이번에 안면 관련 CNN 팀 프로젝트를 진행하게 되었다.
그런데 결론부터 말하자면 많이 진행되지는 않았다..😭
그 과정을 담기 위해 작성한다.
1. 프로젝트 개요
운전자의 안면 인식을 기반으로 졸음 방지 시스템을 만드는 팀 프로젝트를 진행 중에 있다.
초반에 주제 선정에 조금 시간이 걸렸지만 결국에 데이터셋도 꽤 존재해서 선정하게 되었다.
초반에 찾아본 데이터는 다음과 같다.
이들 중 두 번째, 졸음운전 예방을 위한 운전자 상태 정보 영상 데이터셋을 이용하고자 했다. 그런데 특정 장비로 촬영된 흑백이미지였기에 해당 장비를 사용하지 않고 우리는 PC의 웹캠을 사용할 것이고, 집 내부에서 돌리기 때문에 형광등과 같은 밝기에 영향을 받게 된다고 생각했다.
따라서 컬러 이미지인 캐글 데이터를 사용하고 이미지 증강으로 밝기 조절 및 rotation 정도만 생각하고자 했다.
따라서 캐글에서 제공하는 데이터셋인 yawn_eye_dataset_new
을 이용하고자 했다.
2. 데이터 구성 및 전처리
2.1. 데이터 상세
📌 데이터셋: Kaggle - yawn_eye_dataset_new
📌 데이터구성:
- closed: 눈 감은 상태 -> 졸음 판단 핵심 (Train 617 / Test 109)
- open: 눈 뜬 상태 -> 정상 상태 (Train 617 / Test 109)
- yawn: 하품 -> 졸음 전조 가능 (Train 617 / Test 106)
- no_yawn: 입 닫힘 -> 정상 상태 (Train 616 / Test 109)
2.2. 전처리 과정
- Open, Closed, Yawn, No_Yawn 클래스 나누기
- 모델 학습
- cv.VideoCapture()로 프레임 추출
- 눈/입 영역 crop 후 모델에 전달
- 졸음 상태 판단 (눈 감김 + 하품)
- 졸음 판단 로직 추가
- 눈 감김 2초 이상 지속 -> 졸음 알람
- Yawn 클래스 -> 아품 알림 or 졸음 전조 감지
이 정도의 과정을 구상했다.
2.3. 1차 시도
2.3.1. 데이터 로드 및 확인
import numpy as np
import pandas as pd
import os
import cv2
import matplotlib.pyplot as plt
from tqdm import tqdmlabels=os.listdir("../../data/raw/01_kaggle_dataset/dataset_new/train")
labels['Closed', 'Open', 'no_yawn', 'yawn']ce=plt.imread("../../data/raw/01_kaggle_dataset/dataset_new/train/Closed/_0.jpg")
plt.imshow(ce)
ce.shape(145, 145, 3)
ce2=plt.imread("../../data/raw/01_kaggle_dataset/dataset_new/test/Closed/_634.jpg")
plt.imshow(ce2)
ce2.shape(98, 157, 3)
y=plt.imread("../../data/raw/01_kaggle_dataset/dataset_new/train/yawn/1.jpg")
plt.imshow(y)
y.shape(480, 640, 3)
이미지들의 크기가 다 다르다.
따라서 이미지의 크기를 다 일치시켜야 한다.
2.3.2. 얼굴 인식 - Haar Casecades
먼저 Yawn(하품) 이미지를 OpenCV로 얼굴 인식해야 한다.
OpenCV에서 제공하는 얼굴, 눈 등에 대한 미리 훈련된 데이터인 Haar Casecades라는 것이 존재한다.
자세한 내용은 아래를 참고하자.
- https://deep-learning-study.tistory.com/244
또, 이 캐스케이드 분류기 함수cv2.CascadeClassifier,detectMultiScale을 사용하기 위해서는 아래 링크에서haarcascade_frontalface_default.xml파일을 다운받아야 한다. - https://github.com/opencv/opencv/tree/master/data/haarcascades
BASE_DIR="../../data/raw/01_kaggle_dataset/dataset_new"
SAVE_DIR="../../data/processed/01_kaggle_dataset/cropped_dataset_HARR"
FACE_CAS_PATH="../../data/raw/01_kaggle_dataset/haarcascade_frontalface_default.xml"
face_cascade=cv2.CascadeClassifier(FACE_CAS_PATH)
IMG_SIZE=145 # 리사이즈 크기(눈 이미지와 크기 맞추기)
categories=["Closed", "Open", "no_yawn", "yawn"]
def crop_and_save(dataset_type): # train, test
src_path=os.path.join(BASE_DIR, dataset_type) # dataset_new/train, dataset_new/test
dst_path=os.path.join(SAVE_DIR, dataset_type) # cropped_dataset_HARR/train, cropped_dataset_HARR/test
for category in categories: # Closed, Open, no_yawn, yawn
# dataset_new/train/Closed, dataset_new/train/Open, dataset_new/train/no_yawn, dataset_new/train/yawn
src_class_path=os.path.join(src_path, category)
# cropped_dataset_HARR/train/Closed, cropped_dataset_HARR/train/Open, cropped_dataset_HARR/train/no_yawn, cropped_dataset_HARR/train/yawn
dst_class_path=os.path.join(dst_path, category)
os.makedirs(dst_class_path, exist_ok=True)
for img_name in tqdm(os.listdir(src_class_path), desc=f"Processing {category}", ncols=100):
img_path=os.path.join(src_class_path, img_name)
img_array=cv2.imread(img_path, cv2.IMREAD_COLOR)
if img_array is None: continue # IMG load fail -> skip
# cv2.CascadeClassifier.detectMultiScale(image, scaleFactor, minNeighbors, minSize, maxSize) -> result
# image: 입력
# scaleFactor: 축소 비율 (default: 1.1) -> 1.3 -> 너무 작으면 연산량 커지고, 너무 크면 작은 얼굴을 놓침
# minNeighbors: 얼마나 많은 이웃 사각형이 검출되어야 최종 검출 영역으로 설정할지(default: 3) -> 5
# 얼굴 아닌 걸 얼굴로 착각하는 걸 방지 → 값이 낮으면 오탐 많고, 높으면 놓침 많아짐 (3~6 정도가 적절)
# minSize, maxSize: 최소, 최대 객체 크기 (w, h)
# result: 검출된 객체의 사격형 정보(x,y,w,h)를 담은 numpy 배열
faces=face_cascade.detectMultiScale(img_array, scaleFactor=1.3, minNeighbors=5)
if len(faces)==0: continue # 얼굴 못 찾은 경우 스킵
# 가장 큰 얼굴 1개만 crop하여 저장(여러 명이 찍힌 경우도 안정적으로 처리)
x, y, w, h=sorted(faces, key=lambda box: box[2] * box[3], reverse=True)[0]
ROI=img_array[y:y+h, x:x+w] # ROI(Region of Interest) 얼굴 부분만 crop
resized=cv2.resize(ROI, (IMG_SIZE, IMG_SIZE))
save_path=os.path.join(dst_class_path, img_name)
cv2.imwrite(save_path, resized)
crop_and_save("train")
crop_and_save("test")Processing Closed: 100%|█████████████████████████████████████████| 617/617 [00:05<00:00, 103.67it/s]
Processing Open: 100%|███████████████████████████████████████████| 617/617 [00:05<00:00, 106.85it/s]
Processing no_yawn: 100%|█████████████████████████████████████████| 616/616 [00:15<00:00, 38.69it/s]
Processing yawn: 100%|████████████████████████████████████████████| 617/617 [00:16<00:00, 38.40it/s]
Processing Closed: 100%|█████████████████████████████████████████| 109/109 [00:00<00:00, 109.25it/s]
Processing Open: 100%|████████████████████████████████████████████| 109/109 [00:01<00:00, 94.55it/s]
Processing no_yawn: 100%|█████████████████████████████████████████| 109/109 [00:03<00:00, 31.61it/s]
Processing yawn: 100%|████████████████████████████████████████████| 106/106 [00:02<00:00, 35.55it/s]이를 실행하면 아래와 같이 나와야 하는데,
plt.imshow(plt.imread("../../data/processed/01_kaggle_dataset/cropped_dataset_HARR/train/yawn/241.jpg"))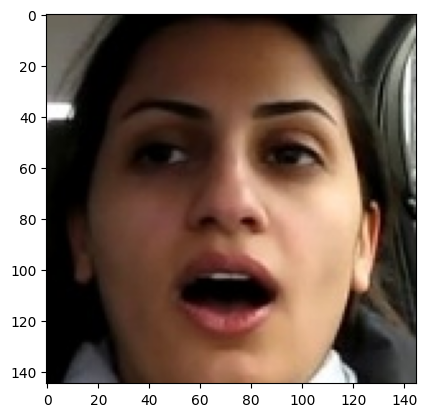
꽤 많은 빈도로 제대로 인식을 못하는 경우가 있었다.
plt.imshow(plt.imread("../../data/processed/01_kaggle_dataset/cropped_dataset_HARR/test/no_yawn/113.jpg"))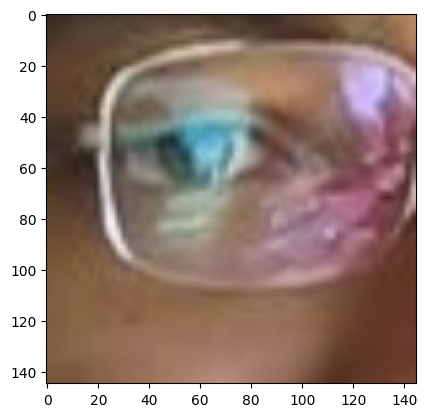
2.3.3. 얼굴 인식 2 - MediaPipe
그래서 또 다른 툴인 MediaPipe를 이용하고자 했다.
!pip install mediapipe --quietimport mediapipe as mpBASE_DIR="../../data/raw/01_kaggle_dataset/dataset_new"
SAVE_DIR="../../data/processed/01_kaggle_dataset/cropped_dataset_MediaPipe"
categories=["Closed", "Open", "no_yawn", "yawn"]
IMG_SIZE=145
mp_face_detection=mp.solutions.face_detection
def crop_with_mediapipe(dataset_type): # train, test
src_path=os.path.join(BASE_DIR, dataset_type) # dataset_new/train, dataset_new/test
dst_path=os.path.join(SAVE_DIR, dataset_type) # cropped_dataset_MediaPipe/train, cropped_dataset_MediaPipe/test
os.makedirs(dst_path, exist_ok=True)
with mp_face_detection.FaceDetection(model_selection=0, min_detection_confidence=0.5) as detector:
for category in categories:
# dataset_new/train/Closed, dataset_new/train/Open, dataset_new/train/no_yawn, dataset_new/train/yawn
src_class_path=os.path.join(src_path, category)
# cropped_dataset_MediaPipe/train/Closed, cropped_dataset_MediaPipe/train/Open, cropped_dataset_MediaPipe/train/no_yawn, cropped_dataset_MediaPipe/train/yawn
dst_class_path=os.path.join(dst_path, category)
os.makedirs(dst_class_path, exist_ok=True)
for img_name in tqdm(os.listdir(src_class_path), desc=f"Processing {dataset_type}/{category}", ncols=100):
img_path=os.path.join(src_class_path, img_name)
img=cv2.imread(img_path)
if img is None: continue # IMG load fail -> skip
if category in ["Closed", "Open"]: # 145x145
resized=cv2.resize(img, (IMG_SIZE, IMG_SIZE))
save_path=os.path.join(dst_class_path, img_name)
cv2.imwrite(save_path, resized)
continue
# yawn / no_yawn → MediaPipe crop
img_rgb=cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
results=detector.process(img_rgb)
if results.detections:
bbox=results.detections[0].location_data.relative_bounding_box
h, w, _=img.shape
x=int(bbox.xmin * w)
y=int(bbox.ymin * h)
box_w=int(bbox.width * w)
box_h=int(bbox.height * h)
x, y=max(0, x), max(0, y)
face_crop=img[y:y+box_h, x:x+box_w]
if face_crop.shape[0] < 50 or face_crop.shape[1] < 50:
continue # 너무 작은 얼굴은 스킵
resized=cv2.resize(face_crop, (IMG_SIZE, IMG_SIZE))
save_path=os.path.join(dst_class_path, img_name)
cv2.imwrite(save_path, resized)
crop_with_mediapipe("train")
crop_with_mediapipe("test")Processing train/Closed: 100%|███████████████████████████████████| 617/617 [00:01<00:00, 360.02it/s]
Processing train/Open: 100%|█████████████████████████████████████| 617/617 [00:01<00:00, 401.94it/s]
Processing train/no_yawn: 100%|██████████████████████████████████| 616/616 [00:05<00:00, 118.24it/s]
Processing train/yawn: 100%|█████████████████████████████████████| 617/617 [00:04<00:00, 128.45it/s]
Processing test/Closed: 100%|████████████████████████████████████| 109/109 [00:00<00:00, 378.54it/s]
Processing test/Open: 100%|██████████████████████████████████████| 109/109 [00:00<00:00, 299.80it/s]
Processing test/no_yawn: 100%|███████████████████████████████████| 109/109 [00:00<00:00, 129.95it/s]
Processing test/yawn: 100%|██████████████████████████████████████| 106/106 [00:00<00:00, 131.70it/s]이를 이용하니 다 제대로 인식했다.
2.3.4. 모델 훈련
import numpy as np
import pandas as pd
import os
import cv2
import matplotlib.pyplot as plt
from tqdm import tqdm
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpointIMG_SIZE=145
BATCH_SIZE=16
SEED=42
train_datagen=ImageDataGenerator(
rescale=1./255,
rotation_range=10,
#zoom_range=0.1,
brightness_range=[0.8, 1.2],
horizontal_flip=False,
validation_split=0.2
)
train_generator=train_datagen.flow_from_directory(
"../../data/processed/01_kaggle_dataset/cropped_dataset_MediaPipe/train",
target_size=(IMG_SIZE, IMG_SIZE),
batch_size=BATCH_SIZE,
class_mode="categorical",
shuffle=True,
seed=SEED,
subset="training"
)
validation_generator=train_datagen.flow_from_directory(
"../../data/processed/01_kaggle_dataset/cropped_dataset_MediaPipe/train",
target_size=(IMG_SIZE, IMG_SIZE),
batch_size=BATCH_SIZE,
class_mode="categorical",
shuffle=True,
seed=SEED,
subset="validation"
)Found 1975 images belonging to 4 classes.
Found 492 images belonging to 4 classes.model = Sequential()
model.add(Conv2D(256, 3, activation="relu", input_shape=(IMG_SIZE, IMG_SIZE, 3)))
model.add(MaxPooling2D(2))
model.add(Conv2D(128, 3, activation="relu"))
model.add(MaxPooling2D(2))
model.add(Conv2D(64, 3, activation="relu"))
model.add(MaxPooling2D(2))
model.add(Conv2D(32, 3, activation="relu"))
model.add(MaxPooling2D(2))
model.add(Flatten())
model.add(Dropout(0.5))
model.add(Dense(64, activation="relu"))
model.add(Dense(4, activation="softmax")) # 4 classes
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])/usr/local/lib/python3.11/dist-packages/keras/src/layers/convolutional/base_conv.py:107: UserWarning: Do not pass an `input_shape`/`input_dim` argument to a layer. When using Sequential models, prefer using an `Input(shape)` object as the first layer in the model instead.
super().__init__(activity_regularizer=activity_regularizer, **kwargs)
# EarlyStopping: val_loss가 patience만큼 개선되지 않으면 멈춤
esc=EarlyStopping(monitor="val_loss", patience=5, restore_best_weights=True, verbose=1)
# ModelCheckpoint: val_loss가 가장 낮은 시점마다 모델 저장
model_checkpoint=ModelCheckpoint("../../src/models/01_Basic_Model/best_drowsiness_model.keras",
monitor="val_loss", save_best_only=True, save_weights_only=False,
mode='min', verbose=1)
history=model.fit(train_generator, validation_data=validation_generator, epochs=50, callbacks=[esc, model_checkpoint])/usr/local/lib/python3.11/dist-packages/keras/src/trainers/data_adapters/py_dataset_adapter.py:121: UserWarning: Your `PyDataset` class should call `super().__init__(**kwargs)` in its constructor. `**kwargs` can include `workers`, `use_multiprocessing`, `max_queue_size`. Do not pass these arguments to `fit()`, as they will be ignored.
self._warn_if_super_not_called()
Epoch 1/50
124/124 ━━━━━━━━━━━━━━━━━━━━ 0s 5s/step - accuracy: 0.4429 - loss: 1.1343
Epoch 1: val_loss improved from inf to 0.45596, saving model to /content/drive/MyDrive/Colab Notebooks/vision_project/drowsiness_cls_project/best_drowsiness_model.keras
124/124 ━━━━━━━━━━━━━━━━━━━━ 640s 5s/step - accuracy: 0.4442 - loss: 1.1319 - val_accuracy: 0.8577 - val_loss: 0.4560
Epoch 2/50
124/124 ━━━━━━━━━━━━━━━━━━━━ 0s 5s/step - accuracy: 0.8732 - loss: 0.3391
Epoch 2: val_loss improved from 0.45596 to 0.34150, saving model to /content/drive/MyDrive/Colab Notebooks/vision_project/drowsiness_cls_project/best_drowsiness_model.keras
124/124 ━━━━━━━━━━━━━━━━━━━━ 625s 5s/step - accuracy: 0.8734 - loss: 0.3388 - val_accuracy: 0.8923 - val_loss: 0.3415
...
...
Epoch 14: val_loss did not improve from 0.14856
124/124 ━━━━━━━━━━━━━━━━━━━━ 677s 5s/step - accuracy: 0.9845 - loss: 0.0433 - val_accuracy: 0.9431 - val_loss: 0.2249
Epoch 14: early stopping
Restoring model weights from the end of the best epoch: 9.plt.plot(history.history["accuracy"], label="train accuracy")
plt.plot(history.history["val_accuracy"], label="val accuracy")
plt.legend()
plt.title("Accuracy")
plt.show()
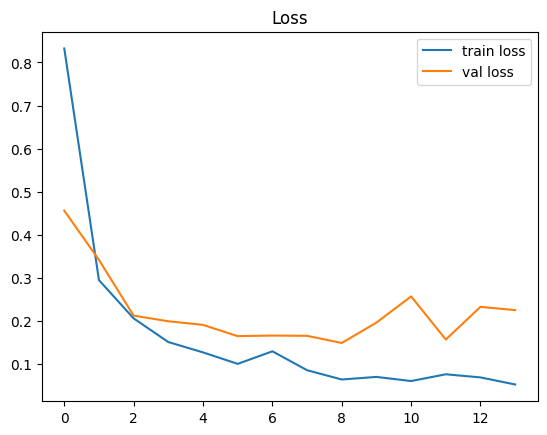
plt.plot(history.history["loss"], label="train loss")
plt.plot(history.history["val_loss"], label="val loss")
plt.legend()
plt.title("Loss")
plt.show()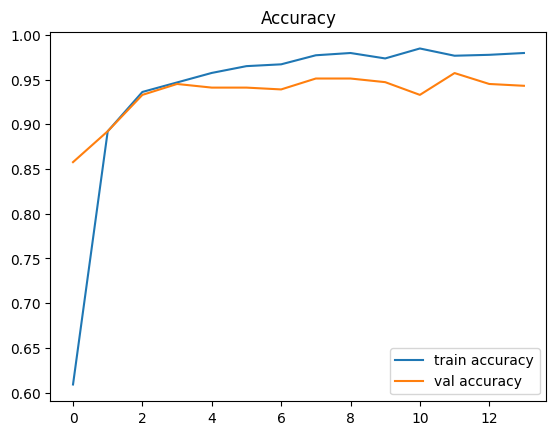
model.save("../../src/models/01_Basic_Model/drowsiness_mediapipe_model_first.keras")2.3.5. 모델 예측
import numpy as np
import pandas as pd
import os
import cv2
import matplotlib.pyplot as plt
from tqdm import tqdm
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
from sklearn.metrics import classification_report, confusion_matrix
import seaborn as sns# 모델 불러오기
model=load_model("../../src/models/01_Basic_Model/drowsiness_mediapipe_model_first.keras")test_datagen=ImageDataGenerator(rescale=1./255)
test_generator=test_datagen.flow_from_directory(
"../../data/processed/01_kaggle_dataset/cropped_dataset_Mediapipe/test",
target_size=(IMG_SIZE, IMG_SIZE),
batch_size=BATCH_SIZE,
class_mode="categorical",
shuffle=False
)
Y_pred=model.predict(test_generator)
y_pred=np.argmax(Y_pred, axis=1)
y_true=test_generator.classesFound 433 images belonging to 4 classes.
[1m28/28[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m42s[0m 1s/stepprint(classification_report(y_true, y_pred, target_names=test_generator.class_indices.keys()))
sns.heatmap(confusion_matrix(y_true, y_pred), annot=True, fmt="d", cmap="Reds")precision recall f1-score support
Closed 0.96 0.99 0.98 109
Open 0.99 0.96 0.98 109
no_yawn 1.00 0.98 0.99 109
yawn 0.98 1.00 0.99 106
accuracy 0.98 433
macro avg 0.98 0.98 0.98 433
weighted avg 0.98 0.98 0.98 433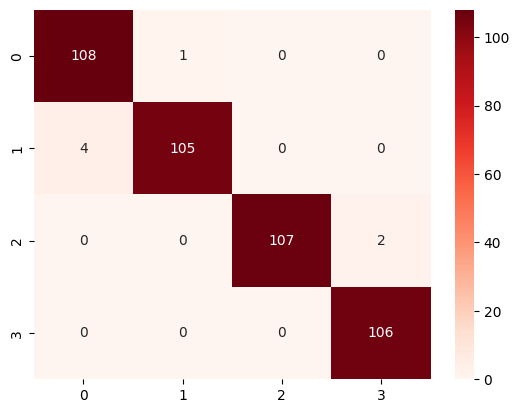
import random
X_all=[]
y_all=[]
# 전체 test 세트에서 이미지와 레이블 수집
for i in range(len(test_generator)):
x_batch, y_batch=test_generator[i]
X_all.append(x_batch)
y_all.append(y_batch)
# X_all과 y_all을 numpy 배열로 변환
X_all=np.vstack(X_all)
y_all=np.vstack(y_all)
y_true=np.argmax(y_all, axis=1)
# 이미지 크기와 배치 크기 설정
class_names=list(test_generator.class_indices.keys())
# 랜덤 10장
indices=random.sample(range(len(X_all)), 10)
selected_images=X_all[indices]
selected_labels=y_true[indices]
# 예측
pred_probs=model.predict(selected_images)
pred_labels=np.argmax(pred_probs, axis=1)
# 시각화
plt.figure(figsize=(15, 6))
for i in range(10):
plt.subplot(2, 5, i + 1)
plt.imshow(selected_images[i])
plt.axis("off")
true_label=class_names[selected_labels[i]]
pred_label=class_names[pred_labels[i]]
plt.title(f"REAL: {true_label} / PRED: {pred_label}")
plt.tight_layout()
plt.show()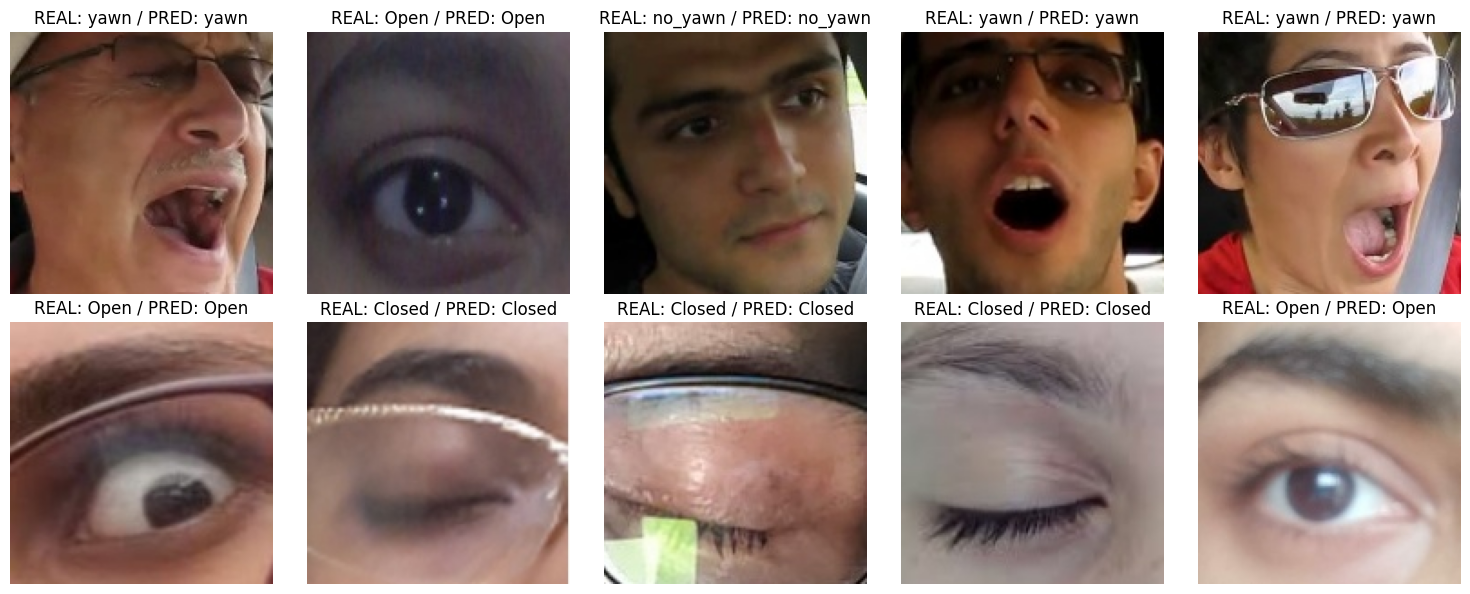
3. ❗❗ 좌절 및 깨달은 점
여기까지는 잘 나왔으나, 웹캠으로 인식해서 예측하는 과정에서 정말 아무것도 맞추지 못했다.
가만히 있어도 yawn으로 인식하고, 특히 눈을 감아도 close로 인식하지 못했다.
아무래도 데이터셋도 부족하고, 증강도 부족했다고 생각이 들었다.
그래서 데이터 수를 늘리기 위해 찾아보다 느꼈지만 흑백이미지가 굉장히 많았기 때문에 생각을 바꿨다.
- 많은 흑백 이미지를 가진 데이터셋을 이용하고, 증강으로 데이터를 더 늘린다.
- 웹캠 인식 후 흑백으로 전환한다.
또 이 과정에서 dlib으로 눈에 랜드마크를 찍고 EAR (Eye Aspect Ratio) 이라는 기법을 통해 threshold 이하로 내려가면 눈을 감았다고 인식 시키는 방법이 있다는 것을 알게 되었다.
따라서 그냥 웹캠 얼굴 인식 후 EAR을 통한다면 굉장히 쉽지만 CNN 모델 학습을 통해 예측하는 것이 목표기 때문에 이를 활용하는 방안에 대해 좀 더 고민하게 되었다.
이번 글은 여기까지.
❗❗ 추가
이 팀 프로젝트 제외하고 개인적으로 진행하는 프로젝트가 있는데, 둘 다 지금 모델 학습에 굉장히 애를 먹고있다..
코랩 이용에도 잘 돌아갈 때가 있고, 느릴 때가 있으며, 무엇보다 할당량 때문에 답답함이 컸다.
그래서 이번 기회에 내 i7-6700 + GTX 1060 PC를 6년만에 바꾸게 되었다!
GPU 먼저 당근🥕 으로 4060ti를 구했는데 CUDA 세팅이 굉장히 복잡해서 며칠째 Toolkit 설치와 삭제를 반복하고 있다.. 멘붕이다.
또 PC 용량도 없어서 어떻게든 용량을 만들어서 설치하고, 삭제하고 반복하니 도저히 건드릴 수 없는 수준까지 왔다..😭그래서 다음 주 안으로 배송 올 반본체에 세팅을 완료해서 어서 빨리 쾌적한 환경에서 진행하고 싶다!!
좀 더 속도를 내보자!
