Reference
- ILSVRC 2014에서 VGGNet을 제치고 1등
- 이름의 유래는 거의 대부분 구글직원이라+ 초기 LeNet의 이름을 따라서 Goog+LeNet
- 1 by 1 conv layer의 사용이나 depth를 늘려 성능개선을 꽤하는 듯 VGGNet과 유사한점이 있다.
- VGGNet과 다른점은 inception 모듈이라는 독특한 구조를 사용
Abstract
- 이 모델의 중점적 특징은 연산시 컴퓨팅 리소스의 활용이 개선되었다.
- 성능 최적화를 위해, Hebbian principle과 multi-scale processing의 직관을 사용하였다.
- 이 구조를 GoogLeNet이라 부르며, 22개의 layer를 가진다.
Introduction
- 지난 3년간 CNN분야의 많은 발전이 있었는데, 그것은 단지 하드웨어 성능의 증가, 커진 dataset, 큰 모델때문이 아니라 새로운 아이디어와 알고리즘, 개선된 신경망 구조때문이였다.
- GoogLeNet은 2년전의 AlexNet보다 파라미터가 12배 적었음에도 불구하고, 더욱 상당히 정확했다.
- power나 메모리사용량에 한계가 있는 mobile이나 임베디드 컴퓨팅환경에서는 효율적인 알고리즘의 중요성이 대두되기때문에, 그러한 곳에서도 현실적으로 적절히 사용하능하게끔 추론시간에 1.5 billion 이하의 연산만을 수행하도록 설계하였다.
- GoogLeNet의 코드네임 Inception은 Network in Network라는 paper과 유명한 인터넷 밈 "we need to go deeper"에서 유래되어 착안하였다.(인셉션 영화 대사)
- 이때 deep은 두가지 의미를 갖는다.
1. Inception module의 형태로 새로운 차원의 구조 도입
2. 네트워크 깊이가 깊어졌다는 직접적인 의미
Related Work
- LeNet을 필두로, CNN은 표준의 구조를 갖는데, 이는 Conv layer가 쌓이고(옵션으로 정규화와 max-pooling) 그 뒤에 1개 또는 그 이상의 FC layer가 따라오는 구조이다.
- 또한 layer의 수를 늘리고, overfitting을 해결하기 위해 dropout을 적용하는 것이다.
- GoogLeNet 또한 위 설명과 같은 구조를 띤다.
GoogLeNet은 Network in Network paper의 영향을 많이 받았다고 한다.
- 1 x 1 conv layer이 추가되며 ReLU activation이 뒤따른다.
- 이는 네트워크신경망의 표현력을 높인다.
- 1 x 1 conv layer의 장점은 아래와 같다.
1. 네트워크 크기 제한
2. 차원 축소
Motivation and High Level Considerations
GoogLeNet이 나오게 된 배경에 대해 설명한다.
-
심층 신경망의 성능을 개선하는 가장 간단한 방법은 크기를 늘리는 것이다.
-
크기를 늘린다는 것은 depth의 증가(layer의 수 증가)와 width의 증가(각 layer의 유닛 수 증가)
-
이는 좋은 성능을 낼 수 있지만 두가지 문제가 있다.
- 크기가 커지면 하이퍼파라미터의 수가 많아지는데, 이는 특히 학습데이터의 수가 적을 경우 오버피팅이 일어나기 쉽다.이를 막기 위해 단순히 고품질의 트레이닝 셋을 늘리는 것은 매우 tricky하며 비용이 높아 주요한 병목현상이 될 수도 있다.
- 네트워크가 커질수록 컴퓨팅파워가 더욱 많이 필요하다. 만약 두 conv layer가 연결되어 있다면, 필터의 수가 늘어날때 연산량은 quadratic하게 증가한다.quadratic?
만약, 3 x 3 Conv filter 개와 3 x 3 x Conv filter 개가 연결되어 있을 시, 이는 3 x 3 x 3 x 3 x x 가 된다. 이는 과 가 동일하다고 가정할 시, 3 x 3 x 와 비슷한 꼴이 되기에 C의 값에 따라 연산량이 quadratic하게 증가하게 된다. -
따라서 한정적인 컴퓨팅 자원에서 네트워크 크기를 늘리는 것보다 컴퓨팅 자원을 효율적으로 분배하는 것이 중요하다.
Architectural Details
Inception module
naive version inception module
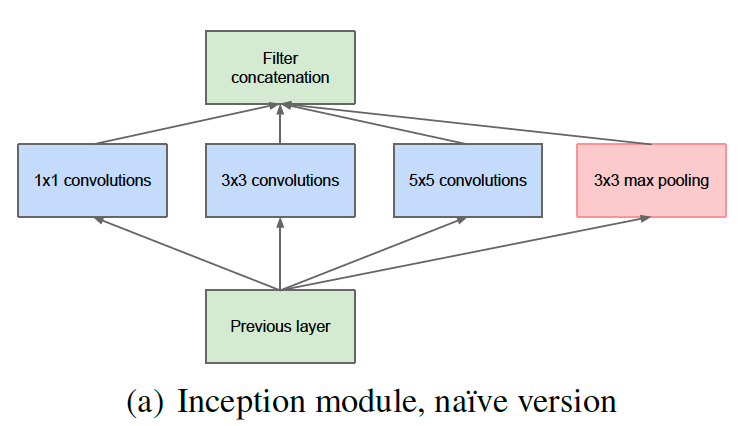
- inception module의 나이브한 접근이다.
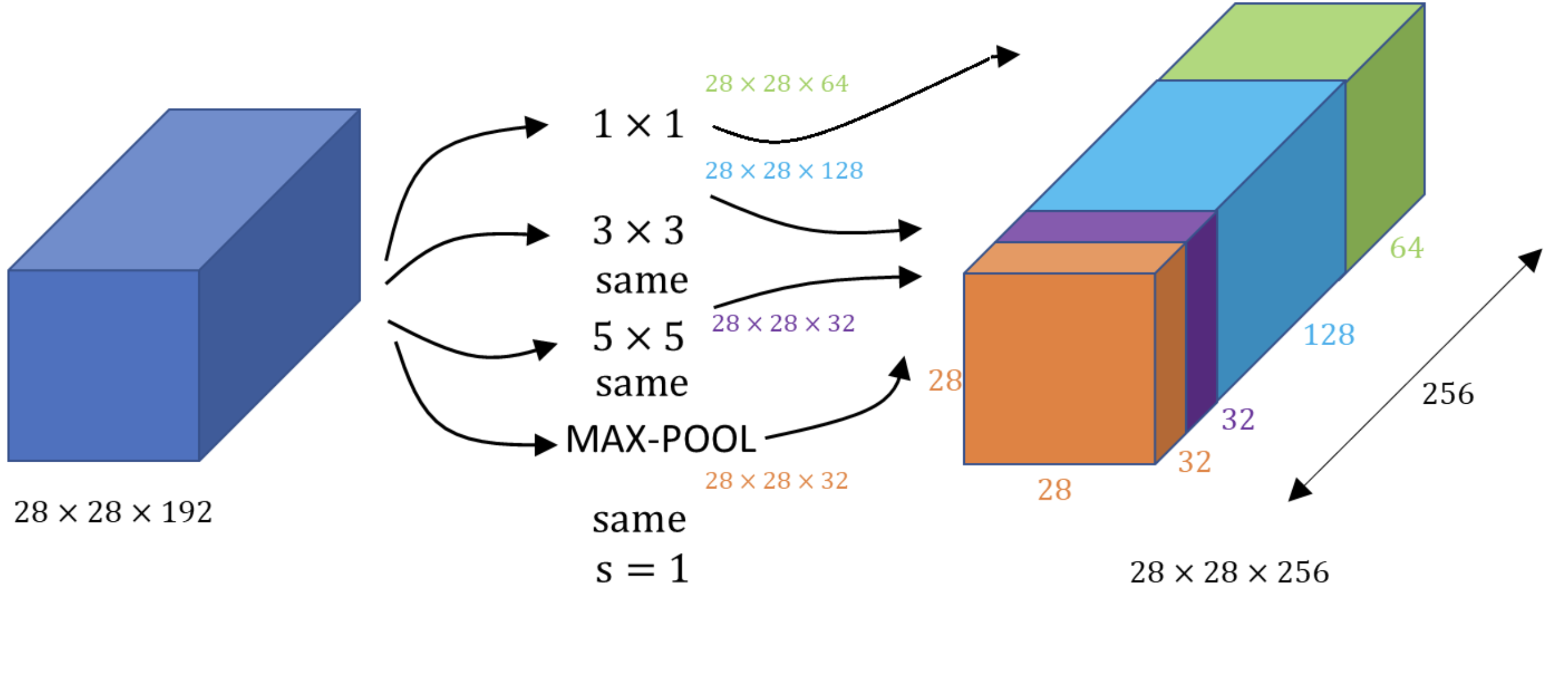
- Feature map을 효과적을 추출할 수 있도록 1X1, 3x3, 5x5 conv 연산을 병렬적으로 수행한다.
- 이럴 경우 연산량은 증가할 수 밖에 없다.
Inception module with dimension reductions
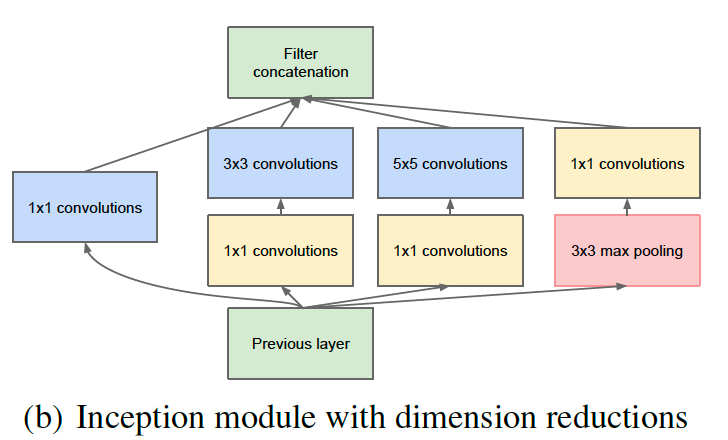
- 따라서 이 문제를 해결하기 위해 1x1 conv 연산을 이용하였다.
- 3x3, 5x5 앞에 두어 차원을 줄이기 때문에, 연산량을 낮추며 비선형성을 얻을 수 있다.
높이, 너비, 채널관점에서의 conv, pooling, 1x1 conv
- convolution : 높이, 너비가 줄어들고, 채널 수를 설정할 수 있다.(padding 고려 X)
- pooling : 높이, 너비만 줄어든다.
높이, 너비를 유지하면서 채널만 줄이려면?
- 1x1 conv filter를 활용가능
1x1 conv filter 이 어떻게 계산의 양을 줄이는가?
필터를 쓰지 않았을 경우
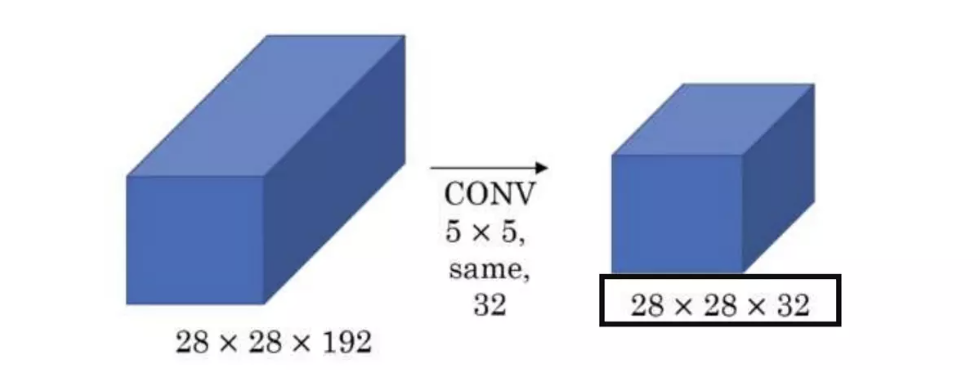
- 조건
- input tensor = 28X28X192
- convolution filter = 5X5X192
- padding = 2
- strride = 1
- number of filter = 32 - 이때 [[출력텐서 크기 공식]]을 쓰면 출력되는 텐서의 크기는 28 X 28 X 32
- 하나의 출력 픽셀을 계산하는데 5X5X192번의 연산이 필요
- 모든 출력 픽셀에 대해 연산할 경우 28X28X하나의 픽셀 출력시 연산 수번의 연산이 필요
- 모든 출력 채널에 대해 연산할 경우 32X모든 출력 픽셀에 대한 연산 수번의 연산 필요
- 28X28X192X5X5X32=12억번 넘는 연산이 필요
필터를 썼을 경우
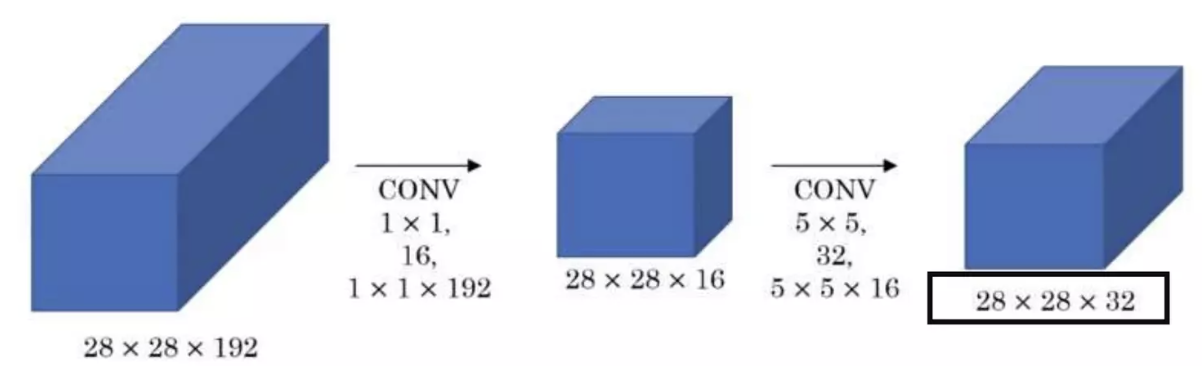
- 1차 조건
- input tensor = 28X28X192
- convolution filter = 1X1X16
- number of filter = 16 - 192X1X1X28X28X16=240만회 연산
- 2차 조건
- input tensor = 28X28X16
- convolution filter = 5X5X192
- padding = 2
- strride = 1
- number of filter = 32 - 16X5X5X28X28X32=1,000만회 연산
- 총 1240만회연산
결론
- 연산횟수가 1/10로 줄어들었다.
- 비선형성이 증가했다.
Inception in GoogLeNet(inception 3a)
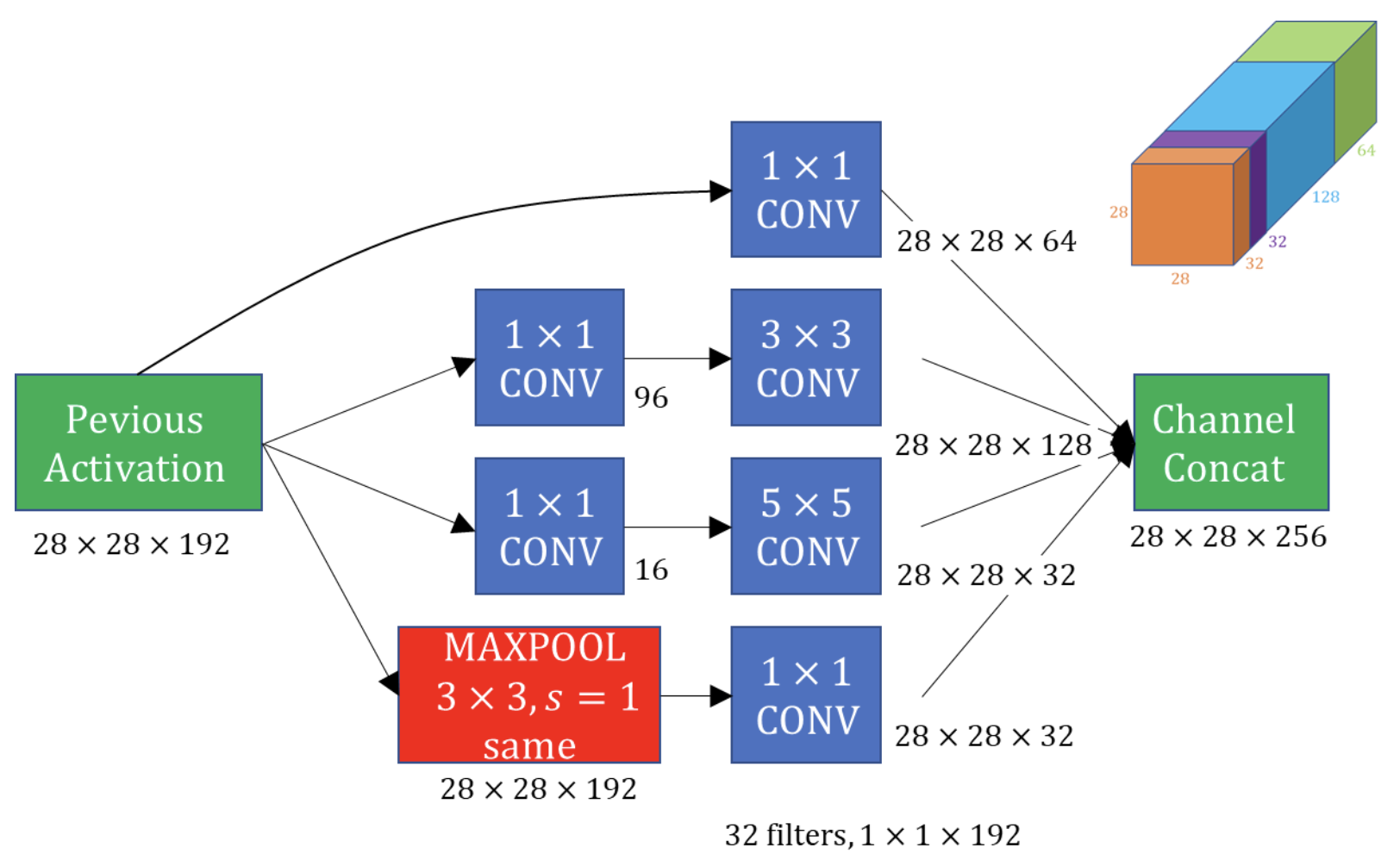
- 실제 GoogLeNet 내부 inception module의 파라미터 계산이다.
- 논문상 첫 인셉션 모듈(inception 3a)에서 쓰이는 과정이다.
GoogLeNet
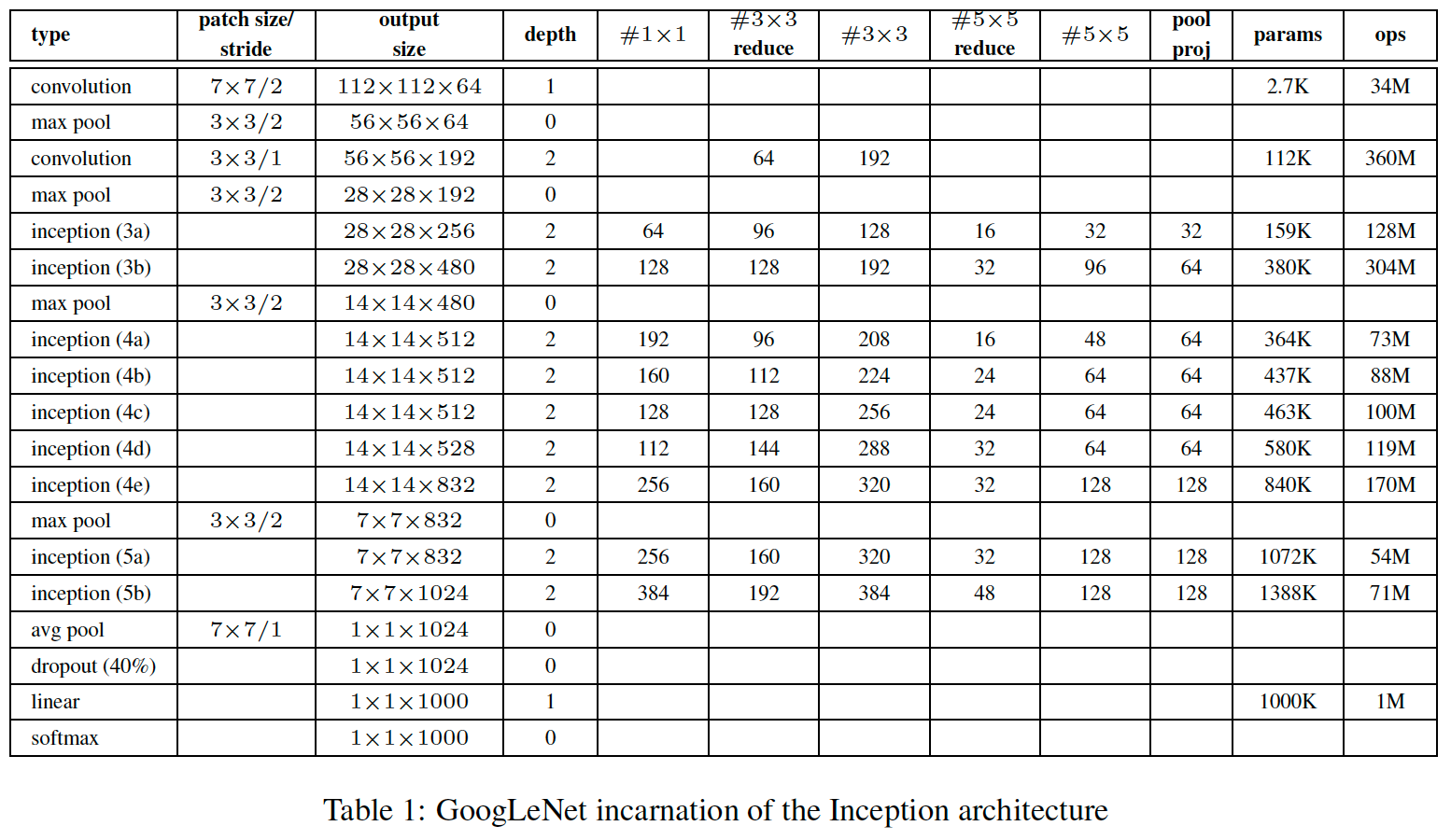
-
위 표에서 # 3X3 reduce와 # 5X5 reduce는 conv layer 앞에 사용되는 1X1필터의 채널 수를 의미한다.
-
pool proj열은 max pooling layer 뒤에 오는 1X1 필터의 채널 수를 의미한다.
-
params는 파라미터 갯수를 의미한다.
-
ops는 전방향 패스동안 필요한 연산 수를 의미한다.
-
GoogLeNet을 4가지 부분으로 나누어보자
Part 1
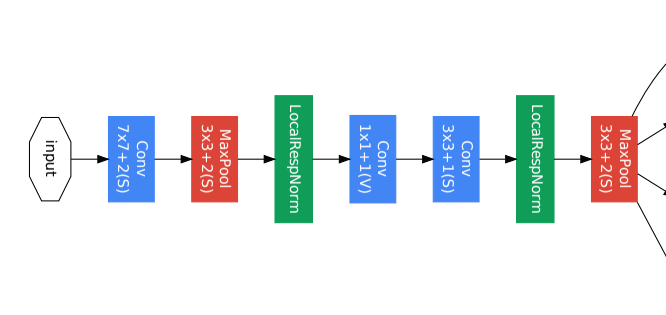
- 입력 이미지와 가까운 낮은 레이어가 위치해 있는 부분이다.
- 효율적인 메모리 사용을 위해 낮은 layer에서는 기본적인 CNN형태의 모델을 적용했다.
- 높은 layer에서 Inception module을 사용하기에 이 파트에서는 사용되지 않았다.
Part 2
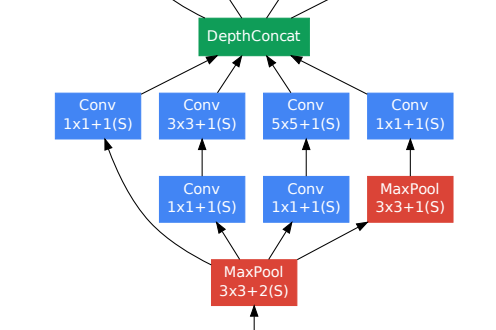
- 다양한 특징을 추출하기 위해 Inception module이 구현되어 있다.
Part 3
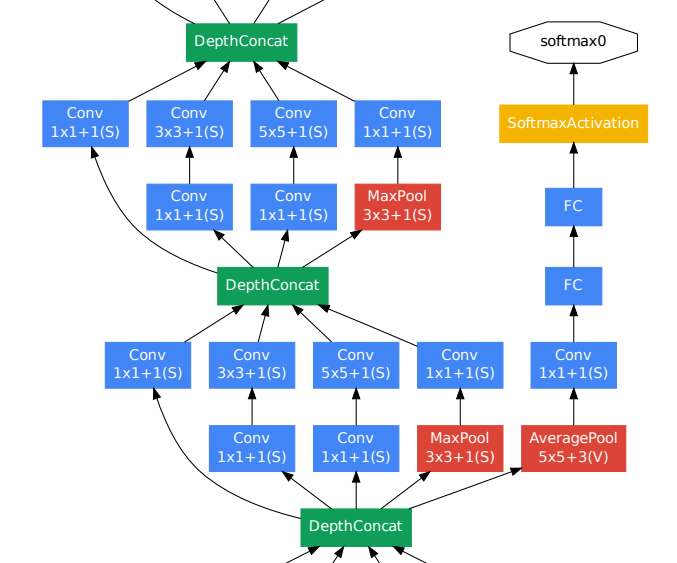
- 모델의 깊이가 매우 깊어지다 보니, ReLU activation function을 사용하더라도 vanishing gradient 문제가 발생할 수 있다.
- 중간 layer에 auxiliary classifier를 추가하여, 중간결과를 출력해 추가적인 backprop으로 gradient가 전달 될 수 있도록 하였다.
- 지나치게 영향을 주는 것을 막기 위해 auxiliary classifier의 loss에 0.3을 곱하여 전체 네트워크의 총 loss에 추가한다.
- 실제 테스트 시에는 auxiliary classifier를 제거 후, 제일 끝단의 softmax만을 사용하였다.
Part 4
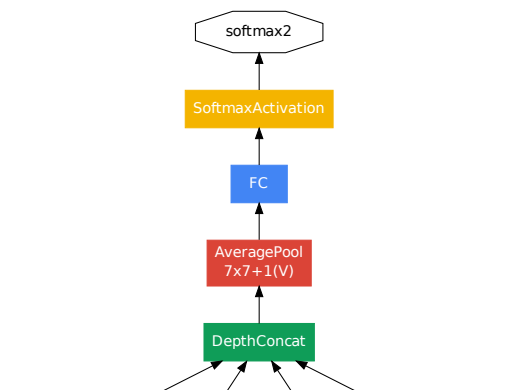
- 예측 결과가 나오는 모델의 끝부분이다.
- Global average pooling이 적용된 average pooling layer가 적용되어 있다.
- 이는 추가적인 파라미터 없이 feature map의 크기를 줄여준다.
GAP(Golbal average pooling)의 장점?
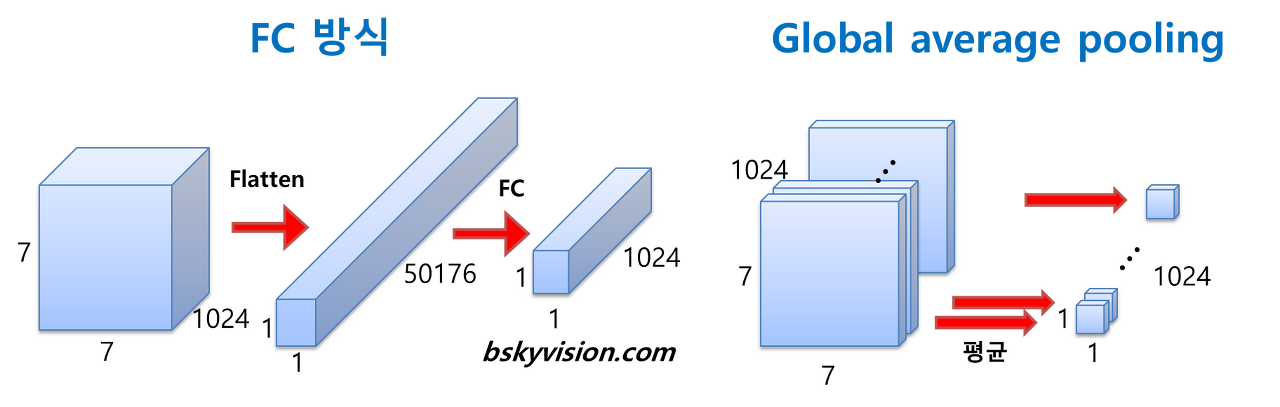
- FC방식을 사용할 경우, perceptron간에 전연결 되기 때문에 7X7X1024X1024=51.3M개의 가중치 갯수가 필요하다.
- 하지만 GAP를 사용할 경우 별도의 가중치가 필요없기 때문에 파라미터 증가가 없다.
Conclusions
- 기존의 깊이만 쌓아나갔던 CNN방식들과 다른 새로운 방법론을 제시했다.
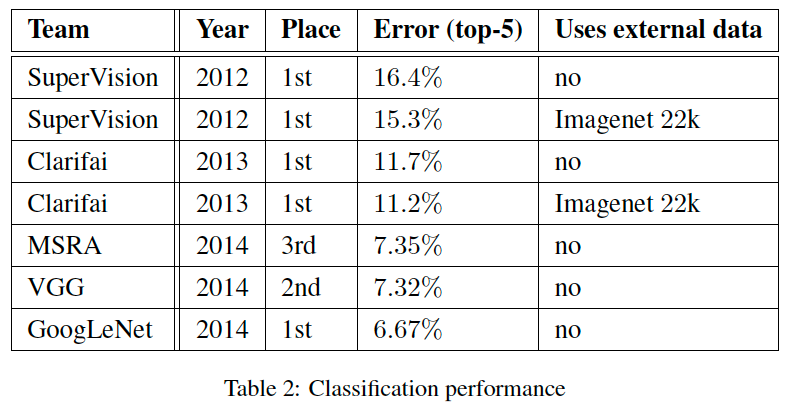
- ILSVRC 2014에서 VGGNet을 제치고 1등을 차지하였다.
