
📌 사용 환경
Python 3.10.2
conda 24.9.0
JupyterLab 4.2.5
딥러닝이다.
딥러닝은 머신러닝 알고리즘 중 하나이다.
머신러닝의 알고리즘은 굉장히 많았는데,
인공지능 이라는 것은 머신러닝, 딥러닝 등을 합쳐서 하나의 큰 학문인 것이고,
인공지능 안에 있는 지도학습, 비지도학습이 있는거고, 지도학습의 수많은 알고리즘 중 하나가 딥러닝이다.
그런데 이 딥러닝은 비정형데이터에서 예측이 워낙 좋다보니 많이 뜬 것이다.
일종의 지도학습의 하나의 알고리즘이다.
컴퓨터 프로그램을 많이 안한 사용자의 입장에서 보면 뉴스에서 많이 들었을 것이다.
1차 방정식의 조합이다.
1. 퍼셉트론(Perceptron)
먼저 단층 퍼셉트론(Single-layer Perceptron, SLP)이다.
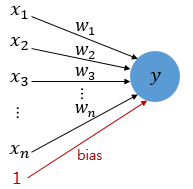
출처: https://wikidocs.net/24958
주로 이진 분류 문제를 해결하는데 사용한다.
그림을 잘 보면, 이는 단층 퍼셉트론(Single-layer Perceptron, SLP)의 경우인데 선형회귀와 비슷한 모습을 볼 수 있다.
X1, X2, ..., Xn 까지 있고 절편(bias)과 W1, W2, ..., Wn의 가중치도 있다.
또한 수식을 보면
이와 같은데, 이는 로지스틱에서 0.5 이상은 1, 이하는 0으로 분류했던 것과 비슷하다.
즉 선형회귀와 로지스틱을 합친 것과 비슷하다.
그런데 이 단층 퍼셉트론에 한계가 존재했다.
- AND GATE
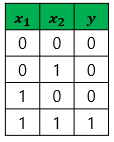
출처: https://wikidocs.net/24958
이는 AND GATE의 경우다.
이를 그래프로 그리면 다음과 같은데,
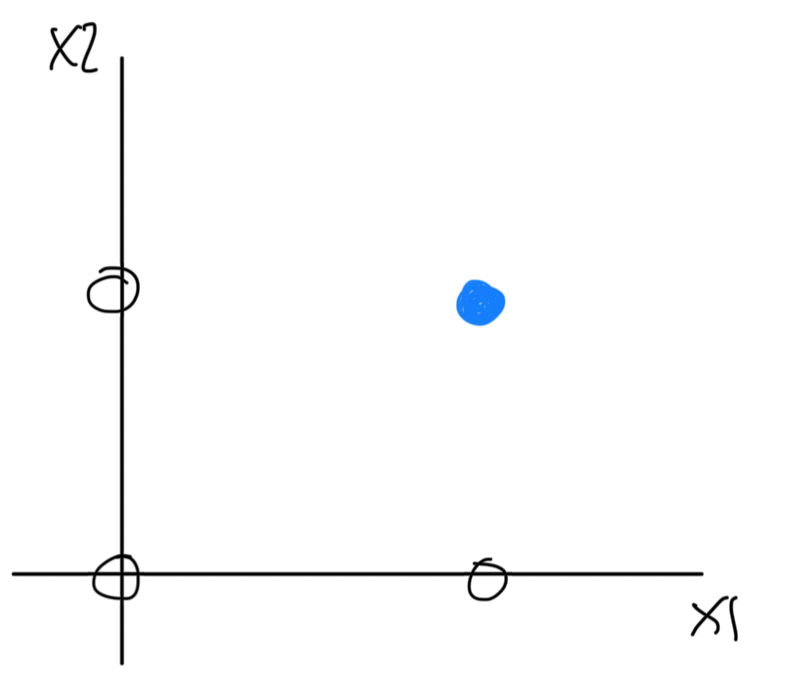
이를 이제 분리한다면 다음과 같다.
- OR GATE
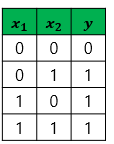
출처: https://wikidocs.net/24958
이를 그래프로 그리고 분리하면,
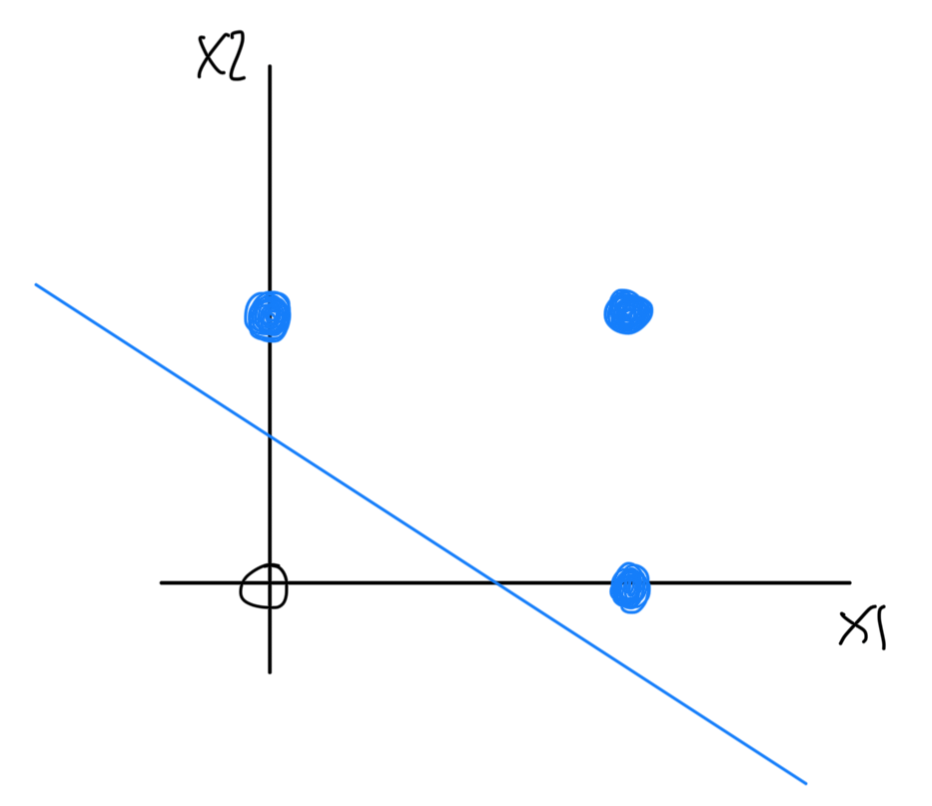
여기까지는 가능했다.
그런데 지금부터 문제다.
- XOR GATE
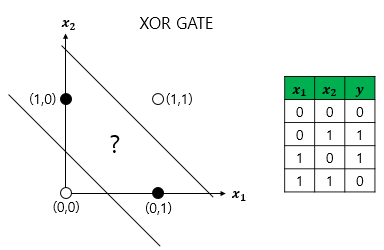
출처: https://wikidocs.net/24958
XOR GATE를 처리할 방법이 없는 것이다.
곡선으로 꺾는 수밖에 없는데, 직선으로 안되기 때문에 문제가 생겼다.
그래서 이를 처리하기 위한 방법으로 Multi layer Perceptron, 즉 다중 퍼셉트론의 축 변환 이라는 것이 사용됐다.
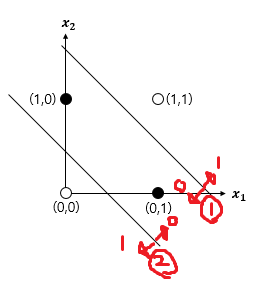
이와 같이 축변환을하여
1번 선의 경우는 위에는 1로, 아래는 0으로 바꾸고,
2번 선의 경우는 위는 0으로, 아래는 1로 바꾼다.
그렇게 되면
(1,1) -> (1,0)
(1,0) -> (0,0)
(0,1) -> (0,0)
(0,0) -> (0,1)
이와 같이 바뀌게 되어 다시 그래프를 그려보면,
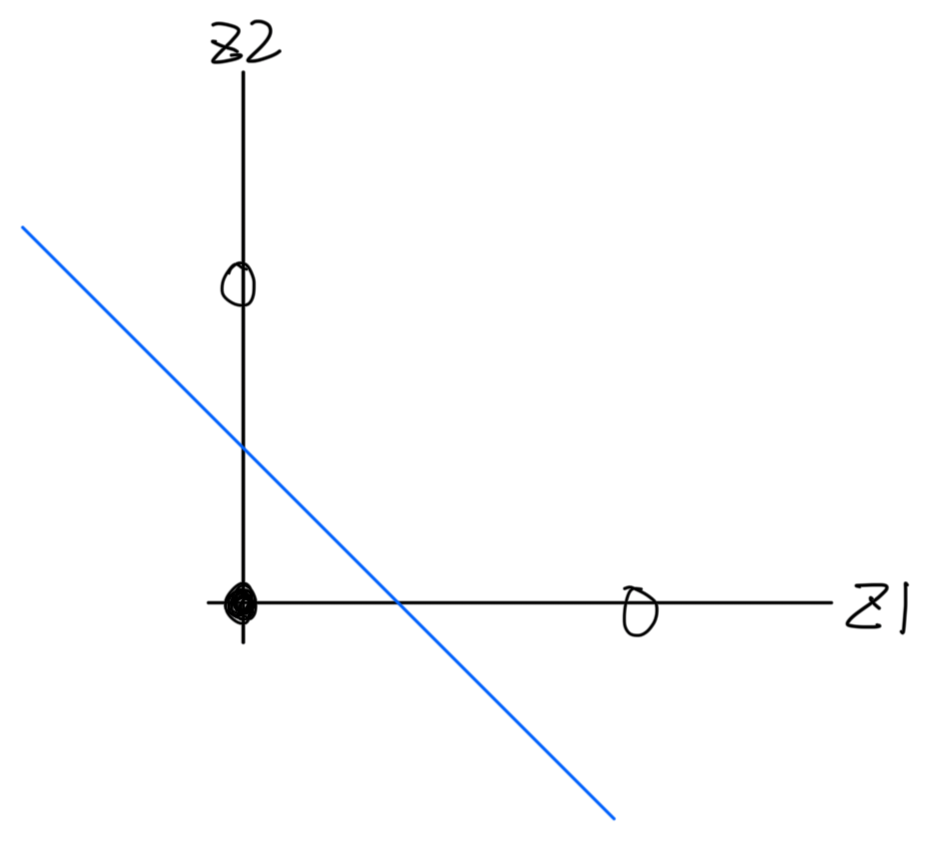
이렇게 바뀌게되었으니 이제 분류가 가능해진다.
이렇게 축을 바꾸면서 최적의 선을 반복해서 찾는다.
그리고 이때 Activation Function이라는 활성화 함수가 또 들어가며 확률로 변환시킨다.
그렇다면 딥러닝은,
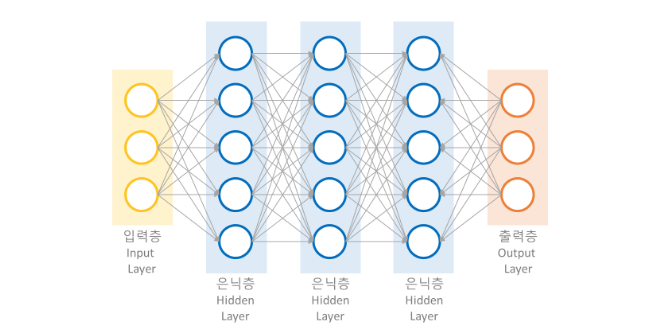
출처: https://velog.io/@posisugar31/딥.한.끝-3.-딥러닝-구조와-모델
은닉층의 각 노드(=유닛, 뉴런) 안에서는 축변환과 확률로 변환이 계속 일어난다.
이렇게 축을 바꿔가면서 최적의 선을 반복해서 찾는것이다.
최적의 선이란? y-가 0에 가깝게하는 것을 말한다.
이 Activation Function(활성화 함수)에는 여러 종류가 있는데,
앞서 설명한 Sigmoid와, TanH, ReLu, Softmax 등이 있다.
Sigmoid와 Softmax는 거의 출력층에서 쓰이고, 주로 TanH와 ReLu 가 쓰인다.
이들 중 ReLu가 가장 많이 사용되며, 수학적인 내용을 모두 다루지는 않겠다.
ReLu 함수만 잠시 보자면,
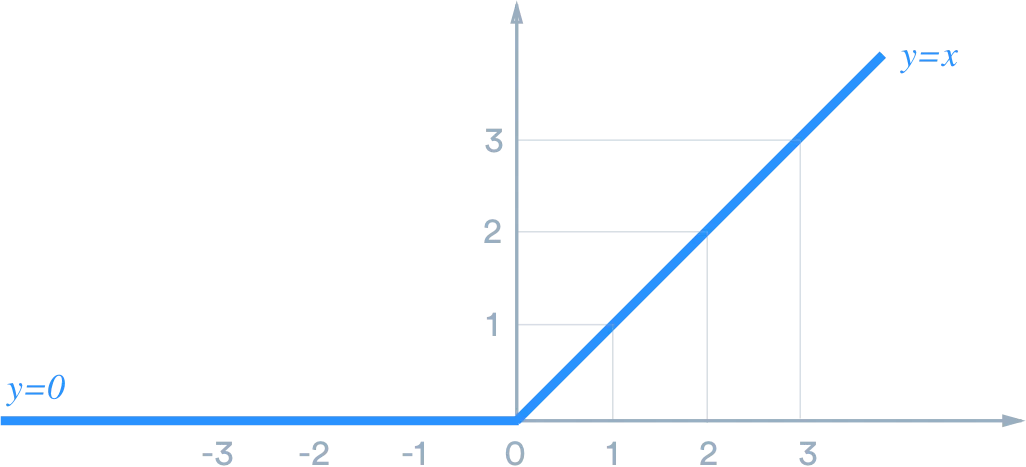
출처: https://wikidocs.net/250622
이와 같이 0또는 0보다 작으면 모두 0으로,
나머지는 모두 자기 값으로 출력하는 함수다.
(TanH는 -1또는 1로)
다른 내용들은 다룰때 추가할 것이고 자세한 내용은 링크를 참고하자.
이제 이 XOR을 코드로 보자.
먼저 필요한 라이브러리들을 import하자.
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rc("font", family="Malgun Gothic")
plt.rcParams["axes.unicode_minus"]=False
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.optimizers import SGD, Adam
from keras.models import load_model
from keras.callbacks import ModelCheckpoint, EarlyStopping
from tensorflow.keras.callbacks import LambdaCallback
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn import metricsKeras API: https://keras.io/getting_started/
1. XOR
단층 퍼셉트론 (Single-layer Perceptron, SLP) : 입력층 + 출력층
다층 퍼셉트론 (Multi-layer Perceptron, MLP) : 입력층 + 은닉층 + 출력층
딥러닝 (Deep Learning) : 여러 은닉층을 가진 딥 신경망(Deep Neural Network) : 입력층 + n개의 은닉층 + 출력층
인공 신경망 (Artificial Neural Network, ANN) : 단층 퍼셉트론, 다층 퍼센트론, 심층 신경망(딥러닝)이 모두 들어가 있는 것
X=np.array([[0,0],
[0,1],
[1,0],
[1,1]])
Y=np.array([[0],
[1],
[1],
[0]])XOR은 서로 다른 조합이 1로 나온다.
1.1. 학습절차
모델 선택 -> 컴파일 -> 학습
- 모델 선택
- 단층(SLP), 다층(MLP), 딥러닝 중 단층은 사용할 일이 없음
- 다층(MLP)모델: 입력층생성 -> 은닉층생성 -> 출력층생성
- 컴파일
- 오차에 관련된 경사하강법 지정 -> 비용함수 처리 -> 정확도 입력
- 학습
- 학습은 동일하게 하는데, 학습 횟수를 지정해야함
그동안은 만약 모델을 불러오려면, model=LinearRegressor()과 같이 그냥 불러와서 사용했다면
지금부터는 만약 다층을 쓰겠다면 이렇게 입력, 은닉, 출력층을 다 만들어줘야한다.
1.1.1. 모델 선택
# MLP모델 생성
model=keras.Sequential()
# 입력층 생성
model.add(keras.layers.Input(shape=(2,))) # X에 2개씩 들어가니까 2개의 입력층이 필요함
# 은닉층 생성
model.add(keras.layers.Dense(10, activation="relu")) # 10개의 노드를 가진 은닉층 생성
# 출력층 생성 (activation을 sigmoid로, 만약 다중분류면 softmax로)
model.add(keras.layers.Dense(1, activation="sigmoid")) # 출력층은 무조건 1개의 노드를 가짐
model.summary()Model: "sequential"┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ dense (Dense) │ (None, 10) │ 30 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_1 (Dense) │ (None, 1) │ 11 │ └─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 41 (164.00 B)
Trainable params: 41 (164.00 B)
Non-trainable params: 0 (0.00 B)
bias들이 각각 들어가야 하므로
입력->은닉: (2x10)+10(bias)=30
은닉->출력: (10x1)+1(bias)=11
총 41개의 파라미터가 들어간 것이다.
1.1.2. 학습 - CASE 1)
컴파일
경사하강법(Gradient Descent) 종류
비용함수, 정확도
이제 이렇게 모델을 층들을 쌓아서 만들어놨으니 이제 fit을 해야하는데,
컴파일이라는 과정이 추가된다.
이 컴파일이라는 과정은 경사하강법이 적용되는데, 이전에 선형회귀에서 오차를 줄이기위해서, cost, 비용함수를 줄이기 위해서 기울기를 조절하고, 얼마만큼 이동할지를 다룬 적이 있다.
그 내용이랑 똑같다.
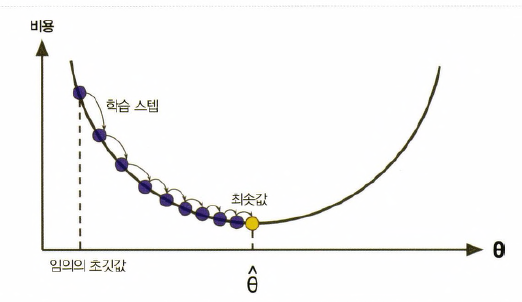
출처: https://velog.io/@jiho_oll2/WIL3.-경사하강법-개념-정리
초기의 회귀선이 그어지고 최솟값에 가깝게 기울기를 어떻게할지, 얼마나 움직일지를 조절해가는 것이다.
이때 학습 스텝으로 얼마만큼 움직일지를 나타내는데, 이를 Learning Rate라고 한다.
이 Learning Rate는 사용자가 정한다.
수학적인 수식이 존재하는데, 미분까지 나오기 때문에 수학적인 부분까지 다루지는 않겠다.
자세한 내용은 링크를 참고하자.
오차를 줄여나가는데 이 경사하강법이 어떻게 적용되는가하면,
순전파(Forward Propagation)와 역전파(Backward Propagation)라는 것이 있다.
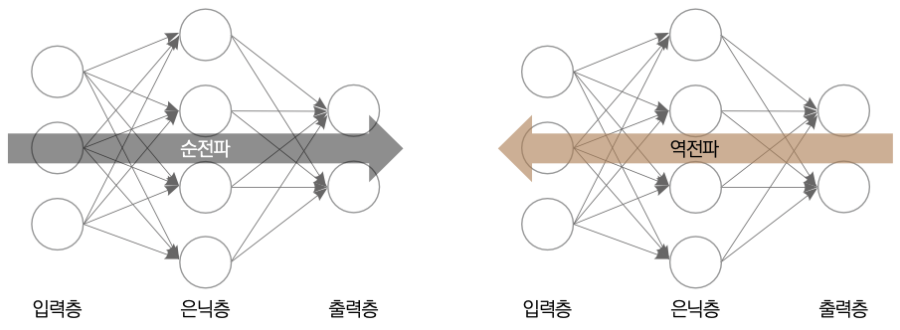
출처: https://goldenrabbit.co.kr/2023/10/27/%EB%8B%A4%EC%8B%9C-%EC%82%B4%ED%8E%B4%EB%B3%B4%EB%8A%94-%EB%94%A5%EB%9F%AC%EB%8B%9D-%EC%A3%BC%EC%9A%94-%EA%B0%9C%EB%85%90-1%ED%8E%B8-%EC%9D%B8%EA%B3%B5-%EC%8B%A0%EA%B2%BD%EB%A7%9D/
이 순전파의 과정으로 w,z,확률값으로 구한 와 y가 의 차이를 구하고 이때 이 비용함수를 줄이기 위해서 경사하강법을 적용하는데,
이 경사하강법을 0.0001로 정했다고 한다면,
0.0001 w z * 확률값 으로 역전파를 진행하는 것이다.
이렇게하면 또 w와 b가 나올 것이고 이를 가지고 또 다시 순전파를 진행하며
오차를 줄여가는 과정이 반복되는 것이다.
이렇게 경사하강법을 적용하는 것이다.
이 경사하강법에는 종류가 굉장히 많은데 많이 사용하는 두가지는
이렇게 말한 가장 기본적인 경사하강법인 확률적 경사하강법(SGD)과
SGD에 추가된 Adam이라는 것이 있다. 이 Adam을 가장 많이 사용한다.
이제 코드로 보자.
model.compile(optimizer="sgd", # learning_rate: default 0.01
loss="binary_crossentropy", # 비용함수: 이진분류 binary_crossentropy, 다중분류 categorical_crossentropy, 회귀 mean_squared_error
metrics=["accuracy"]) # 정확도: 분류 accuracy, 회귀 MSE, MAE, RMSE이제 똑같이 fit으로 학습을 진행하는데 epochs라는 학습 횟수를 지정해준다.
model.fit(X, Y, epochs=10)Epoch 1/10
[1m1/1[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m1s[0m 524ms/step - accuracy: 0.7500 - loss: 0.6991
Epoch 2/10
[1m1/1[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 54ms/step - accuracy: 0.7500 - loss: 0.6989
Epoch 3/10
[1m1/1[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 54ms/step - accuracy: 0.7500 - loss: 0.6987
Epoch 4/10
[1m1/1[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 51ms/step - accuracy: 0.7500 - loss: 0.6985
Epoch 5/10
[1m1/1[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 52ms/step - accuracy: 0.7500 - loss: 0.6983
Epoch 6/10
[1m1/1[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 90ms/step - accuracy: 0.7500 - loss: 0.6981
Epoch 7/10
[1m1/1[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 48ms/step - accuracy: 0.7500 - loss: 0.6978
Epoch 8/10
[1m1/1[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 50ms/step - accuracy: 0.7500 - loss: 0.6976
Epoch 9/10
[1m1/1[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 53ms/step - accuracy: 0.7500 - loss: 0.6974
Epoch 10/10
[1m1/1[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 51ms/step - accuracy: 0.7500 - loss: 0.6972파라미터가 41이었고 epochs=10 으로주면 410번 돌아가는 것이다.
이렇게 비용함수가 반복될수록 줄어간다.
1.1.3. 정확도 및 예측
평가는 간단하다. 가장 낮은 부분이 나온다.
model.evaluate(X, Y)[1m1/1[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 175ms/step - accuracy: 0.7500 - loss: 0.6970
[0.6970407962799072, 0.75]test=np.array([[1,0]])
pred=model.predict(test)
pred[1m1/1[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 71ms/step
array([[0.55707383]], dtype=float32)1.1.4. 학습 - CASE 2)
X=np.array([[0,0],
[0,1],
[1,0],
[1,1]])
Y=np.array([[0],
[1],
[1],
[0]])# MLP모델 생성
model=keras.Sequential()
# 입력층 생성
model.add(keras.layers.Input(shape=(2,))) # X에 2개씩 들어가니까 2개의 입력층이 필요함
# 은닉층 생성
model.add(keras.layers.Dense(10, activation="relu")) # 10개의 노드를 가진 은닉층 생성
# 출력층 생성 (activation을 sigmoid로, 만약 다중분류면 softmax로)
model.add(keras.layers.Dense(1, activation="sigmoid")) # 출력층은 무조건 1개의 노드를 가짐
model.summary()Model: "sequential"┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ dense (Dense) │ (None, 10) │ 30 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_1 (Dense) │ (None, 1) │ 11 │ └─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 41 (164.00 B)
Trainable params: 41 (164.00 B)
Non-trainable params: 0 (0.00 B)이제 다시 컴파일을 진행하는데,
이번에는 learning rate를 변경해서 진행해보자.
# 컴파일(경사하강법 선택, 비용함수선택, 정확도선택)
sgd=SGD(learning_rate=0.05)
model.compile(optimizer=sgd,
loss="binary_crossentropy",
metrics=["accuracy"])학습횟수도 100번으로 지정해보자.
# 학습(X, Y, 학습횟수)
model.fit(X, Y, epochs=100)Epoch 1/100
[1m1/1[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 449ms/step - accuracy: 0.7500 - loss: 0.6521
Epoch 2/100
[1m1/1[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 53ms/step - accuracy: 0.7500 - loss: 0.6486
Epoch 3/100
[1m1/1[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 51ms/step - accuracy: 0.7500 - loss: 0.6448
...
...
...
Epoch 4/100
[1m1/1[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 54ms/step - accuracy: 1.0000 - loss: 0.4859
Epoch 98/100
[1m1/1[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 58ms/step - accuracy: 1.0000 - loss: 0.4843
Epoch 99/100
[1m1/1[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 51ms/step - accuracy: 1.0000 - loss: 0.4828
Epoch 100/100
[1m1/1[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 53ms/step - accuracy: 1.0000 - loss: 0.4817지금도 정신없는데, 이게 만약 1000번이라면?
다 출력할 수 없으니 for문으로 좀 조절해주자.
epochs=100
for epoch in range(epochs):
model.fit(X, Y, verbose=0) # verose=0으로 지정하면 출력을 하지 않겠다는 뜻(1이 디폴트)
if (epoch + 1) % 10 == 0: # 이렇게하여 10의 배수일때만 찍어주도록 (range, 0부터 넘어오니까 +1)
loss, accuracy = model.evaluate(X, Y) # 앞서 배운거처럼 evaluate를 사용하여 출력
print(f"Epoch {epoch + 1}, Loss: {loss:.2f}, Accuracy: {accuracy:.2f}")[1m1/1[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 173ms/step - accuracy: 1.0000 - loss: 0.4657
Epoch 10, Loss: 0.47, Accuracy: 1.00
[1m1/1[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 48ms/step - accuracy: 1.0000 - loss: 0.4520
Epoch 20, Loss: 0.45, Accuracy: 1.00
[1m1/1[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 88ms/step - accuracy: 1.0000 - loss: 0.4382
Epoch 30, Loss: 0.44, Accuracy: 1.00
[1m1/1[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 59ms/step - accuracy: 1.0000 - loss: 0.4243
Epoch 40, Loss: 0.42, Accuracy: 1.00
[1m1/1[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 48ms/step - accuracy: 1.0000 - loss: 0.4116
Epoch 50, Loss: 0.41, Accuracy: 1.00
[1m1/1[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 51ms/step - accuracy: 1.0000 - loss: 0.3982
Epoch 60, Loss: 0.40, Accuracy: 1.00
[1m1/1[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 47ms/step - accuracy: 1.0000 - loss: 0.3855
Epoch 70, Loss: 0.39, Accuracy: 1.00
[1m1/1[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 49ms/step - accuracy: 1.0000 - loss: 0.3733
Epoch 80, Loss: 0.37, Accuracy: 1.00
[1m1/1[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 50ms/step - accuracy: 1.0000 - loss: 0.3610
Epoch 90, Loss: 0.36, Accuracy: 1.00
[1m1/1[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 90ms/step - accuracy: 1.0000 - loss: 0.3487
Epoch 100, Loss: 0.35, Accuracy: 1.002. Fashion MNIST DataSet
딥러닝의 연습용으로 keras에서 제공하는 패션 MNIST가 있다.
(API: https://www.tensorflow.org/tutorials/keras/classification?hl=ko)
60000개의 학습 데이터와 10000개의 테스트 데이터를 제공한다.
Y: 0~9 / 10개로 분류할 수 있는 이미지 분류
X: 28 * 28 흑백 이미지
import가 필요하다.
from keras.models import load_model
2.1. Seed 값 설정
실행할 때마다 같은 결과를 얻기 위해서 seed값을 고정해놓고 가자.
np.random.seed(42) # 데이터 샘플링, 랜덤 분할 등의 난수 고정
tf.random.set_seed(42) # 가중치 초기화, 데이터 증강, 샘플링 등의 난수 고정2.2. 데이터 로드 및 분할
(X_train, Y_train), (X_test, Y_test)=keras.datasets.fashion_mnist.load_data()
print(X_train.shape, Y_train.shape)
print(X_test.shape, Y_test.shape)Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz
[1m29515/29515[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz
[1m26421880/26421880[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m2s[0m 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz
[1m5148/5148[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 1us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz
[1m4422102/4422102[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 0us/step
(60000, 28, 28) (60000,)
(10000, 28, 28) (10000,)fig, ax=plt.subplots(1, 10, figsize=(10,10))
for i in range(10):
ax[i].imshow(X_train[i], cmap="gray_r")
plt.show()
for i in range(10):
print(Y_train[i], end=" ")9 0 0 3 0 2 7 2 5 5 각각 어떻게 구분되는지 알 수 있다.
np.unique(Y_train, return_counts=True) # return_counts=True: 각 개수 반환(array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8),
array([6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000]))
2.3. 전처리
정규화 0~1
1차원 변경(딥러닝에서는 모두 1차원으로 들어감)
먼저 정규화를 진행하는데,
X_train_scaled=X_train/255.0 # 0~255, X_train의 각 값들에 전부 255로 나눔(브로드캐스팅)
X_train_scaled.shape(60000, 28, 28)X_train의 각 값에 255.0을 나눠준다.
이는 브로드캐스팅인데,
넘파이가 255.0을 X_train과 같은 shape으로 확장해서 나눗셈을 수행한 것이다.
X_train_scaled[0]array([[0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. ],
[0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. ],
[0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. ],
[0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0.00392157, 0. , 0. ,
0.05098039, 0.28627451, 0. , 0. , 0.00392157,
0.01568627, 0. , 0. , 0. , 0. ,
0.00392157, 0.00392157, 0. ],
[0. , 0. , 0. , 0. , 0. ,
...
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. ]])이렇게 0~1 사이의 값으로 바꿔줬다.
이제 이 60000개의 학습데이터에 각각 28x28 이미지를 1차원으로 변경해주자.
X_train_scaled=X_train_scaled.reshape(-1, 28*28)
print(X_train_scaled.shape)(60000, 784)테스트 데이터도 똑같이 진행하자.
X_test_scaled=X_test/255.0
print(X_test_scaled.shape)
X_test_scaled=X_test_scaled.reshape(-1, 28*28)
print(X_test_scaled.shape)(10000, 28, 28)
(10000, 784)2.4. 학습 절차
모델 선택 -> 컴파일 -> 학습
2.4.1. 모델 선택
모델 구성:
- 입력층: 784개
- 은닉층
- 출력층: 10개로 분류
model=keras.Sequential()
model.add(keras.layers.Input(shape=(784,)))
model.add(keras.layers.Dense(100, activation="relu"))
model.add(keras.layers.Dense(10, activation="softmax")) # 다중분류
model.summary()Model: "sequential_2"┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ dense_4 (Dense) │ (None, 100) │ 78,500 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_5 (Dense) │ (None, 10) │ 1,010 │ └─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 79,510 (310.59 KB)
Trainable params: 79,510 (310.59 KB)
Non-trainable params: 0 (0.00 B)2.4.2. 컴파일
경사하강법, 비용함수, 정확도
model.compile(optimizer="adam", # learning rate default 0.01
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])이번에는 sgd가 아닌 adam을 사용해보자.
실제로는 adam만 거의 사용한다고 보면 된다.
비용함수에 다중분류는 categorical_crossentropy을 사용한다고 했었다.
그런데 이렇게 categorical_crossentropy를 사용하면, 딥러닝에서는 Y값도 원핫인코딩이 필요하다.
그래서 이 과정을 알아서 해주는 sparse_categorical_crossentropy가 나왔으며,
당연히 그래서 categorical_crossentropy가 아닌 sparse_categorical_crossentropy를 사용한다.
2.4.3. 학습
학습할때, 이후에 시각화하기 위해 우선 history로 담아두자.
history=model.fit(X_train_scaled, Y_train, epochs=5,
validation_split=0.2) # train에 0.2정도를 검증으로 사용 Epoch 1/5
[1m1500/1500[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m5s[0m 3ms/step - accuracy: 0.7565 - loss: 0.7030 - val_accuracy: 0.8430 - val_loss: 0.4448
Epoch 2/5
[1m1500/1500[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m4s[0m 3ms/step - accuracy: 0.8547 - loss: 0.4138 - val_accuracy: 0.8553 - val_loss: 0.4044
Epoch 3/5
[1m1500/1500[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m4s[0m 3ms/step - accuracy: 0.8695 - loss: 0.3666 - val_accuracy: 0.8650 - val_loss: 0.3768
Epoch 4/5
[1m1500/1500[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m4s[0m 3ms/step - accuracy: 0.8790 - loss: 0.3371 - val_accuracy: 0.8691 - val_loss: 0.3636
Epoch 5/5
[1m1500/1500[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m4s[0m 3ms/step - accuracy: 0.8857 - loss: 0.3144 - val_accuracy: 0.8729 - val_loss: 0.35642.4.4. 평가
model.evaluate(X_test_scaled, Y_test)[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m1s[0m 2ms/step - accuracy: 0.8632 - loss: 0.3818
[0.39066991209983826, 0.8621000051498413]정확도가 0.86, loss가 0.39로 굉장히 성능이 좋다.
이제 그래프로 한번 찍어보자.
앞서 history로 담아놨던 걸 가져와서 사용하자.
history.history.keys()dict_keys(['accuracy', 'loss', 'val_accuracy', 'val_loss'])plt.plot(history.history["loss"], label="학습 Loss값")
plt.plot(history.history["val_loss"], label="검증 Loss값")
plt.legend()
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.show()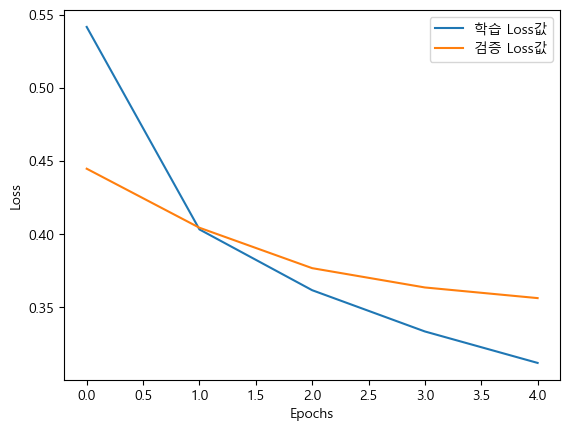
2.4.5. 예측
pred_prob=model.predict(X_test_scaled)
pred_prob[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 1ms/step
array([[2.48644865e-05, 2.49883012e-08, 5.96305370e-07, ...,
2.52483100e-01, 3.27697402e-04, 7.33700573e-01],
[8.02558952e-06, 2.52689469e-09, 9.74803925e-01, ...,
3.70975806e-10, 4.01074103e-05, 1.37534983e-11],
[7.30220791e-06, 9.99991059e-01, 1.66235967e-08, ...,
2.79720947e-19, 1.03485075e-10, 4.21708228e-14],
...,
[1.62651688e-02, 3.09954480e-08, 1.56006520e-03, ...,
3.91904564e-07, 9.71713006e-01, 5.76947059e-07],
[6.77617645e-05, 9.96614158e-01, 2.71759382e-06, ...,
1.19755608e-10, 1.40068630e-06, 6.76903582e-08],
[2.26023156e-04, 1.19215736e-06, 1.77155714e-04, ...,
2.40088813e-02, 8.32274929e-03, 2.42371389e-04]],
shape=(10000, 10), dtype=float32)각 테스트 데이터로 들어가 있는 데이터들의 예측값이 나오는데,
softmax니까 총 10개를 합치면 1이 나오게 됐고,
10개의 열 중에 가장 큰 값으로 분류되기 때문에 가장 큰 값을 열로 가져오자.
np.argmax(): 가장 큰 값을 가진 인덱스 (argument max)
pred=np.argmax(pred_prob, axis=1)
predarray([9, 2, 1, ..., 8, 1, 5], shape=(10000,))pred[0]을 한번 보면,
plt.imshow(X_test_scaled[0].reshape(28,28), cmap="gray_r") # 실제 값 그림
plt.title(f"Label: {pred[0]}") # 예측 값 Label
plt.show()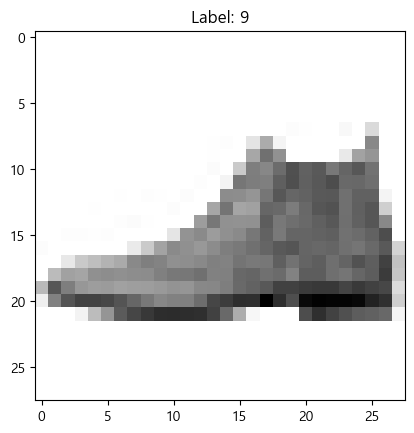
출처: https://keras.io/api/datasets/fashion_mnist/
잘 분류한 것을 볼 수 있다.
정확도를 평가해보면 잘 나온다.
print(metrics.classification_report(Y_test, pred))precision recall f1-score support
0 0.85 0.79 0.82 1000
1 0.99 0.95 0.97 1000
2 0.81 0.73 0.77 1000
3 0.83 0.90 0.86 1000
4 0.77 0.79 0.78 1000
5 0.98 0.93 0.96 1000
6 0.64 0.68 0.66 1000
7 0.86 0.98 0.92 1000
8 0.95 0.97 0.96 1000
9 0.97 0.89 0.93 1000
accuracy 0.86 10000
macro avg 0.87 0.86 0.86 10000
weighted avg 0.87 0.86 0.86 100002.4.6. 모델 저장 및 불러오기
지금은 잘 나왔는데 만약 예측률이 잘 안나온다면, 모델 선택 과정을 바꿔준다.
model=keras.Sequential()
model.add(keras.layers.Input(shape=(784,)))
model.add(keras.layers.Dense(100, activation="relu"))
model.add(keras.layers.Dense(10, activation="softmax"))
model.summary()층을 더 쌓아주거나, 층의 노드 수를 변경하거나 그런 과정을 가진다.
그래서 보통 이런 잘 나온 모델들은 저장해서 나중에 비슷한 문제에 필요할때 불러와서 사용한다.
model.save("./deep_result/fashionMNIST.keras") # 예전버전: .h5model_load=load_model("./deep_result/fashionMNIST.keras")
model_load.summary()Model: "sequential_2"┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ dense_4 (Dense) │ (None, 100) │ 78,500 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_5 (Dense) │ (None, 10) │ 1,010 │ └─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 238,532 (931.77 KB)
Trainable params: 79,510 (310.59 KB)
Non-trainable params: 0 (0.00 B)
Optimizer params: 159,022 (621.18 KB)이렇게 잘 저장됐고 잘 불러왔다.
이런식으로 다른 곳에서 예측이 잘 나온 모델이 있다면 찾아서 불러와서 사용하면 된다.
3. 손글씨 MNIST DataSet
이번에는 keras에서 제공하는 손글씨 MNIST다.
앞선 Fashion MNIST와 비슷하기 때문에 모델을 불러와서 사용하는 과정을 위해 해보자.
60000개의 학습 데이터와 10000개의 테스트 데이터를 제공한다.
Y: 0~9 / 10개로 분류할 수 있는 이미지 분류
X: 28 * 28 흑백 이미지
3.1. 데이터 로드 및 분할
(X_train, Y_train), (X_test, Y_test)=keras.datasets.mnist.load_data()
print(X_train.shape, Y_train.shape)
print(X_test.shape, Y_test.shape)(60000, 28, 28) (60000,)
(10000, 28, 28) (10000,)fig, ax=plt.subplots(1,10,figsize=(10,10))
for i in range(10):
ax[i].imshow(X_train[i], cmap="gray_r")
plt.show()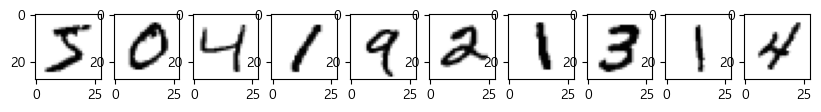
10개 정도만 한번 찍어보자.
for i in range(10):
print(Y_train[i], end=" ")5 0 4 1 9 2 1 3 1 4 각 label에 맞는 이미지들이 나왔다.
이번에는 각 label들과 label들 별로 개수를 확인해보자.
np.unique(Y_train, return_counts=True)(array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8),
array([5923, 6742, 5958, 6131, 5842, 5421, 5918, 6265, 5851, 5949]))
3.2. 전처리
앞서 말했듯이 28x28이고 각각이 0~255의 숫자가 들어있기 때문에 0~1 사이로 바꾸려면 브로드캐스팅을 이용해서 255를 나눠주자.
X_train_scaled=X_train/255.0
print(X_train_scaled.shape)
X_train_scaled=X_train_scaled.reshape(-1,28*28)
print(X_train_scaled.shape)
X_test_scaled=X_test/255.0
print(X_test_scaled.shape)
X_test_scaled=X_test_scaled.reshape(-1,28*28)
print(X_test_scaled.shape)(60000, 28, 28)
(60000, 784)
(10000, 28, 28)
(10000, 784)3.3. 학습 절차
모델 불러오기 -> 컴파일 -> 학습
3.3.1. 모델 불러오기
원래라면,
model=keras.Sequential()
model.add(keras.layers.Input(shape=(784,)))
model.add(keras.layers.Dense(100, activation="relu"))
model.add(keras.layers.Dense(10, activation="softmax"))
model.summary()이렇게 사용하면 되고, 만들어놓은 모델을 사용해보자.
model=load_model("./deep_result/fashionMNIST.keras")
model.summary()Model: "sequential_2"┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ dense_4 (Dense) │ (None, 100) │ 78,500 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_5 (Dense) │ (None, 10) │ 1,010 │ └─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 238,532 (931.77 KB)
Trainable params: 79,510 (310.59 KB)
Non-trainable params: 0 (0.00 B)
Optimizer params: 159,022 (621.18 KB)3.3.2. 컴파일
경사하강법, 비용함수, 정확도
model.compile(optimizer="adam",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])3.3.3. 학습
X, Y, 학습횟수, 검증데이터분할
history=model.fit(X_train_scaled, Y_train, epochs=5, validation_split=0.2)Epoch 1/5
[1m1500/1500[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m5s[0m 3ms/step - accuracy: 0.7984 - loss: 0.7242 - val_accuracy: 0.9488 - val_loss: 0.1746
Epoch 2/5
[1m1500/1500[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m4s[0m 3ms/step - accuracy: 0.9518 - loss: 0.1567 - val_accuracy: 0.9600 - val_loss: 0.1344
Epoch 3/5
[1m1500/1500[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m4s[0m 3ms/step - accuracy: 0.9676 - loss: 0.1058 - val_accuracy: 0.9647 - val_loss: 0.1192
Epoch 4/5
[1m1500/1500[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m5s[0m 3ms/step - accuracy: 0.9763 - loss: 0.0780 - val_accuracy: 0.9663 - val_loss: 0.1127
Epoch 5/5
[1m1500/1500[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m6s[0m 4ms/step - accuracy: 0.9834 - loss: 0.0597 - val_accuracy: 0.9691 - val_loss: 0.10753.3.4. 평가
model.evaluate(X_test_scaled, Y_test)[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m1s[0m 2ms/step - accuracy: 0.9649 - loss: 0.1182
[0.10202490538358688, 0.9692999720573425]0.96에 0.1로 매우 잘 나왔다.
그래프를 찍어보면,
plt.plot(history.history["loss"], label="학습 Loss값")
plt.plot(history.history["val_loss"], label="검증 Loss값")
plt.legend()
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.show()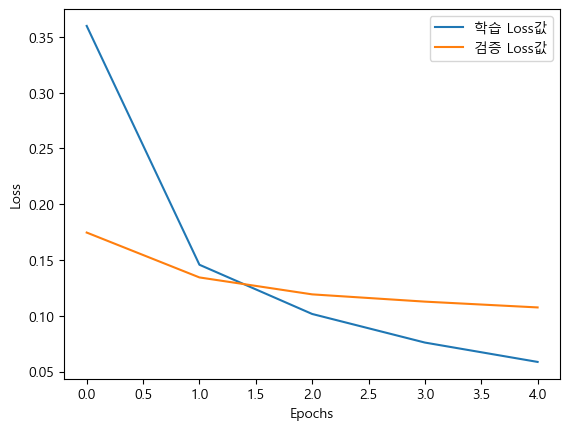
3.3.5. 예측
pred_prob=model.predict(X_test_scaled)
pred_prob[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m1s[0m 2ms/step
array([[1.4846482e-07, 3.8376363e-10, 4.6422679e-07, ..., 9.9990058e-01,
2.6773333e-07, 2.7291619e-06],
[4.1820564e-07, 6.4676111e-05, 9.9970019e-01, ..., 1.1283043e-11,
1.9457155e-04, 2.7364844e-14],
[5.0737044e-06, 9.9728024e-01, 3.2433058e-04, ..., 1.6258584e-03,
2.8603783e-04, 2.4376773e-04],
...,
[1.3636978e-09, 5.4629556e-10, 9.5990528e-11, ..., 2.4138546e-05,
1.3481258e-04, 6.1210027e-05],
[3.9554269e-08, 8.2292290e-10, 1.6447184e-11, ..., 4.6618918e-09,
5.1863179e-05, 9.1806496e-10],
[9.3577580e-07, 3.8228959e-10, 1.4549950e-07, ..., 1.1215546e-08,
8.7184858e-08, 1.2599362e-10]], shape=(10000, 10), dtype=float32)pred=np.argmax(pred_prob, axis=1)
predarray([7, 2, 1, ..., 4, 5, 6], shape=(10000,))pred[0]을 그래프로 그려보자.
plt.imshow(X_test_scaled[0].reshape(28,-1), cmap="gray_r")
plt.title(f"Label: {pred[0]}")
plt.show()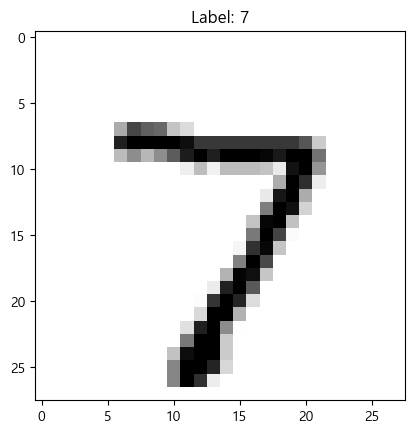
잘 분류했다.
평가지표도 보자.
print(metrics.classification_report(Y_test, pred))precision recall f1-score support
0 0.96 0.99 0.97 980
1 0.99 0.99 0.99 1135
2 0.98 0.96 0.97 1032
3 0.97 0.97 0.97 1010
4 0.98 0.96 0.97 982
5 0.96 0.97 0.96 892
6 0.97 0.97 0.97 958
7 0.96 0.98 0.97 1028
8 0.96 0.96 0.96 974
9 0.98 0.95 0.96 1009
accuracy 0.97 10000
macro avg 0.97 0.97 0.97 10000
weighted avg 0.97 0.97 0.97 10000