🖇 왜 시각화가 중요한가?
🖇 2D 시각화 (PC1 vs PC2)
🖇 3D 시각화 (PC1, PC2, PC3)
드디어 K-Means 클러스터링까지 완료하였다.
이제 클러스터링 결과가 의미 있는 고객 그룹을 잘 분리하고 있는지를 시각화를 통해 확인해야 한다.
그전에 분석에서 시각화가 왜 중요한지부터 짚어보고 넘어가자.
🖇 왜 시각화가 중요한가?
클러스터링은 고객을 그룹으로 나누는 작업이다. 하지만 숫자만으로는 그 품질을 직관적으로 확인하기 어렵다.
따라서 시각화 과정을 거쳐야 분석이 제대로 이루어졌는지 확인하고 명확한 인사이트를 도출까지 이어질 수 있다.
시각화를 통해 다음을 확인할 수 있다.
- 각 클러스터가 얼마나 응집력 있게 모여 있는지
- 서로 다른 클러스터들이 얼마나 잘 분리되어 있는지
- 일부 클러스터가 겹치거나 섞여 있지는 않은지
🖇 2D 시각화 (PC1 vs PC2)
이를 통해 클러스터의 분리와 응집의 품질을 시각적으로 확인하기 위해 시각화가 필요하다는 것을 알 수 있었다.
먼저,
PCA를 통해 축소한 6개의 주성분(PC) 중 가장 많은 분산을 캡처하는 최상위 2개 주성분 PC1, PC2를 기준으로 시각화를 진행해 보았다.
# 각 클러스터 별 데이터 분리
cluster_0 = data_pca[data_pca['cluster'] == 0]
cluster_1 = data_pca[data_pca['cluster'] == 1]
cluster_2 = data_pca[data_pca['cluster'] == 2]
# 클러스터 별 시각화
plt.scatter(cluster_0['PC1'], cluster_0['PC2'], color = 'orange', alpha = 0.7, label = 'Group1')
plt.scatter(cluster_1['PC1'], cluster_1['PC2'], color = 'red', alpha = 0.7, label = 'Group2')
plt.scatter(cluster_2['PC1'], cluster_2['PC2'], color = 'green', alpha = 0.7, label = 'Group3')
plt.xlabel('PC1')
plt.ylabel('PC2')
plt.legend()
plt.show()
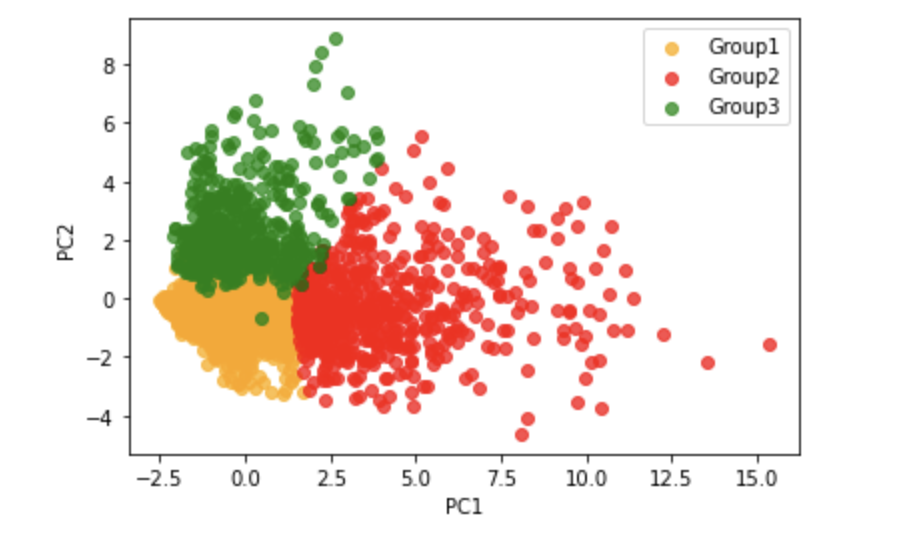
결과 해석
- 각 색상은 서로 다른 고객 그룹을 나타내고,
- 각 그룹은 응집력 있게 모여 있으며,
- 서로 다른 그룹은 명확한 경계를 가지고 분리되어 있는 모습이 관찰된다.
PC1, PC2만으로도 상당한 분산(데이터의 패턴)을 설명할 수 있기에, 고객 그룹이 실제로 의미 있는 구조를 가지고 있다는 것을 보여준다.
🖇 3D 시각화 (PC1, PC2, PC3)
2D로 시각화하는 것도 좋지만, 3차원 공간으로 시각화하면 더 풍부한 정보를 얻을 수 있다.
이번에는 가장 많은 분산을 캡처하는 최상위 3개 주성분 PC1, PC2, PC3를 기준으로 3D 시각화를 진행해 보았다.
시각화 라이브러리 plotly를 설치해야 한다.
!pip install plotly==5.18.0
plotly는 인터랙티브한 시각화 도구로, 복잡한 데이터도 깔끔하게 표현할 수 있게 도와준다.
plotly.graph_objects 를 사용하면 그래프의 구성요소를 세부적으로 지정해주는 방식으로 그래프에 대한 디테일한 커스텀이 가능하다.
import plotly.graph_objects as go
# 색상 지정
colors = ['red', 'blue', 'green']
# 각 클러스터별 데이터 분리
cluster_0 = data_pca[data_pca['cluster'] == 0]
cluster_1 = data_pca[data_pca['cluster'] == 1]
cluster_2 = data_pca[data_pca['cluster'] == 2]
# 3D Scatter Plot 생성
fig = go.Figure()
# 각 클러스터별 데이터 표기
fig.add_trace(go.Scatter3d(x=cluster_0['PC1'], y=cluster_0['PC2'], z=cluster_0['PC3'],
mode='markers', marker=dict(color=colors[0], size=5, opacity=0.4), name='Group 1'))
fig.add_trace(go.Scatter3d(x=cluster_1['PC1'], y=cluster_1['PC2'], z=cluster_1['PC3'],
mode='markers', marker=dict(color=colors[1], size=5, opacity=0.4), name='Group 2'))
fig.add_trace(go.Scatter3d(x=cluster_2['PC1'], y=cluster_2['PC2'], z=cluster_2['PC3'],
mode='markers', marker=dict(color=colors[2], size=5, opacity=0.4), name='Group 3'))
# 범례 및 제목 영역 설정
fig.update_layout(
title=dict(text='3D Visualization of Customer Clusters in PCA Space', x=0.5),
scene=dict(
xaxis=dict(backgroundcolor="grey", gridcolor='white', title='PC1'),
yaxis=dict(backgroundcolor="grey", gridcolor='white', title='PC2'),
zaxis=dict(backgroundcolor="grey", gridcolor='white', title='PC3'),
),
width=900,
height=800
)
fig.show()
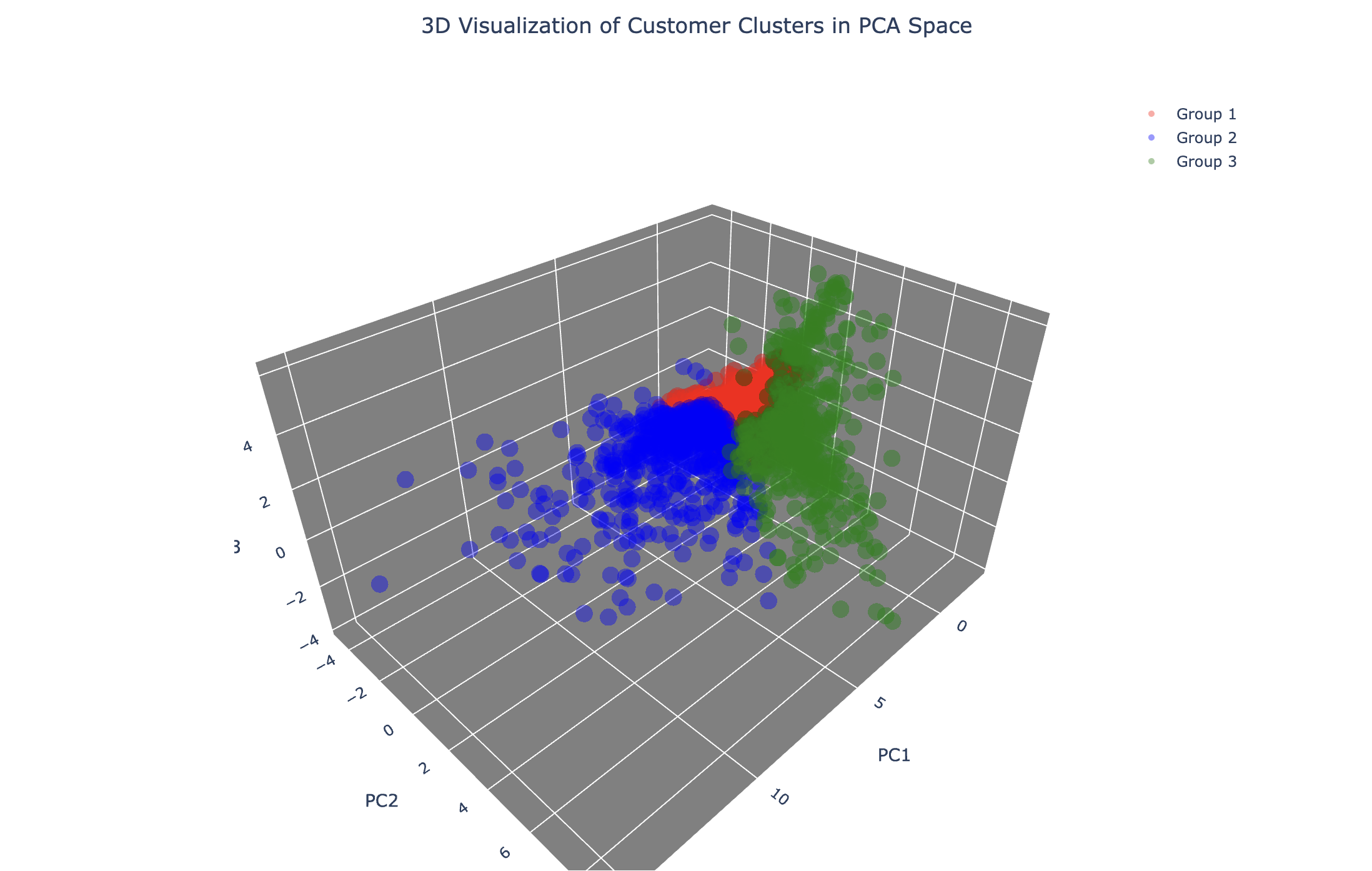
결과 해석
- 각 그룹이 3차원 공간 상에서도 명확히 구분되어 있는 것을 확인할 수 있다.
- 특히 2D에서 겹쳐 보이던 데이터들도 3D에서는 더 선명하게 분리되는 경우가 많다.
- 이는 PCA로 차원을 줄이면서도 데이터의 핵심 구조가 잘 보존되었다는 의미이다.
지금까지 데이터를 기반으로 고객을 그룹화하고, 그 결과가 시각적으로도 타당함을 확인할 수 있었다.
| 항목 | 설명 |
|---|---|
| 시각화 목적 | 클러스터 분리 및 응집 품질 확인 |
| 사용 차원 | 2D (PC1 & PC2), 3D (PC1, PC2, PC3) |
| 시각화 도구 | matplotlib (2D), plotly (3D) |
| 결과 해석 | 각 그룹이 선명하게 구분되며, 군집 품질 양호 |
이제 프로젝트 마무리를 통해 해당 프로젝트의 분석 프로세스를 정리하고 어떤 인사이트를 얻을 수 있었는지 담아 볼 예정이다 😊
[해당 컨텐츠는 아이펠 캠퍼스 LMS에서 학습한 내용을 재해석한 것으로 무단 복제 및 사용을 금지합니다.]
