
1. CelebA
저번 글에 이어서 GAN을 실습해보는데, 이번에는 컬러이미지다.
그런데 크기가 1GB가 넘기 때문에 다 불러올 수 없고, 랜덤하게 100개정도 추출해서 사용하자.
# train_dir='data/celeba/img_align_celeba/img_align_celeba'
# images=random.sample(os.listdir(train_dir), 100)
# len(images)
# save_dir='data/celeba/real'
# for i, img_name in enumerate(images):
# img_path=os.path.join(train_dir, img_name)
# img=imread(img_path)
# img_pil=Image.fromarray(img) # PIL 이미지로 변환
# # 이미지 저장
# save_path=os.path.join(save_dir, img_name)
# img_pil.save(save_path)
# print(f"저장 완료: {save_path}")train_dir='data/celeba/real'
images=os.listdir(train_dir) # 선택한 곳에 폴더가 있으면 폴더를, 파일이 있으면 파일을 가져옴
#print(images[:10])
plt.figure(figsize=(15,5))
for i, img_name in enumerate(images[:10]):
img_path=os.path.join(train_dir, img_name) # 경로 + 파일명
img=imread(img_path)
plt.subplot(2,5,i+1)
plt.imshow(img)
plt.title(img_name)
plt.axis('off')
plt.tight_layout()
plt.show()
def load_celeba_images(path, img_shape=(64, 64)):
images=[]
img_paths=glob.glob(os.path.join(path, '*.jpg')) # glob: 리스트로 가져옴
#print(img_paths)
for img_path in img_paths:
img=load_img(img_path, target_size=img_shape)
img=img_to_array(img)
img=(img/255.0)*2-1 # -1 ~ 1 사이로 정규화
images.append(img)
return np.array(images) # 배열로 변환해주기
X_train=load_celeba_images(train_dir)
X_train.shape(100, 64, 64, 3)
img=(img/255.0)*2-1
- (img/255.0): 모든 픽셀 값 0~1 사이 실수값으로 바꿈
- *2-1: 0~1 범위를 -1~1로
- 0 -> (0x2)-1=-1
- 0.5 -> (0.5x2)-1=0
- 1 -> (1x2)-1=1
GAN에서 생성자의 마지막 출력 활성화 함수로 tanh가 사용되는데
출력 범위가 -1~1이므로, 학습 대상 이미지도 같은 범위로 정규화
이제 생성자 모델과 판별자 모델을 만들고, GAN모델을 만들어서 생성자와 판별자를 연결시키자.
그리고 이 3개를 학습하는 함수까지 정의해보자.
1.1. 생성자 모델(G)
앞서 X_train.shape를 64, 64, 3으로 맞춰놨으니 생성자 모델 마지막도 맞춰주자.
g_model=Sequential()
g_model.add(keras.layers.Input(shape=(100,))) # 노이즈 생성
# 초반에 들어온 노이즈 백터는 완전 랜덤한 값이니까
# 먼저 비선형성(LeakyReLU)을 줘서 약간의 특성을 부여하고
# 그걸 정규화해서 분포를 안정화시키는 구조로 진행
g_model.add(keras.layers.Dense(256*8*8)) # 하이퍼파라미터
g_model.add(keras.layers.LeakyReLU(0.2))
g_model.add(keras.layers.BatchNormalization())
g_model.add(keras.layers.Reshape((8,8,256))) # 8 8 256
# 이후 다음부터는 가장 많이 쓰이는 표준 패턴인 정규화 이후 비선형으로
g_model.add(keras.layers.UpSampling2D()) # 16 16 256
g_model.add(keras.layers.Conv2D(128, kernel_size=5, padding='same')) # 16 16 128
g_model.add(keras.layers.BatchNormalization())
g_model.add(keras.layers.LeakyReLU(0.2))
g_model.add(keras.layers.UpSampling2D()) # 32 32 128
g_model.add(keras.layers.Conv2D(64, kernel_size=5, padding='same')) # 32 32 64
g_model.add(keras.layers.BatchNormalization())
g_model.add(keras.layers.LeakyReLU(0.2))
g_model.add(keras.layers.UpSampling2D()) # 64 64 64
g_model.add(keras.layers.Conv2D(3, kernel_size=5, padding='same', activation='tanh')) # 64 64 3
#g_model.summary()1.2. 판별자 모델(D)
생성자는 만들어내는 거니까 작은 거에서 늘려나가고
판별자는 특징을 뽑아내야하니까 큰 거에서 줄여나간다.
d_model=Sequential()
d_model.add(keras.layers.Input(shape=(64, 64, 3)))
d_model.add(keras.layers.Conv2D(64, kernel_size=5, strides=2, padding='same'))
d_model.add(keras.layers.LeakyReLU(0.2))
d_model.add(keras.layers.Dropout(0.3))
d_model.add(keras.layers.Conv2D(128, kernel_size=5, strides=2, padding='same'))
d_model.add(keras.layers.LeakyReLU(0.2))
d_model.add(keras.layers.Dropout(0.3))
# 완전연결층
d_model.add(keras.layers.Flatten())
d_model.add(keras.layers.Dense(1, activation='sigmoid'))
#d_model.summary()
d_model.compile(optimizer=Adam(0.0002, 0.5), # 논문에서 추천한 값
loss='binary_crossentropy', # 진짜/가짜 이미지를 이진 분류하므로 이진 크로스엔트로피 사용
metrics=['accuracy'])
d_model.trainable=False # 생성자 학습동안 판별자는 멈춰야하니까(가중치 고정시켜야하니까)1.3. GAN 모델
- 생성자와 판별자 연결 모델
g_input=keras.Input(shape=(100,)) # 랜덤한 100개의 벡터 생성
d_output=d_model(g_model(g_input)) # 노이즈 입력 -> 28*28 결과 -> 참인지 거짓인지
gan=Model(g_input, d_output) # 100 input, 64 64 3 output
gan.summary() # -> 1 참 거짓
gan.compile(optimizer=Adam(0.0002, 0.5), loss='binary_crossentropy', metrics=['accuracy']) # 참 거짓 구분Model: "functional_22"┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ input_layer_2 (InputLayer) │ (None, 100) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ sequential (Sequential) │ (None, 64, 64, 3) │ 2,750,083 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ sequential_1 (Sequential) │ (None, 1) │ 242,561 │ └─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 2,992,644 (11.42 MB)
Trainable params: 2,716,931 (10.36 MB)
Non-trainable params: 275,713 (1.05 MB)
1.4. 학습 함수 정의
def gan_train(epoch, batch_size, saving_interval):
# 판별자에 넣을 진짜, 가짜 라벨
true=np.ones((batch_size, 1))
fake=np.zeros((batch_size, 1))
for i in range(epoch):
# 실제 데이터 -> 판별자
d_model.trainable=True
idx=np.random.randint(0, X_train.shape[0], batch_size) # 0~100 32
imgs=X_train[idx]
d_loss_real=d_model.train_on_batch(imgs, true)
# 가상 이미지 -> 판별자
noise=np.random.normal(0, 1, (batch_size, 100)) # 100차원 노이즈
g_imgs=g_model.predict(noise, verbose=0) # 생성자 이미지 (예측)
d_loss_fake=d_model.train_on_batch(g_imgs, fake) # 가짜 이미지 판별 훈련
# 오차계산
d_loss=0.5 * np.add(d_loss_real, d_loss_fake) # np.add(d_loss_real, d_loss_fake)/2 보다, 속도 빠름
# gan모델
# 노이즈가 처음에는 개판일거고 이게 목표는 1이 되어서 오차의 합이 0에 가까워야함
# 그래서 생성자가 gan에게 노이즈와 true라고 강제적으로 넘겨주면서 속이기
# 그런데 얘가 학습할때는 D는 학습하면 안됨
# 그리고 나서 for문이 돌아서 D가 다시 판단할때는 학습을 켜줘야 하니까
# 위쪽에 d_model.trainable=True가 들어가는 거임
d_model.trainable=False
gan_loss=gan.train_on_batch(noise, true)
# 저장
if i % saving_interval == 0:
print('epoch:%d' % i, ' d_loss:%.4f' % d_loss[0], 'd_accuracy:%.4f' % d_loss[1],
' gan_loss:%.4f' % gan_loss[0], 'gan_accuracy:%.4f' % gan_loss[1])
noise=np.random.normal(0, 1, (10, 100))
g_imgs=g_model.predict(noise, verbose=0)
g_imgs=0.5 * g_imgs + 0.5 # tanh(0~255) 출력값 시각화 가능하도록 되돌리는 정규화 해제 작업
# tanh는 출력 범위가 -1~1 -> imshow나 이미지 저장은 int 픽셀값 요구
# 그래서 -1~1 그대로 넣으면 안되고 0~1로 변환해줘야함
fig, axs=plt.subplots(2,5)
count=0
for j in range(2):
for k in range(5):
axs[j,k].imshow(g_imgs[count])
axs[j,k].axis('off')
count+=1
fig.savefig("deep_result/gan_celeba/celeba_gan_%d.png" % i)
plt.close(fig)gan_train(2001, 25, 200)
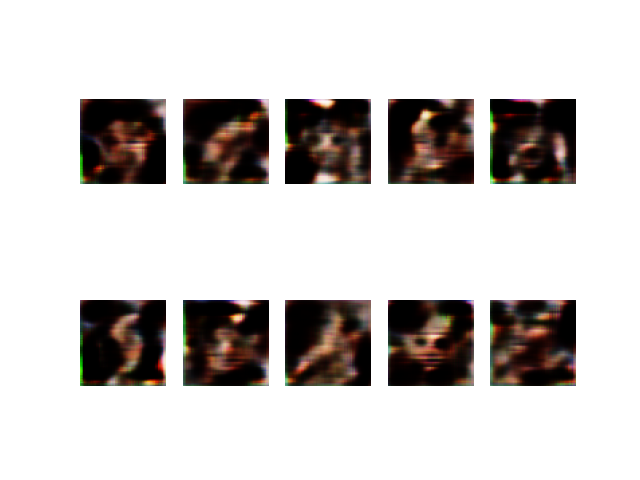
2000번 정도 돌렸는데, 한 10000번 넘으면 어느정도 잘 나올거 같다.

AI Model Developer