- Alexnet은 CNN기반 모델인 LeNet이 개발 된 이후 최초로 나온 large scale CNN이다.
- CNN에서 어떻게 많은 dataset을 처리하고 overfitting을 방지했는지 정리했다.
Reference
[AlexNet]ImageNet Classification with Deep Convolutional Neural Networks(2012)
0. Introduction
- 객체인식을 위한 현대적 접근은, 성능을 끌어올리기 위해 많은 양의 데이터셋, 더 강력한 모델, overfitting을 막기 위한 더 나은 방법들을 사용하는 것이다.
- (그당시) CNN은 기존의 feedforward neural network들(eg.MLP)에 비하면 같은 데이터에 대해 적은 파라미터와 적은 커넥션으로 쉽게 학습하고, 약간 나쁘지만 비슷한 성능을 보여준다.
1. Dataset
- 다양한 해상도의 이미지를 포함하는 ImageNet Dataset을 256X256해상도로 다운샘플링했다.
- ImageNet Dataset는 22,000카테고리에 속하는 1,500만 개 이상의 고화질 이미지 dataset
- 직사각형의 이미지가 주어지면 먼저 짧은 면의 길이가 256이 되도록 이미지를 조정한 다음, 중앙에서 256X256으로 크롭하였다.
2. Architecture
2-1. Activation function-ReLU
-
경사 하강법을 사용한 훈련에서 포화 비선형 함수(saturating nonlinearities)에 비해 빠른 비포화 비선형 함수(non-saturating nonlinearity)인 ReLU를 사용했다.
- 포화 비선형 함 수란 포화되면 특정값으로 수렴하여 기울기가 0에 가까워지는 함수를 말한다.
- 포화 비선형 함수는 특정 어느 지점이상부터 입력값의 크기에 상관없이 출력값에 변화가 거의 없어져 vanishing gradient현상이 발생한다.
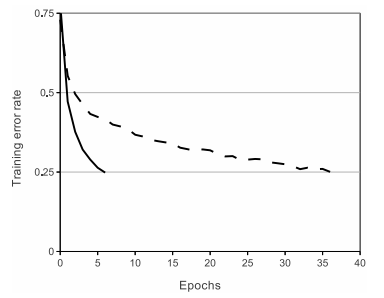
- 사진은 CIFAR-10 Dataset에서 training error rate를 25%까지 낮추는데 얼마나 많은 시간이 소요되는지 보여준다.
- 실선은 ReLU함수를 보여주고, 점선은 saturating nonlinearity인 tanh를 보여주는데, ReLU가 약 6배 빠름을 알 수 있다.
2-2. Training on Multiple GPUs
- 그래픽 메모리가 3GB인 하나의 GPU만으로 학습시키기에는 모델이 커서 3GB GPU(GTX580) 2개에 네트워크를 분산시켜 학습을 진행했다.
- convolution 연산시 결과 feature map이 96개 라면 각 GPU에 48개씩 배치하는 방식으로 병렬화를 진행
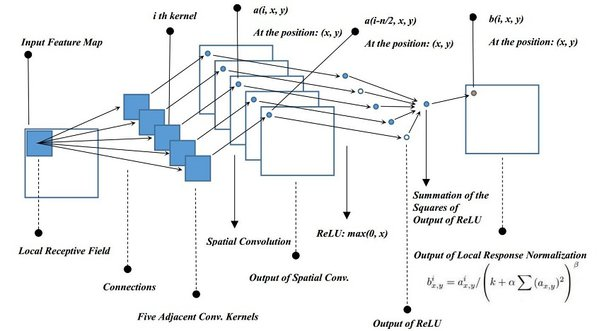
2-3. Local Response Normalization
-
ReLU의 결과 값이 너무 커서 주변 뉴런에 영향을 주는 것을 방지하기 위한 normalization 기법
- receptive field concept을 활용한 CNN 특성상 이웃픽셀의 계산에 영향을 주기 때문
- 현재는 Batch Normalization의 등장으로 잘 사용되지 않는 기법
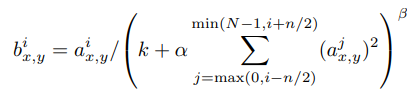
- : 에 존재하는 픽셀에 대해 번째 커널을 적용하여 얻은 결과에 ReLU를 씌운 값
- : 레이어에 존재하는 전체 커널의 수
- : 인접하다고 판단할 범위 값(하이퍼 파라미터)
- 수식에서 등장하는 상수 는 하이퍼파라미터로 논문에서는 각 값을 로 사용했다.
- 위의 정규화 과정은 특정 레이어에서 사용되었으며, ReLU를 거치고 난 결괏값에 사용했다.(뒤에 사진 참조)
- 이 정규화 방법을 통해 Top-1 에러율은 1.4%, Top-5 에러율은 1.2% 감소시킬 수 있다고 밝혔다.
2-4. Overlapping Pooling


- (그당시) 기존 CNN은 Pooling을 진행할때 pooling unit들이 겹치지 않도록 연산되었다.
- kernel size = X , stride=라고 할때, s=z로 설정
- 새로운 CNN(AlexNet)은 unit간 stride를 kernel size보다 줄여 겹치며 연산하도록 overlapping 시켰다.()
- 이 논문에서는 stride=2, kernel size=3X3로 overapping시켰다.
- stride=2, kernel size=2X2와 비교했을때 Top-1 에러율을 0.4%, Top-5 에러율을 0.3% 감소시켰다고 한다.
2-5. Overall Architecture
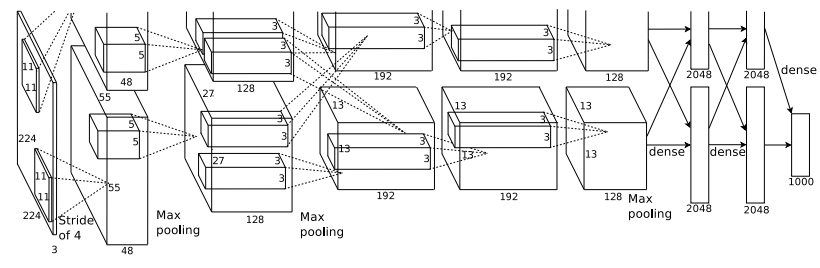
- 모델은 총 8개의 레이어로 이루어져있으며 세부적으로는 5개의 conv layer과 3개의 FC layer로 구성되어있다.
- FC layer의 마지막 레이어는 1000개의 클래스로 분류하기 위해 다중 클래스분류에 사용되는 activation function인 softmax 연산을 거쳐 1000개의 객체를 분류할 수 있도록 했다.
- 3번째 레이어에서는 2번째 레이어의 모든 커널맵이 연결되어있다.(두개 GPU의 정보교환)
- 모든 FC layer는 이전 레이어의 모든 뉴런과 연결되어 있다.
- RNL은 첫번째 레이어와 두번째 레이어에 적용되었다.
- ReLU function은 8개의 모든 레이어(conv+FC)에서 사용되었다.
- : 입력 이미지의 너비(높이)
- : 커널의 너비(높이)
- : 패딩의 크기
- : stride의 크기
3. Reducing Overfitting
- AlexNet은 6,000만개의 파라미터를 갖는다.
- 많은 파라미터를 학습시키기 위해 overfitting을 고려해야한다.
- AlexNet은 2가지 방법을 고안했다.
3-1. Data Augmentation
- overfitting을 줄이기 위해 가장 쉽고 공통적으로 사용되는 방법은 레이블을 보존하는 형식으로 이미지에 변형을 줘서 데이터 셋의 다양성을 늘리는 것이다.
- 이 방식은 GPU가 다른 이미지를 학습하는 동안 간단한 파이썬 코드로 구현되기 때문에, 디스크에 저장할 필요가 없어 효율적이다.
- Alexnet은 두가지 방법을 고안하는데 그 방식은 Horizontal Reflection and Image Translations, RGB channels의 강도조절이다.
Horizontal Reflection and Image Translations
- 이미지를 좌우반전 시키고, 랜덤으로 227X227크기의 패치를 얻어낸다.
- 이는 이론상 최대 하나의 이미지가 29X29X2로 1682개의 패치(데이터)를 얻을 수 있다.
- paper 내에서 alexnet을 테스트할때에는 중앙의 패치+각 모서리 4개의 패치+ 패치마다 좌우반전으로 하나의 이미지로 10개의 패치를 입력으로 넣었다.
RGB channels의 강도조절
- 주성분분석(PCA)를 통해 이미지의 RGB 채널의 주성분을 찾고, 평균 0과 표준편차 0.1을 갖는 가우시안 분포에서 추출한 임의의 값들을 해당 주성분에 곱하여 원본 이미지의 색상을 조절하여 변형을 주었다.
- 이는 원래의 라벨을 해치지 않으며 색상의 변형을 일으킨다.
3-2. Dropout
- 네트워크 구조가 거대한 딥러닝 모델의 학습은 비용효율적이지 못했다.
- 비용 효율적인 layer 구현 및 overfitting 방지를 위해 (그당시) 최신의 기술인 dropout을 사용했다.
- 하이퍼파라미터를 통해 정해진 확률로 뉴런의 출력을 0으로 세팅해 뉴런을 비활성화한다.
- 이는 전체 네트워크가 특정 뉴런에 의존성을 줄여 overfitting을 방지한다.

실패보다 사람을 더 미치게 하는게 후회더라구요