Cosmos-Reason1 논문 리뷰 (arXiv:2503.15558v1)
- [cite_start]Title: Cosmos-Reason1: From Physical Common Sense To Embodied Reasoning [cite: 3]
- [cite_start]Year: 2025 [cite: 5]
- [cite_start]Venue: arXiv (NVIDIA) [cite: 1, 2, 4]
ABSTRACT
Physical AI 시스템은 인지, 이해, 복잡한 해동에 대한 수행을 실제 세계에서 가능해야 한다. Cosmos-Reason1 모델을 제시하며 이는 물리적 세계를 이해할 수 있고 긴 COT 추론과정을 통해 적절한 형태적인 결정(다음 행동)을 생성한다. 물리적 AI 추론을 위해 핵심 능력을 정의하기 시작한다. 물리적 상식을 표현하기 위해 공간, 시간, 물리현상에 대해 포착하는 계층적 구조를 이용한다. 추론을 하기 위해, 다른 물리 현상의 이해를 위해 2차원의 구조에 의존한다. 이러한 능력을 지니기 위해서, 두개의 멀티모달 모델 Cosmos-Reason1-7B & Cosmos-Reason1-56B을 개발했다. 데이터를 선별하고 two-stage의 걸쳐 학습(SFT와 물리 강화 학습)을 진행한다. 모델을 평가하기 위해 물리적 현상과 추론 과정 벤치마크를 제시한다. 평가 결과는 물리 AI SFT와 RL이 가져다 주는 향상을 보인다. physical ai의 발전을 촉진시키기 위해 코드와 사전 학습 모델을 nvidia open license로 공개한다. https://github.com/nvidia-cosmos/cosmos-reason1
Problem Statement
[cite_start]최근 대규모 언어 모델(LLM)이 코딩이나 수학 같은 복잡한 문제에서 뛰어난 추론 능력을 보여줬지만, 이들의 지식은 대부분 텍스트에 기반하고 있어 현실 세계의 물리적 상호작용과 역학에 대한 이해(physical grounding)가 부족합니다[cite: 21, 22]. [cite_start]물리적 세계와 상호작용해야 하는 Physical AI 시스템(로봇, 자율주행차 등)은 단순히 정보를 처리하는 것을 넘어, 물리 법칙에 대한 상식과 실제 환경에서의 행동 계획 능력(Embodied Reasoning)이 필수적입니다[cite: 7, 18, 19]. [cite_start]기존 LLM들은 이러한 능력이 부족하여 물리 세계에서 최적의 행동을 계획하고 실행하는 데 한계가 있었습니다[cite: 21, 22].
Key Idea (1 sentence)
물리적 세계에 대한 체계적인 지식(Ontology)을 정의하고, 이를 바탕으로 대규모 데이터를 구축하여 모델을 학습시킨 후, 검증 가능한 보상 체계를 이용한 강화학습을 통해 물리적 상식과 구체화된 추론 능력을 갖춘 AI 모델을 개발한다.
rule-based, verifiable 보상 방식은 reasoning LLM의 성공의 핵심이었다. 그렇다면 해당 방식이 Physical AI 에서도 동일하게 작동할 것인가? 우리는 multiple-choice question의 근거한 두 가지의 보상 방식을 확인한다. 첫 번째는 사람의 라벨링으로부터 고안되고 나머지는 SSL의 영감을 받아 비디오를 보고 자동으로 질문을 생성하는 방식이다. 비디오의 순서를 섞어 퍼즐을 맞추거나 비디오가 순재생 방향인지 역방향인지를 맞추는 것이다.


데이터가 모델의 한계를 결정한다. 모델의 물리적 이해와 추론 구체화 능력을 강화시키기 위해 비디오 텍스트 페어 데이터 셋 중 4백만개만 선별한다. 두개의 과정을 통해 해당 작업을 수행한다. 데이터는 사람의 어노테이션을 기반으로 선정되며 SFT를 위해 DeepSeek-R1의 모델 distillation으로 선정된다.
모델 평가를 위해 Space, Time, Fundamental Physics 3개의 벤치마크를 구성하며 이는 426개 비디오에서 604개의 질문을 포함한다. 추론 구체화를 위해 600개의 비디오에서 610개의 질문을 포함하며 이는 넓고 다양한 물리 현상인 사람, 로봇, 휴먼 로봇, 자율주행 자동차를 포함한다.
Physical AI Reasoning
physical ai 추론 모델에 대해 두가지 중요한 능력을 확인한다. 물리 현상과 추론 구체화에 대한. 먼저 물리 모델은 물리적 상식을 가져야한다. 이는 일반적 환경에 대한 이해를 말하며 이런 상식은 실제 세계에서 무엇이 가능하고 불가능한지 예측하는 기초가된다. 두 번째로, 물리 모델은 현실 세계에서 어떤 행동을 할지 추론 에이전트가 인지하고 추론하고 결정을 하도록 도와야 한다. System1과 System2가 협력하는 것을 지향한다. System1은 인식에 대해 가능한 빠른 즉각적인 응답과 본능적인 판단을 한다면 System2는 느리지만, 복잡한 결정에 따른 자세한 추론 과정을 거친다.
Common Sense Reasoning
사람은 물리 현상을 세상의 관측에서 얻게 된다. 예를 들어 신생아는 객체의 영속성이나 중력 같은 것을 몇 개월이내에 이해한다. 물리적 상식은 무엇이 가능하고 불가능하고 일어날 것 같은지를 포함한다. AI를 현실 세계에서 학습하는 것은 비싸고 리스크가 존재한다. 물리 상식을 활용하기 위해, AI는 빠르게 적은 시도와 에러에서 새로운 스킬을 빠르게 배워야 한다.
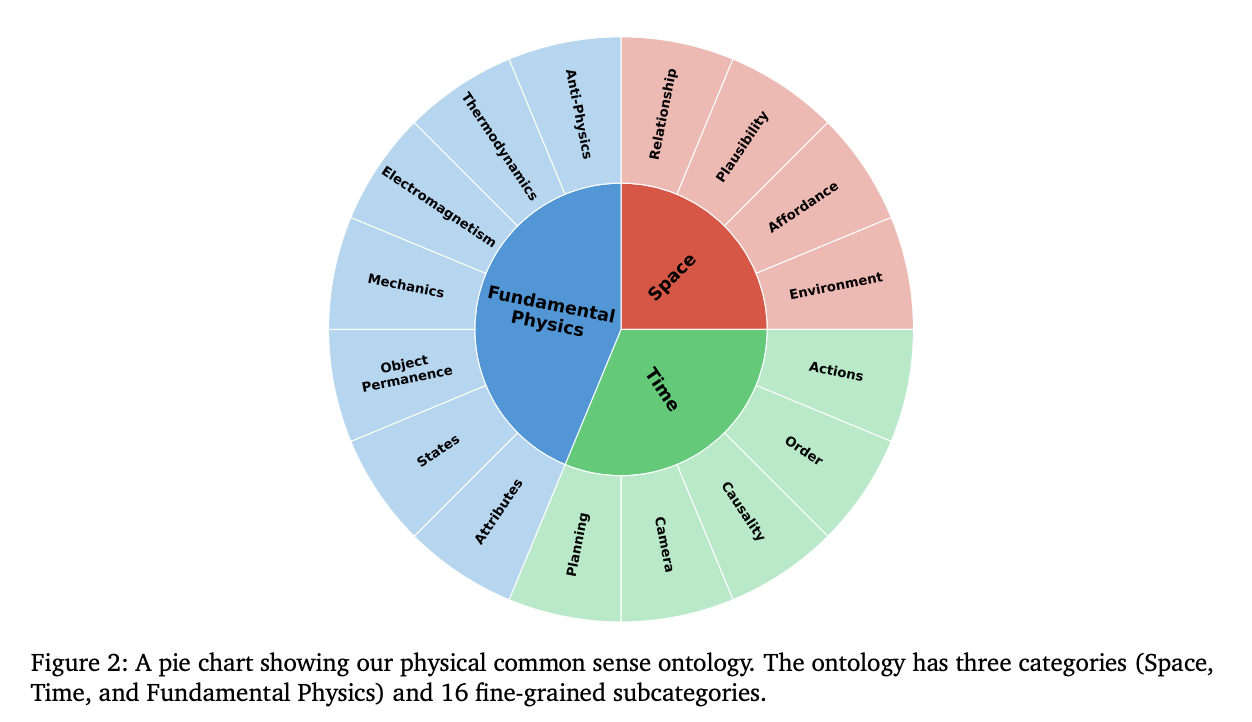
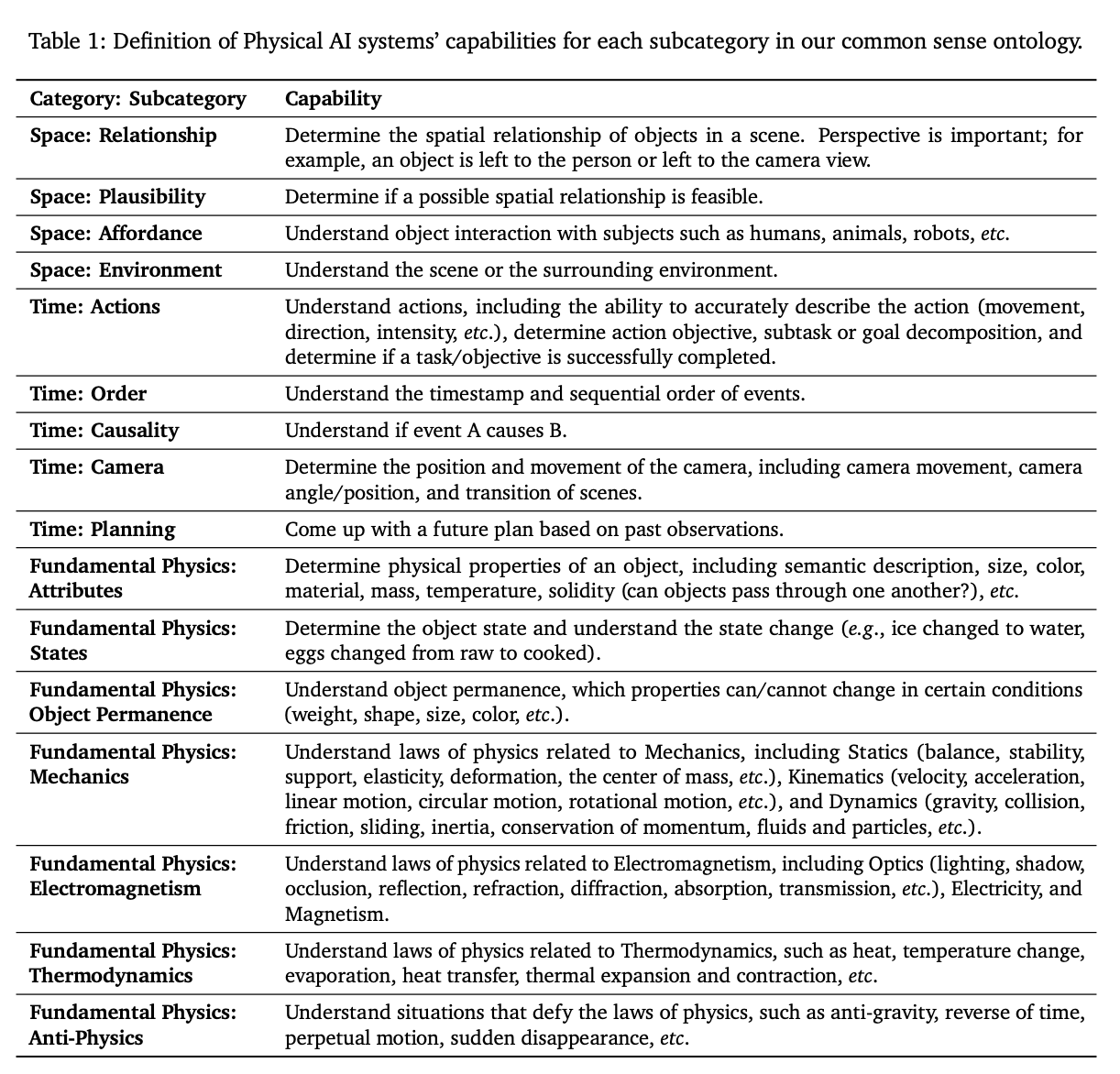
물리 현상을 정의하기 위해 넓은 범위의 구조를 소개한다. 공간, 시간 그리고 다른 물리 형상에 대하여 그리고 이는 16개의 세부적인 서브 카테고리로 나눠진다. 우리는 과정보다 능력에 초점을 맞춘다. ontology는 physical ai가 가져야 하는 핵심 능력들을 정의한다. 예를 들어 물체간의 공간적 과계, 이벤트의 순서 그리고 물체의 영속성은 physical ai의 기본이 된다. 그러나 이러한 시스템은 사람처럼 행동하게 하는데 필수적이지 않다(두 다리로 걷가나 손가락으로 집기).
Embodied Reasoning
physical ai는 다이나믹하고 불확실하고 여러 복잡한 물리 현상에 의해 제약되는 현실에서 작동한다. 수학이나 프로그래밍과는 다르게 추론을 구현하는 것은 AI가 세계와 소통하고 학습하는 것을 요한다. 단순 관찰이 아니라 행동을 통해 환경이나 미래를 예측해야한다.
-
복잡한 감각 입력 처리 (Process Complex Sensory Inputs)
제한된 상황에서의 심볼릭 추론과 다르게 embodied reasoning은 raw, 불완전하고 애매한 정보로부터 의미있는 패턴을 추출해야한다. -
행동 효과 예측 (Predict Action Effects)
액션은 물리적 결과를 가져오고 효과적인 추론은 이유와 결과의 관계를 파악해야한다. AI는 물체에 힘이 가해질 때 어떤 응답을 할지, 로봇의 주변은 어떻게 상호작용할지 예측해야 한다. -
물리적 제약 존중 (Respect Physical Constraints)
추상적인 문제 해결은 이산적 선택 최적화로 해결할 수 있으나 재질, 표면, 재료와 같은 현실의 물리 정보를 이해해야 한다. 이는 AI가 장기 행동 계획을 세우게 된다. -
상호작용으로부터 학습 (Learn from Interaction)
phsycal ai에서 액션은 독립적으로 벌어지지 않는다. 모든 움직임과 결정은 환경에 영향을 미치고 피드백을 생성한다. embodied reasoning은 지속적으로 작용에 대해 업데이트하며 이해햐애 한다.
embodied reasoning은 하나의 agent에 해당되는 내용은 아니며 사람, 동물, 다양한 범위의 로봇에 해당된다. 모든 에이전트가 유사한 embodied reasoning 과정을 필요로 한다.

이번 논문에서는 Learn from Interaction을 제외한 embodied reasoning을 다룬다. 특히, Process Complex Sensory Inputs와 Predict Action Effects에 집중한다. 작업이 완료되었는지를 판별하고 다음 액션을 예측하고 해당 액션이 가능한 것인지 평가한다.
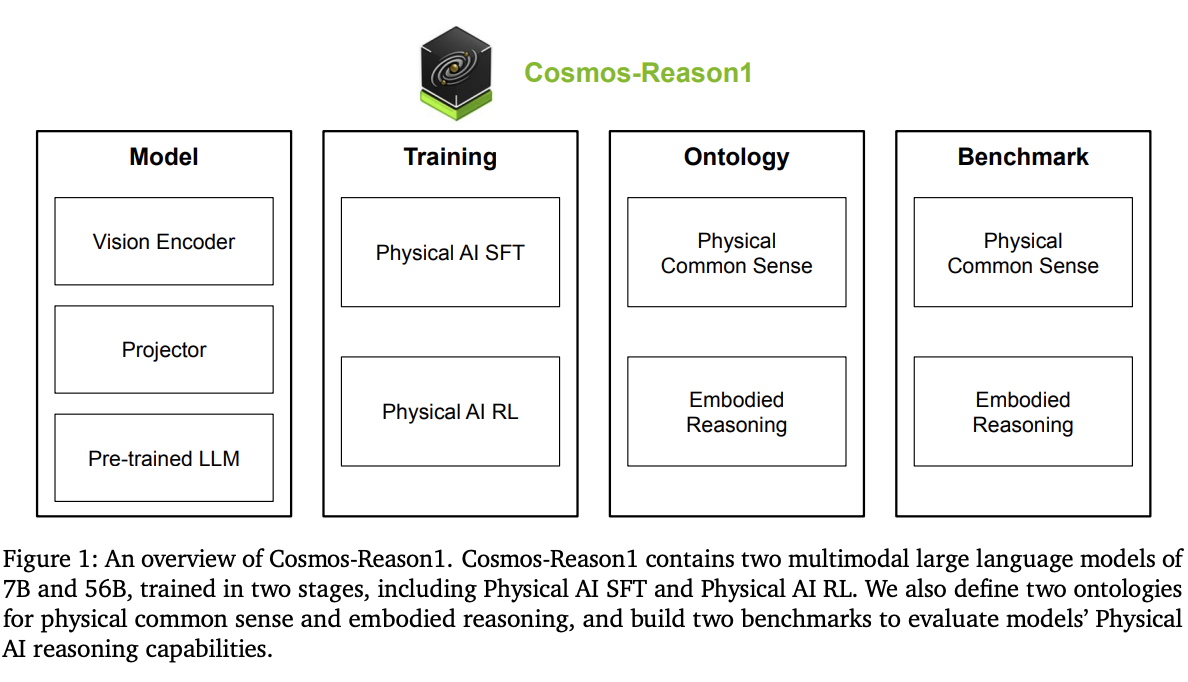
Architecture Summary
[cite_start]Cosmos-Reason1은 물리 세계의 시각적 입력(비디오)을 이해하고, 긴 연쇄 사고(Chain-of-Thought) 과정을 통해 추론하며, 자연어로 다음 행동을 결정하는 멀티모달 대규모 언어 모델(LLM)입니다[cite: 8, 54, 55].
For Cosmos-Reason1-7B, we choose Qwen2.5-VL (Bai et al., 2025) as our pre-trained model and follow the same image and video processing.
For Cosmos-Reason1-56B, we leverage InternViT-300M-V2.5 (Chen et al.,
2024) as our vision encoder and Nemotron-H (NVIDIA, 2025) as our LLM backbone.
Qwen2.5VL을 사전 학습 모델로 사용하며 같은 이미지 비디오 처리를 사용한다. 다이나믹하게 이미지를 12개의 타일로 나누며 각각은 이미지 해상도에 따라 448x448 pixel을 지닌다. 게다가 썸네일 타일도 사용한다. 32프레임을 균일하게 추출하며 초당 2개의 프레임을 멕시멈으로 구성한다.
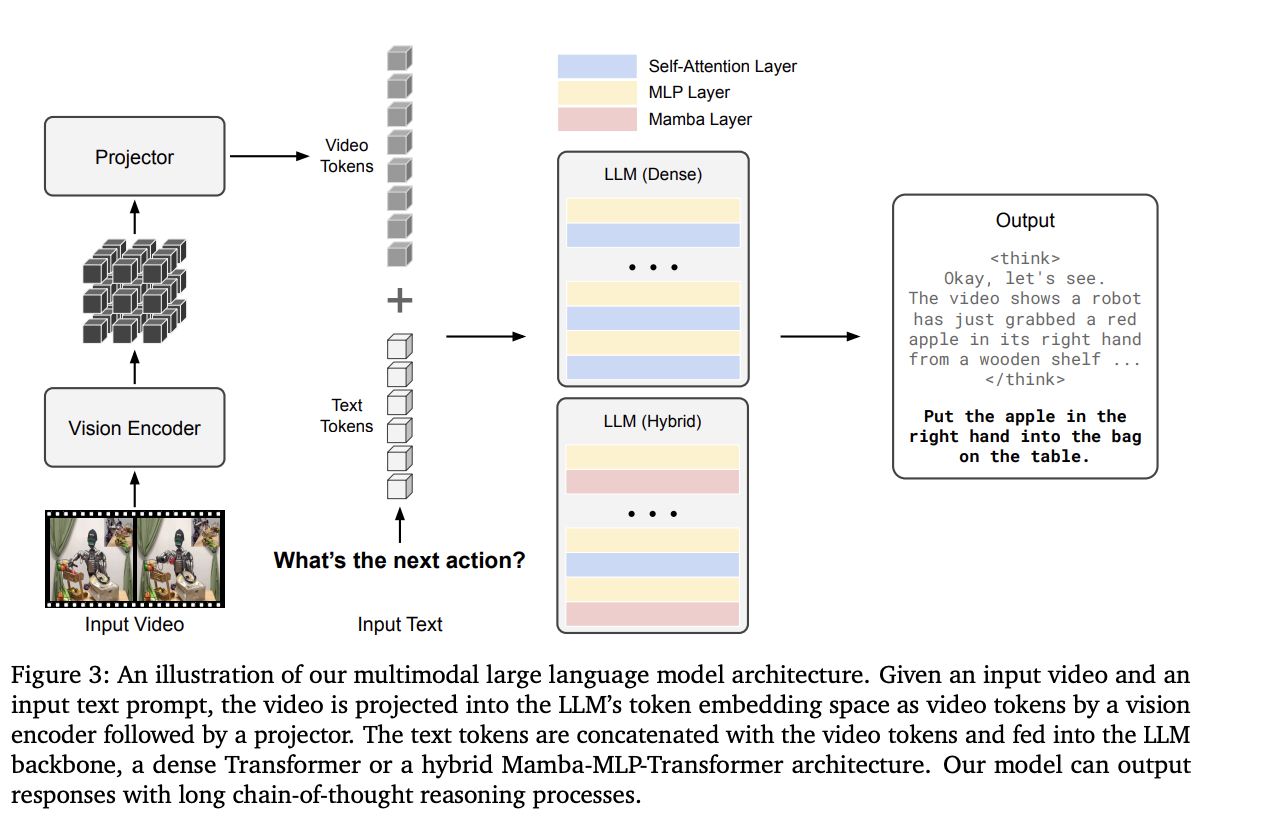
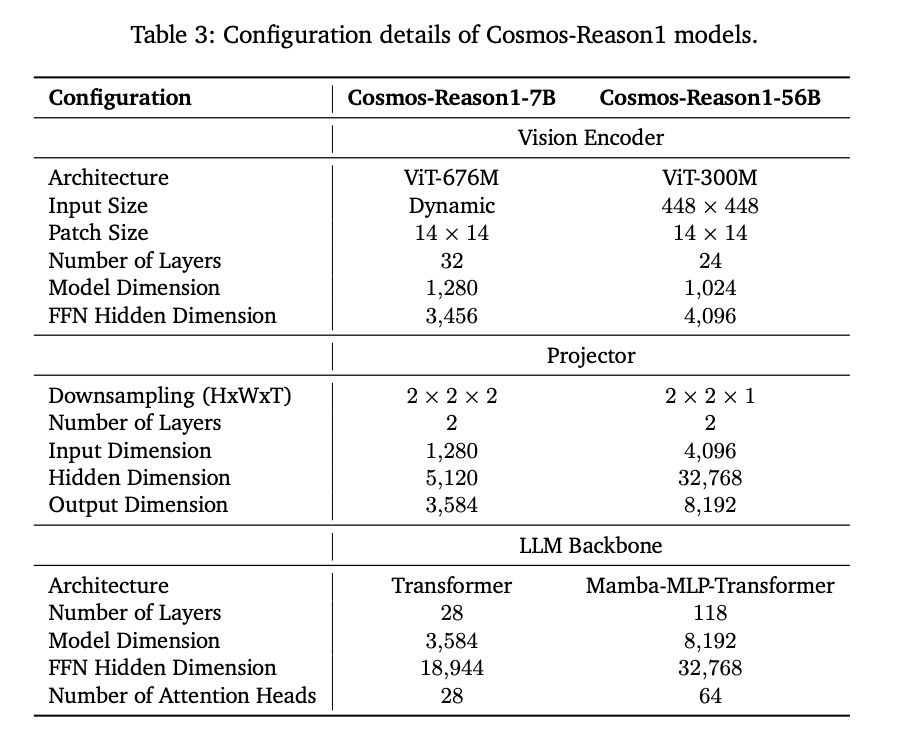
[cite_start]아키텍처는 크게 네 부분으로 구성됩니다[cite: 50]:
- 모델 (Model):
- [cite_start]비전 인코더 (Vision Encoder): 비디오 입력을 처리하여 시각적 특징을 추출합니다[cite: 56]. [cite_start]InternViT-300M-V2.5가 사용되었습니다[cite: 165].
- [cite_start]프로젝터 (Projector): 추출된 시각적 특징을 텍스트 토큰 임베딩 공간에 정렬시키는 역할을 합니다[cite: 56].
- 사전 학습된 LLM (Pre-trained LLM): 텍스트와 정렬된 시각적 토큰을 입력받아 최종 출력을 생성합니다. [cite_start]여기서는 효율적인 장문 처리 능력을 위해 Transformer와 Mamba 아키텍처를 결합한 하이브리드 Mamba-MLP-Transformer 구조를 채택했습니다[cite: 56, 57, 173].
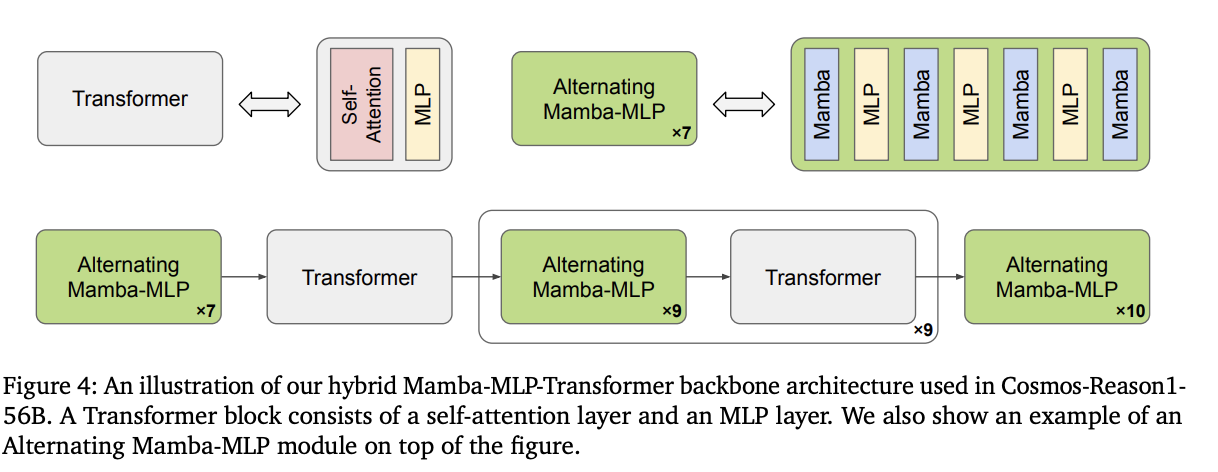
트랜스포머 구조는 혁신을 이끌며 언어 모델의 기본이 되었다. 다만 셀프 어텐션 메커니즘은 On^2의 복잡도를 가지는 반면 최근 mamba 구조는 잠재 공간 선별로 선형적 시퀀스 모델을 제시한다. 이는 더 효율적이고 롱 시퀀스를 다룰 수 있게 한다. 실용적으로, 선별적인 잠재 공간의 mamba는 long sequence에서 모든 디테일을 포착하기는 어렵다. 따라서 트랜스포머 레이어의 일부분을 포함한다. 이를 hybrid mamba mlp transformer이다.
- 학습 (Training):
- [cite_start]4단계로 구성된 체계적인 학습 과정을 거칩니다[cite: 13, 80]:
- [cite_start]Vision Pre-Training: 시각과 텍스트 양식을 정렬합니다[cite: 40].
- [cite_start]General SFT: 일반적인 비전-언어 태스크 능력을 학습합니다[cite: 43].
- [cite_start]Physical AI SFT: 물리적 상식과 구체화된 추론 능력에 특화된 데이터를 집중적으로 학습합니다[cite: 45].
- [cite_start]Physical AI RL: 규칙 기반의 검증 가능한 보상을 사용하여 모델의 추론 능력을 더욱 강화합니다[cite: 49].
- [cite_start]4단계로 구성된 체계적인 학습 과정을 거칩니다[cite: 13, 80]:
GRPO를 강화학습 알고리즘으로 채택한다. 이는 간단하고 계산 효율성을 지닌다. 최적화를 진행할 때 개별 보상을 절대적인 값으로 쓰는 대신, 같은 프롬프트에 대해 생성된 여러 응답들의 상대적 보상을 사용한다.

응답의 품질을 절대적 기준이 아니라 여러 응답들의 상대적 우수성을 평가한다. 이는 보상의 절대값 크기에 덜 민감하며 다양한 출력이 가능한 RL 학습에 적합하다. Critic을 훈련하지 않아도 된다.

-
온톨로지 (Ontology):
- [cite_start]Physical AI가 갖춰야 할 핵심 능력을 체계적으로 정의합니다[cite: 25].
- [cite_start]물리적 상식 (Physical Common Sense): 공간, 시간, 기본 물리 법칙 3가지 대분류와 16개의 세부 분류로 구성된 계층적 구조를 가집니다[cite: 10, 26, 97].
- [cite_start]구체화된 추론 (Embodied Reasoning): 인간, 로봇 팔, 휴머노이드, 자율주행차 등 다양한 물리적 에이전트에 걸쳐 일반화되는 4가지 핵심 추론 능력을 2차원 구조로 정의합니다[cite: 11, 28].
-
벤치마크 (Benchmark):
- [cite_start]위에서 정의한 온톨로지를 기반으로 모델의 물리적 상식과 구체화된 추론 능력을 평가하기 위한 자체 벤치마크를 구축했습니다[cite: 14, 82].
Dataset / 실험 조건
[cite_start]모델 학습은 크게 4단계로 진행되며, 각 단계별로 특화된 데이터를 사용합니다[cite: 239, 240].
- 1. [cite_start]Vision Pre-Training: 캡셔닝, VQA 등 다양한 태스크를 포함하는 1억 3천만 개의 이미지-텍스트 데이터셋을 사용하여 비전 인코더와 LLM 백본을 연결하는 프로젝터만 학습시킵니다[cite: 244, 245, 247].
- 2. [cite_start]General SFT: 600만 개의 이미지-텍스트 샘플과 200만 개의 비디오-텍스트 샘플을 사용하여 모델 전체를 엔드투엔드로 학습시켜 기본적인 비전-언어 능력을 구축합니다[cite: 252, 255].
- 3. Physical AI SFT:
- [cite_start]물리적 상식 데이터: 고품질 비디오에 대해 인간이 직접 또는 VLM을 통해 상세한 캡션을 생성하고, 이를 기반으로 LLM(DeepSeek-R1)을 이용해 질문-답변(VQA) 및 연쇄 사고(CoT) 데이터를 생성합니다[cite: 261, 262, 276, 288].
- [cite_start]구체화된 추론 데이터: BridgeData V2, RoboVQA, AgiBot, HoloAssist 등 기존 로봇 및 자율주행 데이터셋을 "과업 완료 검증", "행동 가능성 판단", "다음 행동 예측"이라는 세 가지 핵심 속성에 맞춰 재가공합니다[cite: 263, 321].
- [cite_start]직관적 물리 데이터: 공간 퍼즐, 시간의 방향성(Arrow-of-Time), 객체 영속성(Object Permanence)과 같은 근본적인 물리적 추론 능력을 학습시키기 위한 데이터를 자체적으로 생성합니다[cite: 267, 400].
- 4. Physical AI RL:
- [cite_start]SFT 데이터를 객관식 질문(MCQ) 형식으로 변환하여, 정답 여부를 통해 규칙 기반의 검증 가능한 보상을 설계합니다[cite: 65, 455]. [cite_start]이를 통해 별도의 보상 모델 없이 강화학습을 수행합니다[cite: 613].
Results Table 해석
물리적 상식 (Physical Common Sense) 결과
| Methods | Space | Time | Other Physics | Avg. |
|---|---|---|---|---|
| GPT-40 | 61.3 | 54.7 | 50.9 | 55.6 |
| OpenAI 01 | 63.8 | 58.1 | 58.0 | 59.9 |
| 56B pre-trained backbone | 61.3 | 68.1 | 45.1 | 58.2 |
| Cosmos-Reason1-56B | 61.3 | 65.5 | 53.9 | 60.2 (+2.0) |
- [cite_start]Cosmos-Reason1-56B 모델은 Physical AI SFT를 통해 기존 백본 모델 대비 2.0%의 성능 향상을 보이며, OpenAI 01을 능가하는 최고의 평균 점수(60.2)를 달성했습니다[cite: 578]. [cite_start]이는 자체적으로 구축한 물리적 상식 데이터셋이 모델의 성능 향상에 효과적이었음을 보여줍니다[cite: 576].
구체화된 추론 (Embodied Reasoning) 결과
| Models | BridgeData V2 | RoboVQA | Agibot | HoloAssist | AV | RoboFail | Avg. |
|---|---|---|---|---|---|---|---|
| GPT-40 | 42.0 | 71.8 | 32.0 | 65.0 | 46.0 | 63.0 | 53.3 |
| 56B pre-trained backbone | 37.0 | 77.2 | 37.0 | 65.0 | 41.0 | 64.0 | 53.5 |
| Cosmos-Reason1-56B | 65.0 | 80.0 | 47.6 | 57.8 | 65.8 | 66.2 | 63.7 (+10.2) |
- [cite_start]Cosmos-Reason1 모델들은 백본 모델 대비 10% 이상의 큰 폭으로 성능이 향상되었습니다[cite: 584]. [cite_start]특히 56B 모델은 기존 백본 대비 10.2%p 상승한 63.7점의 평균 점수를 기록했습니다[cite: 587]. [cite_start]이는 Physical AI SFT가 모델의 구체화된 추론 능력을 크게 향상시켰음을 증명합니다[cite: 585].
강화학습(RL) 후 성능 변화 (Cosmos-Reason1-8B)
| Models | Common Sense | Embodied Reasoning (Avg.) | Intuitive Physics (Avg.) |
|---|---|---|---|
| Cosmos-Reason1-8B | 52.3 | 58.9 | 65.7 |
| + Physical AI RL | 55.1 | 67.1 (+8.2) | 68.7 (+3.0) |
- [cite_start]Physical AI RL 후속 학습을 통해 모든 벤치마크에서 성능이 추가적으로 향상되었습니다[cite: 637, 652]. [cite_start]특히 구체화된 추론 능력은 8.2%p라는 높은 향상 폭을 보였습니다[cite: 631]. [cite_start]이는 규칙 기반의 보상을 사용한 강화학습이 모델의 물리적 추론 능력을 효과적으로 강화했음을 보여줍니다[cite: 78, 652].
한계점 / 향후 연구
한계점
- [cite_start]고난도 추론 데이터의 부족: 직접 제작한 고난도 벤치마크인 RoboFail에서는 SFT와 RL 단계를 거쳐도 성능이 크게 오르지 않았습니다[cite: 638, 639]. [cite_start]이는 복잡한 물리적 제약이나 미묘한 시각적 단서를 포착해야 하는 시나리오에 대한 훈련 데이터가 부족하기 때문으로 분석됩니다[cite: 640, 641].
- [cite_start]시간의 방향성 추론의 어려움: 직관적 물리 테스트에서 '시간의 방향성(Arrow of Time)' 추론 능력은 RL 후에도 크게 개선되지 않아 여전히 도전적인 과제로 남아있습니다[cite: 653].
향후 연구
- [cite_start]상호작용을 통한 학습: 이 논문에서는 "상호작용으로부터 학습(Learn from Interactions)"하는 능력을 향후 연구 과제로 남겨두었습니다[cite: 147]. [cite_start]AI가 환경과 직접 상호작용하며 얻는 피드백을 통해 동적으로 행동을 개선하는 능력을 개발하는 것이 중요합니다[cite: 138].
- [cite_start]고난도 데이터셋 확장: RoboFail 벤치마크에서 드러난 한계를 극복하기 위해, 복잡하고 미묘한 실제 상황을 반영하는 대표적인 훈련 샘플을 추가로 구축하여 모델 성능을 개선할 필요가 있습니다[cite: 643].
- [cite_start]모델 공개: Physical AI 분야의 발전을 촉진하기 위해 코드와 사전 학습된 모델을 NVIDIA Open Model License 하에 공개할 예정입니다[cite: 16, 771].
🔗 관련 글
