- oxford의 Visual Geometry Group이 만든 CNN 신경망
- 레이어가 깊어질수록 파라미터의 수가 많아져 계산량이 늘고, 시간이 오래걸리는데, 이를 어떻게 극복했는지 볼 수있다.
Reference
[VGGNet]VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION (2014)
0. introduction
-
저자는 CNN아치텍처 설계의 중요한 측면인 깊이를 깊게 하는것에 집중하여 성능을 개선시키고자 했다.
-
결과적으로 ImageNet dataset 뿐만 아니라 다양한 이미지 dataset에 대해서도 SOTA(state of the art)에 준하는 성능을 보여주었다.
1. convNet configurations
-
ConvNet의 깊이가 증가함에 따라 개선되는 성능을 측정하기 위해 모든 ConvNet 레이어 구성은 동일한 원리로 설계되었다.
-
우선적으로 ConvNet의 일반적인 레이아웃 구성을 살펴보고, 평가에 사용된 특정 구성에 대한 디테일을 살펴본다.
-
그 후 이전의 SOTA와 비교하고, 논의한다.
1.1 ARCHITECTURE
-
학습과정에서 입력으로 224X224크기의 RGB 이미지가 주어진다.
-
각 이미지 픽셀에서 평균 RGB값을 빼준게 데이터 전처리의 전부이다.
-
전처리를 거친 이미지는 여러 개의 ConvNet을 거치게 되는데, 이때 아래와 같이 매우 작은 크기의 커널을 거친다.
- 3X3 커널:상하좌우 인접성을 고려하기 위한 최소한의 커널크기
- 1X1 커널:입력 채널에 대한 선형 변환으로(비선형성이 뒤따르는) 볼 수 있음 -
Conv layer에서 padding은 이전 입력의 크기가 유지될 크기인 1로 고정한다.(zero padding 1)
-
Maxpooling layer는 5개로 구성되며, 2X2 사이즈의 pixel window와 stride=2값을 갖는다.
- overlapping하지 않는다. -
Conv layer의 뒤에는 3개의 FC layer가 뒤따른다. 처음 2개 레이어는 4096개의 채널을 각각 가지고 있고, 마지막에는 1000개의 채널로 구성된다.
-
마지막 레이어는 1000개의 클래스로 분류하기 위한 soft-max layer이다.
-
모든 hidden layer에 ReLU 비선형함수를 사용했다. LRN normalization이 성능향상에 도움을 주지 않고, 오히려 메모리 사용량와 계산시간만 증가시킨다고 AlexNet과 상반된 주장을 펼치고, 사용하지 않았다.
1.2 CONFIGURATIONS
-
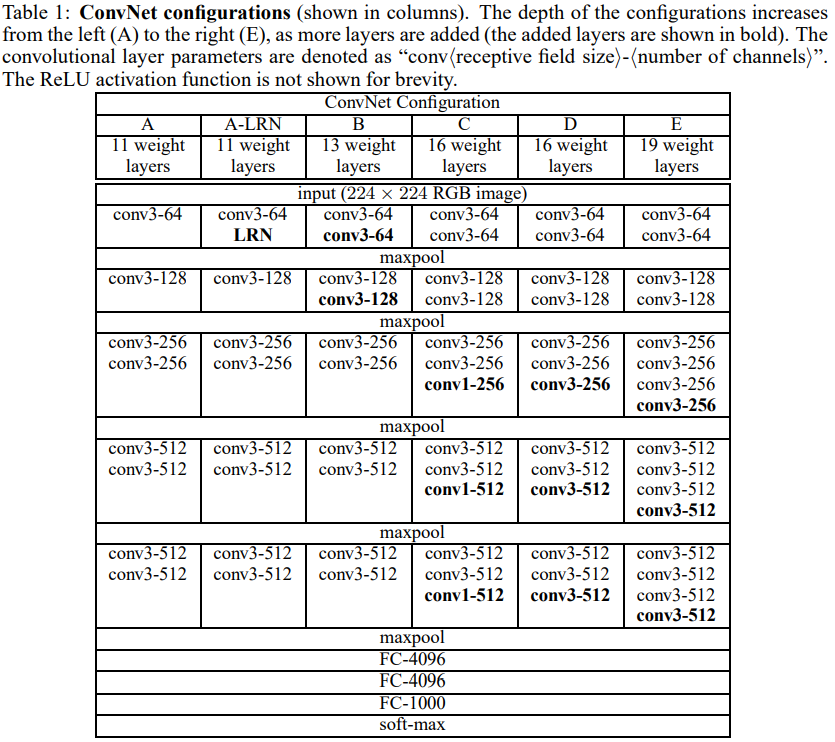
레이어의 상세한 설정은 아래 table과 같다.
-
11~19층까지 나뉘는 layer의 깊이에 따라 A~E까지 이름을 붙였다.
-
레이어를 지나면서 커널의 채널 크기는 512가 될때까지 2배씩 증가시켰다.
1.3 DISCUSSION
- 다른 모델들은 11 X 11이나 7 X 7 크기를 사용한 반면 저자는 거의 최소인 3 X 3과 1 X 1을 사용했다. 그 이유는 2가지가 있는데,
- decision function을 더 discriminative하게 만들고
- 파라미터의 수를 감소시킬 수 있기 때문이다.
왜 커널의 크기가 작으면 파라미터의 수가 작을까?
- 5X5 단일 레이어와 3X3 이중 레이어는 같은 receptive field 크기를 갖는다.
- 5X5 단일레이어는 25개의 파라미터를 , 3X3의 이중 레이어는 18개의 파라미터를 갖는다.
- 충분한 컴퓨팅 파워를 갖추고 있다면, 깊이를 늘리고 커널의 사이즈를 줄여 파라미터의 갯수를 줄일 수 있다.

- 1 X 1 크기의 커널을 사용하는 이유는 인접한 receptive field에 영향을 주지 않으면서 비선형성을 증가시킬 수 있기 때문이다.
TRAINING
- 훈련 과정은 큰 틀에서 AlexNet과 동일하다.
- Batch Size: 256
- Momentum: 0.9
- Learning rate:
- [[Weight decay(L2 regularization)]]: 5x
- Dropout: 0.5 - 파라미터의 잘못된 초기화는 성능에 영향을 줄 수 있기에, 이를 방지하고자 무작위로 초기화된 값으로 학습할 수 있는 얇은 모델을 학습시켰다.
- dropout은 초기 2개의 Fully Connected Layer에 적용했다.
- valiation에 대한 accuracy 향상되지 않을 때마다 10배 감소시켰다.(최종적으로 학습률 3번 감소, 74epoch동안 학습 진)
- 학습시킨 후의 값을 더 깊은 모델의 Convolutional Layer를 초기화시켰다.
- 이외의 층은 평균이 0, 분산이 0.01인 정규분포를 사용해 초기화해주었다.
- 더 적은 수의 파라미터와 더 깊은 레이어가 있음에도 학습을 진행한 횟수가 적었다.
- 저자들은 어림짐작하길 깊은 레이어의 수와 작은 convolution 연산이 정규화와 같은 역할을 내포하고 있었을 것이며, 특정 레이어에 대한 초기화 덕분이라고 하였다.
