
📌 사용 환경
Python 3.10.2
conda 24.9.0
JupyterLab 4.2.5
지금까지 해온 BeautifulSoup, Selenium으로 데이터를 수집하는 과정은 가장 중요한 단계로 가기 위한 초석이 된다.
지금부터는 데이터의 전처리부터 데이터의 분석, 그리고 예측까지 진행할 예정인데
그 중 정말 잘 알아두어야 하는 데이터의 전처리부분에 대해 먼저 알아보자.
크게 Numpy와 Pandas로 데이터의 전처리를 진행하는데
Numpy는 크게 어려운 부분은 아니다.
그런데, 판다스의 문법은 정말 너-무도 많아서 정말 중요하다!
우선 Numpy부터 정리하자.
1. Numpy
API 문서: https://numpy.org/doc/2.2/reference/index.html#reference
파이썬에는 배열이 없다. 그래서 Numpy를 사용해서 배열을 쓴다 !
Numpy는 Numerical Python으로, 빠른 배열(array) 연산이 강점이다.
list에서는 for문으로 돌렸던 연산이지만, Numpy를 이용하면 for를 안돌리고도 각 요소에 연산을 할 수 있다.
즉 Numpy는 이런 수치 데이터를 다루는 패키지이며, N차원 배열의 처리를 도와준다.
이때 자료형은 섞이면 안되고 ⭐하나의 동일한 자료형만 사용가능하며
그 때문에 속도가 빠르고 메모리 효율성에서 좋다.
이런 Numpy는 후에 데이터 분석 및 ML(Machin Learning)과 DL(Deep Learning)에서 많이 사용된다.
1.1. ⭐ Dimension
1차원은 행 또는 Vector,
2차원은 행과 열 또는 Matrix,
3차원은 행과 열과 면 또는 channel, Tensor를 말한다.
즉 n차원은 nTensor라고도 한다.
이 각 차원을 이제 배열로 나타낸다면 1 차원 배열, 2차원 배열과 같이
n 차원 배열이 되는 것인데 이를 N Dimension 배열, ndarray라고 한다.
그림으로 보면 다음과 같다.
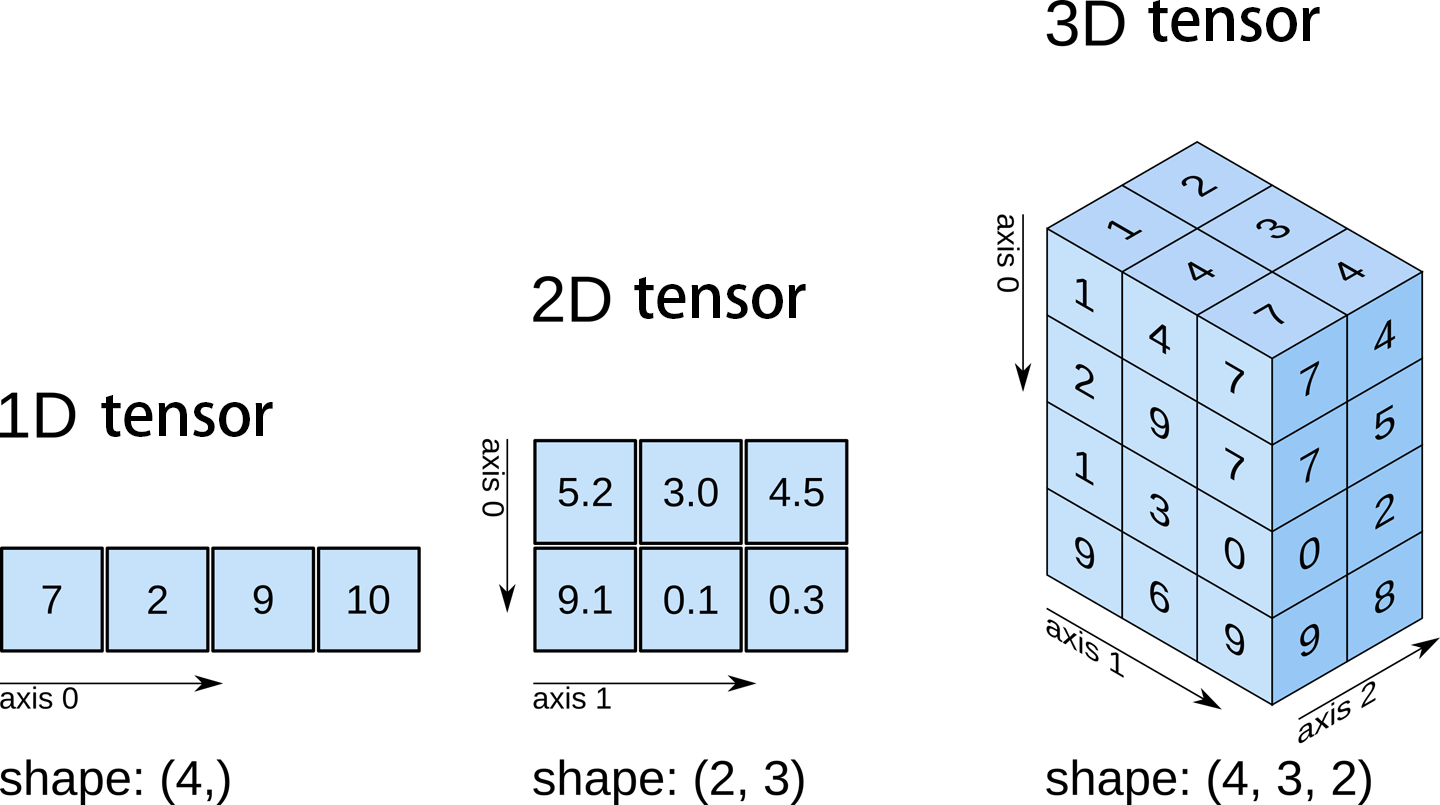
출처: brainpy.readthedocs.io / Tensor
조금 복잡할 수 있는데, 각 행을 axis=0, 열을 axis=1 이라고 한다.
그리고 면에 따라 각각을 또 axis=2 라고 한다.
이 부분을 정말 잘 기억해 두어야 한다!
1.2. Numpy 사용법
우선 import numpy as np 먼저 해주자! (없으면 pip install numpy)
1.2.1. 배열 초기화
리스트로 초기화하는 방법과 함수로 초기화하는 방법이 있다.
List 초기화
단, 동일 자료형을 사용하지 않으면 에러가 발생한다.
my_list=[1,2,3]
my_arr=np.array(my_list)
print("배열:", my_arr) # [1,2,3]
print("배열 인덱스:", my_arr[2]) # 3
# ✅ 출력 결과
# 배열: [1 2 3]
# 배열 인덱스: 3이렇게 접근이 가능하지만, 만약 10만개의 데이터면 다 뽑아내고 인덱스에 각각 접근가능할까?
실제로는 이렇게 print로 볼 일이 없다.
그러면 가장 먼저 데이터의 사이즈를 봐야한다.
사이즈와 차원이 어떤지를 확인하고 그 다음 데이터의 타입을 확인해야한다.
print("배열 크기:", my_arr.size)
print("배열 차원의 크기:", my_arr.shape)
print("배열 차원:", my_arr.ndim)
print("배열 타입:", my_arr.dtype)
# ✅ 출력 결과
# 배열 크기: 3
# 배열 차원의 크기: (3,)
# 배열 차원: 1
# 배열 타입: int32자주 사용하는 함수
num=np.array([1,1,2,3,3,3,1])
print("중복값 제거:", np.unique(num)) # 원본 데이터 영향 안줌
# ✅ 출력 결과
# 중복값 제거: [1 2 3]pandas도 그렇고 numpy도 그렇고 a라는 것을 읽어와서 뭔가를 바꿔주고 할일이 있는데, 만약 100개의 열이 있는데 3개 정도만 작업을 하는 경우가 있다면?
그대로 두고 원본 데이터의 3개를 copy해서 작업한다.
copy_num=num.copy()
print("배열 복사:", copy_num)
# ✅ 출력 결과
# 배열 복사: [1 1 2 3 3 3 1]num.sort()
print("오름 차순:", num) # 원본 데이터에 영향 줌
print("내림 차순:", num[::-1])
# ✅ 출력 결과
# 오름 차순: [1 1 1 2 3 3 3]
# 내림 차순: [3 3 3 2 1 1 1]arr2=np.array([[5,2,3,4,1],
[7,8,10,9,6]])
arr2.sort(axis=1)
print("행기준 정렬:\n", arr2)
# ✅ 출력 결과
# 행기준 정렬:
# [[ 1 2 3 4 5]
# [ 6 7 8 9 10]]⭐ 중요
이를 잘보면, 행기준 정렬인데, 앞서 말한 것과 같이 axis=0이 되어야 하는거 아닌가 할 수 있지만,
예를들어 첫번째 행을 기준으로 정렬한다고 하면, 결국엔 5와 2가 자리가 바뀌는거는 열이 바뀌는 거기 때문에 axis=1을 써야한다.
그러면 열기준 정렬은? 당연히 행끼리 자리가 바뀌기 때문에 axis=0을 사용해야 한다.arr3=np.array([[7,8,3,4,1], [5,2,10,9,6]]) arr3.sort(axis=0) print("열기준 정렬:\n", arr3) # ✅ 출력 결과 # 열기준 정렬: # [[ 5 2 3 4 1] # [ 7 8 10 9 6]]
Numpy 함수를 활용한 초기화
# arange(start, end, step)
# 파이썬의 내장함수 range(start, end, step)와 동일하다.
print("0~3:", np.arange(4))
print("0~10 2씩 증가:", np.arange(1, 10, 2))
# 0으로 초기화 하는 방법
print(np.zeros((4, 4))) # default로 float형. 이를 바꾸고 싶다면 `dtype=int`, `dtype=string`, ...
# print(np.zeros((4, 4), dtype=int))
# 1로 초기화하는 `.ones()` 라는 함수도 존재한다.
print("1로 초기화:\n", np.ones((3, 3)))
# 특정 숫자로 초기화하는 방법은 `.full()`
#`.full((행,열), 특정숫자)` 와 같은 형태
print(np.full((2, 3), 5))
# 대각행렬과 같이 대각선만 1이고, 나머지는 0인 2차원 배열을 만드는 함수인 `.eye()`함수
print(np.eye(5))
# ✅ 출력 결과
# 0~3: [0 1 2 3]
# 0~10 2씩 증가: [1 3 5 7 9]
# [[0. 0. 0. 0.]
# [0. 0. 0. 0.]
# [0. 0. 0. 0.]
# [0. 0. 0. 0.]]
# 1로 초기화:
# [[1. 1. 1.]
# [1. 1. 1.]
# [1. 1. 1.]]
# [[5 5 5]
# [5 5 5]]
# [[1. 0. 0. 0. 0.]
# [0. 1. 0. 0. 0.]
# [0. 0. 1. 0. 0.]
# [0. 0. 0. 1. 0.]
# [0. 0. 0. 0. 1.]]
# [[0.79276112 0.14164195 0.74784328]
# [0.8406162 0.06191038 0.76005842]
# [0.92854097 0.53244981 0.28625783]]랜덤 초기화
-
random이라는 라이브러리를 사용할 수도 있지만, Numpy에서도 제공하며, 실행할 때마다 결과 값이 달라진다.
print(np.random.random((3, 3))) -
랜덤한 int값도 뽑을 수 있다.
print(np.random.randint(0, 10, size=(10,))) # size=(2, 5), [2 6 2 0 8 6 5 7 4 3]
-
또 균일한 값으로 뽑을 수도 있다.
print(np.linspace(0, 10, 5)) # [ 0. 2.5 5. 7.5 10. ] -
또
rand()라는 함수가 있는데random()과 비슷하지만 다른 부분이 있다.
기능적으로 동일하지만,
np.random.rand()는np.random.rand(2, 3)과 같이 차원 수를 직접 인수로 받고,
np.random.random()은np.random.random((2, 3))과 같이 배열 크기를 튜플 형식으로 전달받는다.
1.2.2. Indexing & Slicing
리스트에서는 a[2][0] 과 같이 뽑아오지만 배열에서는 a[2,0] 과 같이 뽑아온다는 점을 잘 기억하자.
인덱싱
a=np.array([1,2,3,4])
print(a[0], a[3], a[-1]) # 1 4 4이렇게 그냥 인덱스를 사용하는 방법 그대로다.
그런데 리스트와 아래와 같은 부분에서 차이가 있다.
# 배열
b=np.array([[1,2,3,4,5],
[6,7,8,9,10]])
print(b[0,4]) # 5
print(b[1,3]) # 9
lst=[[1,2,3,4,5],
[6,7,8,9,10]]
print(lst[0][4]) # 5
print(lst[1][3]) # 9슬라이싱
array=np.array([1,2,3,4,5]) # == np.arange(1,6)
print(array) # [1 2 3 4 5]print(array[3:]) # [4 5]
print(array[1:-1]) # [2 3 4]
print(array[0:3:2]) # [1 3]단 2차원일때부터 차이가 조금 있다.
# 배열
num=np.array([[1,2,3],
[4,5,6],
[7,8,9]])
print(num[0:1, 0:2]) # 0행 / 0,1열
print(num[:, 1:]) # 0,1,2 행 / 1,2 열
# 리스트
lst=[[1,2,3],
[4,5,6],
[7,8,9]]
result = [lst[0][:2]]
print(result)
result = []
for row in lst:
result.append(row[1:])
print(result)
# ✅ 출력 결과
# [[1 2]]
# [[2 3]
# [5 6]
# [8 9]]
# [[1, 2]]
# [[2, 3], [5, 6], [8, 9]]1.2.3. 배열결합 & 배열분할
배열 결합
n=np.array([1,2,3,4])
m=np.array([5,6,7,8])
k=np.concatenate([n,m])
print(k.shape)
print(k)
k=np.concatenate([m,n])
print(k.shape)
print(k)
# ✅ 출력 결과
# (8,)
# [1 2 3 4 5 6 7 8]
# (8,)
# [5 6 7 8 1 2 3 4]2차원 배열 결합
- 행열이 같아야 한다.
# 행 기준 결합
a=np.array([[1,2,3,4],
[5,6,7,8]])
b=np.array([[10,20,30,40],
[50,60,70,80]])
c=np.concatenate([a,b],axis=0) # 행 기준 결합이기 때문에 axis=0
print(c)
# 열 기준 결합
d=np.concatenate([a,b],axis=1) # 열 기준 결합이기 때문에 axis=1
print(d)
# ✅ 출력 결과
# [[ 1 2 3 4]
# [ 5 6 7 8]
# [10 20 30 40]
# [50 60 70 80]]
# [[ 1 2 3 4 10 20 30 40]
# [ 5 6 7 8 50 60 70 80]]배열 분할
arr1=np.arange(1,11)
new1_arr1=np.split(arr1,[3,5])
print(new1_arr1)
new2_arr1=np.split(arr1,[4,6,9])
print(new2_arr1) # 인덱스 번호가 분할지점
# ✅ 출력 결과
# [array([1, 2, 3]), array([4, 5]), array([ 6, 7, 8, 9, 10])]
# [array([1, 2, 3, 4]), array([5, 6]), array([7, 8, 9]), array([10])]2차원 배열 분할
# 행 기준 분할
# np.split(array, [분할지점], axis=0or1)
arr2=np.array([[1,2,3,4,5],
[6,7,8,9,10],
[11,12,13,14,15]])
new1_arr2=np.split(arr2, [2], axis=0)
new1_arr2 # 행 기준 분할이기 때문에 axis=0
# 열 기준 분할
new2_arr2=np.split(arr2, [2], axis=1) # 열 기준 분할이기 때문에 axis=1
new2_arr2
# ✅ 출력 결과
# [array([[ 1, 2, 3, 4, 5],
# [ 6, 7, 8, 9, 10]]),
# array([[11, 12, 13, 14, 15]])]
# [array([[ 1, 2],
# [ 6, 7],
# [11, 12]]),
# array([[ 3, 4, 5],
# [ 8, 9, 10],
# [13, 14, 15]])]1.2.4. ⭐ 배열형태 바꾸기
차원 변환
a=np.arange(1,13) # 1~12
b=a.reshape(2,6) # 2행 6열, 원본 데이터에 영향을 주지는 않는다.
b
# 3차원 변환
d=a.reshape(2,2,3) # 2개로 나누는데, 각각 2행 3열로
d, d.shape # (2, 2, 3) -> 2개로 나누는데, 각각 2행3열 이라는 뜻
# ✅ 출력 결과
# array([[ 1, 2, 3, 4, 5, 6],
# [ 7, 8, 9, 10, 11, 12]])
# (array([[[ 0, 1, 2],
# [ 3, 4, 5]],
#
# [[ 6, 7, 8],
# [ 9, 10, 11]]]),
# (2, 2, 3))자동 재배열
reshape(-1)
-1의 역할을 잘 알아야 한다.
a=np.arange(12)
a
# ✅ 출력 결과
# array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])# 행의 위치에서 -1을 넣으면 행은 알아서 자동 재배열 하고, 열의 수만 지정해주면 된다.
new_a1=a.reshape(-1,1)
new_a1
new_a2=a.reshape(-1,2)
new_a2
# 열의 위치에 -1을 넣으면 열은 자동 재배열하고, 행의 수만 지정해주면 된다.
new2_a1=a.reshape(1,-1)
new2_a1
new2_a2=a.reshape(2,-1)
new2_a2
# ✅ 출력 결과
# array([[ 0],
# [ 1],
# [ 2],
# [ 3],
# [ 4],
# [ 5],
# [ 6],
# [ 7],
# [ 8],
# [ 9],
# [10],
# [11]])
# array([[ 0, 1],
# [ 2, 3],
# [ 4, 5],
# [ 6, 7],
# [ 8, 9],
# [10, 11]])
# array([[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]])
# array([[ 0, 1, 2, 3, 4, 5],
# [ 6, 7, 8, 9, 10, 11]])⭐ 참고
ML과 DL에서 2차원 배열을 1차원 배열로 바꾸는 형태가 많은데,
이럴때reshape()함수를 사용하면 간단하게 해결할 수 있는데,
reshape(-1)이렇게 쓰면 된다.b=np.array([[1,2,3,4,5], [6,7,8,9,10]]) b new_b1=b.reshape(-1) new_b1 # ✅ 출력 결과 # array([[ 1, 2, 3, 4, 5], # [ 6, 7, 8, 9, 10]]) # array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
전치 행렬
- pandas에서 자주 사용하며 행과 열을 바꾼다.
a=np.array([[1,2],
[3,4]])
a
a.T
# ✅ 출력 결과
# array([[1, 2],
# [3, 4]])
# array([[1, 3],
# [2, 4]])1.3. ⭐ Numpy 연산
1.3.1. 사칙연산
배열의 사칙연산이라는 것이 있는데, 굉장히 좋다.
a=[1,2,3]
b=[1,2,3]리스트가 이와 같을때 각각 더하고 싶다면,
원래는 for문을 이용해서 새로운 리스트에 넣어야 한다.
근데 이게 속도가 너무 느리다.
데이터가 10만개, 20만개가 있는데, 언제 for문을 돌릴 수 있을까?
그래서 Numpy는 이걸 함수로 다 만들어 놨다.
이게 Numpy의 가장 강력한 기능이다.
a=np.arange(1,5).reshape(2,2)
a
mul=a*10
mul
b=np.arange(1,5).reshape(2,2)
c=np.arange(5,9).reshape(2,2)
b,c
plus=b+c
plus
d=np.arange(5,9).reshape(2,2)
e=np.arange(1,5).reshape(2,2)
minus=d-e
minus
f=np.arange(5,9).reshape(2,2)
g=np.arange(1,5).reshape(2,2)
div=d/e
div
# ✅ 출력 결과
# array([[1, 2],
# [3, 4]])
# array([[10, 20],
# [30, 40]])
# (array([[1, 2],
# [3, 4]]),
# array([[5, 6],
# [7, 8]]))
# array([[ 6, 8],
# [10, 12]])
# array([[4, 4],
# [4, 4]])
# array([[5. , 3. ],
# [2.33333333, 2. ]])1.3.2. Broadcasting 연산
- 서로 다른 형태(배열의 크기)의 배열의 연산
# 행의 연산
a=np.arange(4).reshape(2,2)
b=np.arange(2)
a, b
a+b
# 열의 연산
c=np.arange(0,16).reshape(4,4)
d=np.arange(10,14).reshape(4,1)
c,d
c*d
# ✅ 출력 결과
# (array([[0, 1],
# [2, 3]]),
# array([0, 1]))
# array([[0, 2],
# [2, 4]])
# (array([[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11],
# [12, 13, 14, 15]]),
# array([[10],
# [11],
# [12],
# [13]]))
# array([[ 0, 10, 20, 30],
# [ 44, 55, 66, 77],
# [ 96, 108, 120, 132],
# [156, 169, 182, 195]])1.3.3. masking 연산
리스트의 for문을 생각하면, 2가지 작업을 많이 했었다.
sum=0
for i in 리스트:
sum += i리스트에 있는 것을 i에 담아서 sum이라는 곳에 더해주는 이런 연산을 많이 했었다.
그리고 Numpy로 그 기능을 for를 사용하지 않고 처리했다.
그리고 for문에서 많이 했던 작업들 중 두번째는?
for i in 리스트:
if i > 10:이런식으로 조건을 줘서 원하는 데이터를 뽑아왔었는데,
Numpy에는 for문안에 if문을 쓸 수 있는 것과 같은 역할을 하는 masking연산이 존재한다.
즉 masking은 배열에서 조건을 걸어주어, 특정 조건을 만족하는 요소만 선택하는 것이다. 이때 논리형인 Boolean 배열로 정의한다.
arr=np.arange(16).reshape(4,4)
arr
# ✅ 출력 결과
# array([[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11],
# [12, 13, 14, 15]])이런 배열에서 10보다 큰 수를 출력하려면
for row in arr:
for num in row:
if num > 10:
print(num, end=" ")
# ✅ 출력 결과
# 11 12 13 14 15기존에 for문을 사용하면 이런식으로 했지만 masking을 사용하면?
m=arr > 10
m
# ✅ 출력 결과
# array([[False, False, False, False],
# [False, False, False, False],
# [False, False, False, True],
# [ True, True, True, True]])이와 같이 조건에 해당하는 마스킹을 생성하여 True, False로 반환한다.
그리고 이 마스킹을 이용하면 다음과 같이 원하는 값만 뽑아낼 수 있다.
m_arr=arr[m]
m_arr
# ✅ 출력 결과
# array([11, 12, 13, 14, 15])1.3.4. 집계함수
a=np.arange(9).reshape(3,3)
a
print("최대값:", np.max(a))
print("최소값:", np.min(a))
print("합:", np.sum(a))
print("평균:", np.mean(a))
# ✅ 출력 결과
# array([[0, 1, 2],
# [3, 4, 5],
# [6, 7, 8]])
# 최대값: 8
# 최소값: 0
# 합: 36
# 평균: 4.0이렇게 Numpy 집계를 사용할 수도 있는데 행과 열을 나누어서도 진행할 수 있다.
만약 합을 구하고 싶을때 각 행의 합, 각 열의 합을 구하는 것인데, 이때도 axis 값에 주목해야 한다.
행의 합은 행끼리의 합이니까 1행1열, 1행2열, 이런 식이기 때문에, axis=1이 되고,
np.sum(a,axis=1)
# 열은 axis=0
np.sum(a,axis=0)
# 열 최소값
np.min(a,axis=1)
# ✅ 출력 결과
# array([ 3, 12, 21])
# array([ 9, 12, 15])
# array([0, 3, 6])1.4. 파일 I/O
- 영화 평점 가져오기 실습
- 사이트 이동 -> older datasets -> MovieLens 1M Dataset 파일 다운로드
이제 총 100만개의 데이터를 처리하는 실습을 해보자.
1.4.1. 파일 가져오기
rating 정보를 가져와서 구조를 보자.
README.txt 파일에서 rating 파일의 설명 부분을 확인하면,

UserID::MovieID::Rating::Timestamp 이와 같은 모습이다.
즉 각각 사용자 id, 영화 id, 평점, 날짜의 데이터를 저장하고 있을 것이다.
path="./data/numpy/ratings.dat"
movie_data=np.genfromtxt(path, delimiter="::", dtype=np.int64) # delimiter: 구분자
movie_data.shape
# ✅ 출력 결과
# (1000209, 4)그런데 데이터의 내용을 어느정도 알기는 해야한다.
하지만 moive_data를 출력해보면? 100만개니까 절대 안된다.
그럴때 쓰는게 slicing. 5행까지의 모든 열(4)을 출력해보자.
movie_data[:5, :]
# ✅ 출력 결과
# array([[ 1, 1193, 5, 978300760],
# [ 1, 661, 3, 978302109],
# [ 1, 914, 3, 978301968],
# [ 1, 3408, 4, 978300275],
# [ 1, 2355, 5, 978824291]], dtype=int64)각 열은 사용자 id, 영화 id, 평점, 날짜 를 나타낸다.
movie_data[-5:, :] # 뒤에 있는 5개의 정보
# ✅ 출력 결과
# array([[ 6040, 1091, 1, 956716541],
# [ 6040, 1094, 5, 956704887],
# [ 6040, 562, 5, 956704746],
# [ 6040, 1096, 4, 956715648],
# [ 6040, 1097, 4, 956715569]], dtype=int64)1.4.2. 전체 평점 평균 계산
그러면 이번에는 전체 평점 평균을 계산해보자.
위를 보면 각각 2열이 평점이다.
np.mean([movie_data[:, 2]]) # 모든 행의 2열
np.mean([movie_data[:, 2]]).round(2)
# ✅ 출력 결과
# 3.581564453029317
# 3.58원래 리스트같은 타입이었다면 for문을 돌렸어야 하는데, 이렇게 numpy의 mean()함수를 사용하니 간단하게 끝난다.
1.4.3. 사용자별 평점 평균
위에 출력결과를 보면 1번 사용자도, 6040번 사용자도 중복된 모습을 볼 수 있다.
사용자별 평점 평균을 구하기 위해서는 먼저 중복 id를 걸러내야 한다.
unique를 사용하자.
user_id=np.unique(movie_data[:, 0])
user_id.shape
user_id[0:10]
user_id[-10:]
# ✅ 출력 결과
# (6040,)
# array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10], dtype=int64)
# array([6031, 6032, 6033, 6034, 6035, 6036, 6037, 6038, 6039, 6040], dtype=int64)이렇게 중복 아이디를 제거하고 유일한 id들이 모인 배열을 만들었다.
이제, 처음 가져온 원본 데이터는 movie_data에 저장되었다. 그리고 movie_data에는 100만개의 데이터가 저장되어있다.
그런데 그 데이터에서 중복 아이디를 제거하고 1~6040번이라는 id값만 따로 뽑아 배열을 만들었으니 이를 이용하는 것이다.
이제 새로 만든 user_id에서 movie_data로 질문을 한다.
만약 id가 1번인 사람이 존재하는지 질문하고,
존재한다면 1번인 사람이 내린 평점의 평균을 반환해서 받아오는 것이다.
원래라면 이런 것을 처리하려면 아래와 같을 것이다.
mean_value=[]
for idx in user_id:
if movie_data[:, 0] == idx:이렇게 if문을 사용해야하는데, 이를 이제 masking을 사용하면 된다.
mean_value=[] # append로 집어넣기 위한 list 선언
for idx in user_id:
data_user=movie_data[movie_data[:,0] == idx] # masking
value=data_user[:, 2].mean() # 배열의 2열(평점)의 평균(mean)
mean_value.append([idx, value]) # unique한 id, 평점의 평균
mean_value[:10]
# ✅ 출력 결과
# [[1, 4.188679245283019],
# [2, 3.7131782945736433],
# [3, 3.9019607843137254],
# [4, 4.190476190476191],
# [5, 3.1464646464646466],
# [6, 3.9014084507042255],
# [7, 4.32258064516129],
# [8, 3.884892086330935],
# [9, 3.7358490566037736],
# [10, 4.114713216957606]]이렇게 10개를 뽑아보면(mean_value[:10]) id가 1번인 사람이 내린 평점의 평균부터 10번인 사람이 내린 평점의 평균까지 출력한다.
1.4.4. 최고 평점
max()라는 내장함수를 사용해도 되는데 np.max() 의 속도가 좀 더 빠르다.
arr_mean_value=np.array(mean_value)
np.max(arr_mean_value[:,1])
# ✅ 출력 결과
# 4.9629629629629631.4.5. 파일 저장하기
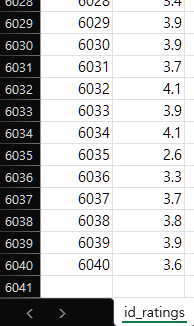
사용자별 평점의 평균을 구한 내용을 다시 엑셀(CSV)로 저장해보자.
fpath="./data/numpy/id_ratings.csv"
np.savetxt(fpath, arr_mean_value, delimiter=",", fmt="%.1f") # fmt: format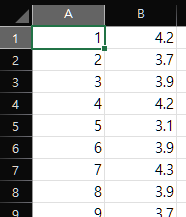
⭐ 정리
즉 배열은 동일한 자료형만 처리할 수 있고, list는 reference여서 객체를 담아주기 때문에 다른 자료형도 처리 가능하다.
파이썬은 배열이라는 것을 만들어 놓지 않았는데, Numpy는 파이썬을 이용해서 배열을 사용가능하게 만들어 준 라이브러리다.
자주 사용하는 함수들을 당연히 까먹으니까 찾아서 쓰자.
막상 정리하고 나니 그렇게 어렵지 않다. 그런데 그래서 쉽게 까먹는다.
그러니 막상 중요할때 쓰지 못하는 경우가 있으니 잘 복습해야한다.
💪 혼합형 퀴즈
Q1. np.concatenate()를 사용하여 배열을 결합할 때, axis=0과 axis=1의 차이는?
1) axis=0은 행 기준 결합, axis=1은 열 기준 결합
2) axis=0은 열 기준 결합, axis=1은 행 기준 결합
3) 동일한 결과
4) axis=0은 2차원 배열만 가능하고, axis=1은 1차원 배열만 가능하다.
A1. 1
Q2. 출력되는 결과는?
arr = np.array([[1, 2], [3, 4], [5, 6]])
print(arr.shape)A2. (3,2)
Q3. 출력되는 결과는?
num = np.array([1, 1, 2, 3, 3, 3, 1])
print(np.unique(num))A3. [1 2 3]
Q4. 출력되는 결과는?
arr2 = np.array([[7, 8, 3, 4, 1],
[5, 2, 10, 9, 6]])
arr2.sort(axis=1)
print(arr2)A4. [[1, 3, 4, 7, 8], [2, 5, 6, 9, 10]]
Q5. np.linspace(0, 10, 5)의 출력 결과는?**
1) [0, 2.5, 5, 7.5, 10]
2) [0, 1, 2, 3, 4]
3) [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
4) [0, 2, 4, 6, 8]
A5. 1
Q6. 출력되는 결과는?
arr3 = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print(np.split(arr3, [2], axis=0))1) 하나의 배열을 두 개로 나누는데, 첫 번째 배열은 2개의 행, 두 번째 배열은 1개의 행.
2) 하나의 배열을 두 개로 나누는데, 첫 번째 배열은 2개의 열, 두 번째 배열은 1개의 열.
3) 두 배열을 하나의 배열로 합친다.
4) 하나의 배열을 두 개로 나누는데, 첫 번째 배열은 1개의 열, 두 번째 배열은 나머지 열.
A6. 1
Q7. 출력되는 결과는?
arr4 = np.zeros((2, 3), dtype=int)
print(arr4)A7. [[0 0 0], [0 0 0]]
Q8. 출력되는 결과는?
arr5 = np.arange(1, 13).reshape(3, 4)
print(arr5)A8. [[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]]
Q9. 출력되는 결과는?
arr = np.array([[10, 20, 30], [40, 50, 60]])
print(arr[1, 0])A9. 40
