
📌 사용 환경
Python 3.10.2
conda 24.9.0
JupyterLab 4.2.5
데이터 전처리는 머신러닝에서 60-70%를 차지하는 중요한 부분이고, 좋은 데이터가 들어와야 학습이 잘 된다. Pandas는 그 중 가장 중요한 부분이다.
내용은 쉬운데 구현이 어렵다.
반대로 머신러닝은 내용은 어려운데, 구현은 scikit-learn에서 잘 만들어놨기에 쉽다.
통계와 연계된다.
통계의 자료형은 정말 많은데 우선 숫자, 문자, 날짜(순서형) 이 세가지만 기억하자.
1. Pandas
API 문서 : https://pandas.pydata.org/docs/reference/frame.html
데이터 분석을 위한 효율적인 데이터 구조 제공
Numpy 기반으로 만들어짐
Numpy와 함께 다양한 연계적 기능 제공
Excel(csv, xlsx)과 비슷
Numpy가 배열에 특화됐다면 Pandas는 Series와 DataFrame.
그리고 Numpy를 기반으로 만들어졌기에 Numpy와 함께 다양한 연계적 기능을 제공한다.
따라서 보통 import시 numpy도 함께한다.
Numpy와 비교하자면 Numpy의 형태는 5x5의 표의 형태라면,
Pandas는 컬럼(Column)과 인덱스(Index) 가 있고 그 안에 데이터들이 들어간다.
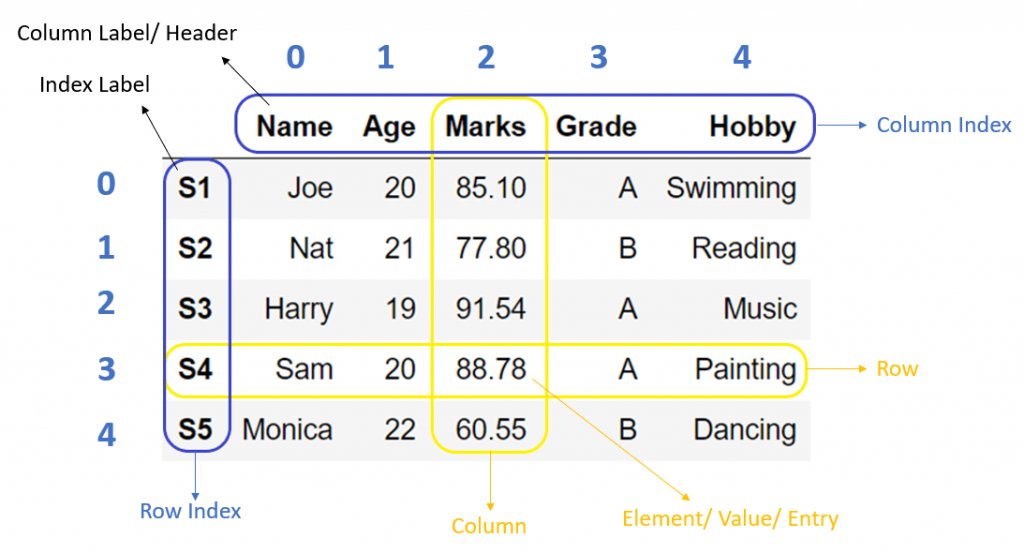
출처: PYnative, Pandas DataFrame
위 사진과 같은 형태이며, 행을 읽어와서(행 단위) 데이터를 예측하게 된다.
또 이 Pandas는 Numpy와 마찬가지로 for문이 없고 대용량의 데이터를 빠르고 쉽게 다룰 수 있으며, 모든 자료형이 다 들어갈 수 있다.
1.1. 자료형
엑셀표를 생각하자.
1차원 배열을 Series, 2차원 배열을 Data Frame이라고 한다.
1.1.1. Series 자료형
1차원 배열
인덱스(index), 값(values)으로 구성
열 기준으로 하나의 데이터 타입만 가짐
numpy 기반으로 만들어진 library로 통계 연산 가능
num=pd.Series([1,2,3,4])
print(num, type(num))
# ✅ 출력 결과
# 0 1
# 1 2
# 2 3
# 3 4
# dtype: int64 <class 'pandas.core.series.Series'>그리고 Series의 시작이 대문자 S인걸 보아 이는 Series라는 클래스임을 알 수 있는데, Series의 내부를 보면
Init signature:
pd.Series(data=None, index=None, dtype: 'Dtype | None' = None, name=None, copy: 'bool | None' = None, fastpath: 'bool' = False,
) -> 'None'이와 같다.
여기서 data=None, index=None 을 보면 이는 키워드 인수로, 이 이름을 지정해주어도 된다.
pd.Series([1,2,3], index=["A","B","C"])
# ✅ 출력 결과
# A 1
# B 2
# C 3
# dtype: int641.1.2. DataFrame 자료형
2차원 배열
인덱스(index), 값(values)과 열(Columns)로 구성
여러개의 Series가 모여서 DataFrame을 구성
열 기준으로 하나의 데이터 타입만 가짐
numpy 기반으로 만들어진 library로 통계 연산 가능
df=pd.DataFrame([[1,2,3],
[4,5,6],
[7,8,9]])
df, type(df)
df2=pd.DataFrame([[1,2,3],
[4,5,6],
[7,8,9]],
index=["i1","i2","i3"],
columns=["c1","c2","c3"])
df2
# ✅ 출력 결과
# ( 0 1 2
# 0 1 2 3
# 1 4 5 6
# 2 7 8 9,
# pandas.core.frame.DataFrame)
# c1 c2 c3
# i1 1 2 3
# i2 4 5 6
# i3 7 8 91.1.3. DataFrame 생성 및 읽기
list, ndarray, dictionary를 DF로 생성
DF를 list, ndarry, dictionary 변환
excel file 읽기, 쓰기
가장 중요한 부분으로 표의 형태의 데이터를 가져온다.
그리고 그 데이터를 DataFrame에 저장 후 ML/DL같은 곳에서는 거의 Numpy로 학습하기 때문에 바꿔줘야 하는 경우가 많다.
# list -> DF
lst=[[1,2,3],
[4,5,6],
[7,8,9]]
pd.DataFrame(lst)
# ndarray -> DF
arr=np.arange(1,10)
new_arr=arr.reshape(3,3)
new_arr
pd.DataFrame(new_arr,
index=["i1","i2","i3"],
columns=["c1","c2","c3"])
# dictionary -> DF
dic={"A":[1,2,3],
"B":[4,5,6],
"C":[7,8,9]}
dic # KEY 값이 Columns명이 된다.
dic_df=pd.DataFrame(dic)
dic_df
# ✅ 출력 결과
# 0 1 2
# 0 1 2 3
# 1 4 5 6
# 2 7 8 9
# array([[1, 2, 3],
# [4, 5, 6],
# [7, 8, 9]])
# c1 c2 c3
# i1 1 2 3
# i2 4 5 6
# i3 7 8 9
# {'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]}
# A B C
# 0 1 4 7
# 1 2 5 8
# 2 3 6 9- DF -> list, ndarry, dictionary 변환
결국은 list나 ndarray를 DataFrame으로 바꾸면 위와 같은 표의 형태로 나오는데,
반대로 저장된 데이터를 list나 ndarry로 바꿀수 있어야 한다.
my_lst=dic_df.values.tolist() # dic_df의 value값을 가지고 와서 list로 변환
my_lst, type(my_lst)
my_np=dic_df.to_numpy()
my_np, type(my_np)
my_dic=dic_df.to_dict()
my_dic, type(my_dic)
# ✅ 출력 결과
# ([[1, 4, 7], [2, 5, 8], [3, 6, 9]], list)
# (array([[1, 4, 7],
# [2, 5, 8],
# [3, 6, 9]], dtype=int64),
# numpy.ndarray)
# ({'A': {0: 1, 1: 2, 2: 3}, 'B': {0: 4, 1: 5, 2: 6}, 'C': {0: 7, 1: 8, 2: 9}}, dict)1.2. DDA(Descriptive Data Analysis, 기술적 데이터 분석)
기술적이라고 해서 테크놀로지가 아닌, 데이터의 구조와 타입 등을 분석하는 것
데이터 불러오기, 구조와 타입 파악
기술적 통계량 확인: 평균, 합계, 최소값 등.
데이터 전처리: 데이터 정제, 결측치 처리, 스케일 등.
X(설명변수), Y(목표변수): 몸무게가 몇키로 나가면 키가 몇이 될 것이라는 이런 예측들. 즉 Y는 분석 결과, X는 결과를 내기위한 설명을 말함.
이제 파일을 읽어와서 통계적인 부분을 함께 살펴볼 예정인데,
먼저 크게 데이터 분석은 총 4개가 있다.
DDA(Descriptive Data Analysis): 기술적
EDA(Exploratory Data Analysis): 시각화 -> Seaborn, Matplotlib
CDA(Confirmatory Data Analysis): 검증
PDA(Predictive Data Analysis): 예측
그 중 먼저 DDA 에 대해 알아보자.
1.2.1. ⭐ 분산과 표준편차
DDA를 들어가지 전에 먼저 분산과 표준편차에 대한 개념을 알아야한다.
머신러닝 끝날때까지 계속 쫓아다니기 때문에 반드시 알아야 한다.
통계에서 연속형(숫자형)에 대해 분석할때 대표값이라는 것을 뽑는다.
대표값 두개를 뽑는데, 평균과 중위(중간)값이 있다.
예를들어 수강생들의 나이 평균을 뽑는데, 교수의 나이가 들어가면 안된다. 이 값을 이상치라고 한다.
또 강남구청 사회초년생인 20대 남성을 뽑아 평균(대표값) 월급을 뽑아냈는데 1억을 받는 사람이 나온다면 이건 평균의 값에 혼동을 준다. 이럴때 중위값을 사용함
이렇게 이상치가 있는 집단에서는 평균을 사용하면 안되며 중앙값을 사용해야 한다.
또는 이상치를 제거해서 평균을 구하던가 해야한다.
좀 더 보자면, 모든 평균을 중심으로 -와 +로 존재할 수 밖에 없다. 그런데 여기서 평균에 많이 모여있다면 분석하기 좋을 것이다.
근데 만약 시험성적 70점이 평균인데, 70점 보다 못보거나 잘본 사람들의 평균을 구해보고 싶다면, 즉 편차의 평균을 구해보고 싶다면 중심으로부터 얼마나 떨어져 있는가 즉 산포도를 구해야한다.
이제 편차의 평균을 구해야 하는데 편차는 -값과 +값이 합쳐져서 합은 많은 경우에 0인데 어떻게 평균을 구할까?
이럴때 편차에 제곱이나 절대값을 취한다.
(절대값은 보통 중위값을 구할 때 많이 사용한다.)
평균을 구하려면 제곱을 하고 나눌 수 있게 만들어서 이를 나누면 이게 편차 제곱 평균이 되며, 이를 분산이라고한다.
그리고 분산은 제곱한 값이기 때문에 값이 뻥튀기 된 상태니까 루트를 씌워준다.
이것을 표준편차라고 한다.
다시 정리하자면, 통계는 숫자와 문자로 나뉘는데, 숫자로 할때는 항상 대표값을 뽑는다. 대표값으로 뽑는 값은 평균과 중위값이다. 이상치가 많을때를 제외하고는 거의 다 평균을 사용한다.
이렇게 평균을 뽑았는데, 키의 평균이 170이다.
그러면 평균보다 작은애들, 큰애들이 있을 거다.
이를 통계 수학에서는 평균에서 떨어져있는 간격을 편차라고 한다.
평균에서 떨어진 수치가, 즉 편차가 키가 160이면 10만큼의 차이가 나는데,
이런 각각 떨어진 편차들을 다 더하다 보니까 -, +가 있다보니까 합이 항상 0이 나온다.
그런데 0을 n명으로 나눌 수 없으니까 편차의 평균을 구할 수 없는거다.
그런데 분명 작은애가 있고 큰애가 있는데 구해야 하는데 못구하니까,
편차에 제곱이나 절대값으로 하여 0이 안나오도록 해준다.
(그런데 보통 제곱으로 한다.)
제곱으로하여 n명으로 나누면 그게 분산이고,
분산에서 값이 뻥튀기 됐으니까 이를 루트를 씌워 주어 나온 값이 표준 편차다.
(반대로 중위값은 제곱을 안하니까 뻥튀기도 없으니까 그냥 나누면 된다.)
그럼 이제 표가 있다면,
c1이라는 열에 대한 평균, 분산, 표준 편차를 구할 수 있다.
그리고 c2라는 열도 따로 할 수 있고, c1와 c2를 묶어서도 가능하고 전체도 가능하다.
이런 개념을 알아야 함수를 쓸때 파라미터도 바꿀 수 있고 그런거다.
1.2.2. 파일 읽기
employee_df=pd.read_csv("./employee_salary.csv") ❗❗ 해당 데이터는 강의 자료로 상세한 내용은 생략합니다.
1.2.3. 데이터 타입
데이터 구조에서 저장되는 데이터를 value라고 하며 이 데이터의 타입을 크게 3개로 나눈다.
- 연속형 (숫자형)
- 범주형 (문자형)
- 순서형 (날짜형)
이 외에도 수치형, 이산형, 명목형 등이 있는데, 위의 3개 반드시 알아두자.
그리고 각 단어 또한 계속해서 사용되기 때문에 외워두자!
파일을 읽어왔으니 이제 구조에 대해 파악을 해야하는데, 먼저 요약 정보를 확인해야한다.
employee_df.ndim # 객체의 차원 확인 -> 2
employee_df.shape # 객체의 사이즈 확인 -> (250, 6)
employee_df.dtypes # 인덱스와 컬럼들을 제외하고 그 안에있는 데이터들의 타입 출력
employee_df.columns # 컬럼명만 출력항상 이렇게 사이즈와 데이터 타입은 무조건 확인해야한다.
즉 전체 순서는 이와 같다.
먼저 객체의 사이즈를 확인하고,
.head()나 .tail()로 실제 저장된 데이터를 확인한 후,
마지막으로 문자인지 숫자인지를 확인해야하니까 .dtypes 까지 찍어준다.
그리고 이런 사이즈, 컬럼명, 데이터 타입을 확인하는 과정들을 합친, 전체 데이터 타입 정보를 요약하는 함수도 존재한다.
employee_df.info()지금 모든 데이터가 다 정확히 들어있는데, null 값이 있다면 250 non-null 부분이 230 non-null 이런식으로 바뀔 것이다.
그러면 이런 곳에서 결측치가 있다고 알게되고, 결측치를 제거하는 과정을 가지는 것이다.
데이터 분석을 할때 포커스는 열에 맞춰야 한다. 열을 봐야 gender에는 F, M이 오겠다는 것을 파악할 수 있듯이, 열 단위의 특성을 파악하는 것이 가장 중요하다.
그런데 이 Column을 파악할때 또 세가지로 나뉜다.
- 단일컬럼 1개
- 다(중)컬럼 2개 이상
- 전체
그리고 이어서 안에 있는 데이터가 연속형(숫자형), 범주형(문자형), 순서형(날짜형) 중 무엇인지에 따라 분석하는 방법도 다 다르고.. 계속 이어져서 따라와야한다.
1.2.4. 기술적 통계량
1.2.4.1. 단일 컬럼 - 연속형
print("평균값:", employee_df["age"].mean())
print("중앙값:", employee_df["age"].median())
# 이상치
print("최소값:", employee_df["age"].min())
print("최대값:", employee_df["age"].max())
# 분산(편차 제곱의 평균)과 표준편차(편차 제곱의 제곱근)
print("분산:", employee_df["age"].var()) # various
print("표준편차:", employee_df["age"].std()) # standard deviation
# ✅ 출력 결과
# 평균값: 39.24
# 중앙값: 39.0
# 최소값: 20
# 최대값: 55
# 분산: 74.88995983935743
# 표준편차: 8.653898534149649이런 것들을 한번에 표시해주는 .describe()함수
employee_df["age"].describe()
# ✅ 출력 결과
# count 250.000000
# mean 39.240000
# std 8.653899
# min 20.000000
# 25% 33.000000
# 50% 39.000000
# 75% 46.000000
# max 55.000000
# Name: age, dtype: float64정수형으로 하고 싶으면 .astype(int)를 붙이고, 소수점 아래 2개까지를 원하면 .round(2)를 붙이는 등의 방식도 가능하다.
IQR
그리고 여기 보면 25% 와 같은 부분이 보이는데 이 부분을 사분범위 IQR(Inter Quantile Range) 이라고 한다.
- 25%(1사분위수, Q1): 전체 데이터에서 순서대로 나열시, 아래 25% - 33세 이하
- 50%(중앙값, 2사분위수, Q2): 전체 데이터에서 50% - 39세 이상
- 75%(3사분위수, Q3): 전체 데이터에서 순서대로 나열시, 아래 75% - 44세 이하
Q1: 평균 - 0.675 표준편차
Q2: 평균(중앙값)
Q3: 평균 + 0.675 표준편차
그리고 단일 컬럼의 연속형에서 볼 수 있는 histogram이라는 그래프가 있다.
이를 이용하여 분포를 확인하자.
sns.histplot(data=employee_df, x="age", kde=True) # kde=True는 줄 그리기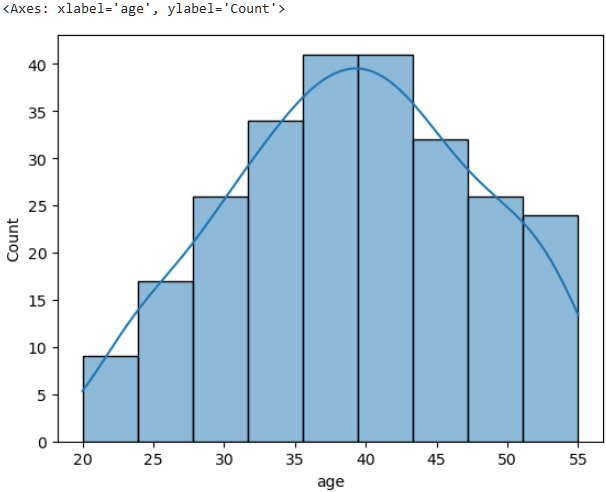
1.2.4.2. 다중 컬럼 및 전체 컬럼 - 연속형
age만 했었는데 이번에는 두개 이상 보고싶다면?
employee_df[["age", "salary"]].mean()
# ✅ cnffur rufrhk
# age 39.24
# salary 6357.48
# dtype: float64그리고 저번 전치행렬을 기억해보면 .T를 붙였으니까 여기서도 보기 불편하면 .T를 붙여보자.
employee_df[["age", "salary"]].describe().T
# 전체 컬럼 (이렇게 연속형(숫자)만 출력)
employee_df.describe()참고로 범주형 describe는
employee_df.describe(include="object")
1.2.4.3. 빈도수 - 범주형
이제 범주형(문자)인데, 이는 오히려 더 쉽다. 문자로 평균을 구하거나 그럴 수 없으니까.
빈도수 밖에 없다.
주민번호는 순서형(날짜)
employee_df["gender"].nunique() # 유니크한 값 개수, 2
employee_df["gender"].unique() # 유니크한 데이터 내용, array(['F', 'M'], dtype=object)
employee_df["gender"].value_counts()
# ✅ 출력 결과
# gender
# M 138
# F 112
# Name: count, dtype: int641.2.4.4. 다중 컬럼 및 전체 컬럼 - 연속형
순서형(날짜형)은 년 월 일을 나눠주는걸 주로 한다.
월단위 매출, 일단위 매출 이렇게 쓸 수 있다.
그런데 여기서는 object형인 문자형으로 되어있는데 이걸 순서형(날짜형)으로 바꿔줘야한다.
그래서 우선 사용할 컬럼인 identifynum을 따로 뽑고 데이터프레임으로 만든다음 object를 datetime64 로 바꿔줘야한다.
employee_df["identifynum"].head(2)
얘는 열을 뽑아왔으니 Series다.
이제 Series를 이용해서 새로운 데이터프레임을 만들자.
date_employee=pd.DataFrame(employee_df["identifynum"])
그리고 이제 이 뽑아온 DF에 identifynum02이라는 새로운 컬럼을 추가하는데. 이 내용은 identifynum의 내용을 가져다가 온 object형을 to_datetime을 사용해 순서형으로 바꿔줄 것이다.
이도, for문을 돌리지 않아도 된다.
date_employee["identifynum02"]=pd.to_datetime(date_employee["identifynum"], format="%y%m%d-%w")
그런데 68년생이 2068년도로 바뀐 것을 알 수 있다.
그러면 현재 년도를 가져오고, 현재 년도 보다 큰 값을 필터링하면 된다.
current_year=pd.Timestamp.now().year
current_year # 2025이제 현재 년도 보다 큰 값을 필터링하고 그 값을 수정해보자.
이는 masking 연산과 같다고 할 수 있다.
즉 for문을 안돌려도 된다.
cond=date_employee["identifynum02"].dt.year > current_year
date_employee.loc[cond, "identifynum02"] -= pd.DateOffset(years=100).loc: location.DateOffset(): pd.DateOffset(기간)
이번에는 년, 월, 일, 요일, 요일명을 뽑아보자.
date_employee["year"]=date_employee["identifynum02"].dt.year
date_employee["month"]=date_employee["identifynum02"].dt.month
date_employee["day"]=date_employee["identifynum02"].dt.day
date_employee["weekday"]=date_employee["identifynum02"].dt.weekday # 0 월요일 ~ 6일요일
date_employee["day_name"]=date_employee["identifynum02"].dt.day_name()이 요일명을 한글로 변경하려면? 영어 요일과 한글 요일의 이름을 매핑해줘야한다.
eng_to_kor={
"Monday": "월요일",
"Tuesday": "화요일",
"Wednesday": "수요일",
"Thursday": "목요일",
"Friday": "금요일",
"Saturday": "토요일",
"Sunday": "일요일",
}
date_employee["kor_day_names"]=date_employee["day_name"].map(eng_to_kor)Python의
.map()함수에 대해 좀더 알아보자면,
.map()함수는,map(함수 이름, 데이터 집합)이와 같이 사용한다.def square1(x): arr=[] for i in x: arr.append(i ** 2) return arr square1([1,2,3,4]) # [1, 4, 9, 16]이런 부분을 lambda함수와 비슷한 map 함수를 사용하면 간단하게 처리할 수 있다.
def square2(x): return x**2 arr2=map(square2, [1,2,3,4]) list(arr2) # [1, 4, 9, 16]def mul1(x, y): return x*y arr3=map(mul1, [1,2,3,4], [4,5,6]) list(arr3) # [4, 10, 18]이와 Python에서 제공하는 map함수도 비슷하다.
파이썬의 기본 map은map(함수명, 데이터 집합)인데,
Pandas의 map함수는date_employee["day_name"].map(eng_to_kor)와 같이
date_employee["day_name"]이eng_to_kor를 호출하여 매칭되는 것들을 변경하는 것이다.
이렇게 map함수를 사용하면for문을 사용하지 않을 수 있다.
1.2.5. 결측치
데이터에 값이 없거나 비어 있는 상태
먼저 중간중간 값이 빠져있는(결측치가 있는) 파일을 불러오고
employee_na=pd.read_csv('./employee_na.csv')어떤 부분에서 빠져있는지 먼저 info()를 통해 확인한다.
employee_na.info()# T/F로 보고싶다면
employee_na.isna()
# 총 몇개가 빠져있는지 알고싶다면
employee_na.isna().sum()name 0
identifynum 0
gender 0
height 0
age 16
blood_type 16
dept 0
grades 0
salary 16
expenditure 0
dtype: int64그렇다면 이를 처리하는 방법으로 두가지가 있는데..
1.2.5.1 결측치 삭제
연속형, 범주형, 순서형 다 삭제
.drop() 함수를 사용하여 결측치를 삭제한다.
그런데 결측치를 삭제할때는 .copy()로 우선 dataframe을 복사해서 가져와야한다.
위와 같이 age, blood_type, salary 부분이 각각 전체중에 여러곳에 빠져있다면,
그냥 drop하게되면 행이 전체 다 삭제되기 때문에 조심해야한다.
drop_employee_na=employee_na.copy()
drop_employee_na.dropna(inplace=True) # inplace: 정말 삭제할 것인지1.2.5.2. 결측치 대체
연속형(숫자): 평균 또는 중앙값으로 대체
범주형(문자): 최빈값으로 대체
나이(연속형)를 평균값으로 대체해보자.
먼저 평균을 구하면,
age_avg=int(replace_employee_na["age"].mean())
age_avg # 39
replace_employee_na["age"]=replace_employee_na["age"].fillna(age_avg)연봉(연속형)은 중앙값으로 대체해보자.
먼저 중앙값을 확인해보자.
salary_median=int(replace_employee_na["salary"].median())
salary_median # 6130
replace_employee_na["salary"]=replace_employee_na["salary"].fillna(salary_median)혈액형은 범주형으로 최빈값으로 대체해주자.
최빈값을 먼저 확인하자.
replace_employee_na["blood_type"].value_counts() # A형 최빈값
# 그리고 인덱스값을 이용해서 변환해야하기 때문에 `.mode()`함수를 사용
replace_employee_na["blood_type"].mode() # Series로 반환해준다.
blood_type=replace_employee_na["blood_type"].mode()[0]
replace_employee_na["blood_type"]=replace_employee_na["blood_type"].fillna(blood_type)1.2.6. 이상치
정상 범위에서 크게 벗어난 값
이상치를 포함하여 분석 결과에서 왜곡이 발생
이상치는 결측치로 만들고 삭제 또는 대체함
for문과 if문을 사용하여 변경할 수도 있지만,
Numpy에서 제공하는 where() 함수를 사용할 수도 있다.
np.where() 함수는 삼항식을 사용하는데, np.where(조건, true, false) 이런 형태다.
아래를 보면 이해가 될 것이다.
result_my_outlier_df["gender"]=np.where(result_my_outlier_df["gender"]==3, np.nan, result_my_outlier_df["gender"]) 이후 결측치와 마찬가지고 삭제 또는 대체를 하면 된다.
result_my_outlier_df.dropna(inplace=True)💪 혼합형 퀴즈
Q1. Series와 DataFrame의 차이점으로 옳은 것은?
1) Series는 1차원, DataFrame은 2차원 데이터 구조다.
2) Series는 2차원, DataFrame은 1차원 데이터 구조다.
3) Series와 DataFrame은 모두 2차원 데이터 구조다.
4) Series와 DataFrame은 모두 1차원 데이터 구조다.
A1. 1
Q2. None 값을 0으로 대체하는 코드를 작성하시오.
df = pd.DataFrame({
"A": [1, 2, None, 4],
"B": [None, 2, 3, 4]
})A2. df.fillna(0)
Q3. Age 컬럼의 평균값을 구하는 코드를 작성하시오.
df = pd.DataFrame({
"name": ["A", "B", "C", "D"],
"age": [19, 20, 21, 22]
})A3. df["age"].mean()
Q4. 결측치가 포함된 행을 삭제하는 코드를 작성하시오.
df = pd.DataFrame({
"name": ["A", "B", "C", "D"],
"age": [19, None, 21, 22]
})A4. df.dropna()
Q5. city와 age 컬럼으로 새로운 DataFrame을 만드는 방법으로 옳은 것은?
df = pd.DataFrame({
"name": ["A", "B", "C", "D"],
"age": [19, 20, 21, 22]
"city": ['Seoul', 'Seongnam', 'Suwon', 'Yongin']
})1) df[["city", "age"]]
2) df.loc["city", "age"]
3) df.select("city", "age")
4) df[["city", "name"]]
A5. 1
Q6. age 컬럼에 이상치가 포함되어 있을 때 이를 처리하는 방법으로 옳은 것은?
df = pd.DataFrame({
"name": ["A", "B", "C", "D"],
"age": [19, 20, 1000, 22]
})1) df["age"]=df["age"].replace(1000, df["age"].mean())
2) df["age"]=df["age"].apply(lambda x: 0 if x > 100 else x)
3) df=df.drop(df[df["age"]>100].index)
4) df["age"]=df["age"].apply(lambda x: 1 if x > 100 else x)
A6. 1
