[Paper Review]Review-driven Personalized Preference Reasoning with Large Language Models for Recommendation
Recommender System
Introduction

기존 llm을 이용한 추천시스템의 한계가 있음
1. in-context learning을 적용해서 추천 작업 수행
- 도메인 특화 학습이 부족
--> 정확도 떨어짐
- LLM fine-tuning
- 사용자 및 아이템에 대한 입력 정보가 부족함
e.g. 사용자/아이템 ID, 아이템 제목, 상호작용 이력 정도만 활용
-> 모델이 사용자의 선호도를 깊이 있게 이해하는 데 제약을 줌
--> 일반화 성능 낮아짐
- 생성되는 출력이 많이 짧음
e.g. 예/아니오, 평점(숫자)
-> 충분한 맥락이나 논리적 근거가 결여되어 정확한 예측이 어려움, 추천에 대한 설명성도 확보되지 못함
- 추천에 대한 개인화된 설명 생성 (text generate)
특정 사용자-아이템 상호작용에 대한 리뷰 텍스트를 활용하여 설명을 annotate하고, 이를 바탕으로 LLM 학습
e.g. 리뷰의 첫 문장이나 간단한 요약을 설명으로 사용함
- annotation이 실제 증거나 논리에 기반하지 않아, 관찰되지 않은 사용자-아이템 쌍에 대해 일반화 하기 어려움
- 생성된 설명 또한 신뢰성과 타당성이 부족할 수 있음
본 연구에서는 Personalized Preference Reasoning을 위해 LLM을 fine-tuning 함으로써, 평점 예측의 정확도와 추천 설명의 논리성을 동시에 향상 시키고자 함.
사용자와 아이템의 리뷰를 사용함.
리뷰: 사용자의 주관이기에 선호도에 유용하게 사용됨
리뷰에서 추출된 preference descriptions 목록인 사용자 및 아이템 프로필을 활용하여 의미 기반 이해를 도모하고, 이를 바탕으로 단계별 텍스트 추론을 수행함으로써 평점 예측과 논리적인 설명을 동시에 제공함.
-> 단계별 텍스트 추론을 위하여 성능이 뛰어난 LLM을 사용하면 좋지만, domain specific adaptation 문제와 computing source가 많이 든다는 단점이 있음
--> 본 연구에서는 knowledge distillatoin 을 사용함
1. teacher LLM (GPT-3.5)이 고품질의 text reasoning을 생성
2. student LLM (LLaMA3-8B)이 이를 학습하여 text resoning을 생성하고 이어서 평점을 예측하도록 fine-tuning
---> student LLM은 teacher LLM의 advanced reasoning capabilities를 가져서 user-iten interactoin과 preference를 더 잘 이해하게 되고, 계산비용을 감소시킴.
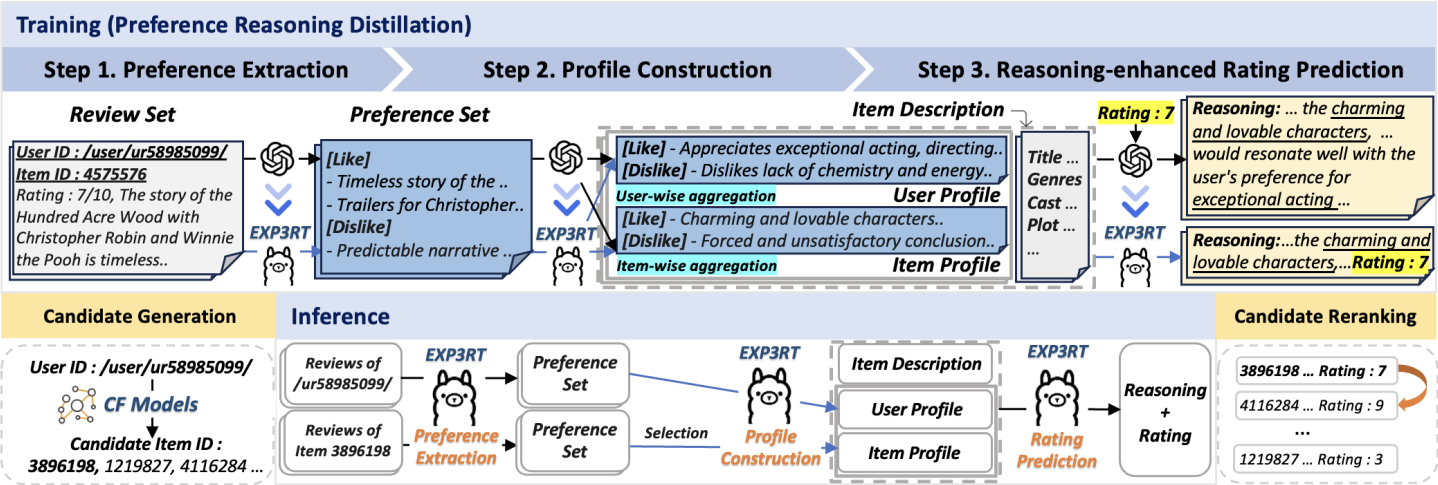
본 연구에서는 Exp3rt(EXPlainable Personalized Preference Reasoner for recommendaTion)을 제안
Exp3rt는 사용자와 아이템의 리뷰에서 파생한 prefence profile을 기반으로 평점 예측을 수행한다.
Exp3rt는 teacher-student distilation을 통해서 3step으로 fine-tuning된 student LLM임
-
선호 추출(Preference Extraction)
– 원시 리뷰에서 선호 정보를 추출해 선호 집합을 생성 -
프로필 구성(Profile Construction)
– 추출된 선호를 집계·요약해 사용자 및 아이템 프로필을 구축 -
추론 기반 평점 예측(Reasoning-enhanced Rating Prediction)
– 단계별 텍스트 추론을 통해 사용자의 평점을 예측
이러한 distilation step을 통하여 student LLM은 cost-efficient하면서도 뛰어난 추론 능력을 갖추게 됨.
추론 할 때 Exp3rt는 user/item profile(주관적 정보), item description(객관적 정보)를 함께 활용하여 선호를 종합적으로 파악함
-> 관측되지 않은 user-item 쌍에도 효과적으로 일반화 함
- 평점 예측, Top-K 추천, 설명 생성 등 다양한 측면에서 추천 실험을 하였고, Exp3rt의 효과를 검증함.
-> Exp3rt는 개인화된 preference reasing으로 평점 예측 및 reranking 정확도를 향상 시켰고, 논리적이고 이해하기 쉬운 reasoning도 제공함.
CF 모델이 생성한 후보 아이템을 multi-stage ranking pipeline에서 rerank함으로써 Top-K 추천 작업에도 기여함
The main contributions
- Exp3rt는 리뷰 기반 개인화 추론을 통해 평점 예측 정확도를 크게 향상시킴
- Exp3rt는 풍부한 선호 정보를 활용한 단계별 추론을 생성하여 신뢰할 수 있는 논리적 설명을 제공함
- Exp3rt는 독립형 추천기로도 동작할 수 있으며, CF 모델과 통합되어 multi-stage ranking pipeline에서 item reranker로 활용될 수 있음
Method
Exp3rt overall framework
학습단계
teacher LLM(GPT-3.5)의 추론 능력을 3step으로 student LLM(Llama3.8B)으로 knowledge distillatoin함.
1. raw review로 부터 preference descriptions 추출
2. preference를 aggregate해서 user/item profile ㄱ성
3. textual reasoning을 기반으로 평점 예측
추론단계
user-item pair가 주어지면 3step을 수행하여 평점을 예측함
Exp3rt는 기존의 CF기반 모델들로 효율적으로 후보 item을 검색하고, 해당 후보를 reranking하여 Top-k 추천을 위한 item reranker로 사용가능 하다.
Preliminaries
Rating predictoin
사용자 집합 U와 아이템 집합 I가 주어졌을 때, 사용자와 아이템 간 상호작용으로 구성된 데이터셋을 수집 (이 데이터셋은 사용자가 아이템에 남긴 평점(R)과 리뷰(V)를 포함)
평점 예측의 목적은, 관측된 평점 R과 리뷰 V를 바탕으로 사용자-아이템 쌍 (u, i)에 대한 평점 r_u,i을 예측하는 것 임.
rhat_u,i를 도출하여 관측되지 않은 사용자-아이템 쌍에 대해 예측할 수 있어야 하고, 사전 정의된 평점 스케일 S내에 있어야 함.
Knowledge distillation from teacher to student LLM.
GPT-3.5와 같은 LLM은 뛰어난 추론 능력을 보여주지만, 인컨텍스트 학습만으로는 추천 작업에 한계가 있음. 본 연구에서는 이처럼 뛰어난 LLM의 강점을 보다 비용 효율적인 모델로 지식 증류함으로써, 핵심 능력은 유지하면서 계산 효율성을 최적화함.
우리는 GPT-3.5를 teacher LLM으로 사용함. student LLM은 LLaMA3-8B를 기반으로 하며, teacher LLM으로부터의 distillation을 통해 성능이 향상됨
지식 증류는 주로 두 단계로 구성됩니다
- 교사 LLM에 프롬프트를 입력해 고품질 출력을 생성하고, 이를 학습 데이터로 구축
- 생성된 데이터를 사용해 학생 LLM을 지도 학습 방식(supervised fine-tuning)으로 학습
-> 학생 LLM이 다양한 작업에서 효과적으로 작동하면서도 자원 소모를 줄일 수 있음
Preference Extraction from Reviews
Step1.
raw review로 부터 핵심 선호 정보를 추촐하여 구조화된 형식으로 정리.
raw review는 noise가 껴있을 가능성이 높음 -> LLM이 이해하기 어려움
--> preference descriptions list 형태로 정리
preference description은 user의 취향을 like/dislike로 구분하여 표현
교사 LLM의 선호 추출 능력을 증류하기 위해, 입력 리뷰 vv에 대해 교사 LLM에 프롬프트를 입력해 “좋음/싫음” 정보를 추출하게 하여 선호 설명 p의 리스트를 생송 이로부터 학습 데이터셋 𝐷PE = {(𝑣, 𝑝)|𝑝 ∼ 𝑃teacher(·|𝑣,𝑇PE), 𝑣 ∈ V}를 생성합니다. 여기서 𝑇PE는 선호 추출 단계에 사용된 프롬프트임
User and Item Profile Construction
Step2.
user Profile과 item profile s를 생성
각자 사용자 또는 아이템에 대한 포괄적인 주관적 선호 정보를 반영하 텍스트
Step1. 에서 추출한 preference description을 aggregate하고 요약해서 각 사용자 또는 아이템에 대한 구조화된 프로필로 구성함
-> 리뷰의 noise를 감소시키고 핵심 선호 및 특징을 명확하게 반영하여 더 효과적인 추론을 가능하게 함
𝑠𝑢는 V𝑢(사용자 리뷰 집합)로부터 추출된 서호 집합 𝑃𝑢 = {𝑝| (𝑣 ∈ V𝑢, 𝑝) ∈ 𝐷PE}을 통해 구성됨
𝑠𝑖도 동힐하게 V𝑖에서 추출한 𝑃𝑖 = {𝑝| (𝑣 ∈ V𝑖, 𝑝) ∈ 𝐷PE}를 기반으로 생성됨
Reasoning-enhanced Rating Prediction
Step3.
user-item 간 상호작용에 대한 평점 예측
step-by-step reasoning을 통해 예측 수행
사용자 및 아이템 프로필에는 주관적 정보가 포함
아이템 설명과 같은 객관적 정보도 함께 활용함
-> Exp3rt는 사용자 선호와 아이템 특성을 비교하고, 이들의 정합성을 기반으로 평점을 예측함.
--> Exp3rt는 개인화된 설명을 포함한 추론을 통해 평점을 도출하며, 추천의 논리적 근거도 제공함.
학습을 위해 teacher LLM이 생성한 텍스트 기바 설명과 평점을 활용한 데이터 생성, i.e., 𝐷PC = {(𝑃, 𝑠)|𝑠 ∼ 𝑃teacher(·|𝑃,𝑇PC)}
𝑇PC추론 생성을 위한 프롬프트
