Introduction
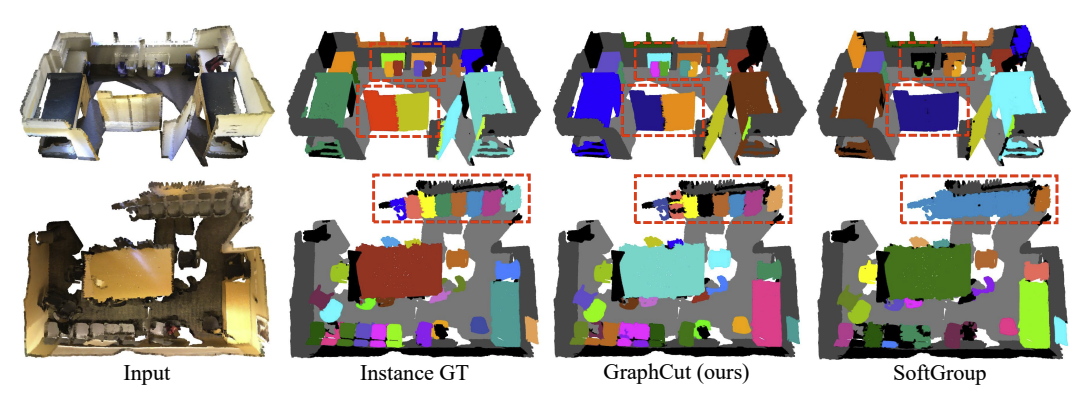
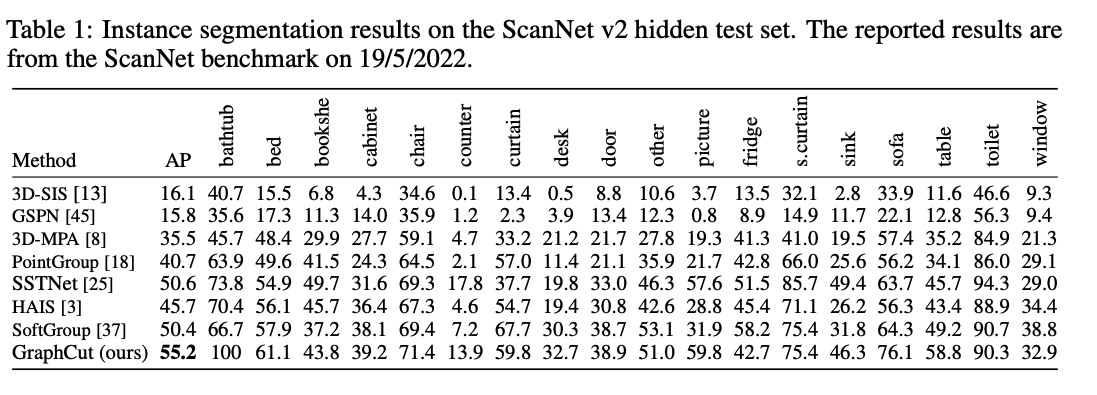
- 3D point cloud를 input으로 받아 instance segmentation을 하는 task로 기존의 detection-based, clustering-based 방식으로는 복잡한 geometric structure에서 잘 작동하지 못한다.
- 본 논문에서는 superpoint graph를 활용한 learning-based 방식으로 3D point cloud의 local geometric structure를 explicit하게 학습한다.
- Edge prediction network를 통해 인접 노드들 간의 similarity를 계산하고 coordinate space와 feature space에서 각각 같은 instance인 노드끼리는 끌어당기고 다른 instance인 노드끼리는 밀어내도록 학습한다.
Superpoint Graph
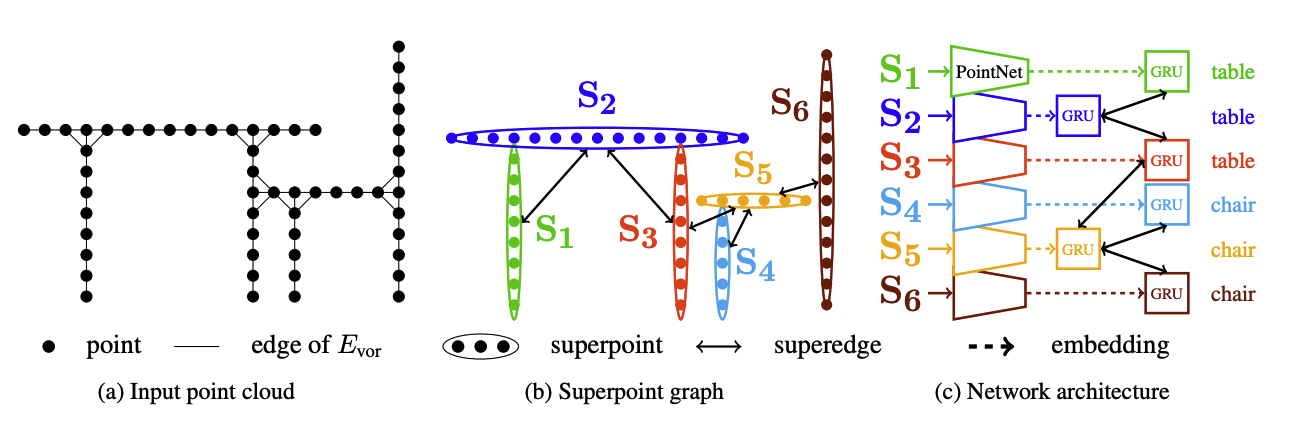
- Input으로 들어오는 point cloud를 geometric metric을 기준으로 하여 나눠주고 각각의 partition을 하나의 superpoint라 한다.
- 각 superpoint는 PointNet을 거쳐 embedding feature 및 semantic 정보를 가진다.
Method
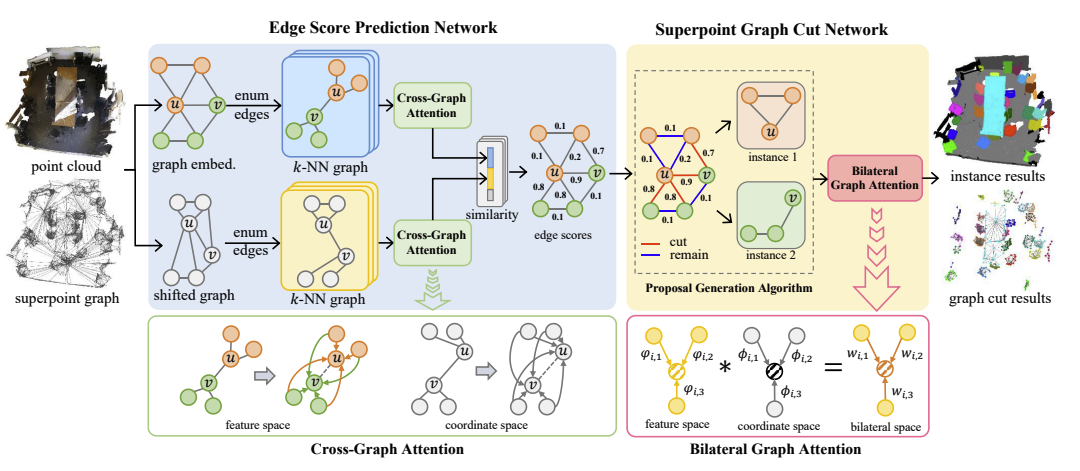
Edge Score Prediction Network
Edge feature embedding in coordinate space
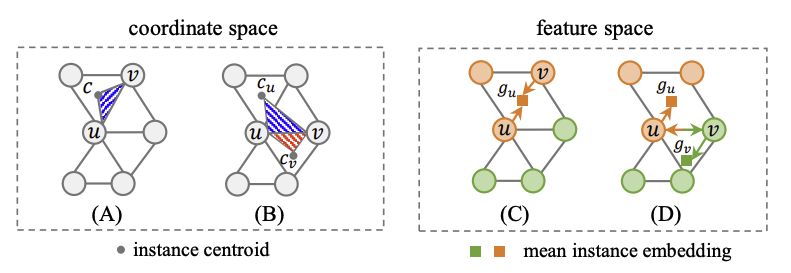
- 두 노드 의 similarity를 계산하기 위해 coordinate space 상에서 각각 instance centeroid를 향하도록 shift 한다.
- Superpoint의 feautre 는 MLP를 거쳐 offset vectors 로 encoding 되며 shifted superpoint coordinates는 가 된다. 는 original superpoint coordinates를 의미한다.
- 이후 노드 에 대해 -nearest superpoints를 활용하여 local -NN graph 를 만들고 노드 에 대해서도 동일한 과정을 거쳐 를 만든다.
- 두 그래프 에 대해 cross-graph attention을 수행하며 최종적인 output feature vector는 다음과 같다.
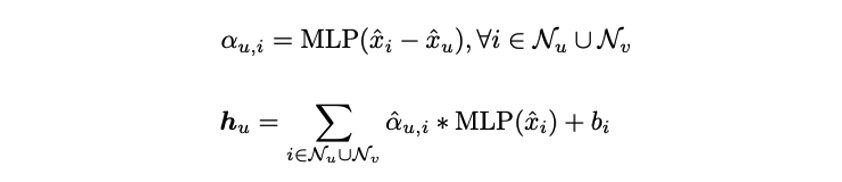
- shifted coordinates
- enumerates the all 2* neighbors across two graphs
- Feature vector 는 두 그래프 간의 gemetric한 차이를 학습하여 geometry similarity를 characterize하며 edge embedding 는 를 concat하여 정의된다.
Edge feature embedding in feature space
- Feature space에서의 embedding은 가 MLP를 통과하여 initial feature embedding 를 얻는다.
- 동일한 방식으로 -NN graph 를 만들어 cross-graph attention을 통해 feature vectors 를 얻으며 concat하여 edge embedding 를 만든다.
- 가 동일한 instance에 속한다면 유사한 -NN graph를 공유할 것이며 그 결과 두 개의 feature vector가 유사해진다.
Geometry-Aware Loss
-
두 space에서 얻은 edge embedding들은 MLP를 거쳐 edge score를 생성한다. 는 두 노드의 shifted coordinate space에서의 geometric distance를 나타낸다.
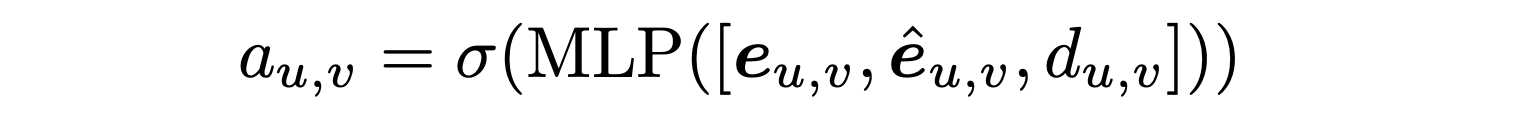
-
Edge score 가 0.5보다 크면 두 노드 사이의 엣지는 superpoint graph에서 사라지며 는 BCE loss로 구성된다.
-
노드 에 해당하는 instance centroids를 라 할 때 distance 를 minimize하고 두 노드가 같은 instance일 때는 가 최소가 되도록, 다른 instance일 때는 와 가 최소화되도록 하기 위해 다음과 같은 loss를 활용한다.
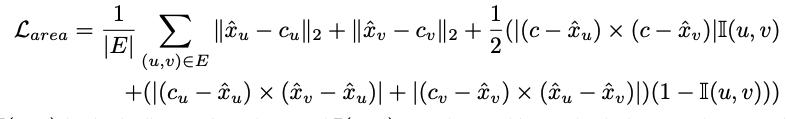
-
Feature space에서도 마찬가지로 동일한 instance라면 서로 끌어당기고 mean embedding 가 가까워지도록, 다른 instance라면 서로 밀어내며 또한 멀어지도록 학습한다.
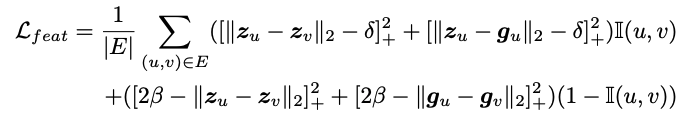
-
최종 loss는 다음과 같다.

Superpoint Graph Cut Network
Proposal Generation via Superpoint Graph Cut

- Edge score 와 노드에 대한 predicted semantic class를 통해 candiate proposals를 생성한다.
- Semantic prediction error의 영향력을 줄이기 위해 -th class에 대한 확률값이 threshold 이상인 superset 을 만든 뒤 두 노드 가 에 모두 속하면 edge를 유지하고 그렇지않으면 제거한다.
- 이후 유지된 superpoint graph에서 edge score가 0.5 이상인 경우 제거한다.
- 마지막으로 breadth-first-search 알고리즘을 적용하여 -th class에 대해 개의 proposals 를 생성한다.
Bilateral Graph Attention for Proposal Embedding
- Coordinate space와 feature space에 모두 attention을 적용하는 bilateral graph attention을 통해 proposal embedding을 추출한다.
- -th proposal이 주어졌을 때, shifted superpoint coordinates를 평균낸 proposal centroid 를 계산한다.
- Proposal의 embedding을 interpolate 하기위해 inverse distance weighted average를 활용한다. 는 번째 proposal의 superpoints를 는 superpoints의 original coordinates를 의미한다.
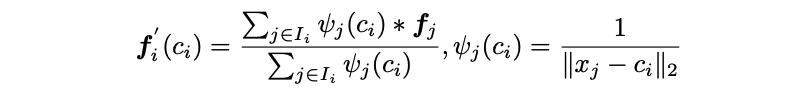
- 는 superpoint 와 번째 proposal 사이의 bilateral weight로 와 는 각각 feature space와 coordinate space에서의 proposal centroid와 superpoint의 차이를 encoding하는 mapping function이다. 는 softmas를 거친 정규화된 weight이다.
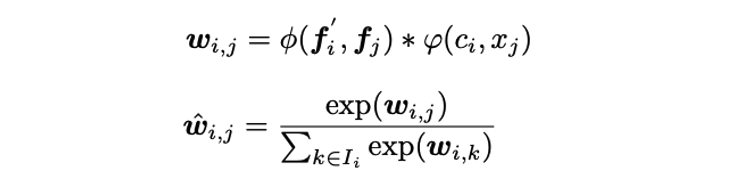
- Weighted superpoint embedding을 sum하여 proposal embedding을 얻는다.
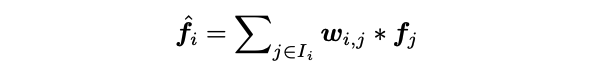
- Proposal embedding은 classification head, score head 그리고 low confidence를 가지는 superpoint를 마스킹하기 위한 score를 예측하는 superpoint mask head를 거쳐 instance를 생성하며 각각 CE loss, BCE loss, MSE loss를 쓴다.

- 최종 loss는 semantic score를 위한 conventional CE loss까지 더해져 다음과 같다.
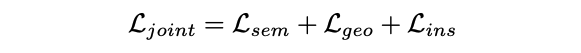
Experiments