유방암 데이터셋
CIFAR-10 데이터셋
ensemble
여러개의 분류 모델을 조합하여 더 나은 성능을 내는 방법
1.Voting
서로 다른 알고리즘을 가진 여러개의 분류기가 투표를 통해 최종 예측 결과를 결정하는 방식
- 하드보팅 : 다수결로 최종 class 선정
- 소프트보팅 : classifier들의 class 확률을 평균하여 결정
유방암 데이터셋 실습
KNN, 로지스틱 회귀로 Voting을 만들어 비교
코드실습
import pandas as pd
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
cancer = load_breast_cancer()
df = pd.DataFrame(cancer.data, columns=cancer.feature_names)
lr_clf = LogisticRegression(solver="liblinear")
knn_clf = KNeighborsClassifier(n_neighbors=8)
vo_clf = VotingClassifier(estimators=[("LR", lr_clf), ("KNN", knn_clf)], voting="soft")
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, test_size=0.2, random_state=999)
classifiers = [vo_clf, lr_clf, knn_clf]
for classifier in classifiers:
classifier.fit(X_train, y_train)
pred = classifier.predict(X_test)
name = classifier.__class__.__name__
print(f"{name} 정확도 : {accuracy_score(y_test, pred)}")
1.Bagging
같은 유형의 알고리즘을 가진 여러개의 분류기가 투표를 통해 최종 예측 결과를 결정하는 방식
- 배깅의 가장 대표적인 예는 ‘랜덤포레스트’
유방암 데이터셋 실습
배깅의 가장 대표적인 예는 ‘랜덤포레스트’
코드실습
cancer = load_breast_cancer()
np.random.seed(9)
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, stratify=cancer.target)
params = {'n_estimators': [100], 'max_depth': [6, 8, 10, 12], 'min_samples_leaf': [8, 12, 18],
'min_samples_split': [8, 16, 20]}
clf = RandomForestClassifier(n_estimators=100)
grid_clf = GridSearchCV(clf, param_grid=params, cv=2, n_jobs=-1) # -1 은 cpu를 다 쓴다는 의미
grid_clf.fit(X_train, y_train)
print(f"최적의 파라미터\n{grid_clf.best_params_}")
print(f"최고 예측 정확도: {grid_clf.best_score_}")
CNN
CIFAR-10 데이터셋 ANN 실습
- 50,000개의 학습 데이터, 10,000개의 테스트 데이터로 구성
- 데이터 복잡도가 MNIST보다 훨씬 높은 특징이 있음
- 신경망이 특징을 검출하기 어려움
코드 실습
1.데이터 불러오기
import numpy as np
from tensorflow.keras.utils import to_categorical
from keras.datasets import cifar10
from keras.models import Sequential
from keras.layers import Dense, Activation
from keras.layers import Conv2D, MaxPooling2D, Flatten
from google.colab.patches import cv2_imshow
# CIFAR-10 Dataset 가져오기
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
print('x_train :', np.shape(x_train))
print('y_train :', np.shape(y_train))
print('x_test :', np.shape(x_test))
print('y_test :', np.shape(y_test))x_train : (50000, 32, 32, 3)
y_train : (50000, 1)
x_test : (10000, 32, 32, 3)
y_test : (10000, 1)
2.전처리
# Loss의 스케일 조정을 위해 0 ~ 255 -> 0 ~ 1 범위로 변경
x_train = x_train.astype('float32') / 255.0
x_test = x_test.astype('float32') / 255.0
# One-Hot Encoding
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
print('y_train :', np.shape(y_train))y_train : (50000, 10)
3-1.모델링
- 일반적인 CNN 모델로 학습
width = 32
height = 32
channel = 3
model = Sequential(name='CIFAR10_CNN')
model.add(Conv2D(filters=32, kernel_size=(3, 3), padding='same', activation='relu',
input_shape=(width, height, channel)))
model.add(Conv2D(filters=32, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(filters=64, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(Conv2D(filters=64, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(filters=128, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(Conv2D(filters=128, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(10, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])
hist = model.fit(x_train, y_train,
epochs=10,
batch_size=16,
validation_data=(x_test, y_test))
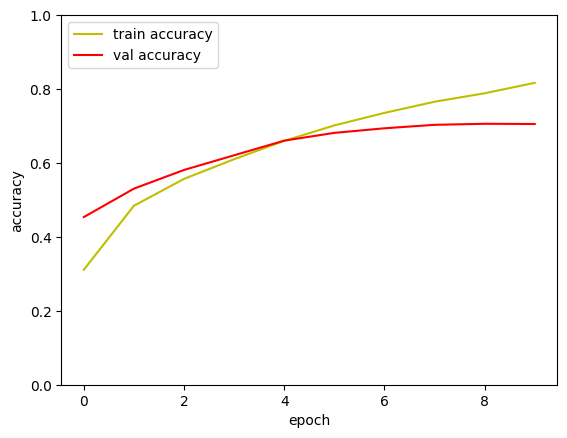
3-2.모델링
- layer 1층 추가
model = Sequential(name='CIFAR10_CNN')
model.add(Conv2D(filters=32, kernel_size=(3, 3), padding='same', activation='relu',
input_shape=(width, height, channel)))
model.add(Conv2D(filters=32, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(filters=64, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(Conv2D(filters=64, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(filters=128, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(Conv2D(filters=128, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(filters=256, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(Conv2D(filters=256, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(10, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])
hist = model.fit(x_train, y_train,
epochs=10,
batch_size=16,
validation_data=(x_test, y_test))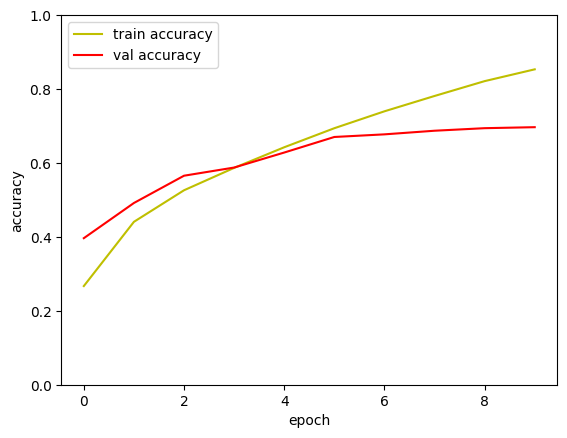
3-3.모델링
- Dropout 기법 부분 적용
model = Sequential(name='CIFAR10_CNN')
model.add(Conv2D(filters=32, kernel_size=(3, 3), padding='same', activation='relu',
input_shape=(width, height, channel)))
model.add(Conv2D(filters=32, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(filters=64, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(Conv2D(filters=64, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(filters=128, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(Conv2D(filters=128, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(filters=256, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(Conv2D(filters=256, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(10, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])
hist = model.fit(x_train, y_train,
epochs=10,
batch_size=16,
validation_data=(x_test, y_test))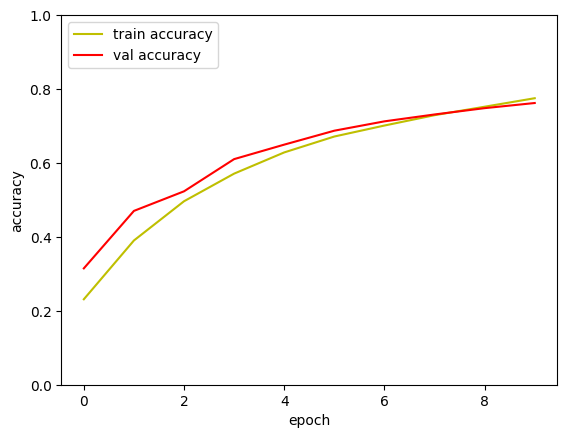
최종적으로 Train과 Val의 정확도 차이를 줄일 수 있었음
