
Ting Chen, Simon Kornblith, Mohammad Norouzi, Geoffrey Hinton
ICML'2020
1. Introduction
기존 Visual Representation의 방법론은 크게 Generative, Discriminative 두가지로 나뉜다.
- Generative 방법론은 픽셀단위로 generation을 수행하는데, 이는 비용이 많이 들고 representation learning에 꼭 필요하지 않을 수도 있다.
- Discriminative 방법론은 원본 이미지를 변형한 후 이를 학습하는 pretext task를 수행한다.
그렇다면 Discriminative에 constrastive learning을 도입하면 어떨까? 이 방법론이 바로 SimCLR(Simple Framework for Contrastive Learning of Visual Representations)이다.
2. Method
The Contrastive Learning Framework

이 프레임워크의 구조는 다음과 같다:
- 우선 데이터 를 갖고 두 augmentation을 수행한다. 이 과정을 통해 나온 아웃풋을 로 표시한다.
- 이를 인코더 에 각각 집어넣어 representation vector를 추출한다. 해당 아웃풋을 로 표시한다. 이 논문에서는 인코더로 ResNet을 사용했다.
- 이를 projection head 에 집어넣는다. projection head는 하나의 히든 레이어로 구성된 MLP로, 로 표현된다. projection head의 존재에 대한 효용성은 이후 실험에서 증명된다.
- 마지막으로, 두 아웃풋의 결과를 비교하는 constrastive loss function을 사용해서 모델을 학습시킨다.
contrastive loss function은 다음과 같은 형태로 표현된다:
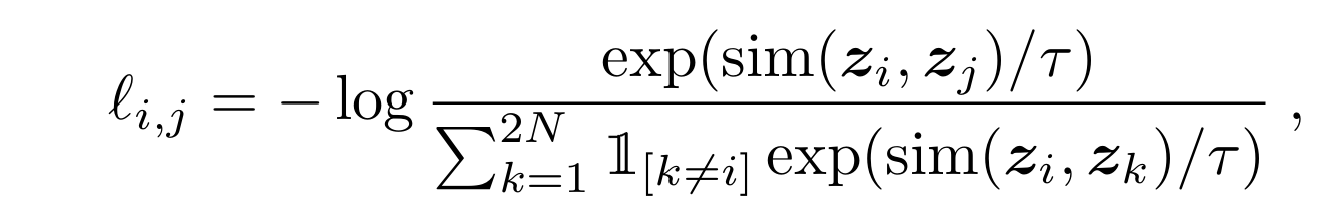
이 식의 목적은, 같은 인풋에서 파생된 positive pair 간의 similarity를 maximize하면서, 동시에 다른 인풋에서 파생된 negative pair간의 similarity를 minimize하는 것이다. 여기서 similarity는 cosine similarity를 사용한다.
식을 잘 보면 분자는 positive pair의 similarity이고 분모는 negative pair의 similarity가 포함되어 있다. 따라서 분자를 maximize함과 동시에 분모를 minimize하면 결국 loss는 줄어들게 된다.
이 loss를 논문에서는 NT-Xent(the normalized temperature-scaled cross entropy loss)라고 부른다.
Evaluation Protocol
이렇게 해서 얻은 representation을 평가하는 방법으로 linear evaluation protocol을 사용한다.
linear evaluation protocol은, 학습이 끝난 모델의 weight를 freeze하고 맨 마지막층에 linear classifier를 추가해서 fine-tuning을 하는 방식이다.
또한, 이 논문은 linear evaluation외에도 semi-supervised와 transfer learning을 사용해서 추가로 비교를 수행했다고 한다.
3. Data Augmentation for Contrastive Representation Learning
이제 augmentation에 대해 좀 더 디테일하게 알아보자.
data augmentation이 predictive task를 결정한다
기존 방식들은 특정 predictive task를 위해 모델의 아키텍처 자체를 바꾸어버린다.
예를 들면, Hjelm et al. (2018); Bachman et al. (2019)에서는 global-to-local view prediction을 위해 receptive field에 제약을 걸었고, Oord et al. (2018); Hénaff et al. (2019)에서는 neighboring view prediction을 위해 fixed image splitting procedure과 context aggregation network를 추가했다고 한다.

하지만 SimCLR는 아키텍처의 수정 없이 random cropping을 통해 이 과제들을 전부 수행할 수 있다.
data augmentation의 합성이 더 나은 성능을 보여준다

위처럼 augmentation의 종류는 여러가지가 있다.
중요한 것은, augmentation 두개를 합쳐서 수행하는 것이 하나만 수행하는 것보다 성능이 뛰어나다는 것이다.
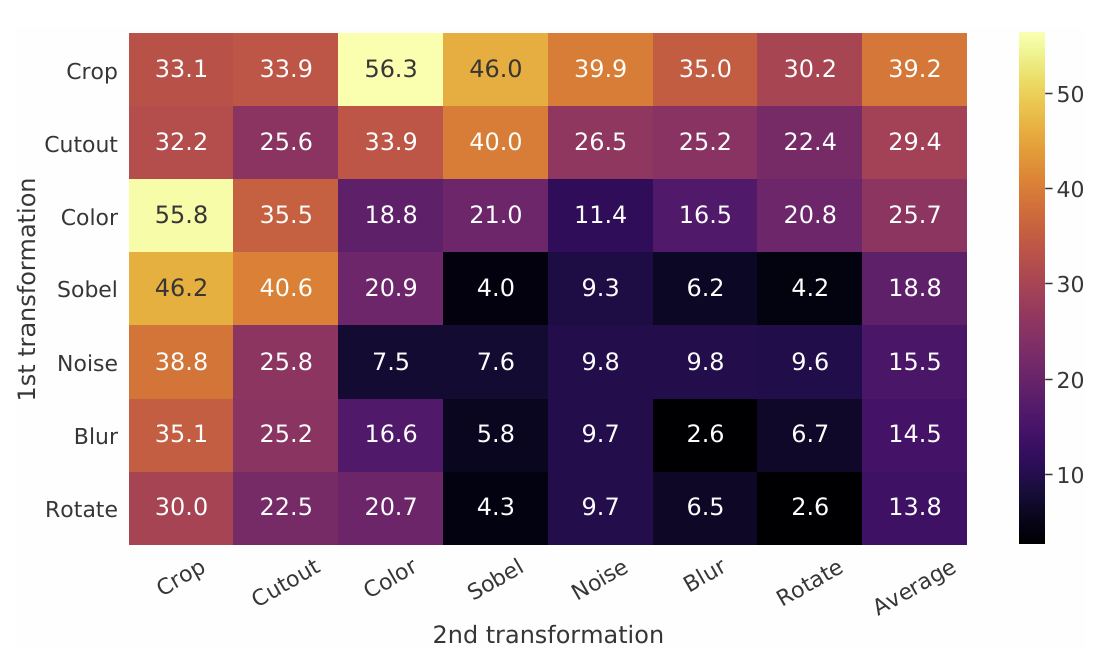
그림을 보면 대각선 부분(augmentation을 하나만 수행한 결과)의 값이 그 외 값들보다 대체로 낮은 것을 확인할 수 있다.
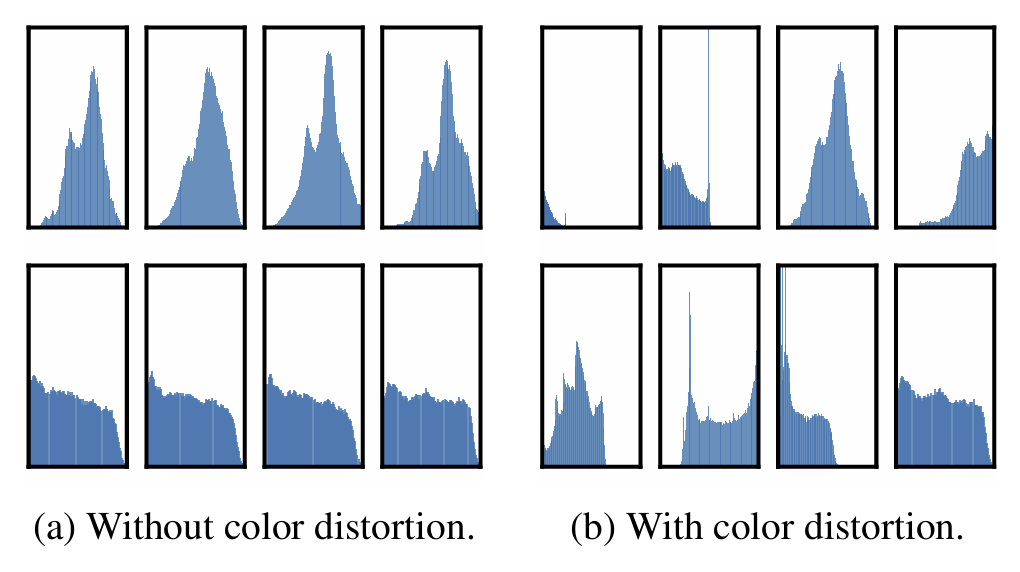
특히, crop+color의 성능이 눈에 띄는데, 보통 crop을 할 경우 color distribution이 제한되기 때문에 아래 그림처럼 이들의 차이만 보고도 두 이미지를 구별할 수 있게 된다. 하지만 color distortion을 하면 모델이 이러한 편법을 쓰지 못하도록 막아주고, 결과적으로 더욱 효과적인 학습이 가능할 수 있었다고 이 논문은 설명하고 있다.
Contrasitive learning은 더 강한 data augmentation을 필요로 한다
흥미로운 것은, 아래 표에서 보이는 것처럼, distortion이 강해질수록 SimCLR의 성능은 증가하는데, 반대로 Supervised의 성능은 감소한다는 것이다.
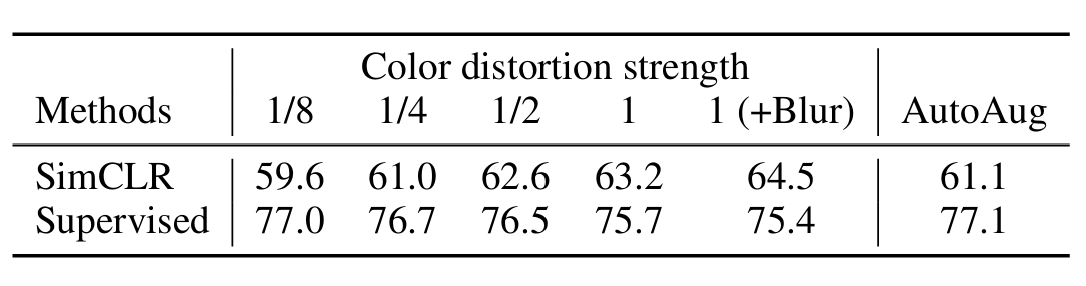
따라서 Unsupervised contrastive learning에서는 supervised보다 더 강력한 augmentation이 필요하다는 것을 알 수 있다.
4. Architectures for Encoder and Head
Unsupervised contrastive learning은 거대한 모델을 필요로 한다
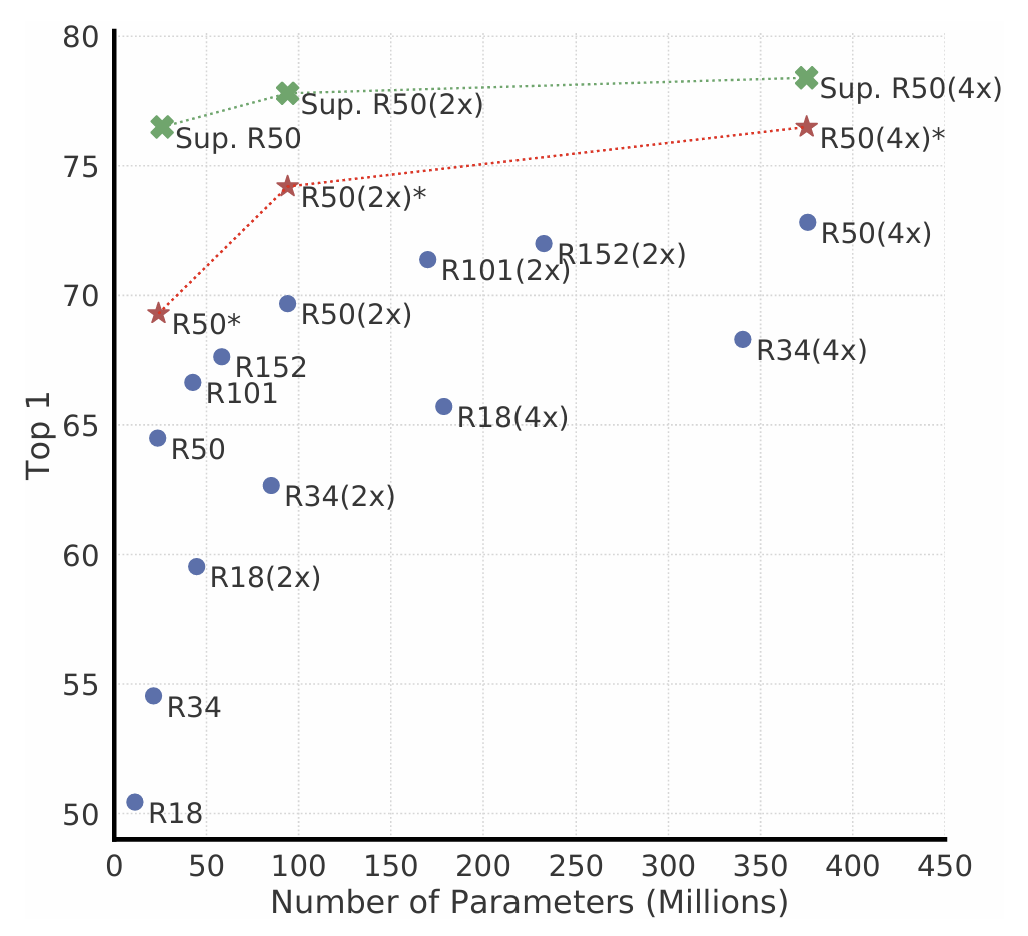
위에 그림에서 파란점은 SimCLR를 100 epochs 돌린 결과이고, 빨간 별은 1000 epochs 돌린 결과이다. 초록색 X는 supervised ResNet을 90 epochs 돌린 결과이다. 모델이 커질 수록 supervised와 unsupervised의 성능 차이가 줄어드는 것을 알 수 있다.
즉, unsupervised 모델은 사이즈가 성능에 미치는 영향력이 supervised에 비해 매우 크다는 것이다.
nonlinear projection head가 성능을 가장 향상시킨다
다음으로, projection head의 역할에 대해 분석해보자. 이 논문은 linear, nonlinear, none 이렇게 세가지 projection head를 갖고 실험을 진행했는데, 결과는 아래와 같다.

즉, projection head가 있을 때가 없을 때보다 나았으며, nonlinear가 linear보다 뛰어났다.
여기서 중요한 것은, nonlinear projection head를 사용했을 때, projection head 이전 레이어 가 projection head 이후 레이어 보다 representation 성능이 좋았다는 것이다.

이에 대해 논문은 을 하게 되면 data transformation 과정에서 정보를 잃어버리게 되어서 그렇다고 설명한다.
5. Loss Functions and Batch Size
NT-Xent가 가장 나은 결과를 보여준다
다음은 NT-Xent와 다른 loss를 비교하는 것이다.

표에서 NT-Xent의 gradient는 두가지 특징이 있다.
첫번째로, l2 normalization과 temperature-scale이 적용되어 있다. 따라서 temperature를 잘 설정해서 hard negative를 학습하는 것이 가능하다.
두번째로, negative들의 상대적 hardness를 반영한다. 다른 두 loss는 이게 없어서 semi-hard negative mining을 적용해야 한다.
semi-hard negative란 구별하기에 너무 쉽지도 않고 어렵지도 않은 적당한 난이도의 negative를 말한다.
결과적으로 아래 표를 보면, semi-hard를 적용하더라도 여전히 NT-Xent가 최고 성능을 보이고 있는 것을 확인할 수 있다.

다음으로 l2 normalization과 temperature 의 중요성을 입증해보자.
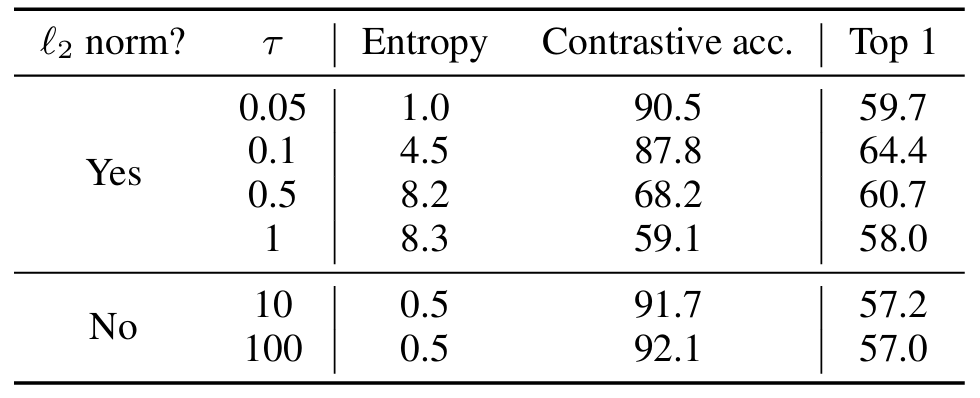
표를 보면 l2 normalization과 적절한 temperature가 성능을 향상시키고 있다.
Contrastive learning은 거대한 batch size와 epoch를 필요로 한다
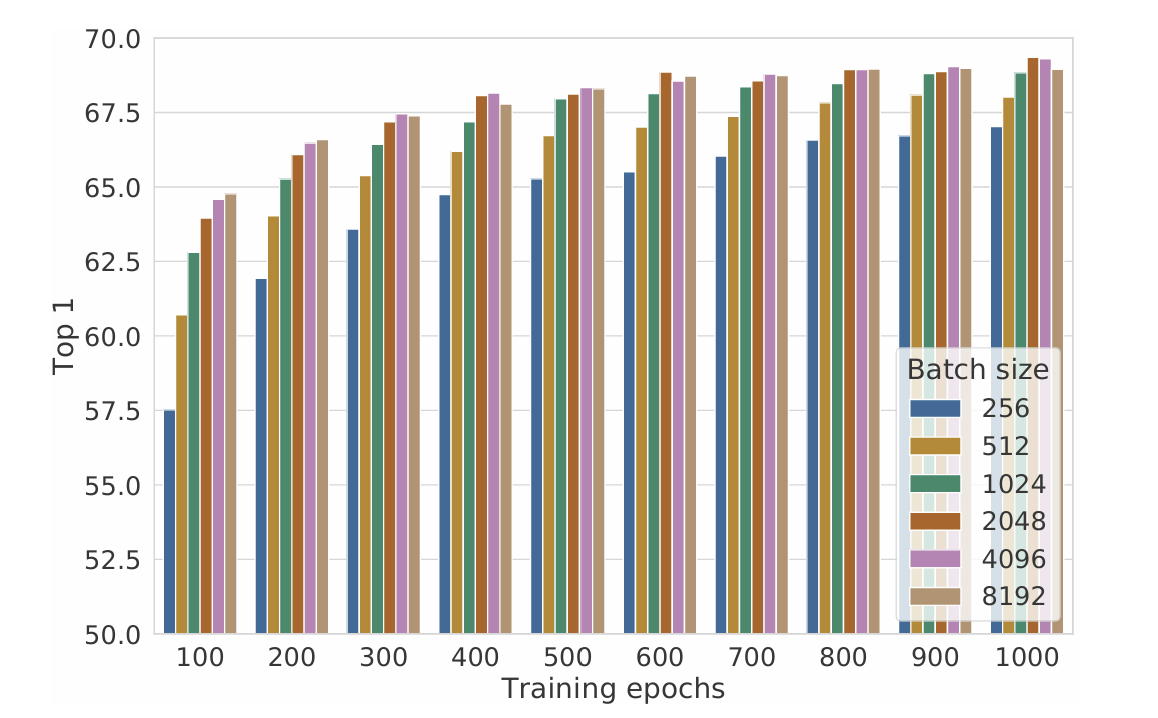
아까 모델의 사이즈가 성능에 강한 영향을 미친 것과 비슷하게, 거대한 batch 사이즈와 더 많은 epoch 수가 성능을 매우 향상시키고 있다.
6. Comparison with State-of-the-art
Linear evaluation
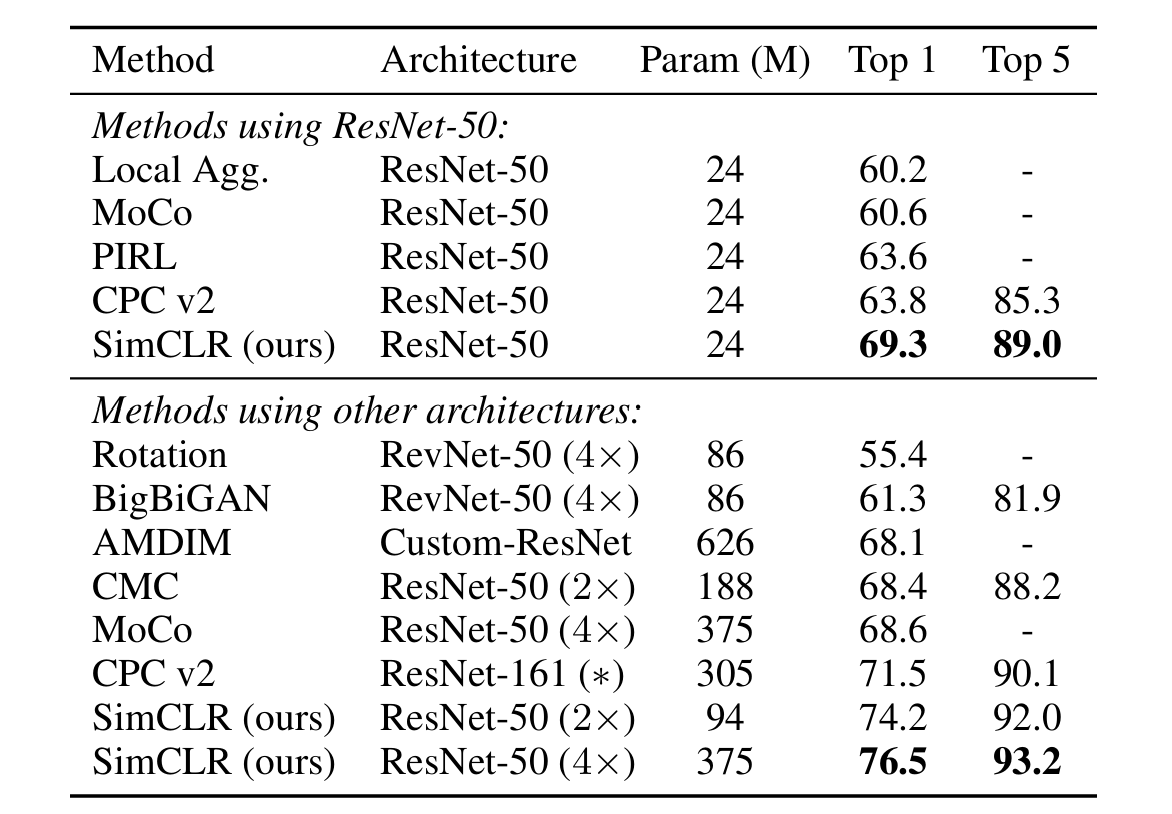
SimCLR가 성능이 제일 좋았다.
Semi-supervised learning
semi-supervised learning는 데이터중 일부만 라벨이 있는 경우를 말한다. 여기서는 모델을 학습시킨 후 트레이닝 데이터셋 중 1% 혹은 10%를 라벨과 함께 샘플링해서 이를 갖고 fine-tuning을 수행했다. 결과는 아래와 같다.

마찬가지로 SimCLR가 가장 뛰어났다.
Transfer learning
transfer learning은 학습 task와 다른 새로운 task를 수행하는 것을 말한다.

이때 SimCLR는 supervised보다도 대체로 성능이 뛰어났다.
*related work는 생략
8. Conclusion
- SimCLR 프레임워크는 self-supervised, semi-supervised, transfer learning 모두의 경우에서 기존 방법들의 성능을 상당히 개선했다.
- SimCLR는 기존 supervised learning과 비교했을 때 data augmentation, nonlinear head, loss function만 다를 뿐 매우 간단한 구조를 갖고 있음에도 상당한 강점을 보여주었다.
