Introduction
- 2개의 파노라마 이미지가 input으로 주어질 때 relative pose를 추정하는 연구
- Featureless region이 많거나 유사한 구조가 많은 이미지의 경우 feature-based 방식은 잘 작동하지 못하며 이를 보완하기 위해 denser RGB나 RGB-D 데이터를 필요로 하는 방식은 데이터 취득에 있어 추가비용이 발생한다.
- 본 논문에서는 relative pose와 함께 layout geometry, co-visibility, angular correspondence에 대해 함께 학습함으로써 ambiguity를 줄이고 visual overlap이 작거나 wide baseline을 가지는 경우에도 pose 추정이 가능하도록 함
Method
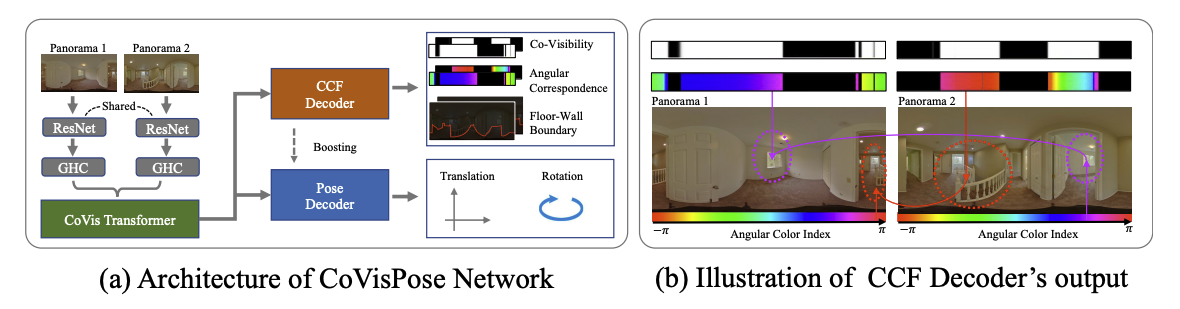
Definition
- Relative pose: 2개의 이미지 가 있을 때 은 에 대한 의 relative pose로 rotation , translation vector , translation scale 로 표현된다.
- Floor-wall boundary: 각 column별로 바닥과 벽이 맞닿는 영역에 대한 vertical angle 정보가 담긴 1D representation
- Co-visibility: 번째 column의 floor-wall boundary가 두 개의 파노라마 이미지에서 모두 존재하면 1, 그렇지 않으면 0인 binary value
- Angular Correspondence: 번째 column이 매칭되는 다른 파노라마 이미지에서의 horizontal angle
CoVisPose Network Architecture
-
HorizonNet과 동일하게 ResNet50의 각 block에서의 output을 concat하여 columnwise feature 를 만든다.
-
Positional encoding과 learnable per-image segment embedding이 더해진 두 이미지의 feature 는 concat하여 transformer를 통과한다.
-
Transformer의 output 는 single FC layer로 구성된 CCF Decoder를 거쳐 를 출력한다.
-
또한, 6-layer 1-D CNN으로 구성된 Pose Decoder에서는 relative pose에 대한 5D vector를 출력한다.
Loss
- Floor-wall boundary와 correspondence에 대해서는 L1 loss를, co-visiblility 확률값에 대해서는 BCE loss를 적용한다.
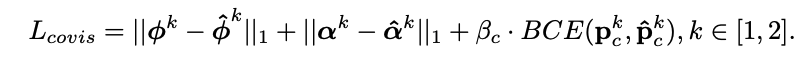
- Normalized translation에 scale 를 곱해 최종적인 translation 를 구하며MSE loss를 통해 학습한다.
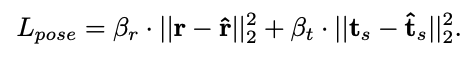
Relative Pose Estimation by RANSAC
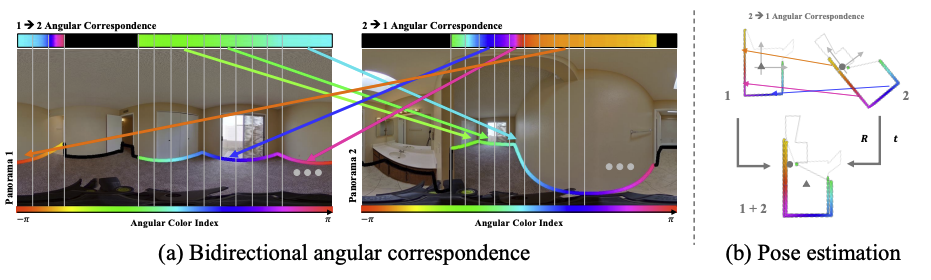
- CCF Decoder에서 예측한 correspondence를 활용해 RANSAC으로 pose를 추정할 수도 있다.
- 매칭되는 floor-wall boundary points를 바닥으로 projection하고 를 적용했을 때 매칭점들의 오차를 통해 inlier를 추정한다.
Experiments

- RANSAC이 성능은 가장 좋지만 CoVisPose Direct는 inference 시 50ms, RANSAC은 30sec

