
📌 사용 환경
Python 3.10.2
conda 24.9.0
JupyterLab 4.2.5
1. 전력 예측
https://archive.ics.uci.edu/dataset/321/electricityloaddiagrams20112014
(다운받는데 좀 걸린다.)
날짜와 특정지역코드로 구성되어있다.
그래서 총 140256개의 데이터를 가지고 매 15분 단위의 타임스템프를 가진다.
열은 370개로 소비 지역을 나타낸다.
먼저 필요한 라이브러리들을 import해주고,
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rc("font", family="Malgun Gothic")
plt.rcParams["axes.unicode_minus"]=False
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split, cross_validate
from sklearn.model_selection import TimeSeriesSplit
from sklearn.model_selection import GridSearchCV, RandomizedSearchCV
from sklearn import metrics
from sklearn.metrics import r2_score, mean_squared_error, root_mean_squared_error, mean_absolute_error
from statsmodels.tsa.stattools import adfuller
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
from statsmodels.tsa.stattools import acf
from statsmodels.tsa.statespace.sarimax import SARIMAX
import statsmodels.tsa.api as tsa
import itertools
import tensorflow as tf
from tensorflow import keras
from keras.models import Sequential, load_model
from keras.layers import LSTM
from keras.optimizers import SGD, Adam
from keras.callbacks import ModelCheckpoint, EarlyStopping
from keras.callbacks import LambdaCallback
import random
np.random.seed(42)
tf.random.set_seed(42)
random.seed(42)데이터를 불러오는데 txt파일로 되어있고, 열과 열의 간격에 특수문자가 이번에는 ; 세미콜론으로 되어있다.
따라서 read_csv로 불러올때, sep=';'로 지정해줘야한다.
# read_csv의 옵션으로 여러가지를 줄 수 있는데,
data=pd.read_csv("./data/LD2011_2014.txt",
sep=';',
index_col=0, # index_col=0으로 지정하면 첫번째 열을 인덱스로 지정한다.
parse_dates=True, # 날짜 형태로 생긴 애들이 있다면, 문자열을 자동으로 datetime으로 변환해준다.
decimal=',') # decimal=","로 지정하면 소수점을 쉼표로 인식한다. 즉 소수점 구분자로, 숫자가 예를들어 0,123 이라면 0.123으로 변환해준다.
# 데이터 확인
data.shape(140256, 370)elec=data.copy()
elec.head(2)| MT_001 | MT_002 | MT_003 | MT_004 | MT_005 | MT_006 | MT_007 | MT_008 | MT_009 | MT_010 | ... | MT_361 | MT_362 | MT_363 | MT_364 | MT_365 | MT_366 | MT_367 | MT_368 | MT_369 | MT_370 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2011-01-01 00:15:00 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2011-01-01 00:30:00 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
2 rows × 370 columns
elec.tail(2)| MT_001 | MT_002 | MT_003 | MT_004 | MT_005 | MT_006 | MT_007 | MT_008 | MT_009 | MT_010 | ... | MT_361 | MT_362 | MT_363 | MT_364 | MT_365 | MT_366 | MT_367 | MT_368 | MT_369 | MT_370 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2014-12-31 23:45:00 | 1.269036 | 21.337127 | 1.737619 | 166.666667 | 85.365854 | 285.714286 | 10.17524 | 225.589226 | 64.685315 | 72.043011 | ... | 246.252677 | 28000.0 | 1443.037975 | 909.090909 | 26.075619 | 4.095963 | 664.618086 | 146.911519 | 646.627566 | 6540.540541 |
| 2015-01-01 00:00:00 | 2.538071 | 19.914651 | 1.737619 | 178.861789 | 84.146341 | 279.761905 | 10.17524 | 249.158249 | 62.937063 | 69.892473 | ... | 188.436831 | 27800.0 | 1409.282700 | 954.545455 | 27.379400 | 4.095963 | 628.621598 | 131.886477 | 673.020528 | 7135.135135 |
2 rows × 370 columns
elec.info()<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 140256 entries, 2011-01-01 00:15:00 to 2015-01-01 00:00:00
Columns: 370 entries, MT_001 to MT_370
dtypes: float64(370)
memory usage: 397.0 MB총 4년치의 데이터다.
날짜도 인덱스로 잘 들어왔고, 지금 15분마다로 나뉘어져 있기 때문에 sum으로하여 하여 하루 사용 총합으로 바꿔주자.
그래서 매일 사용한 전기량으로 바꾼 후에 평균을 구한 후,
평균보다 높으면 전기 사용을 많이한 것이고, 평균보다 적으면 적게 사용했다는 1과 0으로 분류문제로 만들자.
그러면 다음에 어느정도 쓰면 이게 평균보다 높은지 낮은지를 분류해주는 모델을 만들자.
일별 소비량 합산을 구하자.
# resample 메서드는 pandas에서 제공하는 메서드로, 시간 데이터를 원하는 단위로 샘플링 할 수 있다.
# D, W, Y, M, Q, A 등 다양한 방법으로 샘플링 할 수 있다.
# D: 일별, W: 주별, Y: 년별, M: 월별, Q: 분기별, A: 년별
daily_elec=elec.resample("D").sum()
daily_elec.shape(1462, 370)이제 임계값을 계산하자.
전체 평균으로 임계값을 하고, 그 임계값을 기준으로 1과 0으로 분류하자.
# 첫번째 mean: 하루동안 사용한 전기량의 평균
# 두번째 mean: 1462개의 "일별 평균 사용량" 시리즈 전체에서 또 평균을 내는 것. 전체 4년간 평균적인 하루의 사용량 평균
threshold=daily_elec.mean(axis=1).mean()
thresholdnp.float64(50704.3933356309)# 새로운 분류 열 추가하여 1이면 전기 사용이 많은 것, 0이면 전기 사용이 적은 것으로 분류
daily_elec["label"]=np.where(daily_elec.mean(axis=1)>threshold, 1, 0)
daily_elec["label"].value_counts()label
0 742
1 720
Name: count, dtype: int64daily_elec.tail()| MT_001 | MT_002 | MT_003 | MT_004 | MT_005 | MT_006 | MT_007 | MT_008 | MT_009 | MT_010 | ... | MT_362 | MT_363 | MT_364 | MT_365 | MT_366 | MT_367 | MT_368 | MT_369 | MT_370 | label | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2014-12-28 | 227.157360 | 2131.578947 | 151.172893 | 14327.235772 | 6776.829268 | 20122.023810 | 429.621255 | 25255.892256 | 5118.881119 | 4794.623656 | ... | 3272100.0 | 220721.518987 | 257477.272727 | 8169.491525 | 552.369807 | 45914.837577 | 4405.676127 | 66135.630499 | 1.553189e+06 | 1 |
| 2014-12-29 | 248.730964 | 2212.660028 | 160.729800 | 14067.073171 | 7198.780488 | 22824.404762 | 550.593556 | 30286.195286 | 6697.552448 | 6337.634409 | ... | 3109100.0 | 206852.320675 | 269090.909091 | 8438.070404 | 1153.891164 | 53928.884987 | 12914.858097 | 73882.697947 | 1.806486e+06 | 1 |
| 2014-12-30 | 232.233503 | 2205.547653 | 165.073849 | 14290.650407 | 7189.024390 | 23880.952381 | 586.772188 | 30909.090909 | 6487.762238 | 6489.247312 | ... | 2904300.0 | 204126.582278 | 263613.636364 | 10615.384615 | 892.334699 | 56334.503951 | 15996.661102 | 73950.146628 | 1.867568e+06 | 1 |
| 2014-12-31 | 229.695431 | 2273.115220 | 166.811468 | 14006.097561 | 7023.170732 | 23511.904762 | 690.785755 | 28700.336700 | 6211.538462 | 5034.408602 | ... | 2748800.0 | 162556.962025 | 215886.363636 | 7415.906128 | 530.134582 | 50259.877085 | 13245.409015 | 70416.422287 | 1.365892e+06 | 0 |
| 2015-01-01 | 2.538071 | 19.914651 | 1.737619 | 178.861789 | 84.146341 | 279.761905 | 10.175240 | 249.158249 | 62.937063 | 69.892473 | ... | 27800.0 | 1409.282700 | 954.545455 | 27.379400 | 4.095963 | 628.621598 | 131.886477 | 673.020528 | 7.135135e+03 | 0 |
5 rows × 371 columns
X와 Y를 나눠주자.
daily_X=daily_elec.drop(columns=["label"], axis=1)
daily_Y=daily_elec["label"]
daily_X.shape, daily_Y.shape((1462, 370), (1462,))표준화 진행할때 X는 해줘야하고, Y는 분류이기 0아니면 1이기 때문에 스케일링을 해줄 필요가 없다.
min_max_scaler=MinMaxScaler()
min_max_scaled=min_max_scaler.fit_transform(daily_X)데이터를 묶어주고,
def make_sample(data, labels, seq_length):
train=[]
target=[]
for i in range(len(data)-seq_length):
train.append(data[i:i+seq_length])
target.append(labels[i+seq_length])
return np.array(train), np.array(target)seq_length=30
X, Y=make_sample(min_max_scaled, daily_Y.values, seq_length)
X.shape, Y.shape((1432, 30, 370), (1432,))1.1. LSTM
이제 학습을 하기 위해서 X, Y train, test를 split해주자.
X_train, X_test, Y_train, Y_test=train_test_split(X, Y, test_size=0.3, shuffle=False)
X_train.shape, X_test.shape, Y_train.shape, Y_test.shape((1002, 30, 370), (430, 30, 370), (1002,), (430,))모델을 생성할때, 분류기 때문에 sigmoid 사용한다.
model=Sequential()
model.add(keras.layers.Input(shape=(seq_length, 370)))
model.add(keras.layers.LSTM(16, activation="tanh", return_sequences=False))
model.add(keras.layers.Dense(1, activation="sigmoid"))
model.summary()Model: "sequential_3"┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ lstm_3 (LSTM) │ (None, 16) │ 24,768 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_3 (Dense) │ (None, 1) │ 17 │ └─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 24,785 (96.82 KB)
Trainable params: 24,785 (96.82 KB)
Non-trainable params: 0 (0.00 B)
def on_epoch_end_function(epoch, logs):
if (epoch+1) % 20 == 0:
print(f"Epoch {epoch+1}: loss={logs['loss']:.4f}, accuracy={logs['accuracy']:.4f}",
f"val_loss={logs['val_loss']:.4f}, val_accuracy={logs['val_accuracy']:.4f}") # test
print_callback=LambdaCallback(on_epoch_end=on_epoch_end_function)
# val_loss == test_loss
early_stopping=EarlyStopping(monitor="val_loss",
patience=20,
verbose=1,
restore_best_weights=True)model.compile(optimizer="adam", loss="binary_crossentropy", metrics=["accuracy"])
history=model.fit(X_train, Y_train,
epochs=50, batch_size=16,
validation_data=(X_test, Y_test), shuffle=False,
verbose=0, callbacks=[print_callback, early_stopping])Epoch 20: loss=0.4526, accuracy=0.6267 val_loss=0.7005, val_accuracy=0.2070
Epoch 40: loss=0.2881, accuracy=0.9541 val_loss=0.5985, val_accuracy=0.8000
Restoring model weights from the end of the best epoch: 38.test_loss, test_mse=model.evaluate(X_test, Y_test)
print(f"test loss: {test_loss:.4f}, test mse: {test_mse:.4f}")[1m14/14[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 6ms/step - accuracy: 0.7565 - loss: 0.5441
test loss: 0.4863, test mse: 0.8047plt.figure(figsize=(10,5))
plt.plot(history.history["loss"], label="훈련 loss")
plt.plot(history.history["val_loss"], label="테스트 loss")
plt.legend()
plt.xlabel("epoch")
plt.ylabel("loss")
plt.show()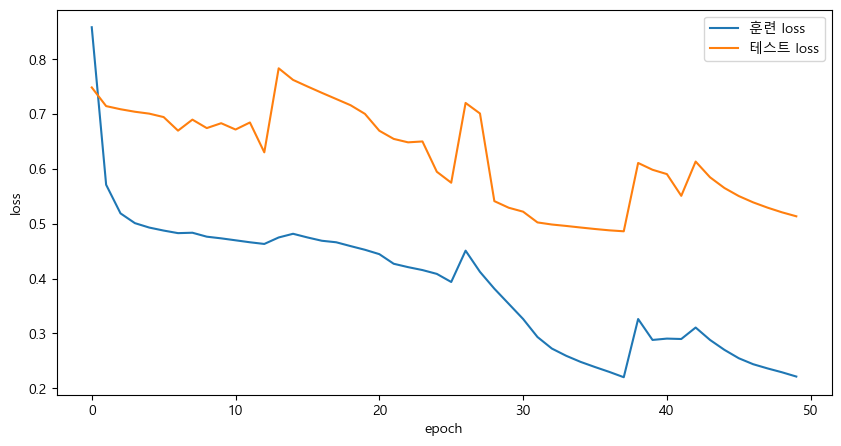
pred_prob=model.predict(X_test)
pred_prob[0][1m14/14[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m1s[0m 21ms/step
array([0.7568716], dtype=float32)pred_class=(pred_prob > 0.5).astype(int)
pred_class[0]array([1])이렇게 분류를 했다.
metrics.accuracy_score(Y_test, pred_class)0.8046511627906977그리고 보통 classification_report를 찍어보는데,
시계열에서는 크게 의미가 없다.
그렇다면 랜덤포레스트의 경우를 보자.
1.2. RandomForestClassifier
우선 X의 형태는
X.shape(1432, 30, 370)이렇게 3차원이기 때문에 이를 2차원으로 변환해줘야한다.
X_flat=X.reshape(X.shape[0], -1)
X_flat.shape(1432, 11100)370개의 열과 30일 간격으로 묶인 것을 평탄화했기 때문에 370x30=11100개의 열이 되었다.
그런데 이렇게 많은 열을 가지고 있으면 절대 다 학습을 진행할 수 없을 것이고 물론 과적합도 될 수 있기 때문에 차원축소를 진행한다.
차원축소를 진행하는 방법은 여러가지가 있는데, 여기서는 PCA를 사용하여 차원축소를 진행한다.
PCA는 주성분 분석이라고 부르기도 하는데, 주성분 분석은 데이터의 분산을 최대한 보존하면서 차원을 줄이는 기법이다.
즉, 데이터의 분산을 최대한 보존하면서 차원을 줄이는 기법이다.
이를 사용하면 타임 스텝 간의 상관관계를 최대한 보존하면서 차원을 줄일 수 있다.
370x30으로 평탄화함으로써 시간 흐름을 하나의 벡터에 녹여냈다.
그리고 PCA는 그 안에 있는 전체 패턴의 분산을 기준으로 요약하니까,
자연스럽게 어떤 타임스텝들이 서로 비슷한지, 연관 있는지를 어느정도 반영할 수 있을 것이다.
from sklearn.decomposition import PCA
pca=PCA(n_components=0.95)
X_pca=pca.fit_transform(X_flat)
X_pca.shape(1432, 34)X_train, X_test, Y_train, Y_test=train_test_split(X_pca, Y, test_size=0.3, shuffle=False)
X_train.shape, Y_train.shape, X_test.shape, Y_test.shape((1002, 34), (1002,), (430, 34), (430,))forest=RandomForestClassifier(max_depth=5, random_state=42)
forest.fit(X_train, Y_train)
forest.score(X_train, Y_train), forest.score(X_test, Y_test)(0.9820359281437125, 0.586046511627907)과대 적합이다.
그러면 트레인에서 일부를 빼서 검증 데이터를 돌려보자.
tscv=TimeSeriesSplit(n_splits=5)
scores=cross_validate(forest, X_train, Y_train, return_train_score=True, cv=tscv)
scores{'fit_time': array([0.18849516, 0.14559197, 0.2283988 , 0.31521297, 0.37699103]),
'score_time': array([0.00797749, 0.01098561, 0.0099721 , 0.01296759, 0.01196837]),
'test_score': array([1. , 0.77844311, 0.5988024 , 0.76646707, 0.89221557]),
'train_score': array([1. , 1. , 1. , 0.99850299, 0.98203593])}
np.mean(scores["train_score"]), np.mean(scores["test_score"])(np.float64(0.9961077844311378), np.float64(0.8071856287425151))이도 잘 나오긴 했는데 과대적합이다.
최적화를 해보자.
1.2.1. 최적화
from scipy.stats import randint, uniform
params={
"n_estimators": randint(50,500),
"max_depth": randint(3,10),
"min_samples_split": randint(5,20),
"min_samples_leaf": randint(5,20)
}rs=RandomizedSearchCV(RandomForestClassifier(), params, n_jobs=-1, cv=tscv, random_state=42)
rs.fit(X_train, Y_train)
rs_best=rs.best_estimator_
rs_best
rs.best_score_np.float64(0.8083832335329342)rs_best.score(X_train, Y_train), rs_best.score(X_test, Y_test)(0.9760479041916168, 0.7023255813953488)1.3. SARIMAX
SARIMAX는 사실 열이 많으면 계산이 안된다.
스케일링과 훈련, 테스트 데이터를 나누는 코드는 생략하고 결과만 보이자면,
model=SARIMAX(Y_train, exog=X_train, order=(1,0,0))
model_fit=model.fit()d:\anaconda\envs\thirdENV\lib\site-packages\statsmodels\base\model.py:607: ConvergenceWarning: Maximum Likelihood optimization failed to converge. Check mle_retvals
warnings.warn("Maximum Likelihood optimization failed to "테스트로 seasonal order도 안주고, 차분도 없이 간단하게 돌려봤는데 실행시간도 꽤걸리고 이와 같이 에러가 발생한다.
열이 370개이기 때문에 계산이 안되는 것이다.
이 SARIMAX는 생략한다.
