Unsupervised Learning
- Most of this course focuses on
supervised learningmethods such as regression and classification - In that setting we observe obth a set of features for each object, as well as a response or outcome variable
- The goal is then to predict using
- Here we instead focus on
unsupervised learning, we where observe only the features - We are not interested in prediction, because we do not have an associated response variable
The Goals of Unsupervised Learning
- The goal is to discover interesting things about the measurements :
is there an informative way to visualize the data? - Can we discover subgroups among the variables or among the observations?
- We discuss two methods
principal components analysis
A tool used for data visulization or data pre-processing before supervised techniques are appliedclustering
A broad class of methods for discovering unknown subgroups in data
Principal Components Analysis
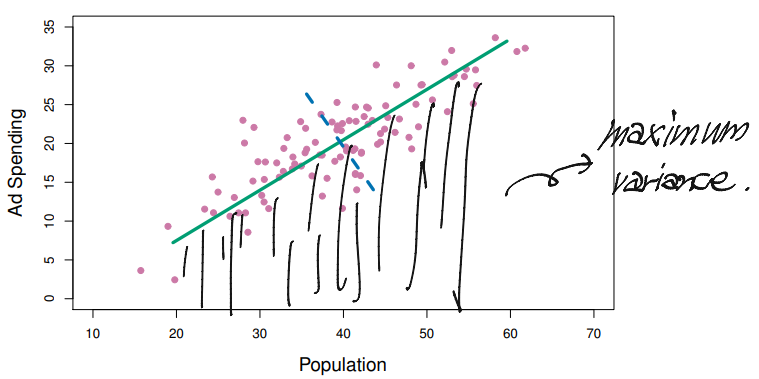
PCAproduces alow-dimensionalrepresentation of a dataset- If finds a sequence of linear combinations of the variables that have maximal variance, and are mutually uncorrelated
- Apart from producing derived variables for use in supervised learning problems,
PCAalso serves as a tool for data visulization - The
first principal componentsof a set of features is the normalized linear combination of the featuresthat has the largest variance. Bynormalized, we mean that - We refer to the elements as the loadings of the first principal component; together, the loadings make up the
principal component loading vector - We constrain the loadings so that their sum of squares is equal to one, since otherwise setting these elements to be arbitrarily large in absolute value could result in an arbitrarily large variance
Computation of Pricinpal Components
- Suppose we have a data set
- Since we are only interested in variance, we assume that each of the variables in has been centered to have mean zero (that is, the column means of are zero)
- We then look for the linear combination of the sample feature values of the formfor that has largest sample variance, subject to the constraint that
- Since each of the has mean zero, then so does (for any value of
- Hence the sample variance of the can be written as
- Plugging in (1) the first principal component loading vector solves the optimization problem
- This problem can be solved via a singular-value decomposition of the matrix , a standard technique in linear algebra
- We refer to as the first principal component, with realized values
Geometry of PCA
- The loading vector with elements defines a direction in feature space along which the data vary the most
- If we project the data points onto this direction, the projected values are the principal component scores themselves
Further principal components
- The second principal component is the linear combination of that has maximal variance among all linear combinations that are
uncorrelatedwith - The second principal component scores take the formwhere is the second principal component loading vector, with elements
- It turns out that constraining to be uncorrelated with is equivalent to constraining the direction to be orthogonal (perpendicular) to the direction And so on
- The principal component directions are the ordered sequence of right singular vectors of the matrix , and the variance of the components are times the squares of the singular values
- There are at most principal components
PCA should be performed after standardization
PCA find the hyperplane closest to the observations
- The first principal component loading vector has a very special property : it defines the line in -dimensional space that is
closestto the observations (using averae squared Euclidean distance as a measure of closeness) - The notion of principal components as the dimensions that are closest to the observations extends beyond just the first principal component
- For instance, the first two principal components of a data set span the plan that is closest to the observations, in terms of average squared Euclidean distance
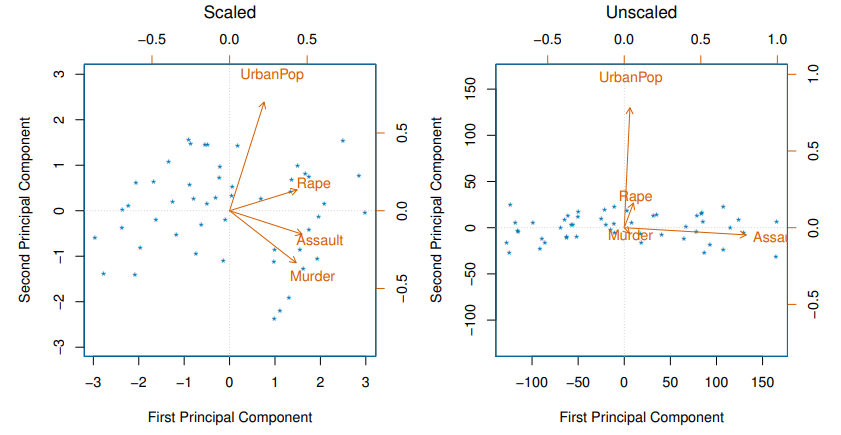
Scaling of the variables matters
- If the variables are in different units, scaling each to have standard deviation equal to one is recommended
- If they are in the same units, you might or might not scale the variables
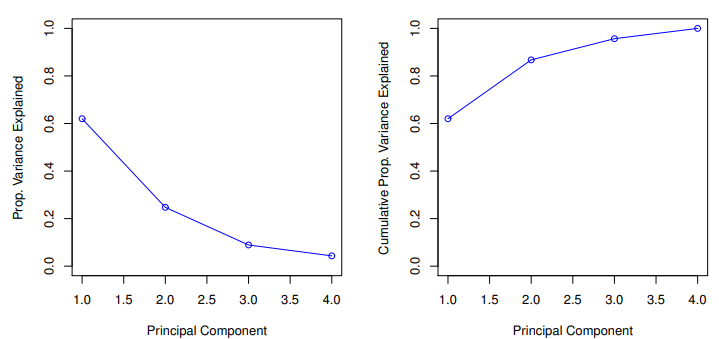
Proportion Variance Explained
- To understand the strength of each component, we are interested in knowing the proportion of variance explained (PVE) by each one
- The
total variancepresent in a data set (assuming that the variables have been centered to have mean zero) is defined asand the variance explained by the th principal component is - It can be shown that
- Therefore, the
PVEof the th principal component is given by the positive quantity between and - The
PVEs sum to one - We sometimes display the cumlative
PVEs
How many principal components should we use?
- If we use principal components as a summary of our data, how many components are sufficient?
- No simple answer to this question, as cross-validation is not available for this purpose
- Why not?
- When could we use cross-validation to select the number of components?
- the
scree ploton the previous slide can be used as a guide : we look for anelbow
- No simple answer to this question, as cross-validation is not available for this purpose
Matrix Completion via Principal Components
- We pose instead a modified version of the approximation criterion
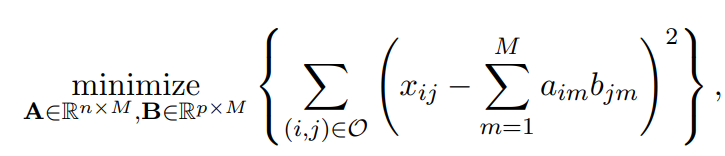
where is the set of allobservedpairs of indices a subset of the possible pairs - Once we solve this problem :
- we can estimate a missing observation using , where and are the and elements of the solution matrices and
- we can (approximately) recover the principal component scores and loadings, as if data were complete
Iterative Algorithm for Matirx Completion
Initialize: create a complete data matrix by filling in the missing value susing mean imputationRepeat: step (a)-(c) until the objective in (c) fails to decreases- (a)
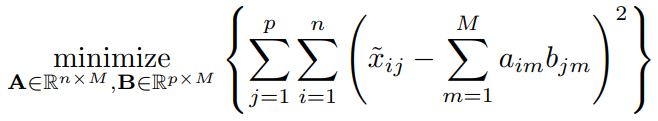
by computing the principal components of - (b) For each missing entry set
- (c) Compute the objective
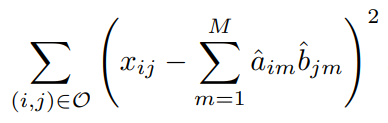
- (a)
- Return the estimated missing entries
Clustering
K-means clustering
- Note that there is
no ordering of the clusters, so thatcluster coloring is arbitrary - Let denotes sets containing the indices of the observations in each cluster
- These sets satisfy two properties
- . In other words, each observation belongs to at least one of the clusters
- for all
In other words, the clusters are non-overlapping : no observation belongs to more than one cluster
- For instnace, if the th observation is in the th cluster, then
- The idea begind -means clustering is that a good clustering is one for which the
within-cluster variationis as small as possible - The within-cluster variation for cluster is a measure of the amount by which the observations within a cluster differ from each other
- Hence we wnat to solve the problem
- In words, this formula says that we want to partition the observation into clusters such that the total within-cluster variation, summed over all clusters, is as small as possible
How to define within-cluster variation
- Typically we use Euclidean distancewhere denotes the number of observations in the th cluster
- Combining (2) and (3) gives the optimization problem that define -means clustering
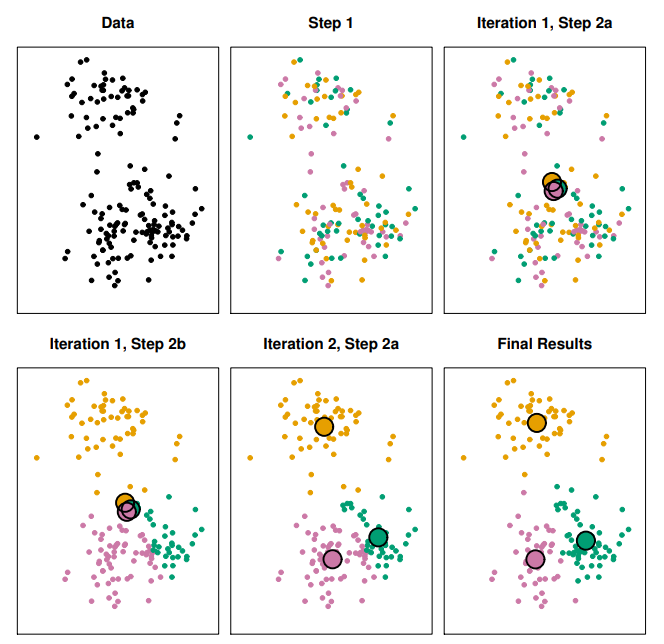
K-Means Clustering Algorithm
- Randomly assign a number, from to , to each of the observations. These serve as initial cluster assignments for the observations
- Iterate until the cluster assignments stop changing
2.1. For each of the clusters, compute the clustercentroid. The th cluster centroid is the vector of the feature means for the observations in the th cluster
2.2. Assign each observation to the cluster whose centroid is closest (whereclosestis defined using Euclidean distance)
Properties of the Algorithm
- This algorithm is guaranteed to decrease the value of the objective (4) at each step
- however it is not guaranteed to give the global minimum
Hierarchical Clustering
K-meansrequires us to pre-specify the number of clusters- We describe
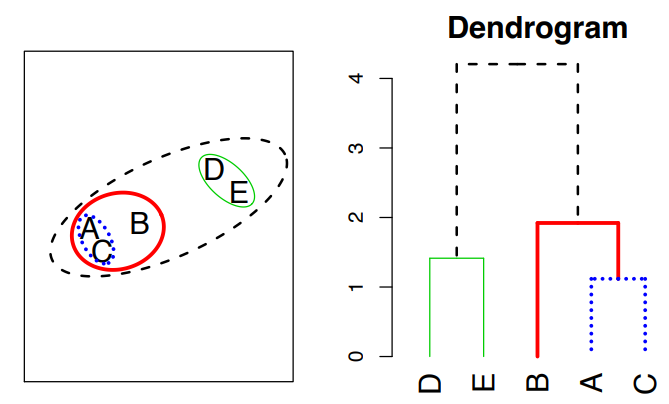
bottom-uporagglomerativeclustering - The approach in words :
- Start with each point in its own cluster
- Identify the closest two clusters and merge them
- Repeat
- Ends when all points are in a single cluster
Linkage

Choice of Dissimilarity Measure
- So far have used
Euclidean distance - An alternative is
correlation-based distancewhich considers two observations to be similar if their features are highly correlated - This is an unusual use of correlation, which is noramlly computed betwen variables; here it is computed between the observation profiles for each pair of observations
Practical issues
Scaling of the variable matters- Should the observations of features first be standardized in some way?
- For instance, maybe the variables should be centered to have mean zero and scaled to have standard deviation one
- In the case of hierarchical clustering,
- What dissimilarity measure should be used?
- What type of linkage should be used?
- How many clusters to choose? ( in both K-means or hierarchical clustering)
Difficult problem
- No agreed-upon method
- Which features should we use to drive the clustering?

AI, Security