동시에 데이터를 읽고 쓰지 못하게 된다. 즉, 클러스터 전체가 한순간에 마비된다.
[Scenario 4] OS NVMe, Data SMR HDD Hybrid Disk Architecture
이후 마지막으로 하드웨어 교체가 불가능하다는 제약 조건 하에서, 현재 보유한 자원인 결함이 존재하는 NVMe, 건강한 SMR HDD을 최대한 활용하는 하이브리드 디스크 구성에 관한 시나리오를 고안해보았다.
[root@openstack-host ~]# ls /dev/ | grep sd
sda
sda1
sda2
sda3
[root@openstack-host ~]# sudo smartctl -a /dev/sda
smartctl 7.2 2020-12-30 r5155 [x86_64-linux-5.14.0-503.26.1.el9_5.x86_64] (local build)
Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Western Digital Blue Mobile (SMR)
Device Model: WDC WD10SPZX-24Z10
Serial Number: WD-WXG1A89D0N10
LU WWN Device Id: 5 0014ee 266f4f70c
Firmware Version: 05.01A05
User Capacity: 1,000,204,886,016 bytes [1.00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 5400 rpm
Form Factor: 2.5 inches
TRIM Command: Available, deterministic
Device is: In smartctl database [for details use: -P show]
ATA Version is: ACS-3 T13/2161-D revision 5
SATA Version is: SATA 3.1, 6.0 Gb/s (current: 6.0 Gb/s)
Local Time is: Tue Jul 8 03:28:51 2025 EDT
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
General SMART Values:
Offline data collection status: (0x00) Offline data collection activity
was never started.
Auto Offline Data Collection: Disabled.
Self-test execution status: ( 0) The previous self-test routine completed
without error or no self-test has ever
been run.
Total time to complete Offline
data collection: ( 60) seconds.
Offline data collection
capabilities: (0x71) SMART execute Offline immediate.
No Auto Offline data collection support.
Suspend Offline collection upon new
command.
No Offline surface scan supported.
Self-test supported.
Conveyance Self-test supported.
Selective Self-test supported.
SMART capabilities: (0x0003) Saves SMART data before entering
power-saving mode.
Supports SMART auto save timer.
Error logging capability: (0x01) Error logging supported.
General Purpose Logging supported.
Short self-test routine
recommended polling time: ( 2) minutes.
Extended self-test routine
recommended polling time: ( 8) minutes.
Conveyance self-test routine
recommended polling time: ( 3) minutes.
SCT capabilities: (0x303d) SCT Status supported.
SCT Error Recovery Control supported.
SCT Feature Control supported.
SCT Data Table supported.
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x002f 200 200 051 Pre-fail Always - 0
3 Spin_Up_Time 0x0027 193 185 021 Pre-fail Always - 1341
4 Start_Stop_Count 0x0032 019 019 000 Old_age Always - 81769
5 Reallocated_Sector_Ct 0x0033 200 200 140 Pre-fail Always - 0
7 Seek_Error_Rate 0x002e 200 200 000 Old_age Always - 0
9 Power_On_Hours 0x0032 091 091 000 Old_age Always - 6991
10 Spin_Retry_Count 0x0032 100 100 000 Old_age Always - 0
11 Calibration_Retry_Count 0x0032 100 100 000 Old_age Always - 0
12 Power_Cycle_Count 0x0032 096 096 000 Old_age Always - 4706
187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always - 0
192 Power-Off_Retract_Count 0x0032 198 198 000 Old_age Always - 1875
193 Load_Cycle_Count 0x0032 156 156 000 Old_age Always - 132862
194 Temperature_Celsius 0x0022 105 085 000 Old_age Always - 38 (Min/Max 10/58)
196 Reallocated_Event_Count 0x0032 200 200 000 Old_age Always - 0
197 Current_Pending_Sector 0x0032 200 200 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0030 100 253 000 Old_age Offline - 0
199 UDMA_CRC_Error_Count 0x0032 200 200 000 Old_age Always - 0
200 Multi_Zone_Error_Rate 0x0008 100 253 000 Old_age Offline - 0
206 Flying_Height 0x0022 100 000 000 Old_age Always - 36
240 Head_Flying_Hours 0x0032 098 098 000 Old_age Always - 1738
SMART Error Log Version: 1
No Errors Logged
SMART Self-test log structure revision number 1
No self-tests have been logged. [To run self-tests, use: smartctl -t]
SMART Selective self-test log data structure revision number 1
SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS
1 0 0 Not_testing
2 0 0 Not_testing
3 0 0 Not_testing
4 0 0 Not_testing
5 0 0 Not_testing
Selective self-test flags (0x0):
After scanning selected spans, do NOT read-scan remainder of disk.
If Selective self-test is pending on power-up, resume after 0 minute delay.Western Digital Blue Mobile (SMR)
SMR 방식은 플래터 위에 트랙을 기와(Shingle)처럼 일부 겹쳐 기록해 단위 면적당 저장 밀도를 높이는 디스크 기술이며 이를 통해 동일 크기 플래터에서 더 많은 용량 확보 가능
하지만 갱신 시 겹쳐진 트랙 전체를 다시 써야 해서 랜덤 쓰기 성능이 크게 저하
위와 같이 SMR 방식을 사용하는 디스크만을 사용한다면 클러스터 운영 자체가 불가할 수 있으나 현 시나리오의 목표는 시스템 전체를 멈추게 하는 K8s의 쓰기 부하를 SMR HDD로 격리시켜서, 결함이 있는 NVMe SSD의 부담을 덜어줄 수 있을 것이라 이론적으로는 예측해볼 수 있었다.
하지만 SMR HDD의 쓰기 성능에 대한 아래와 같은 치명적인 물리적 한계가 존재하였다.
랜덤 쓰기 및 동시 다발적 I/O 취약:Kubernetes환경의 컨테이너는 다양한 종류의 I/O 패턴(로그, 캐시, 데이터베이스 파일, 임시 파일 등)을 생성하며, 이는 대부분 작고 빈번한 랜덤 쓰기 또는 여러 Pod이 동시에 접근하는 패턴을 보인다. 이때SMR HDD는 이러한 패턴에 극히 취약하여, 쓰기 작업을 처리하는 동안 디스크 전체의 응답성이 현저히 느려지거나 일시적으로 멈추는스톨(Stall)현상이 빈번하게 발생할 수 있다.Pod 및 애플리케이션 지연:data-root를SMR HDD로 변경하면, 모든 컨테이너 이미지, 컨테이너 계층, 볼륨 데이터 등이 해당 HDD에 저장된다. 이는 컨테이너 시작 시간 지연, 애플리케이션의 데이터 읽기/쓰기 작업 지연, 심각한 경우 애플리케이션 타임아웃 등을 유발하여 서비스 품질 저하로 이어진다.K8s 컴포넌트 영향:kubelet이Pod의 상태를 감지하고 컨테이너를 관리하는 과정에서도 디스크 I/O가 발생하는데SMR HDD의 성능이 저하되면kubelet의 응답성에도 영향을 미쳐, Pod 상태 불일치, Pod 강제 재시작, 노드 NotReady 상태 진입 등의 문제가 발생할 수 있다.
[Scenario 5] Openstack Flavor HW I/O Quota
openstack flavor set k8s.worker \
--property quota:disk_write_bytes_sec=209715200 \
--property quota:disk_write_iops_sec=2500마지막 시도로 HW 쓰기 속도를 200MB/s로, IOPS를 2500으로 Flavor 레벨에서 영구적으로 I/O 속도를 제한하였다.
quota:disk_write_bytes_sec: 초당 디스크 쓰기 총량을 바이트 단위로 제한quota:disk_write_iops_sec: volume type에 속한 모든 Cinder 볼륨에 대해 초당 최대 2,500개의 쓰기 I/O 작업(IOPS) 을 수행하도록 제한
openstack flavor set k8s.worker \
--property hw:disk_bus=virtio \
--property hw:cache_mode=writethrough또한 조금이라도 더 안정성을 높이기 위해, 위 속성도 추가해주었다.
-
hw:disk_bus: 디스크 버스 타입을 virtio로 설정하여 최적의 성능을 유도 (대부분 기본값) -
hw:cache_mode: 디스크 캐시 모드를 제어
writethrough 모드는 데이터가 호스트 캐시와 디스크에 모두 쓰여졌을 때 완료 신호를 보내므로 안정성을 약간 높일 수 있지만, 성능은 저하됨
디스크에 가해지는 부하의 강도와 빈도를 모두 제어하므로, 결함 있는 NVMe 컨트롤러가 멈추는 시스템 다운 현상은 현저히 줄어들거나 사라질 수 있음을 기대할 수 있었고 워커 노드가 부팅되고, 마스터 노드와 통신하며, 클러스터에 정상적으로 참여하는 기본 기능은 유지된다.
또한 현재 간단한 API 서버 등, I/O 부하가 매우 낮은 애플리케이션을 운영하고 있기 때문에 새로운 Flavor를 통해 인스턴스를 생성하고 추가적인 모니터링을 통해 동일한 문제가 재발하는지 지켜보도록 하였다.
[root@master wwwm]# k get pod
NAME READY STATUS RESTARTS AGE
wwwm-mysql-6b74788df8-vcszk 2/2 Running 0 10d
wwwm-spring-be-deployment-58589d7bdc-rfvfz 1/1 Running 0 167m
wwwm-spring-be-v2-dev-5bf69b6cb7-8hxv4 1/1 Running 0 46h다행이도 새로운 Flavor를 통해 생성한 인스턴스에 kubeadm 등을 설치할 때나 Pod를 배포할 때 기존에 비해 약간의 지연이 존재하였지만, 클러스터가 정상 작동함을 확인하였다.
[Scenario 6] Disable Compute KVM SWAP Memory
Swap이 RAM이 부족할 때 디스크의 일부를 '느린 RAM'처럼 쓰는 과정에서 발생하는 지속적이고 자잘한 무작위 I/O(random I/O)는 어떤 디스크에게나 엄청난 부담을 준다.
또한 하이브리드 구성을 고려했을 때 NVMe SDD 환경과 SMR HDD 환경에서의 Swap 메모리의 역할을 아래와 같이 정리할 수 있었으며, Kernel Panic을 유발하게 되는 과정 또한 아래와 같이 정리할 수 있었다.
1. NVMe 환경에서 Swap의 역할
- RAM 부족: VM이 실행하는 애플리케이션들이 할당된 6GB의 메모리를 거의 다 사용한다.
- 커널, Swap 사용 시작: 운영체제는 RAM 공간을 확보하기 위해 메모리의 일부 내용을 디스크의 Swap 공간으로 옮기기 시작한다.
- NVMe에 대규모 랜덤 쓰기 발생: 이 '스와핑' 과정은 NVMe에 엄청난 양의 무작위 쓰기 I/O를 유발한다.
- 컨트롤러 과부하 및 프리징: 결함이 있는 NVMe 컨트롤러는 이 부하를 감당하지 못하고 멈춰버린다.
- 시스템 전체 다운: 결국 커널 패닉이나 task blocked 오류로 이어진다.
2. SMR HDD 환경에서 Swap의 역할
SMR 드라이브에게 '지속적인 랜덤 쓰기'는 가장 피하고 싶은 최악의 워크로드이다.
- RAM 부족 및 Swap 사용 시작: 위와 동일한 이유로 스와핑이 시작된다.
- SMR 캐시 즉시 고갈: SMR 드라이브의 작은 캐시(CMR 영역)는 스와핑으로 발생하는 지속적인 쓰기 요청에 즉시 가득 차 버린다.
- '성능 절벽' 진입: 캐시가 가득 찬 드라이브는 '읽기-수정-쓰기'라는 매우 느린 모드로 전환되어, 응답 속도가 급격히 떨어진다.
- 애플리케이션 타임아웃: 이로 인해 VM 내부의 애플리케이션들은 I/O 타임아웃, 게이트웨이 타임아웃 등의 오류를 내며 사실상 멈춰버린다.
# Compute VM 내부에서 실행
free -h
# 임시로 모든 Swap 비활성화
sudo swapoff -a
# 재부팅 후에도 비활성화되도록 /etc/fstab 파일에서 swap 관련 줄을 주석 처리
sudo vim /etc/fstab따라서 이전에 Compute Node의 메모리를 추가로 확보하기 위해 SWAP을 활성화했던 것을 기억하여 이를 비활성화하고 추후 경과를 모니터링 하였다.
[Scenario 7] Disable Host SWAP Memory
[root@openstack-host ~]# free -h
total used free shared buff/cache available
Mem: 15Gi 14Gi 176Mi 55Mi 1.4Gi 1.2Gi
Swap: 7.8Gi 1.7Gi 6.1Gi현재 호스트의 거의 모든 물리 메모리가 사용되고 있으며 남은 여유는 1.2Gi(available)로 매우 적은 편이다.
이는 게스트 VM들이 필요시 메모리 페이지를 바로 할당받지 못하고, swap이 발생하거나, KVM에서 비동기 페이지 폴트(async PF)가 잦아질 수 있는 조건이다.
[root@openstack-host ~]# swapoff -a
[root@openstack-host ~]# free -h
total used free shared buff/cache available
Mem: 15Gi 14Gi 491Mi 307Mi 451Mi 396Mi
Swap: 0B 0B 0B따라서 시험적으로 swapoff -a를 실행였다.
이후에도 OOM 상황 없이 시스템이 정상적으로 동작하는 것으로 보아 메모리가 반드시 부족해질 때 paging하는 등 swap이 시스템 필수 불가결한 역할을 하고 있다는 것은 아니었음을 의미한다.
따라서 현 상황에서 추가적인 추이를 관찰하도록 결정하였다.
Conclusion
위와 같은 여러 시나리오를 고안해본 결과 현 상황에서 취할 수 있는 가장 올바른 조치는, 문제가 되는 하드웨어를 사용하지 않도록 워크로드를 옮기는 거시적인 관점의 VM 마이그레이션이 성능 향상을 위해 올바른 방향이라고 결론지었다.
하지만 이전에 발생했던 문제는 Host 머신의 SWAP 설정으로 인해 발생했던 문제임을 확인하고 현 상황에서의 최선의 해결책임을 확인하였다.
언제볼까 v2 Deployment
MySQL Deployment
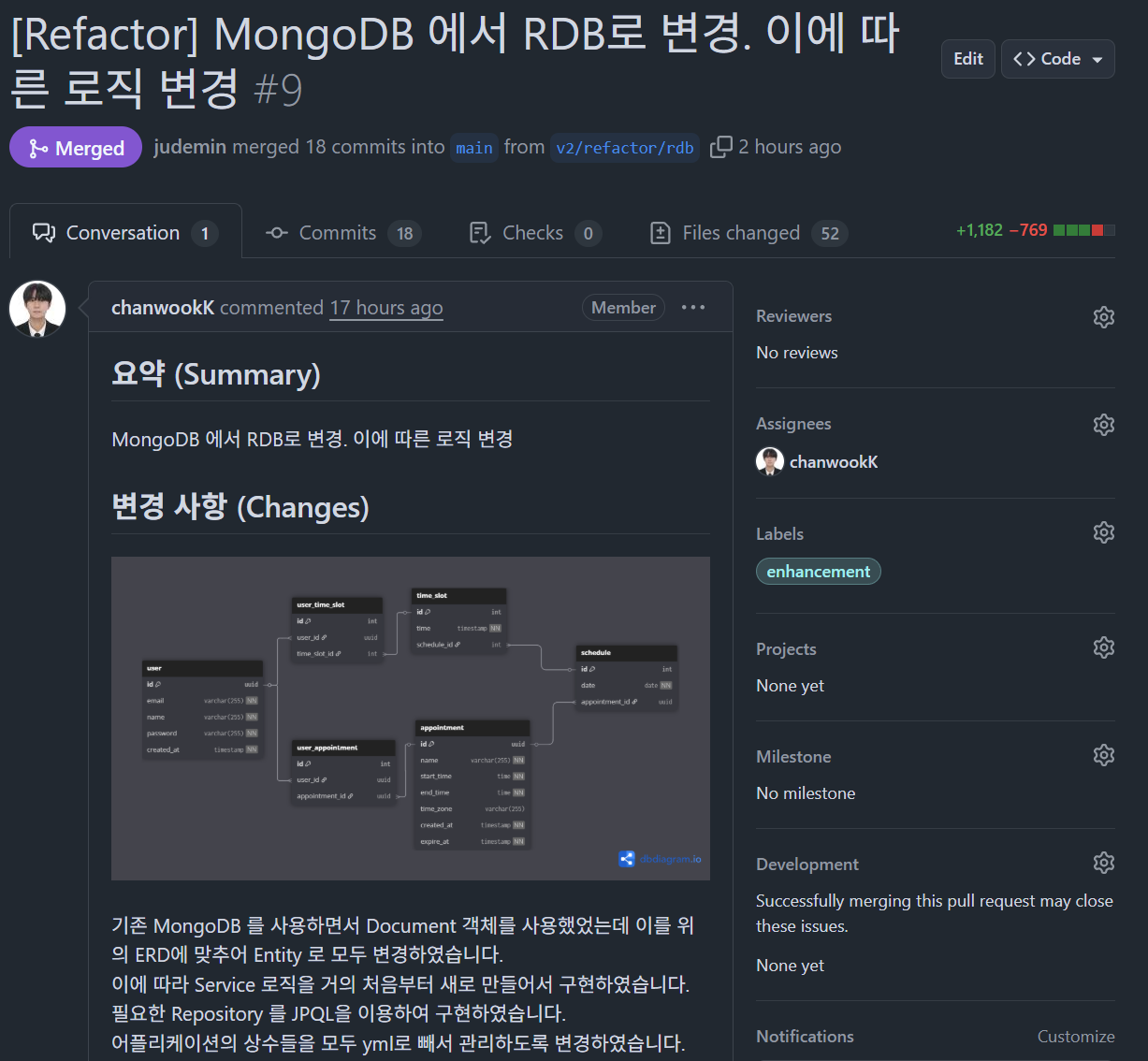
 현재 v2의 경우 모두 MongoDB를 기반으로 개발이 완료된 상황이었는데 추후
현재 v2의 경우 모두 MongoDB를 기반으로 개발이 완료된 상황이었는데 추후 RAVO 프로젝트의 적용과 성능 및 데이터 관리의 측면에서 RDB로 전면 교체하는 것이 낫다는 결론이 내려져 본격적인 전환 이전에 미리 현 클러스터에 MySQL DB를 배포하여 개발을 원활하게 하고자 한다.
apiVersion: v1
kind: PersistentVolume
metadata:
name: wwwm-mysql-pv
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
storageClassName: manual
hostPath:
path: "/mnt/data/wwwm-mysql"
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: wwwm-mysql-pvc
spec:
accessModes:
- ReadWriteOnce # 단일 노드에서만 Read/Write 가능한 모드
storageClassName: manual # 동적 프로비저닝 없이, 직접 PV를 만들겠다는 의미
resources:
requests:
storage: 10Gi
volumeName: wwwm-mysql-pv
---
apiVersion: v1
kind: ConfigMap
metadata:
name: mysql-exporter-config
data:
.my.cnf: |
[client]
user=root
password=<PASSWORD>
host=127.0.0.1
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: wwwm-mysql
spec:
replicas: 1
selector:
matchLabels:
app: wwwm-mysql
template:
metadata:
labels:
app: wwwm-mysql
spec:
# master 노드의 NoSchedule taint를 허용
# 미상의 원인으로 Worker Node를 위한 Openstack Instance가 중지되는 문제 일시적 조치
tolerations:
- key: "node-role.kubernetes.io/control-plane"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: wwwm-mysql
image: mysql:latest
# Failover를 위한 readinessProbe 설정
readinessProbe:
exec:
command:
- mysqladmin
- ping
- "-h127.0.0.1"
ports:
- containerPort: 3306
env:
- name: MYSQL_ROOT_PASSWORD
value: <PASSWORD>
- name: MYSQL_ROOT_HOST # 루트 계정을 원격 접속 허용하려면 MYSQL_ROOT_HOST=%를 추가
value: "%"
- name: MYSQL_DATABASE
value: wwwwm_db
- name: MYSQL_USER
value: wwwm_user
- name: MYSQL_PASSWORD
value: <PASSWORD>
resources:
limits:
memory: "800Mi"
cpu: "500m"
requests:
memory: "800Mi"
cpu: "500m"
volumeMounts:
- name: wwwm-mysql-data
mountPath: /var/lib/mysql
# mysqld_exporter sidecar
- name: wwwm-mysql-exporter
image: prom/mysqld-exporter:latest
args:
- "--config.my-cnf=/config/.my.cnf"
ports:
- containerPort: 9104
resources:
limits:
memory: "128Mi"
volumeMounts:
- name: mysql-exporter-config
mountPath: /config/.my.cnf
subPath: .my.cnf
volumes:
- name: wwwm-mysql-data
persistentVolumeClaim:
claimName: wwwm-mysql-pvc
- name: mysql-exporter-config
configMap:
name: mysql-exporter-config
---
apiVersion: v1
kind: Service
metadata:
name: wwwm-mysql-service
spec:
type: NodePort
selector:
app: wwwm-mysql
ports:
# MySQL
- name: mysql
protocol: TCP
port: 3306
targetPort: 3306
nodePort: 32306
# mysqld_exporter
- name: metrics
protocol: TCP
port: 9104
targetPort: 9104
nodePort: 32104-
PersistentVolume (wwwm-mysql-pv)
capacity: 10Gi로 고정 용량 설정accessModes: ReadWriteOnce→ 단일 노드에서만 읽기·쓰기 가능storageClassName: manual→ 동적 프로비저닝 없이 수동 바인딩hostPath: "/mnt/data/wwwm-mysql"→ 호스트 디렉터리 직접 마운트
-
PersistentVolumeClaim (wwwm-mysql-pvc)
storageClassName: manual로 특정 PV에 직접 연결requests.storage: 10Gi→ PV와 동일한 크기 요청volumeName: wwwm-mysql-pv→ 명시적 바인딩으로 PV 고정
-
ConfigMap (mysql-exporter-config)
-
키
.my.cnf에 MySQL 클라이언트 접속 정보 저장[client] user=root password=root host=127.0.0.1 -
prom/mysqld-exporter사이드카가/config/.my.cnf로 참조
-
-
Deployment (wwwm-mysql)
-
Primary 컨테이너:
- 이미지:
mysql:latest - 환경변수로
MYSQL_ROOT_PASSWORD,MYSQL_ROOT_HOST,MYSQL_USER,MYSQL_PASSWORD설정 readinessProbe(mysqladmin ping) 로 DB 준비 상태 감시- 리소스
requests/limits모두cpu:500m,memory:800Mi volumeMounts로 PVC(wwwm-mysql-data) →/var/lib/mysql마운트
- 이미지:
-
Sidecar 컨테이너 (
mysqld-exporter):- 이미지:
prom/mysqld-exporter:latest --config.my-cnf=/config/.my.cnf로 ConfigMap 사용- 메트릭 포트
9104노출
- 이미지:
-
-
Service (wwwm-mysql-service)
-
type: NodePort→ 각 노드 임의 포트로 외부 접근 -
포트 매핑
- MySQL:
port:3306→nodePort:32306 - Exporter:
port:9104→nodePort:32104
- MySQL:
-
selector: app=wwwm-mysql로 Deployment 파드 트래픽 라우팅
-
[root@master k8s]# k get pod -w
NAME READY STATUS RESTARTS AGE
wwwm-mysql-56dc8c59b-7cb56 2/2 Running 0 12s
wwwm-spring-be-deployment-5d6f65c667-89l4n 1/1 Running 0 3h56mk8s-mysql-stream.conf
sudo dnf install nginx-mod-stream -y
sudo mkdir -p /etc/nginx/stream.d# nginx.conf
# Stream 모듈 추가
stream {
include /etc/nginx/stream.d/*.conf;
}# vim stream.d/k8s-mysql-stream.conf
upstream wwwm-mysql {
server 172.20.112.101:32306;
}
server {
listen 33306;
proxy_pass wwwm-mysql;
}이후 외부에서 연결을 위한 nginx 포워딩 정책을 위와 같이 설정하여준다.
이때 Nginx의 Stream 모듈은 HTTP 및 HTTPS 외에도 TCP와 UDP 트래픽을 처리해 포워딩하는 기능을 제공한다.
즉, 일반적인 웹 요청 이외에 MySQL과 같은 TCP 기반 데이터베이스나 SSH, SMTP, FTP 등 다양한 프로토콜을 중계하는 용도로 사용된다.
MySQL 프로토콜은 HTTP가 아니라 TCP Stream을 이용하기 때문에, HTTP 프록시처럼 proxy_pass를 사용하는 대신 Stream 모듈을 활용해야 한다.
 이후 정상적으로 DBeaver에서 DB로 접근이 가능한 것을 확인할 수 있었으며
이후 정상적으로 DBeaver에서 DB로 접근이 가능한 것을 확인할 수 있었으며
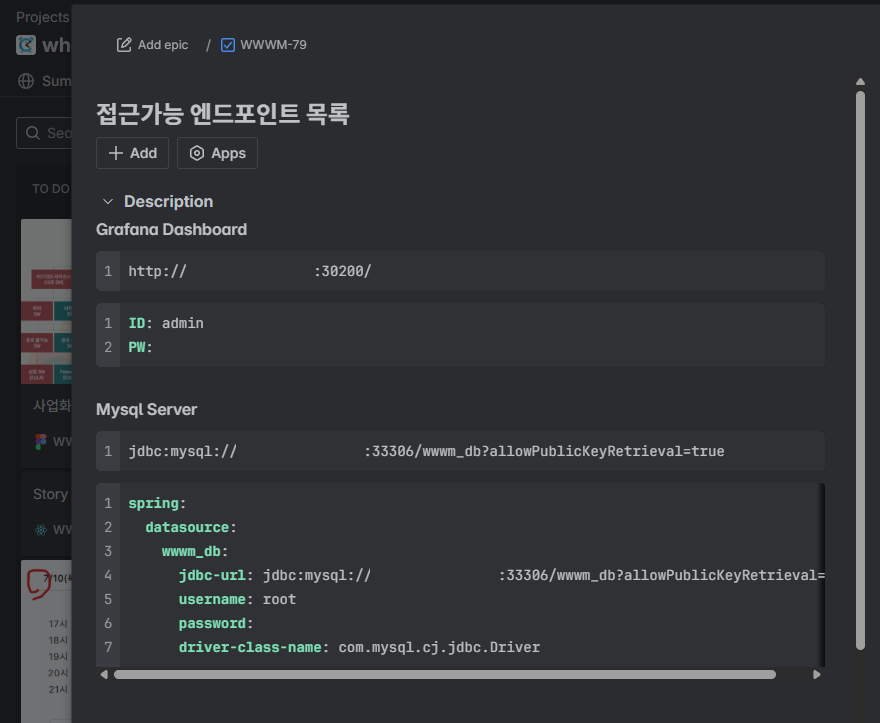 최종적으로 Jira에 접근 가능한 엔드포인트 목록을 기록한 뒤 팀원분들께 공유하였다.
최종적으로 Jira에 접근 가능한 엔드포인트 목록을 기록한 뒤 팀원분들께 공유하였다.
Spring v2 Deployment
 이후 BE 개발자 팀원분께서 RDB로 변경된 v2를 제공해주셔서 이를 시범적으로 배포하고자 한다.
이후 BE 개발자 팀원분께서 RDB로 변경된 v2를 제공해주셔서 이를 시범적으로 배포하고자 한다.
jobs:
build:
runs-on: ubuntu-latest
steps:
- name: checkout
uses: actions/checkout@v3
- name: Set up JDK 17
uses: actions/setup-java@v3
with:
java-version: '17'
distribution: 'temurin'
## create application-private.yml
- name: make application-private.yml
run: |
## create application-private.yml
cd ./src/main/resources
# application-private.yml 파일 생성
touch ./application-private.yml
# GitHub-Actions 에서 설정한 값을 application-private.yml 파일에 쓰기
echo "${{ secrets.SPRING_BE_APPLICATION_PRIVATE }}" >> ./application-private.yml
shell: bash
...우선 Git Workflow를 위와 같이 변경된 내용에 맞게 application-private.yml를 생성하고 주입하도록 수정하고
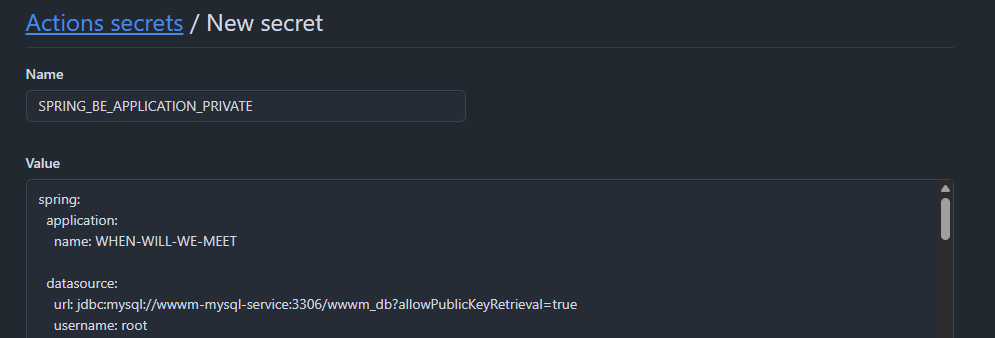 Git의 Repository의 Secret도 추후 K8s에 배포될 수 있도록 DataSource URL을 K8s의 서비스로 수정하여준다.
Git의 Repository의 Secret도 추후 K8s에 배포될 수 있도록 DataSource URL을 K8s의 서비스로 수정하여준다.
apiVersion: v1
kind: ConfigMap
metadata:
name: wwwm-spring-be-v2-config
data:
application-private.yml: |-
spring:
application:
name: WHEN-WILL-WE-MEET
datasource:
# 외부 IP 주소 대신 wwwm-mysql-service 사용
url: jdbc:mysql://wwwm-mysql-service:3306/wwwm_db?allowPublicKeyRetrieval=true
username: root
password: <PW>
driver-class-name: com.mysql.cj.jdbc.Driver
jpa:
hibernate:
ddl-auto: validate
properties:
hibernate.format_sql: true
dialect: org.hibernate.dialect.MySQL8InnoDBDialect
show-sql: true
jackson:
time-zone: UTC
constant:
appointment-expiration-time: 30
time-slot-unit-time: 10
jwt:
secret:
key: <SECRET>
public-url: /api/v2/users/auth/signup, /api/v2/users/auth/login, /
utils:
authorization-header: Authorization
id-key: id
bearer-prefix: Bearer
token-time: 3600000위 Workflow의 경우 추후 ArgoCD를 통한 CD 파이프라인 구축 시 위와 같이 별도의 ConfigMap을 VolumeMount를 통해 Spring BE 애플리케이션에 적용하도록 수정할 예정이다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: wwwm-spring-be-v2-dev
spec:
replicas: 1
selector:
matchLabels:
app: wwwm-spring-be-v2-dev
template:
metadata:
labels:
app: wwwm-spring-be-v2-dev
spec:
containers:
- name: wwwm-spring-be-v2-dev
image: judemin/wwwm-spring-be:latest
# 이미지 Pull 정책을 명시적으로 설정하여 항상 최신 이미지를 사용하도록 보장
imagePullPolicy: Always
ports:
- containerPort: 8080
resources:
requests:
cpu: "500m"
memory: "500Mi"
limits:
cpu: "800m"
memory: "800Mi"
---
apiVersion: v1
kind: Service
metadata:
name: wwwm-spring-be-v2-dev
labels:
app: wwwm-spring-be-v2-dev
spec:
type: NodePort
selector:
app: wwwm-spring-be-v2-dev
ports:
- name: port8080
protocol: TCP
port: 8080
targetPort: 8080
nodePort: 30081또한 이후 위와 같이 임시로 wwwm-spring-be-v2-dev를 배포할 수 있는 메니페스트 파일을 작성하고 해당 Application을 30081 NodePort 서비스로 외부로 노출시킨 뒤
server {
listen 8082;
server_name _;
location / {
proxy_pass http://172.20.112.101:30081;
proxy_set_header Host wwwm-spring-be.com;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_http_version 1.1;
proxy_set_header Connection "";
}
}nginx에 위와 같은 conf 파일을 추가해주면
 FE 개발을 위해 CloudFlare의 Public Domain을 거치지 않고 바로 BE 서버에 정상적으로 접근이 가능한 모습을 볼 수 있으며
FE 개발을 위해 CloudFlare의 Public Domain을 거치지 않고 바로 BE 서버에 정상적으로 접근이 가능한 모습을 볼 수 있으며
java.lang.NullPointerException: Not Found Token
at org.example.whenwillwemeet.security.jwt.JwtUtils.substringToken(JwtUtils.java:71) ~[!/:0.0.1-SNAPSHOT]
at org.example.whenwillwemeet.security.jwt.JwtUtils.getTokenFromRequest(JwtUtils.java:94) ~[!/:0.0.1-SNAPSHOT]
at org.example.whenwillwemeet.security.jwt.JwtFilter.doFilterInternal(JwtFilter.java:46) ~[!/:0.0.1-SNAPSHOT]
at org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:116) ~[spring-web-6.1.11.jar!/:6.1.11]
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:164) ~[tomcat-embed-core-10.1.26.jar!/:na]단순히 브라우저를 통해 요청했기 때문에 BE 로그에 java.lang.NullPointerException: Not Found Token 오류가 찍히지만 정상 접근은 가능함을 확인할 수 있었다.
 이를 바탕으로 현재 진행되고 있는 FE v1에 대한 QA와 리팩토링 그리고 추후 Spring v2에 맞추어 개발하는 과정이 동시에, 그리고 유기적으로 이루어질 수 있도록 위와 같이 엔드포인트 목록을 업데이트하고 FE 개발자분께 이를 말씀드렸다.
이를 바탕으로 현재 진행되고 있는 FE v1에 대한 QA와 리팩토링 그리고 추후 Spring v2에 맞추어 개발하는 과정이 동시에, 그리고 유기적으로 이루어질 수 있도록 위와 같이 엔드포인트 목록을 업데이트하고 FE 개발자분께 이를 말씀드렸다.
ArgoCD CD Pipeline
ArgoCD Deployment
Helm Chart
# Helm Repo 등록 및 업데이트
helm repo add argo https://argoproj.github.io/argo-helm
helm repo update
# argocd 네임스페이스 생성
kubectl create namespace argocd현재 클러스터에 ArgoCD를 배포하기 위해 위와 같이 Helm Repo를 등록하고 namespace를 생성해주었다.
controller:
replicaCount: 1
resources:
requests:
cpu: 25m
memory: 256Mi
limits:
cpu: 100m
memory: 512Mi
server:
replicaCount: 1
resources:
requests:
cpu: 50m
memory: 128Mi
limits:
cpu: 200m
memory: 256Mi
repoServer:
replicaCount: 1
resources:
requests:
cpu: 25m
memory: 64Mi
limits:
cpu: 100m
memory: 128Mi
redis:
resources:
requests:
cpu: 25m
memory: 64Mi
limits:
cpu: 100m
memory: 128Mi
# 사용하지 않는 컴포넌트 비활성화
applicationSet:
enabled: false
dex:
enabled: false
metrics:
server:
resources:
requests:
cpu: 10m
memory: 32Mi
limits:
cpu: 50m
memory: 64Mi또한 우선 리소스를 아끼기 위해 위와 같이 적은 규모의 리소스를 설정해주었다.
이러한 값으로도 작은 규모 즉, 1~5개 애플리케이션 정도까지는 Argo CD가 정상 기동하지만 추후 베포하고자 하는 Repository 크기나 동시 task 수가 늘어나면 CPU 부족으로 지연과 메모리 부족으로 OOM이 발생할 수 있기 때문에 모니터링을 통해 실제 사용량을 관찰하며 필요시 점진적으로 리소스를 늘리고자 한다.
helm install argocd argo/argo-cd \
-n argocd \
-f values.yaml[root@master argocd]# k get pod -n argocd
NAME READY STATUS RESTARTS AGE
argocd-application-controller-0 1/1 Running 0 87s
argocd-applicationset-controller-68f9f99d89-29528 1/1 Running 0 87s
argocd-notifications-controller-f55767bc9-4mcqv 1/1 Running 0 87s
argocd-redis-5d897dfdbb-nlrmv 1/1 Running 0 87s
argocd-repo-server-b88c9fdb6-sx4d6 1/1 Running 0 87s
argocd-server-86ccb59bc8-vlf2d 1/1 Running 0 87s이후 위와 같이 성공적으로 배포가 완료되고 모든 Pod들이 정상 기동하는 것을 확인할 수 있었으며
# argocd 비밀번호 확인
kubectl get secret -n argocd argocd-initial-admin-secret -o jsonpath="{.data.password}" | base64 -d
[root@master argocd]# kubectl get svc -n argocd
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
argocd-applicationset-controller ClusterIP 10.110.47.79 <none> 7000/TCP 54s
argocd-redis ClusterIP 10.102.220.25 <none> 6379/TCP 53s
argocd-repo-server ClusterIP 10.104.143.154 <none> 8081/TCP 54s
argocd-server NodePort 10.110.184.251 <none> 80:30808/TCP,443:30809/TCP 53s비밀번호와 NodePort Service의 포트들도 정상적으로 설정된 것을 확인할 수 있었다.
[TroubleShooting] ArgoCD TLS Redirecting
용어 설명 SSL Secure Sockets Layer
– 넷스케이프 시절에 개발된 초기 암호화 프로토콜TLS Transport Layer Security
– SSL 3.0을 대체하면서 설계 결함을 보완한 최신 보안 프로토콜HTTPS Hypertext Transfer Protocol Secure
– HTTP 위에 SSL/TLS 암호화를 얹은 통신 방식HTTPS = HTTP + (SSL 또는 TLS)라고 볼 수 있으며 오늘날엔 대부분
TLS 1.2/1.3을 사용하며,SSL은 관습적으로 남아 있는 용어이다.
Argo CD 서버는 기본적으로 HTTP 요청을 HTTPS로 리다이렉트하도록 설정되어 있는데,
TLS 인증서가 없거나 자체 서명일 경우 브라우저/클라이언트에서 안전하지 않음을 경고하고
인그레스나 프록시가 이미 TLS 종료한 뒤 내부에 HTTP만 남겨두면 무한 리다이렉트 루프 발생하여 정상 기동이 불가하다.
[root@master argocd]# curl localhost:30808
<a href="https://localhost:30808/">Temporary Redirect</a>.주석의 설명과 같이 클러스터 내부에서 요청하였을 때 proxy_pass http://…:30808처럼 HTTP로 요청해도 리다이렉트가 발생하는 것을 볼 수 있었다.
# values.yaml
# 아래 설정이 있으면 HTTP로만 서비스하고 TLS 리다이렉트를 비활성화
configs:
params:
# Helm Chart v6 이후부터는
# configs.params 블록을 아래와 같은 형태가 아니면 해석하지 못함
create: true # 반드시 선언
server.insecure: true # dotted key 그대로이러한 상황에서는 ArgoCD 대시보드 접근이 Authorization이 정상적으로 이루어지지 않기 때문에 위와 같이 HTTP로만 서비스하고 TLS 리다이렉트를 비활성화하도록 하였다.
또한 Helm Chart v6 이후부터는 configs.params 블록을 위와 같은 형태(create: true 선언과dotted key)가 아니면 해석하지 못하여 이를 추가주었고
curl localhost:30808
<!doctype html><html lang="en"><head><meta charset="UTF-8"><title>Argo CD</title><base href="/"><meta name="viewport" content="width=device-width,initial-scale=1"><link rel="icon" type="image/png" href="assets/favicon/favicon-32x32.png" sizes="32x32"/><link rel="icon" type="image/png" href="assets/favicon/favicon-16x16.png" sizes="16x16"/><link href="assets/fonts.css" rel="stylesheet"><script defer="defer" src="main.aabf5778d950742bec21.js"></script></head><body><noscript><p>Your browser does not support JavaScript. Please enable JavaScript to view the site. Alternatively, Argo CD can be used with the <a href="https://argoproj.github.io/argo-cd/cli_installation/">Argo CD CLI</a>.</p></noscript><div id="app"></div></body><script defer="defer" src="extensions.js"></script></html>ArgoCD를 재설치하여 위와 같이 클러스터 내에서 리다이랙트되지 않고 접근이 가능함을 확인할 수 있었다.
Host Machine Nginx 설정
sudo semanage port -a -t http_port_t -p tcp 30909
sudo firewall-cmd --add-port=30909/tcp --permanent
sudo firewall-cmd --reload또한 외부에서도 접근이 가능하도록 K8s 호스트 머신에서 위와 같이 보안 설정을 완료하고
server {
listen 30909;
server_name _;
location / {
proxy_pass http://172.20.112.101:30808;
proxy_http_version 1.1;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header Connection "";
}
}nginx의 프록시를 위와 같이 설정해주어
 로그인 이후 ArgoCD 대시보드에 정상적으로 외부 브라우저를 통해 접근할 수 있었다.
로그인 이후 ArgoCD 대시보드에 정상적으로 외부 브라우저를 통해 접근할 수 있었다.
WWWM-BE CD Pipeline
ArgoCD Application Resource 생성
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: wwwm-spring-be
namespace: argocd
spec:
project: default
source:
repoURL: 'https://github.com/TEAM-WHEN-WILL-WE-MEET/WWWM-INFRA.git'
targetRevision: main
path: kubernetes-master/wwwm-spring-be
destination:
server: 'https://kubernetes.default.svc'
namespace: default
syncPolicy:
automated:
prune: true
selfHeal: true
syncOptions:
- CreateNamespace=trueArgoCD에 설정한 Git 리포지토리를 감시하고, 변경사항이 생기면 이 클러스터에 배포하라고 알려주는 Application 리소스를 위와 같이 생성한다.
repoURL: 'https://github.com/TEAM-WHEN-WILL-WE-MEET/WWWM-INFRA.git': 추적할 매니페스트 파일이 있는 Repo 주소를 명시해주고targetRevision: main: 추적할 브랜치를 설정path: kubernetes-master/wwwm-spring-be: 리포지토리 내 매니페스트 파일이 위치한 경로prune: true: Git에서 사라진 리소스를 클러스터에서도 자동 삭제selfHeal: true: 클러스터의 상태가 Git과 다를 경우 자동으로 Git 상태로 복구
또한 주요 설정 값들의 의미는 위와 같다
 이후
이후 kubectl apply -f를 통해 이를 적용하면 위와 같이 ArgoCD의 UI에서 확인할 수 있고
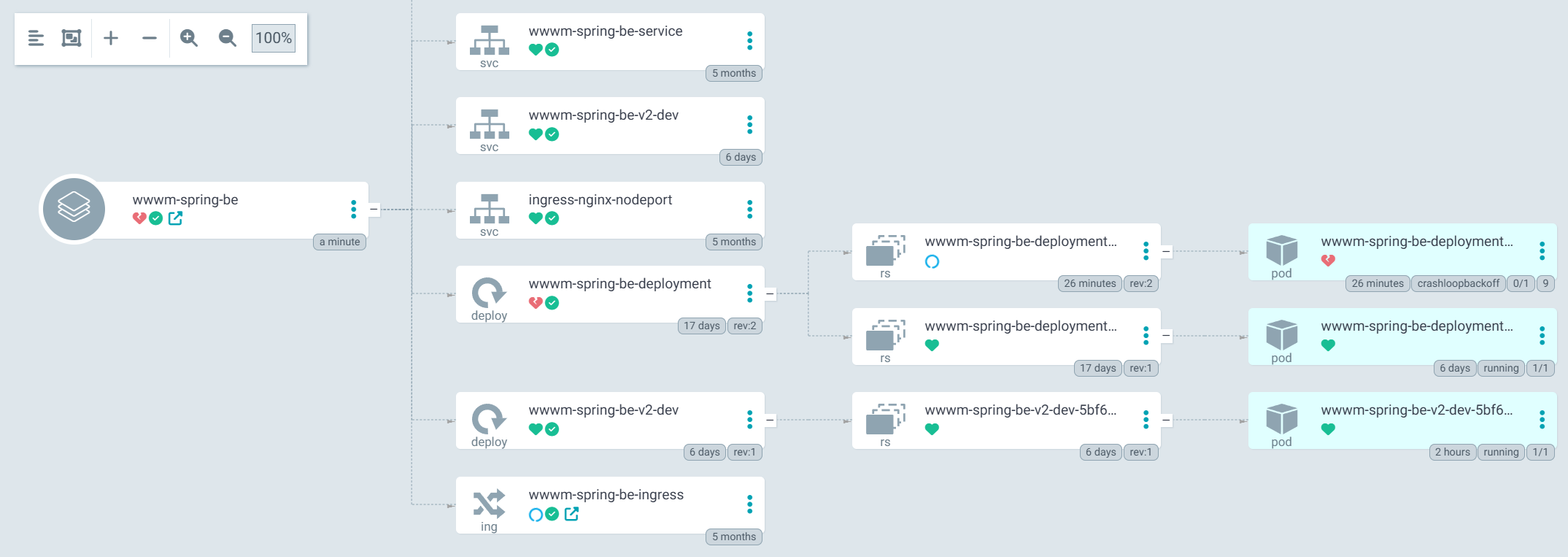 현재 클러스터 상태와 잘 동기화가 되어있는 것을 볼 수 있다
현재 클러스터 상태와 잘 동기화가 되어있는 것을 볼 수 있다
secrets.PAT_FOR_MANIFEST_REPO 설정
WWWM-SPRING-BE의 CI 파이프라인이 매니페스트 리포지토리에 git push를 하려면 권한이 필요하기 때문에 PAT(Personal Access Token)를 생성해준다.
현재 Organization의 설정이 외부 Token의 Access를 허용하고 있는 상태이기에 Owner 권한을 가진 사용자의 PAT가 정상적으로 적용된다.
 위와 같은 이름으로 우선 Token을 실행해주고
위와 같은 이름으로 우선 Token을 실행해주고
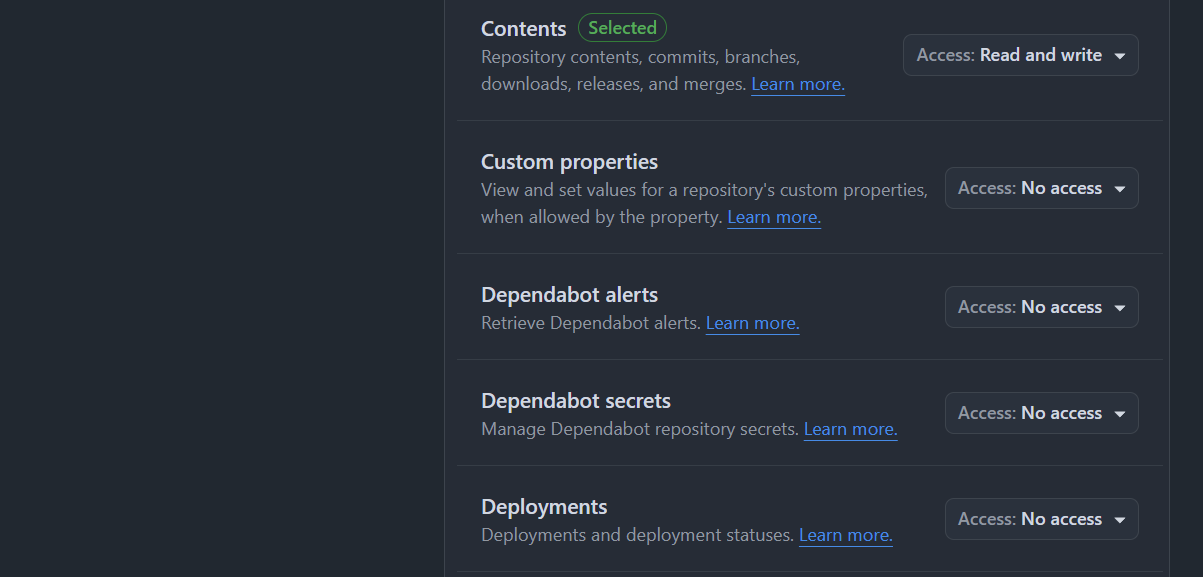 허용 권한의 경우
허용 권한의 경우 Contents에 대한 Read and Write 권한으로 설정한다.
 이후 위와 같이 Organization의 Secret에 PAT를 추가한다.
이후 위와 같이 Organization의 Secret에 PAT를 추가한다.
WWWM-BE Workflow 수정
name: Spring Boot CI/CD with Gradle
on:
push:
branches: [ "main" ]
permissions:
contents: read
jobs:
build:
runs-on: ubuntu-latest
steps:
### 1. CI: 소스 코드 빌드 및 Docker 이미지 생성
- name: checkout
uses: actions/checkout@v3
- name: Set up JDK 17
uses: actions/setup-java@v3
with:
java-version: '17'
distribution: 'temurin'
# create application-private.yml
- name: make application-private.yml
run: |
## create application-private.yml
cd ./src/main/resources
# application-private.yml 파일 생성
touch ./application-private.yml
# GitHub-Actions 에서 설정한 값을 application-private.yml 파일에 쓰기
echo "${{ secrets.SPRING_BE_APPLICATION_PRIVATE }}" >> ./application-private.yml
shell: bash
# gradle build
- name: Build with Gradle
run: |
chmod +x ./gradlew
./gradlew bootJar
shell: bash
- name: Set up Docker Buildx
uses: docker/setup-buildx-action@v1
- name: Login to DockerHub
uses: docker/login-action@v1
with:
username: ${{ secrets.ORG_JUDEMIN_DOCKERHUB_USERNAME }}
password: ${{ secrets.ORG_JUDEMIN_DOCKERHUB_PASSWORD }}
- name: Set Unique Image Tag
id: image_tag
run: echo "tag=$(echo ${GITHUB_SHA} | cut -c1-7)" >> $GITHUB_OUTPUT
- name: Docker Build and Push
uses: docker/build-push-action@v2
with:
context: .
push: true
tags: judemin/wwwm-spring-be:${{ steps.image_tag.outputs.tag }}
cache-from: type=gha
cache-to: type=gha,mode=max기존의 CI Git Workflow 코드를 위와 같이 Unique한 태그를 설정하도록 수정하고
### 2. CD: WWWM-INFRA Repo의 K8s 매니페스트 업데이트
- name: Checkout Infra Repository
uses: actions/checkout@v3
with:
repository: 'TEAM-WHEN-WILL-WE-MEET/WWWM-INFRA'
token: ${{ secrets.PAT_FOR_INFRA_REPO }}
path: 'WWWM-INFRA'
- name: Update Kubernetes Manifest
run: |
# 수정할 매니페스트 파일 경로 지정
TARGET_FILE="WWWM-INFRA/kubernetes-master/wwwm-spring-be/v2-spring-deployment-dev.yaml"
# sed 명령어로 이미지 태그를 새로 빌드된 태그로 교체
sed -i "s|image: judemin/wwwm-spring-be:.*|image: judemin/wwwm-spring-be:${{ steps.image_tag.outputs.tag }}|g" $TARGET_FILE
# git 설정 및 변경사항 커밋/푸시
cd WWWM-INFRA
git config --global user.name "GitHub Actions"
git config --global user.email "actions@github.com"
git add .
git commit -m "CI: Update wwwm-spring-be image to ${{ steps.image_tag.outputs.tag }}"
git push
shell: bash WWWM-INFRA Repo의 K8s 매니페스트 업데이트하는 CD 과정을 추가한다.
이는 Update Kubernetes Manifest Step에서 이루어질 수 있도록 한다.
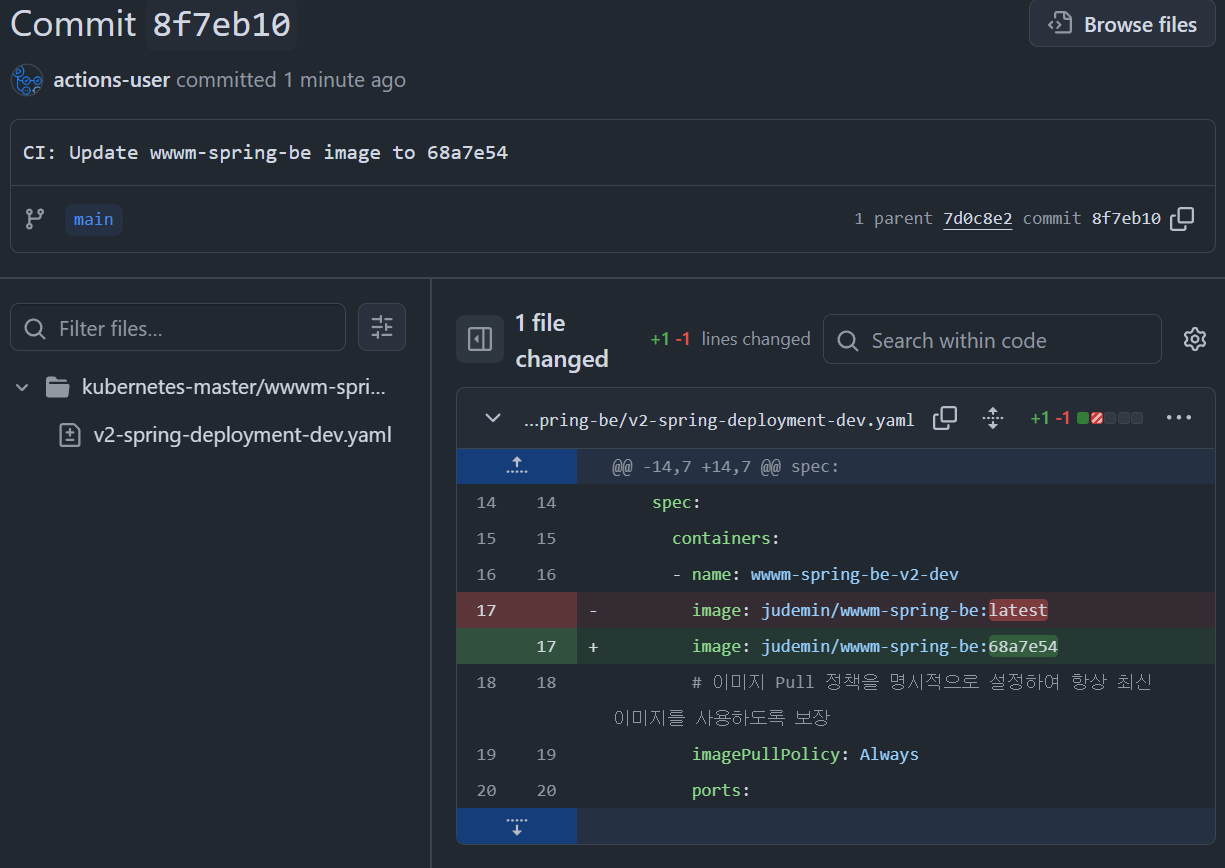 이후 이를 적용하면 위와 같이 성공적으로 deployment의 이미지 파일이 수정된 것을 볼 수 있으며
이후 이를 적용하면 위와 같이 성공적으로 deployment의 이미지 파일이 수정된 것을 볼 수 있으며
[root@master argocd]# k get pod
wwwm-spring-be-v2-dev-5bf69b6cb7-x84xm 1/1 Running 0 162m
wwwm-spring-be-v2-dev-7548db74c8-qsr6b 0/1 ContainerCreating 0 16s
[root@master argocd]# k get pod
NAME READY STATUS RESTARTS AGE
wwwm-spring-be-v2-dev-7548db74c8-qsr6b 1/1 Running 0 18sPod도 정상적으로 재배포된 것을 볼 수 있다.
 또한 최종적인 결과를 위와 같이 UI에서도 확인할 수 있다.
또한 최종적인 결과를 위와 같이 UI에서도 확인할 수 있다.
이로써 성공적으로 ArgoCD를 이용해 v2-dev Pod에 대한 CI/CD 파이프라인이 구축되었고 추후 v2 개발이 완료되는대로 Service를 수정하고 v1의 Manifest를 제거할 계획이다.
