
DALLE를 써봤다 ㅋㅎ
Coursera의 앤드류 응의 교수님의 말씀을 토대로한 포스트입니다.
Sigmoid function, tanh function
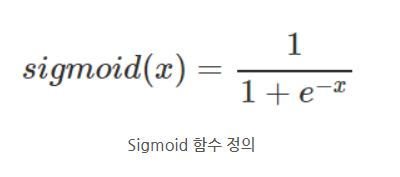
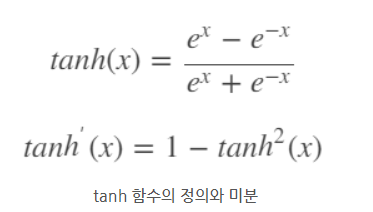
앤드류 교수님은 먼저 자신은 binary classification 문제의 output layer를 제외하고서는 sigmoid를 절대로 쓰지 않는다고 하셨다.
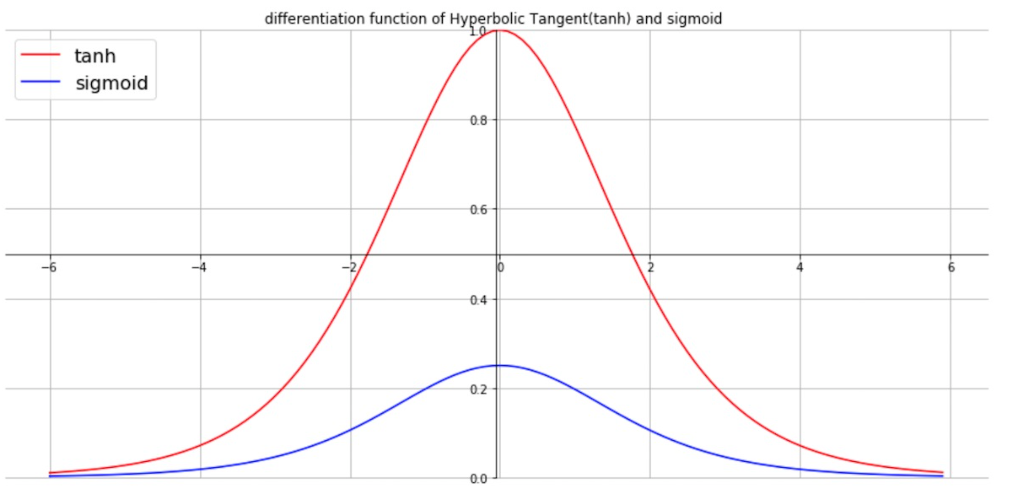
아마 tanh함수가 gradient vanishing 문제도 sigmoid에 비해 어느정도 잘 해결하고(미분의 최댓값이 1이므로) 데이터를 mean이 0에 가깝게 끔 정규화 하는 효과가 있어서 그런 것 같다.
이미지 데이터는 보통 0에서 255 사이의 픽셀 값을 가진다. 만약 이 데이터를 그대로 사용한다면, 네트워크의 입력 레이어는 매우 높은 값의 범위를 다루게 되므로 이를 해결하기 위해 데이터를 정규화하여 평균이 0에 가까워지도록 조정하는 하면 가중치 또한 더 균일하고 효율적으로 학습한다고 한다. (이 부분은 직관적으로 받아들이자)
하지만 tanh 역시 x의 값이 크거나 작아질 때 해당 함수의 미분 값이 0에 가까워지는 문제를 안고있다. (ends up with vanishing gradient)
ReLu funciton
그래서 또 고안된 activation function이 ReLu 함수이다.
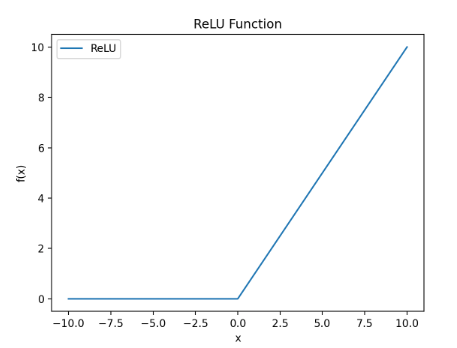
이 함수의 경우 미분값이 0또는 1로 나타나고 컴퓨터 내부에서 x값이 정확히 0값이 나올 확률은 거의 없기 때문에 0에서의 미분불가능한 값은 신경쓰지 않아도 된다고 한다. (만약 그럴 확률이 있더라도 함수 정의부분에서 예외처리를 했을듯)
"And I know that for half of the range of z, the slope for value is zero. But in practice, enough of your hidden units will have z greater than zero " -앤드류 응 교수님
앤드류 교수님은 본인이 무슨 activation function을 쓸지 고민 될 때는 그냥 ReLu 함수를 쓰라고 하신다. (Rule of thumb)
Leaky ReLu function
또 Leaky ReLu라는 함수도 있는데
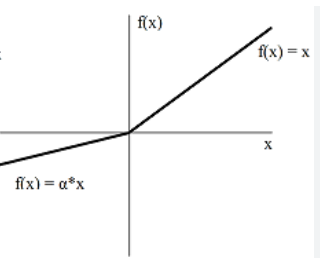
ReLU 함수보다 성능상 우수하지만, 실제 적용에서는 그다지 널리 사용되지 않는다고 하셨다.
Curiosity
ReLu함수를 쓰면 z값이 0보다 작은 unit들에 대해서는 가중치 업데이트가 이루어지지 않는데 이러한 문제는 어떻게 해결할까? 이걸 해결하려한게 Leaky Relu라면 왜 실전에서는 자주 쓰이지 않을까?
