Survival Analysis
Survival analysisconcerns a special kind of outcome variable : the time until an event occurs- For example, suppose that we have conducted a five-year medical study, in which patients have been treated for cance
- We would like to fit a model to predict patient survival time, using features such as baseline health measurements or type of treatment
- Sounds like a
regression problem. But there is an important complication : some of the patients have survived until the end of the study. Such a patient's survival time is said to becensored - We do not wnat to discard this subset of surviving patients, since the fact that they survived at least five years amounts to valuable information
Non-medical Examples
- The applications of survival analysis extend far beyond medicine. For example, consider a company that wishes to model
churn, the event when customers cancel subscription to a service - The company might collect data on customers over some time period, in order to predict each customer's time to cancellation
- However, presumably not all customers will have cancelled their subscription by the end of this time period; for such customers, the time to cancellation is censored
Survival analysisis a very well-studied topic within statistic. However, it has received relatively little attention in the machine learning community
Survival and Censoring Times
- For each individual, we suppose that there is a true
failureoreventtime , as well as a true censoring time - The
survival timerepresents the time at which the event of interest occurs (such as death) - By contrast, the
censoringis the time at which censoring occurs: for example, the time at which the patient drops out of the study or the study ends
- We observe either the survival time or else the censoring time . Specifically, we observe the random variable
- If the event occurs before censoring (i.e. ) then we observe the true survival time ; if censoring occurs before the event () then we observe the censoring time. We also observe a status indicator
- Finally, in our dataset we observe paris , which we denote as
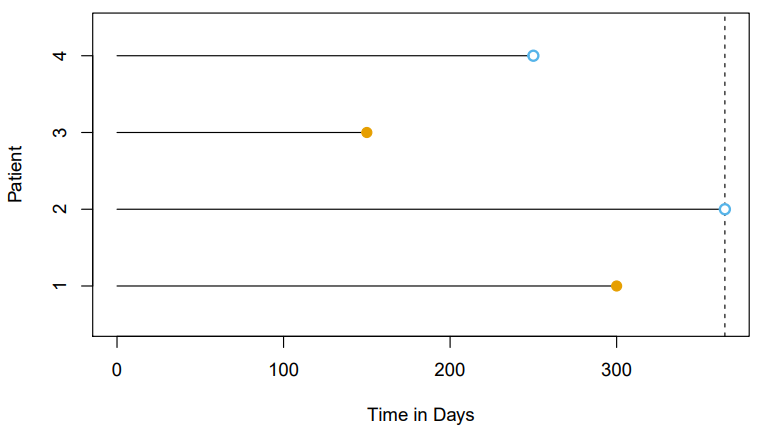
- Here is an illustration of censored survival data
- For patients and , the event was observed
- Patient was alive when the study ended
- Patient dropped out of the study
A Closer Look at Censoring
- Suppose that a number of patients drop out of a cancer study early because they are very sick
- An analysis that does not take into consideration the reason why the patients dropped out will likely overestimate the true average survival time
- Similarly, suppose that males who are very sick are more likely to drop out of the study than females who are very sick
- Then a comparison of male and female survival times may wrongly suggest that males survive longer than females
- In general, we need to assume that, conditional on the features, the event time is
independentof the censoring time - The two examples above violate the assumption of independent censoring
The Survival Curve
- The survival function ( or curve) is defined as
- This decreasing function quantifies the probability of surviving past time
- For example, suppose that a company is interested in modeling customer churn
- Let represent the time that a customer cancels a subscription to the company's service
- Then represents the probability that a customer cancels later than time
- The larger the value of , the less likely that the customer will cancel before time
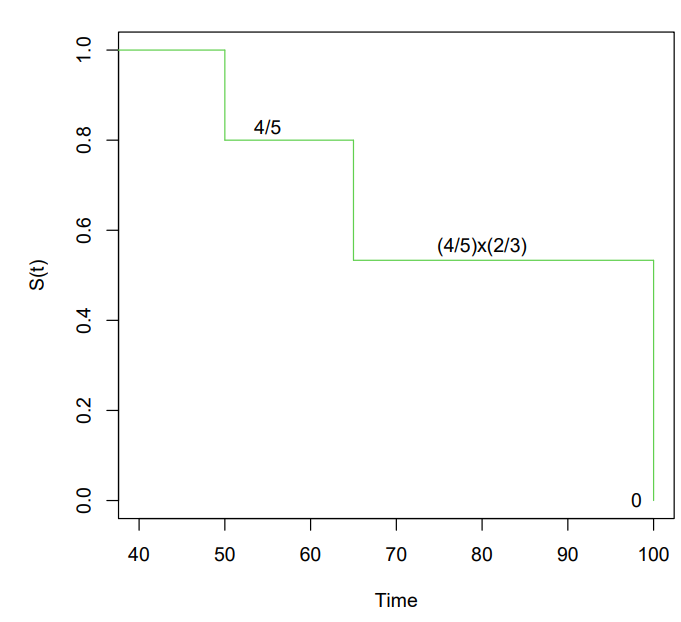
Estimating the Survival Curve
- Consider the
BrainCancerdataset, which contains the survival times for patients with primary brain tumors undergoing treatment with stereotactic radiation methods - Only of the patients were still alive at the end of the study
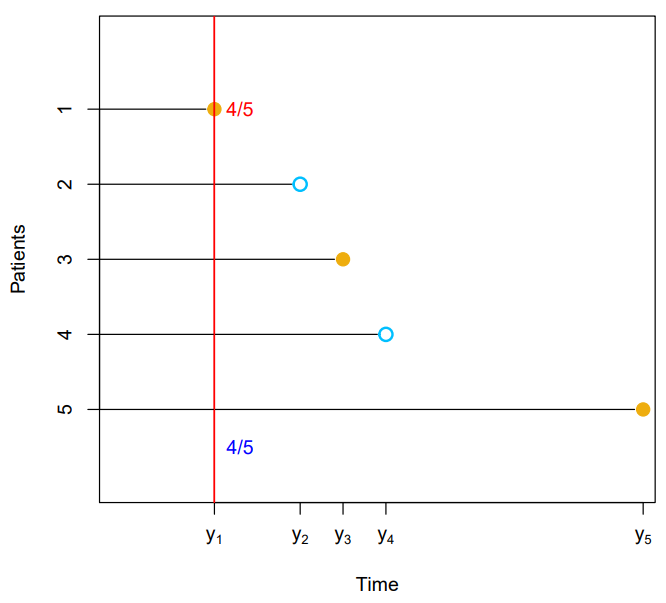
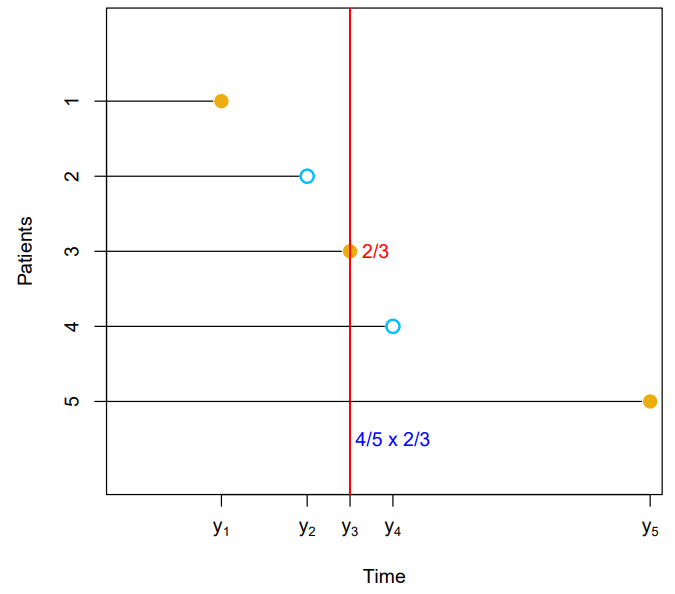
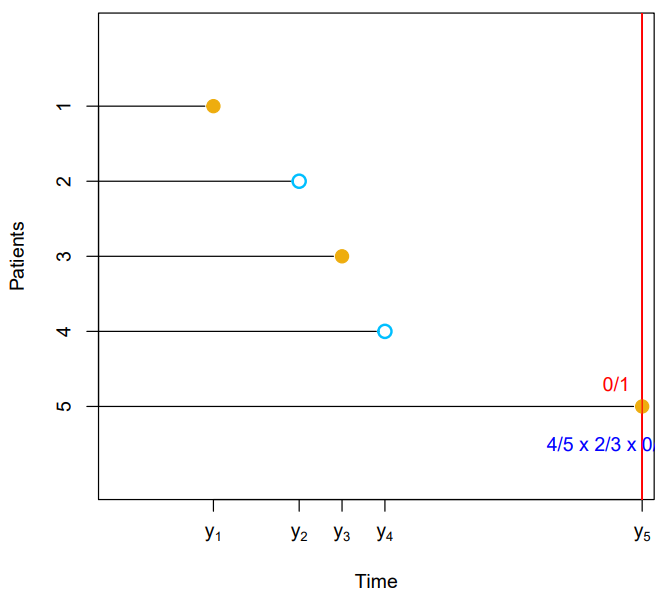
- Suppose we'd like to estimate , the probability that a patient survives for at least months
- It is tempting to simply compute the proportion of patients who are known to have survived past months, that is, the proportion of patients for whom
- This turns out to be or approximately
- However, this does not seem quite right : of the patients who did not survive to months were actually censored, and this analysis implicitly assumes they died before months
- Hence it is probably an underestimate
 |  |  |
|---|
Kaplen-Meier Survival Curve
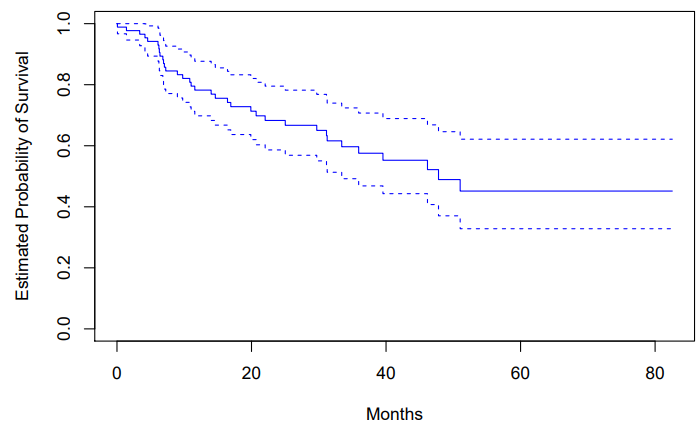
- Each point in the solid step-like curve shows the estimated probability of surviving past the time indicated on the horizontal axis
- The estimated probability of survival pas months is , which is quite a bit higher than the naive estimate of presented earlier
The Log-Rank Test
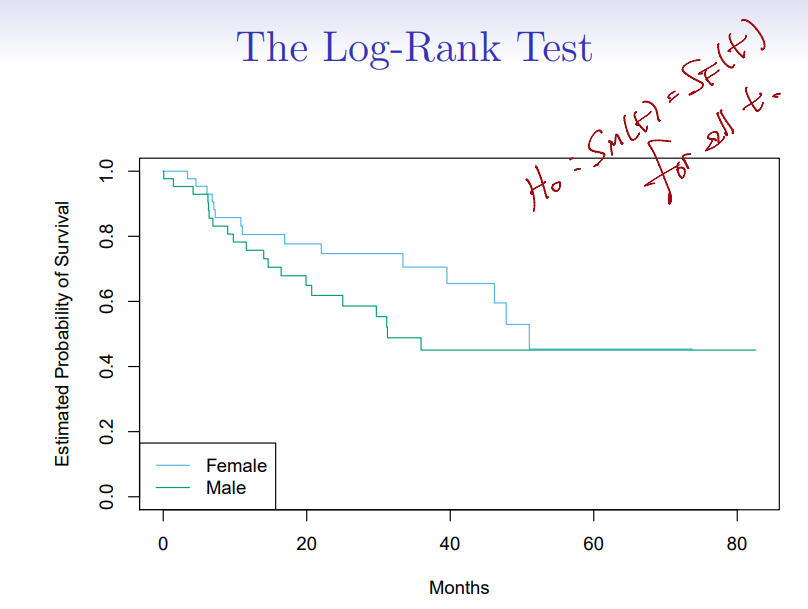
- We wish to compare the survival of males to that of females
- Shown are the
Kaplan-Meiersurvival curves for the two groups - Females seem to fare a little better up to about months, but then the two curves both level off to about
- How can we carry out a formal test of equality of the two survival curves?
- At first glance, a two-sample -test seems like an obvious choice : but the presence of censoring again creates a complication
- To overcome this challenge, we will conduct a
log-rank test
- Recall that are the unique death times among the
non-censored patients, is the number of patients at risk at time , and is the number of patients who died at time - We further define and to be the number of patients in groups and , respectively, who are at risk at time
- Similarly, we define and to be the number of patients in groups and , respectively, who died at time
- Note that and
Details of the Test Statistic
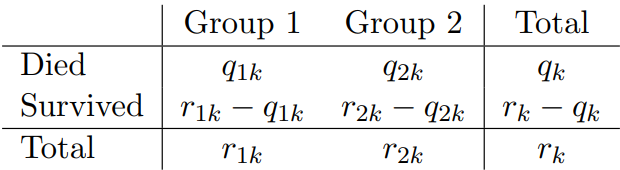
- At each death time , we construct a table of counts of the form shown above
- Note that if the death times are unique (i.e. no two individuals die at the same time), then one of and equals one, and the other equals zero
- To test for some random variable , one approach is to construct a test statistic of the formwhere and are the expectation and variance, respectively, of under
- In order to construct the
log-ranktest statistic, we compute a quantity that takes exactly the form above, with , where is given in the top left of the table above
- The resulting formula for the log-rank test statistic is
- When the sample size is large, the
log-rank teststatistic has approximately a standard normal distribution - This can be used to compute a -value for the
null hypothesisthat there is no difference between the survival curves in the two groups
- Comparing the survival times of females and males on the
BrainCancerdata gives alog-rank test statisticofwhich corresponds to a two-sided -value of
Then, can not rejectnull hypothesis
Regression Models with a Survival Response
- We now consider the task of fitting a regression model to survival data
- We wish to predict the true survival time
- Since the observed quantity is positive and may have a long right tail, we might be tempted to fit a linear regression of on
- But
censoringagain creates a problem - To overcome this difficulty, we instead make use of a sequential construction, similar to the idea used for the
Kaplain-Meiersurvival curve
The Hazard Function
- The
hazard functionorhazard rate- also known as theforce of mortality- is formally defined aswhere is the (true) survival time - It is the death rate in the instant after time , given survival up to that time
- The hazard function is the basis for the
Proportional Hazards Model
The Proportional Hazards Model
- The proportional hazards assumprion states thatwhere is an
unspecified function, known as thebaseline hazard - It is the hazrard function for an individual with features
- The name
proportional hazardsarises from the fact that the hazard function for an individual with feature vector is some unknown function times the factor - The quantityis called the
relative riskfor the feature vector , realtive to that the feature vector - What does it mean that the baseline hazard function is unspecified
- Basically, we make no assumption about its functional form
- We allow the instantaneous probability of death at time , given that one has survived at least until time , to take any form
- This means that the hazard function is very flexible and can model a wide range of relationships between the covariates and survival time
- Our only assumption is that a one-unit increase in corresponds to an increase in by a factor of
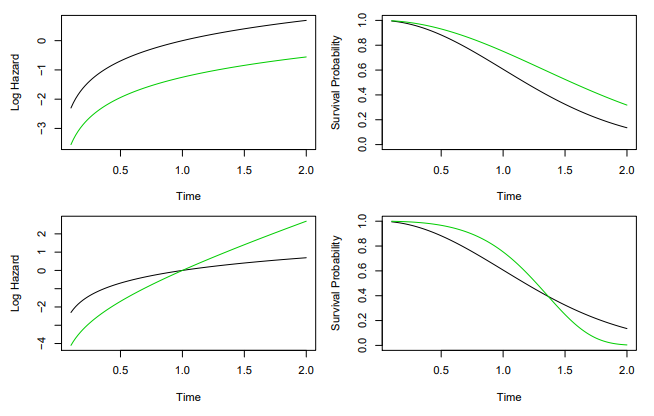
- Here is an example with and a binary covariate
Top row: the log hazard and the survival function under the model are shown (green for and black for ). Because of the proportional hazards assumption, the log hazard functions differ by a constant, and the survival functions do not crossBottom row: the proportional hazards assumptions does not hold
Partial Likelihood
- Because the form of the baseline hazard is unknown, we cannot simply plug into the likelihood and then estimate by maximum likelihood
- The magic of
Cox's proportional hazard modellies in the fact that it is in fact possible to estimate without having to specify the form of - To accomplish this, we make use of the same
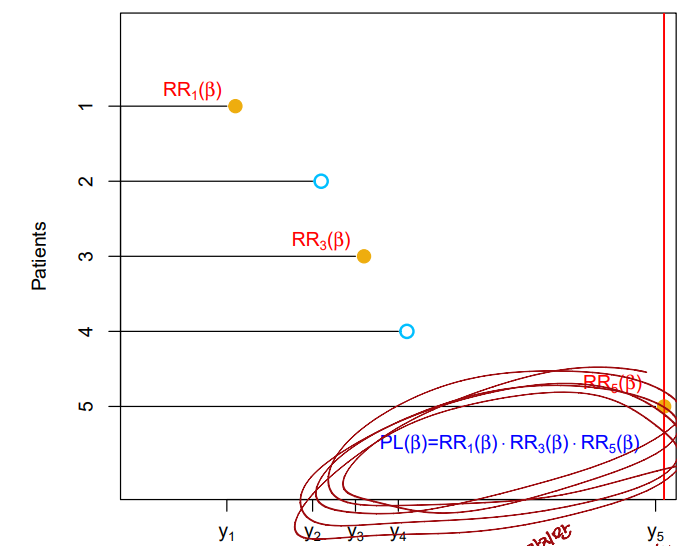
sequential in timelogic that we used to derive theKaplan-Meiersurvival curve and the log-rank test - Then the total hazard at failure time for the at-risk observations is
- Therefore, the probability that the th observation is the one to fail at time (as opposed to one of the other observations in the risk set) is
- Notice that the unspecified baseline hazard function cancels out of the numerator and denominator
- The partial likelihood is simply the product of these probabilities over all of the
uncensored observations - Critically, the partial likelihood is valid regardless of the true value of , making the model very flexible and robust
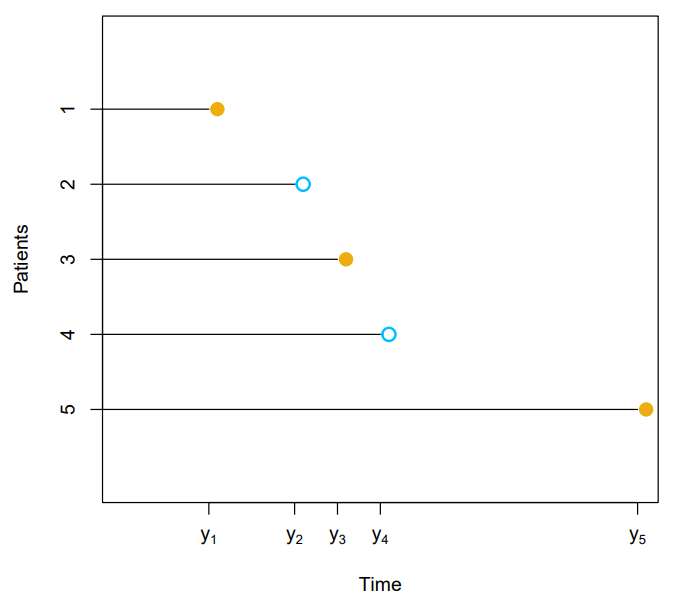
Relative Risk Functions at each Failure Time
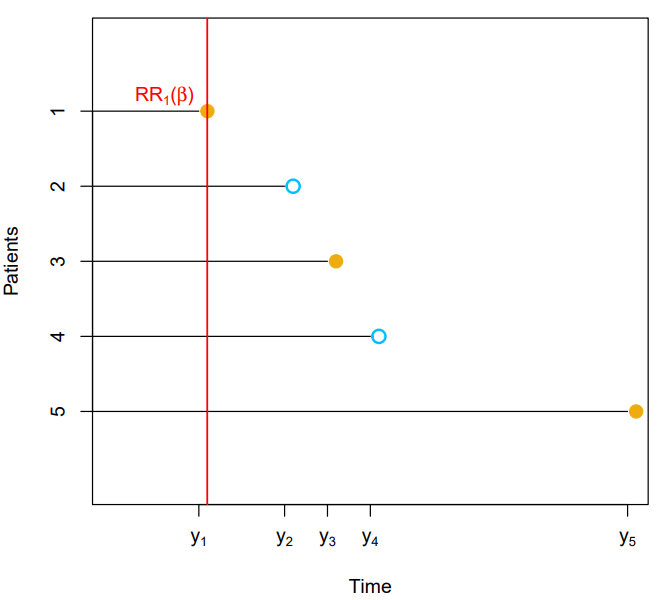 | 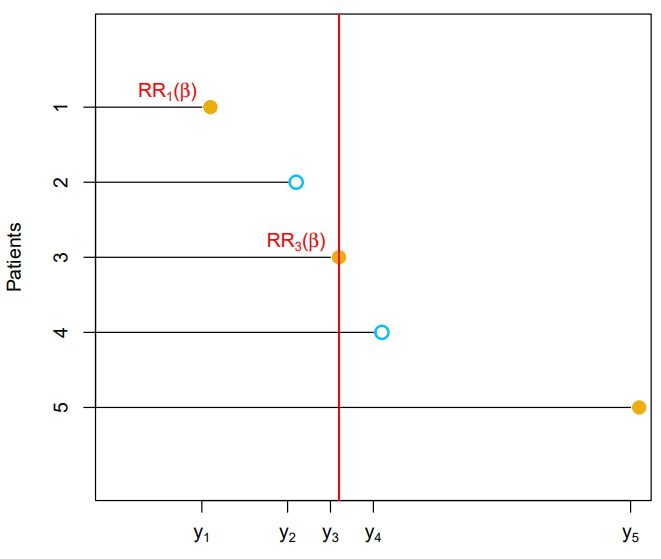 |  |
|---|

AI, Security