
📌 사용 환경
Python 3.10.2
conda 24.9.0
JupyterLab 4.2.5
딥러닝은 비정형 데이터를 학습하는데 최적화된 모델이라고 했는데,
정형데이터도 가능하다.
이미지는 다 배열로 읽기때문에 pandas의 정형데이터를 다루는 선형과 같은 모델로 사용할 수 없었지만,
딥러닝으로 이런 정형데이터를 다뤄보겠다.
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rc("font", family="Malgun Gothic")
plt.rcParams["axes.unicode_minus"]=False
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.optimizers import SGD, Adam
from keras.models import load_model
from keras.callbacks import ModelCheckpoint, EarlyStopping
from tensorflow.keras.callbacks import LambdaCallback
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn import metrics1. 보스턴 집값 예측
다중 선형 회귀에서 예측이 더 좋다.
그래도 딥러닝에서도 가능하다는 것을 보이기 위해서 해보자.
Batch라는 것이 있다.
Epoch는 전체 학습을 이야기하는데, 데이터 세트가 너무 많으면 전체를 다 돌리기에는 무리가 있다.
데이터셋이 2000개일때 epoch는 전체 데이셋을 한번에 돌리는 것이고,
Batch는 2000개를 한번에 돌리는게 아니라, 나누어서 예를들어 200개씩 10번 돌리는 것이다.
이는 epochs와 다른게 아닌, 학습시킬때
model.fit(X, Y, epochs=200, validation_split=0.2, batch_size=50)
이렇게 같이 지정해준다.
이번에도 랜덤 시드를 정해주고 시작하자.
np.random.seed(42)
tf.random.set_seed(42)house=pd.read_csv("./data/boston.csv")
house| CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | B | LSTAT | MEDV | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00632 | 18.0 | 2.31 | 0.0 | 0.538 | 6.575 | 65.2 | 4.0900 | 1.0 | 296.0 | 15.3 | 396.90 | 4.98 | 24.0 |
| 1 | 0.02731 | 0.0 | 7.07 | 0.0 | 0.469 | 6.421 | 78.9 | 4.9671 | 2.0 | 242.0 | 17.8 | 396.90 | 9.14 | 21.6 |
| 2 | 0.02729 | 0.0 | 7.07 | 0.0 | 0.469 | 7.185 | 61.1 | 4.9671 | 2.0 | 242.0 | 17.8 | 392.83 | 4.03 | 34.7 |
| 3 | 0.03237 | 0.0 | 2.18 | 0.0 | 0.458 | 6.998 | 45.8 | 6.0622 | 3.0 | 222.0 | 18.7 | 394.63 | 2.94 | 33.4 |
| 4 | 0.06905 | 0.0 | 2.18 | 0.0 | 0.458 | 7.147 | 54.2 | 6.0622 | 3.0 | 222.0 | 18.7 | 396.90 | 5.33 | 36.2 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 501 | 0.06263 | 0.0 | 11.93 | 0.0 | 0.573 | 6.593 | 69.1 | 2.4786 | 1.0 | 273.0 | 21.0 | 391.99 | 9.67 | 22.4 |
| 502 | 0.04527 | 0.0 | 11.93 | 0.0 | 0.573 | 6.120 | 76.7 | 2.2875 | 1.0 | 273.0 | 21.0 | 396.90 | 9.08 | 20.6 |
| 503 | 0.06076 | 0.0 | 11.93 | 0.0 | 0.573 | 6.976 | 91.0 | 2.1675 | 1.0 | 273.0 | 21.0 | 396.90 | 5.64 | 23.9 |
| 504 | 0.10959 | 0.0 | 11.93 | 0.0 | 0.573 | 6.794 | 89.3 | 2.3889 | 1.0 | 273.0 | 21.0 | 393.45 | 6.48 | 22.0 |
| 505 | 0.04741 | 0.0 | 11.93 | 0.0 | 0.573 | 6.030 | 80.8 | 2.5050 | 1.0 | 273.0 | 21.0 | 396.90 | 7.88 | 11.9 |
506 rows × 14 columns
house.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 506 entries, 0 to 505
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 CRIM 506 non-null float64
1 ZN 506 non-null float64
2 INDUS 506 non-null float64
3 CHAS 506 non-null float64
4 NOX 506 non-null float64
5 RM 506 non-null float64
6 AGE 506 non-null float64
7 DIS 506 non-null float64
8 RAD 506 non-null float64
9 TAX 506 non-null float64
10 PTRATIO 506 non-null float64
11 B 506 non-null float64
12 LSTAT 506 non-null float64
13 MEDV 506 non-null float64
dtypes: float64(14)
memory usage: 55.5 KB1.1. 데이터 분할 및 전처리
X=house.drop("MEDV", axis=1)
Y=house["MEDV"]
X.shape, Y.shape((506, 13), (506,))X_train, X_test, Y_train, Y_test=train_test_split(X, Y, test_size=0.2)
X_train.shape, X_test.shape, Y_train.shape, Y_test.shape((404, 13), (102, 13), (404,), (102,))스케일을 맞추는데, 딥러닝에서는 MinMax가 예측율이 좋기 때문에 MinMaxScaler를 사용한다.
scaelr=MinMaxScaler()
X_train=scaelr.fit_transform(X_train)
X_test=scaelr.transform(X_test)딥러닝 모델 구성할때, 입력층에 열값이 들어가야하는데, shape를 확인하고 13을 넣어줘도 되지만,
print(X_train.shape)
print(X_train.shape[1])(404, 13)
13이렇게도 뽑을 수 있기 때문에 이를 사용해도 된다.
1.2. 모델 구성
입력층 13, 은닉층, 출력층 1
model=keras.Sequential()
model.add(keras.layers.Input(shape=(X_train.shape[1],)))
model.add(keras.layers.Dense(64, activation="relu"))
model.add(keras.layers.Dense(32, activation="relu"))
model.add(keras.layers.Dense(1))
model.summary()Model: "sequential"┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ dense (Dense) │ (None, 64) │ 896 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_1 (Dense) │ (None, 32) │ 2,080 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_2 (Dense) │ (None, 1) │ 33 │ └─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 3,009 (11.75 KB)
Trainable params: 3,009 (11.75 KB)
Non-trainable params: 0 (0.00 B)은닉층이 두개이며, 이번에는 회귀모델이기 때문에 활성화 함수를 사용하지 않는다.
1.3. 컴파일
경사하강법, 비용함수, 정확도
model.compile(optimizer="adam",
loss="mean_squared_error",
metrics=["mse"])회귀이기 때문에 loss와 metrics도 바뀐다.
1.4. 학습
history=model.fit(X_train, Y_train, epochs=200, validation_split=0.2, batch_size=50)Epoch 1/200
7/7 ━━━━━━━━━━━━━━━━━━━━ 1s 42ms/step - loss: 604.0343 - mse: 604.0343 - val_loss: 546.7675 - val_mse: 546.7675
Epoch 2/200
7/7 ━━━━━━━━━━━━━━━━━━━━ 0s 15ms/step - loss: 590.3466 - mse: 590.3466 - val_loss: 532.8712 - val_mse: 532.8712
Epoch 3/200
7/7 ━━━━━━━━━━━━━━━━━━━━ 0s 14ms/step - loss: 575.2795 - mse: 575.2795 - val_loss: 516.2228 - val_mse: 516.2228
Epoch 4/200
7/7 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - loss: 556.9360 - mse: 556.9360 - val_loss: 495.5573 - val_mse: 495.5573
Epoch 5/200
7/7 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - loss: 534.3395 - mse: 534.3395 - val_loss: 469.8658 - val_mse: 469.8658
Epoch 6/200
7/7 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - loss: 506.4365 - mse: 506.4365 - val_loss: 438.2219 - val_mse: 438.2219
Epoch 7/200
7/7 ━━━━━━━━━━━━━━━━━━━━ 0s 30ms/step - loss: 472.1773 - mse: 472.1773 - val_loss: 399.6772 - val_mse: 399.6772
Epoch 8/200
7/7 ━━━━━━━━━━━━━━━━━━━━ 0s 18ms/step - loss: 430.5843 - mse: 430.5843 - val_loss: 353.7838 - val_mse: 353.7838
Epoch 9/200
7/7 ━━━━━━━━━━━━━━━━━━━━ 0s 18ms/step - loss: 381.0833 - mse: 381.0833 - val_loss: 300.3723 - val_mse: 300.3723
Epoch 10/200
7/7 ━━━━━━━━━━━━━━━━━━━━ 0s 15ms/step - loss: 324.5457 - mse: 324.5457 - val_loss: 243.0328 - val_mse: 243.0328
Epoch 11/200
7/7 ━━━━━━━━━━━━━━━━━━━━ 0s 14ms/step - loss: 265.2050 - mse: 265.2050 - val_loss: 188.3138 - val_mse: 188.3138
Epoch 12/200
7/7 ━━━━━━━━━━━━━━━━━━━━ 0s 13ms/step - loss: 209.6273 - mse: 209.6273 - val_loss: 142.9429 - val_mse: 142.9429
Epoch 13/200
...
Epoch 199/200
7/7 ━━━━━━━━━━━━━━━━━━━━ 0s 14ms/step - loss: 16.5990 - mse: 16.5990 - val_loss: 18.0234 - val_mse: 18.0234
Epoch 200/200
7/7 ━━━━━━━━━━━━━━━━━━━━ 0s 15ms/step - loss: 16.5620 - mse: 16.5620 - val_loss: 17.9935 - val_mse: 17.99351.5. 평가지표
pred=model.predict(X_test)
metrics.r2_score(Y_test, pred)[1m4/4[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 18ms/step
0.7814538880843104from sklearn.metrics import r2_score, mean_squared_error, root_mean_squared_error, mean_absolute_error
mae=metrics.mean_absolute_error(Y_test, pred)
mse=metrics.mean_squared_error(Y_test, pred)
rmse=metrics.root_mean_squared_error(Y_test, pred)
mae, mse, rmse(2.6605958008298685, 17.984404454784467, 4.2408023362076745)이제 앞서 history에 담아놨기 때문에 이를 사용하여 그래프를 그려보자.
plt.plot(history.history["loss"], label="학습 loss값")
plt.plot(history.history["val_loss"], label="검증 loss값")
plt.legend()
plt.xlabel("epoch")
plt.ylabel("loss")
plt.show()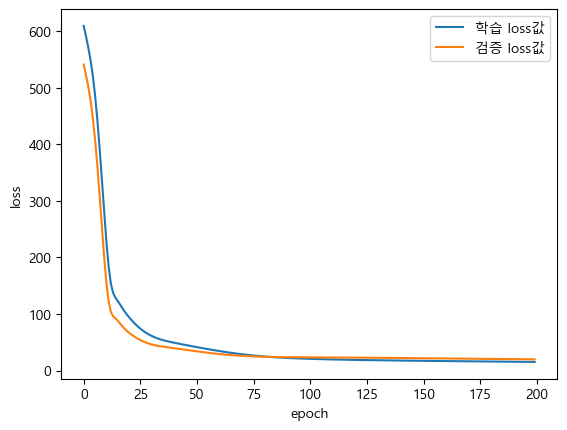
📌 참고로 Dense층 유닛수와 batch_size를 정할때는 보통..
16~32: 간단한 문제, 빠른 계산, 학습, 과적합 위험성 낮음, 복잡한 캐치 못함
64~128: 중간~복잡한 문제, 가장 보편적으로 사용, 약간 느림
256~: 매우 복잡한 패턴, 딥한 정보 추출, 느리고 과적합 위험성
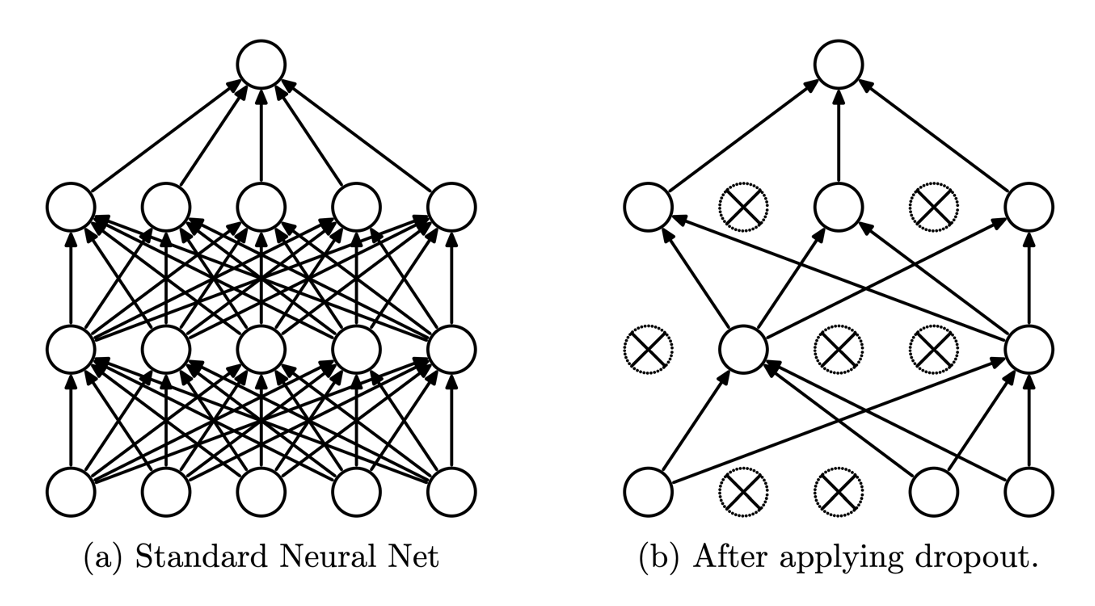
📌 Dropout
Dropout이라는 것이 있다.
이는 과적합을 방지하기 위해 사용하는 것인데, 따로 여기서 보이지는 않고 필요할 때 사용할 예정이다.
개념을 설명하자면 다음과 같다.
출처: https://kh-kim.github.io/nlp_with_deep_learning_blog/docs/1-14-regularizations/04-dropout/
이와 같이 하는 것인데, 트리의 max_depth를 짤라주는 것처럼 중간에 무작위로 삭제하는 것이다.
코드로 보면,
model=keras.Sequential()
model.add(keras.layer.Input(shape=(33,)))
model.add(keras.layer.Dense(30, activation="relu"))
model.add(keras.layer.Dropout(0.3)) # 30% 삭제
model.add(keras.layer.Dense(6, activation="relu"))
model.add(keras.layer.Dense(1))이런식으로 넘어가는 중간에 넣어주는 것이다.
단! 시계열에서는 사용하면 안된다.
2. 와인 분류 예측
변수들에 대한 설명 및 import 관련: https://archive.ics.uci.edu/dataset/109/wine
이렇게 회귀문제에 대해 다뤄봤는데, 사실 모스턴집값 문제는 딥러닝이 아닌 그냥 회귀로 돌려야 더 잘나온다.
그리고 이제 분류에 대해 다뤄볼 것인데, 와인데이터를 이용한다.
사이트로 들어가서 IMPORT IN PYTHON을 클릭하여 패키지 install과
import까지 먼저 해보자.
2.1. 데이터 전처리
#!pip install ucimlrepo
from ucimlrepo import fetch_ucirepo
# fetch dataset
wine = fetch_ucirepo(id=109)
# data (as pandas dataframes)
X = wine.data.features
Y = wine.data.targets
# metadata
#print(wine.metadata)
# variable information
#print(wine.variables) metadata같은 거는 우선 제외하고 확인해보자.
X.shape, Y.shape((178, 13), (178, 1))X.head()| Alcohol | Malicacid | Ash | Alcalinity_of_ash | Magnesium | Total_phenols | Flavanoids | Nonflavanoid_phenols | Proanthocyanins | Color_intensity | Hue | 0D280_0D315_of_diluted_wines | Proline | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 14.23 | 1.71 | 2.43 | 15.6 | 127 | 2.80 | 3.06 | 0.28 | 2.29 | 5.64 | 1.04 | 3.92 | 1065 |
| 1 | 13.20 | 1.78 | 2.14 | 11.2 | 100 | 2.65 | 2.76 | 0.26 | 1.28 | 4.38 | 1.05 | 3.40 | 1050 |
| 2 | 13.16 | 2.36 | 2.67 | 18.6 | 101 | 2.80 | 3.24 | 0.30 | 2.81 | 5.68 | 1.03 | 3.17 | 1185 |
| 3 | 14.37 | 1.95 | 2.50 | 16.8 | 113 | 3.85 | 3.49 | 0.24 | 2.18 | 7.80 | 0.86 | 3.45 | 1480 |
| 4 | 13.24 | 2.59 | 2.87 | 21.0 | 118 | 2.80 | 2.69 | 0.39 | 1.82 | 4.32 | 1.04 | 2.93 | 735 |
X.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 178 entries, 0 to 177
Data columns (total 13 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Alcohol 178 non-null float64
1 Malicacid 178 non-null float64
2 Ash 178 non-null float64
3 Alcalinity_of_ash 178 non-null float64
4 Magnesium 178 non-null int64
5 Total_phenols 178 non-null float64
6 Flavanoids 178 non-null float64
7 Nonflavanoid_phenols 178 non-null float64
8 Proanthocyanins 178 non-null float64
9 Color_intensity 178 non-null float64
10 Hue 178 non-null float64
11 0D280_0D315_of_diluted_wines 178 non-null float64
12 Proline 178 non-null int64
dtypes: float64(11), int64(2)
memory usage: 18.2 KBX.describe().T| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| Alcohol | 178.0 | 13.000618 | 0.811827 | 11.03 | 12.3625 | 13.050 | 13.6775 | 14.83 |
| Malicacid | 178.0 | 2.336348 | 1.117146 | 0.74 | 1.6025 | 1.865 | 3.0825 | 5.80 |
| Ash | 178.0 | 2.366517 | 0.274344 | 1.36 | 2.2100 | 2.360 | 2.5575 | 3.23 |
| Alcalinity_of_ash | 178.0 | 19.494944 | 3.339564 | 10.60 | 17.2000 | 19.500 | 21.5000 | 30.00 |
| Magnesium | 178.0 | 99.741573 | 14.282484 | 70.00 | 88.0000 | 98.000 | 107.0000 | 162.00 |
| Total_phenols | 178.0 | 2.295112 | 0.625851 | 0.98 | 1.7425 | 2.355 | 2.8000 | 3.88 |
| Flavanoids | 178.0 | 2.029270 | 0.998859 | 0.34 | 1.2050 | 2.135 | 2.8750 | 5.08 |
| Nonflavanoid_phenols | 178.0 | 0.361854 | 0.124453 | 0.13 | 0.2700 | 0.340 | 0.4375 | 0.66 |
| Proanthocyanins | 178.0 | 1.590899 | 0.572359 | 0.41 | 1.2500 | 1.555 | 1.9500 | 3.58 |
| Color_intensity | 178.0 | 5.058090 | 2.318286 | 1.28 | 3.2200 | 4.690 | 6.2000 | 13.00 |
| Hue | 178.0 | 0.957449 | 0.228572 | 0.48 | 0.7825 | 0.965 | 1.1200 | 1.71 |
| 0D280_0D315_of_diluted_wines | 178.0 | 2.611685 | 0.709990 | 1.27 | 1.9375 | 2.780 | 3.1700 | 4.00 |
| Proline | 178.0 | 746.893258 | 314.907474 | 278.00 | 500.5000 | 673.500 | 985.0000 | 1680.00 |
Y.value_counts()class
2 71
1 59
3 48
Name: count, dtype: int64이는 1,2,3 으로 되어 있는데, 사이트에서 찾아보니 지역, 원산지와 관련된 구분이었다.
그런데 이렇게 value_counts()로 볼때 주의해야하는 점이 있다.
X와 Y가 있는데, X는 결국에 Y를 설명하는 설명변수고, Y는 정답이다.
그리고 X는 숫자나 문자가 될 수 있고, 문자일 경우에는 원핫인코딩을 진행했다.
Y는 숫자면 회귀, 문자면 분류가 되는데, 그동안 따로 Y에 대해서는 원핫인코딩을 하지 않았다.
왜냐하면 각 모델들이 내부적으로 알아서 원핫인코딩을 진행했기 때문이다.
그래서 만약 서울, 대전, 대구가 각각 0, 1, 2라면 100, 010, 001과 같이 알아서 바뀌었던 것이다.
그런데 지금 보면 1,2,3이 들어가 있는데, 이렇게 들어가면 안된다.
최소한 0,1,2로 들어가거나 차라리 문자가 들어가야 한다.
문자로 들어간다면, sparse_categorical_crossentropy가 내부적으로 0,1,2로 바꿔서 원핫인코딩을 해준다.
그게 아닌 1,2,3으로 들어가면 100% 에러가 발생한다.
따라서 원핫인코딩으로 바꿔서 넣어주던가, 0,1,2로 바꾸는 작업이 필수다.
sparse가 아닌 categorical_entropy를 사용한다면, 원핫인코딩을 사용해야하며,
keras에서 제공하는 to_categorical을 사용해서 원핫인코딩으로 바꾸는 방법은 다음과 같다.
Y_categorical=to_categorical(Y, num_classes=3)
Y_categorical그리고 sparse를 사용한다면 원핫인코딩이 되기 때문에
이번에는 그냥 Y-1을 이용해서 각 1,2,3에 1씩 빼줘서 0,1,2로 만들고 sparse를 사용하자.
Y=Y-1
Y.value_counts()class
1 71
0 59
2 48
Name: count, dtype: int64이렇게 0,1,2로 바껴서 들어가게 된다.
그러면 이제 train, test를 나누고 스케일링만 해주면 전처리는 끝이다.
X_train, X_test, Y_train, Y_test=train_test_split(X, Y, test_size=0.2)
X_train.shape, X_test.shape, Y_train.shape, Y_test.shape((142, 13), (36, 13), (142, 1), (36, 1))scaelr=MinMaxScaler()
X_train_scaled=scaelr.fit_transform(X_train)
X_test_scaled=scaelr.transform(X_test)2.2. 모델 구성 및 학습
학습: X,Y, 학습횟수, 검증, 콜백
model=keras.Sequential()
model.add(keras.layers.Input(shape=(X_train.shape[1], )))
model.add(keras.layers.Dense(64, activation="relu"))
model.add(keras.layers.Dense(3, activation="softmax"))
model.summary()Model: "sequential_6"┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ dense_15 (Dense) │ (None, 64) │ 896 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_16 (Dense) │ (None, 3) │ 195 │ └─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 1,091 (4.26 KB)
Trainable params: 1,091 (4.26 KB)
Non-trainable params: 0 (0.00 B)model.compile(optimizer="adam",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])데이터 수가 많지는 않지만 대략 흐름을 알기위해서 콜백함수도 만들어주자.
def on_epoch_end_fun(epoch, logs):
if(epoch + 1) % 20 == 0:
print(f"Epoch {epoch+1}: loss={logs['loss']:.4f}, accuracy={logs['accuracy']:.4f}",
f"val_loss={logs['val_loss']:.4f}, val_accuracy={logs['val_accuracy']:.4f}")
print_callback=LambdaCallback(on_epoch_end=on_epoch_end_fun)
stopping_callback=EarlyStopping(monitor="val_loss",
patience=10,
verbose=1,
restore_best_weights=True)history=model.fit(X_train_scaled, Y_train,
epochs=50, validation_split=0.2,
verbose=0, callbacks=[print_callback, stopping_callback])Epoch 20: loss=0.6727, accuracy=0.9381 val_loss=0.6459, val_accuracy=0.9655
Epoch 40: loss=0.3562, accuracy=0.9646 val_loss=0.3138, val_accuracy=0.9655
Restoring model weights from the end of the best epoch: 50.검증이 더 좋게 나오는데, 데이터의 수가 적어서 그렇다.
원래는 이렇게 170개 정도의 데이터라면 그냥 검증데이터를 따로 빼지 않는게 맞긴하다.
2.3. 평가지표
model.evaluate(X_test_scaled, Y_test)[1m2/2[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 25ms/step - accuracy: 0.8843 - loss: 0.2542
[0.2564815580844879, 0.8888888955116272]plt.plot(history.history["loss"], label="훈련 loss값")
plt.plot(history.history["val_loss"], label="검증 loss값")
plt.legend()
plt.xlabel("epoch")
plt.ylabel("loss")
plt.show()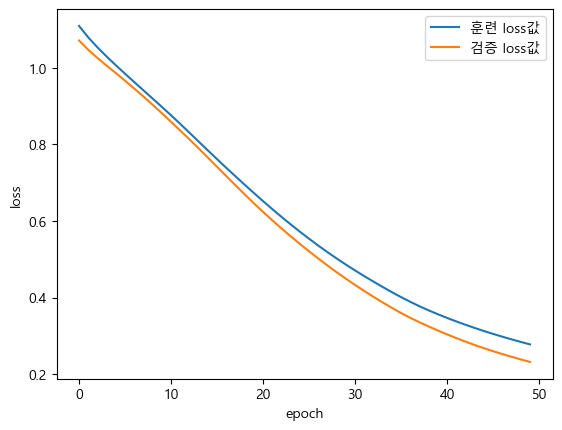
보스턴과 와인은 정형데이터다.
그래서 비정형데이터에 어울리는 모델은 아니다.
따라서 이런거는 차라리 그냥 지도학습의 회귀나 분류에 관련된 알고리즘을 쓰는게 더 좋은데 사용하는 방법을 보기 위해서 진행했다.
