오늘은 Overfitting을 방지하는 여러 regularization 기법들을에 대해 포스팅하려 합니다.
L2 norm
먼저 cost function뒤에 l2 norm을 더해주는 방법이 있습니다.
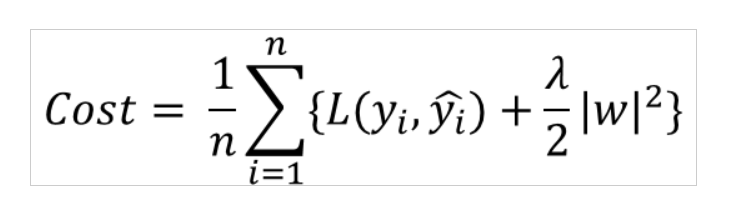
위의 그림과 같이 기존의 Loss function에 lambda/2*(모든 가중치들의 제곱의 합)을 더해주고 number of example(n)로 나눠주면 됩니다.
이 항을 더 해줌으로써 weight의 크기가 지나치게 커지는 것을 제한하여 overfitting을 방지할 수 있습니다.
고차다항식의 계수가 클때 high variance problem이 나타났던 걸 기억합시다.
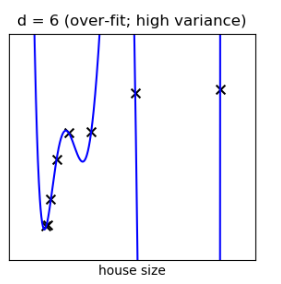
l2 norm이 추가된 cost function은 backprop할 때도 고려해야할 사항임을 잊지 맙시다!
단점: 많은 lambda값을 실험해봐야한다.
Dropout
Dropout regularization은 random하게 노드들을 shut down시키는 방식입니다.
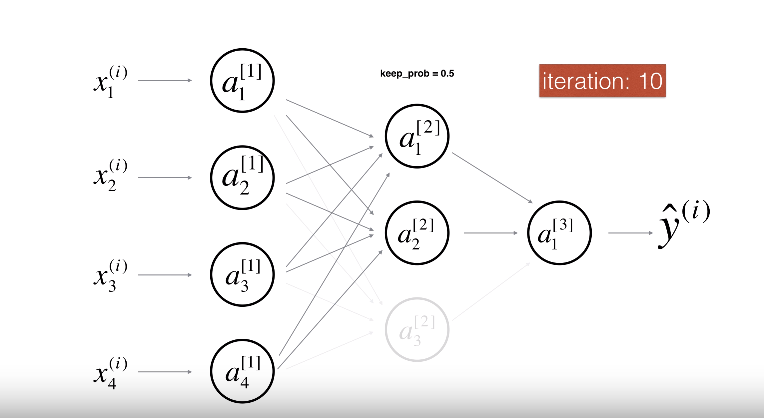
위의 그림에서 볼 수 있듯이, 'keep_prob'은 하이퍼파라미터로서, 노드가 활성 상태를 유지할 확률을 나타냅니다.
우리는 여러 노드들을 비활성화 시켜 가면서 학습을 진행함으로써 특정 뉴런에 지나치게 의존하는 것을 방지합니다. 또 모델이 더 다양한 특성 조합을 학습하게 됩니다. 이로써 모델이 더 robust 해지며 새로운 데이터에 대해 더 잘 일반화할 수 있습니다.
뉴런을 비활성화하는 것은 마치 더 작은 규모의 신경망을 훈련시키는 것과 유사한 효과를 가져옵니다. 이 방식은 모델이 훈련 데이터에 지나치게 맞춰져 발생하는 과적합을 예방하는 데 도움이 됩니다. (더 simple한 네트워크 구조를 가지므로)
Dropout regularization은 컴퓨터비전 분야에서 많이 쓰입니다. 이미지 데이터는 고차원이고 복잡하기 때문에, 이를 충분히 학습시키기 위해서는 매우 많은 양의 데이터가 필요하다는 것을 강조하고 있습니다.
(아무리 많은 데이터를 가지고 있어도 충분하지 않을 수 있다 --> 데이터 부족하다 --> Overfitting 위험 있다 --> Dropout을 통해 regularization해서 Overfitting 방지)
inverted dropout technique
training을 할때 가중치를 keep_prob으로 나눠줌으로써 scale을 유지 시키는 것.
test할때는 그대로 모든 뉴런 살린채로 한다.
Data augmentation
Data augmentation은 돌리고, 뒤집고, 밝게하는 등등 다양한 방식으로 Data수를 늘리는 방식입니다.
많은 데이터수는 Overfitting을 방지할 수 있다고 말씀드렸었죠.

early stop
early stop은 overfitting이 되기전에, 즉 development set의 error가 증가하기전에 학습을 멈추는 방법입니다.
앤드류 교수님 께서 cost function을 optimize하는 task와 overfitting을 방지하는 task는 분리되는 orthogonal한 task라 하셨습니다. (seperate set of tools)
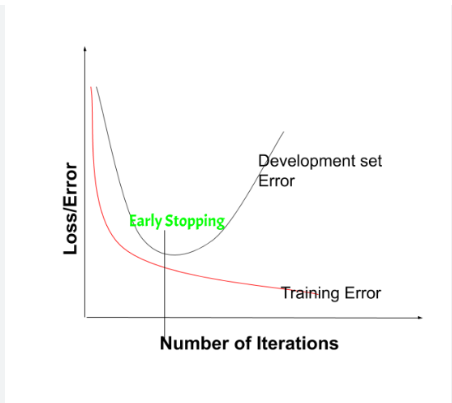
하지만 이 early stopping의 유일한 단점은 이 두가지의 task를 묶어서 본다는 것입니다.
왜냐면 일찍 학습을 끝내는 행위 자체가 cost function의 최적화를 방해하고 있기 때문입니다.
교수님은 l2 norm을 좀 더 선호하시는 것 같다.
