InternVL3 논문 리뷰 (arXiv:2504.10479v3)
Title / Year / Venue
- [cite_start]Title: InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models [cite: 2]
- [cite_start]Year: 2025 (초판 공개 기준) [cite: 1]
- [cite_start]Venue: arXiv (프리프린트 논문) [cite: 1]
Problem Statement
[cite_start]기존의 강력한 대규모 비전-언어 모델(MLLM)들은 대부분 텍스트만 이해하는 언어 모델을 여러 단계의 복잡한 파이프라인을 거쳐 시각 능력을 지원하도록 '개조'하는 "사후(post-hoc)" 방식으로 만들어졌습니다[cite: 18, 19]. [cite_start]이 접근 방식은 시각과 언어라는 서로 다른 양식을 통합할 때 정렬(alignment) 문제를 일으키고 [cite: 10, 128][cite_start], 이를 해결하기 위해 많은 계산 자원이 소모되는 비효율적인 튜닝 과정이 필요했습니다[cite: 129, 130].
[cite_start]따라서 이 논문은 이러한 다단계 파이프라인의 복잡성과 비효율성을 해결하기 위해, 사전 학습 단계부터 텍스트와 이미지 데이터를 함께 학습시켜 언어와 시각 능력을 동시에 습득하는 '네이티브 멀티모달 사전학습(native multimodal pre-training)' 패러다임을 제안합니다[cite: 8, 131, 251].
Key Idea (1 sentence)
[cite_start]사전 학습 단계에서부터 순수 텍스트와 다양한 멀티모달 데이터를 함께 학습시켜 언어와 시각 능력의 근본적인 정렬을 이루고, 여기에 고급 후속 학습 및 테스트 시점의 확장 전략을 더하여 모델의 성능을 극대화한다[cite: 11, 132, 133].
Architecture and Method Summary
[cite_start]InternVL3는 기존의 "ViT-MLP-LLM" 구조를 따르지만[cite: 214], 학습 패러다임과 여러 기술적 요소에서 큰 차별점을 가집니다.
The multilayer perceptron (MLP) utilized in the model is a two-layer network with
random initialization. In line with the approach taken in InternVL2.5, InternVL3 incorporates a pixel unshuffle
operation to enhance scalability for processing high-resolution images. This operation reduces the visual token
count to one-quarter of its original value, representing each 448×448 image tile with 256 visual tokens.
MLP Layer를 2개를 사용하여 VLM과 LLM의 연결고리 역할을 수행함. 또한, Internvl2.5에서의 pixel unshuffle을 사용하여 고해상도 이미지의 토큰 수를 4분의 1로 줄였다.
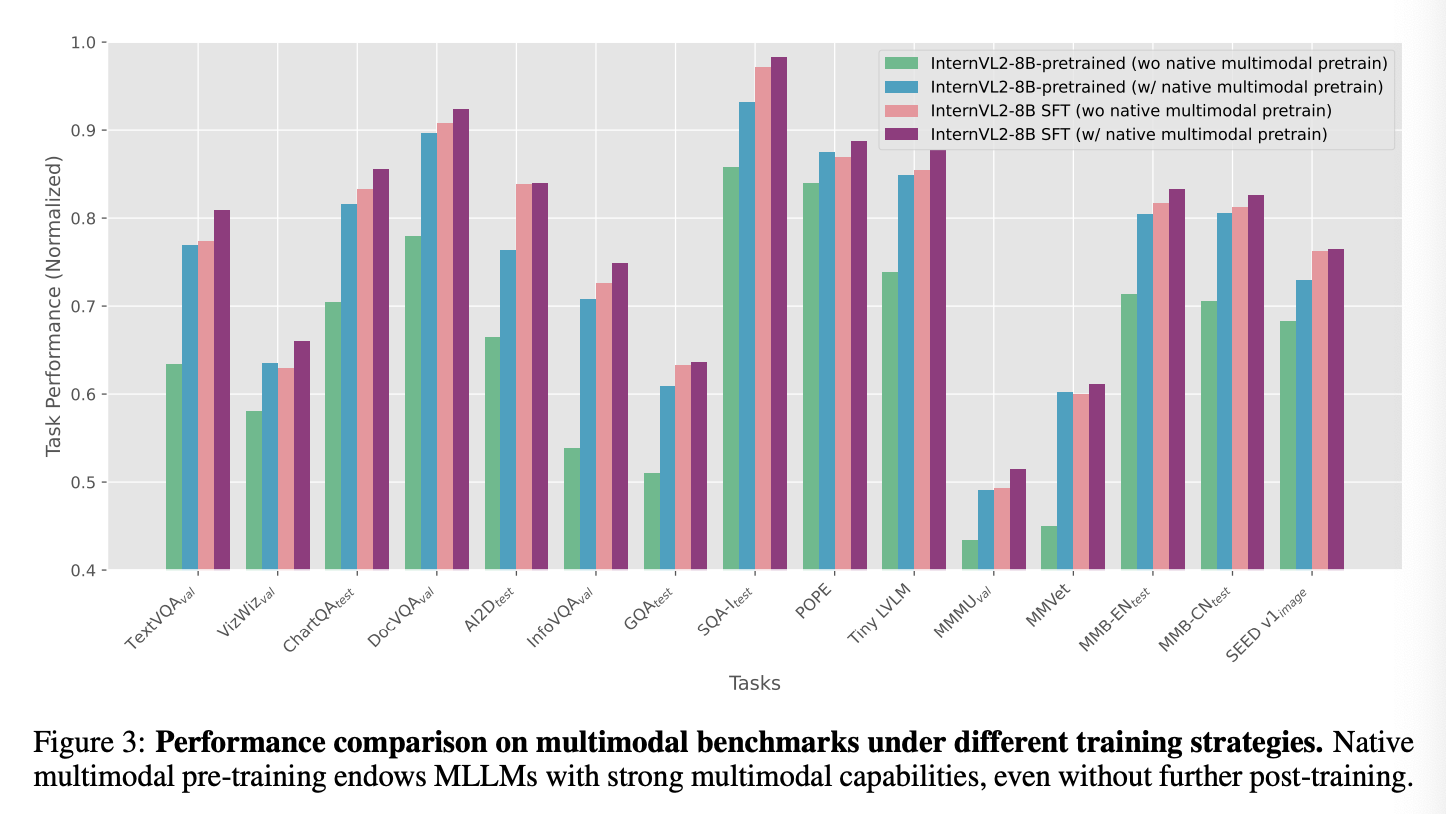
- 네이티브 멀티모달 사전학습 (Native Multimodal Pre-Training)
- 이 논문의 가장 핵심적인 아이디어입니다. [cite_start]기존 방식처럼 텍스트 모델을 먼저 만들고 나중에 이미지 데이터를 학습시키는 것이 아니라, 사전 학습 과정에서부터 대규모 텍스트 데이터와 이미지-텍스트 데이터를 섞어서 한 번에 학습시킵니다[cite: 251, 252].
- [cite_start]이를 통해 모델은 언어 능력과 시각 능력을 동시에, 그리고 더 통합된 방식으로 습득하게 되어 모달리티 간의 정렬 문제를 근본적으로 해결합니다[cite: 253, 277].
- [cite_start]실험적으로 언어 데이터와 멀티모달 데이터의 학습 비율을 1:3으로 설정했을 때 전반적인 성능이 가장 좋았습니다[cite: 294].
This unified training scheme enables the pre-trained model to
learn both linguistic and multimodal capabilities simultaneously, ultimately enhancing its capability to handle
vision-language tasks without introducing additional bridging modules or subsequent inter-model alignment
procedures.
같이 학습을 진행함으로써 기존에 필요로 했던 bridging modules (like Q-former)에 대한 필요성을 감소시켰다. 결과적으로 같이 학습시키는 것은 모든 파라미터가 함께 참여하여 학습하여 더 좋은 성능을 갖게 된다.
where wi denotes the loss weight of token i. Although this formulation naturally propagates gradients through
tokens of all modalities, we restrict the loss computation exclusively to text tokens, resulting in
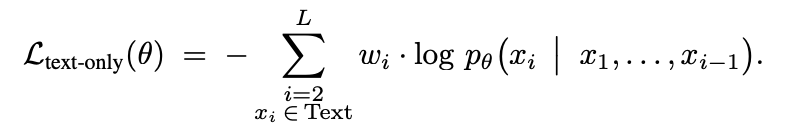
또한, 텍스트가 생성되는 부분만의 로스를 계산한다. 이런 선택적인 목적함수는 시각 토큰이 직접적인 예측에 활용되는 것이 아닌 맥락으로 적용하게 되며 결과적으로 멀티모달 정보를 임베딩하는 방향으로 학습되어진다.

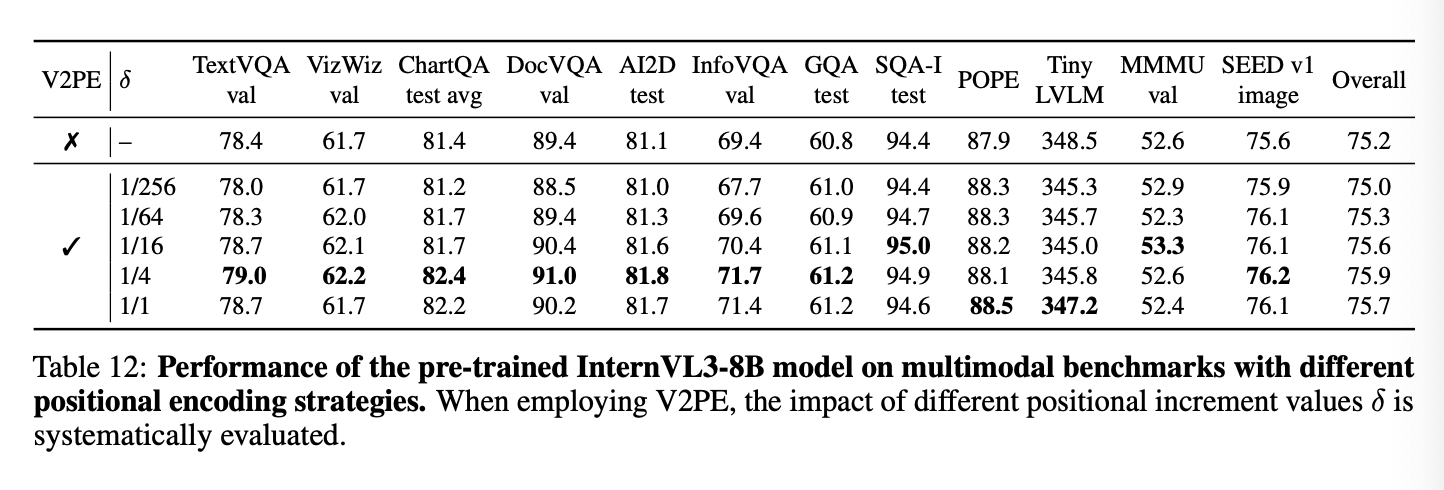
- 가변 시각 위치 인코딩 (Variable Visual Position Encoding, V2PE)
- [cite_start]고해상도 이미지나 긴 비디오와 같이 시각적 토큰이 많은 데이터를 효율적으로 처리하기 위해 도입된 기술입니다[cite: 135, 223, 579].
- [cite_start]기존에는 모든 토큰(텍스트, 시각)의 위치를 1씩 증가시켰지만, V2PE는 텍스트 토큰은 1씩, 시각 토큰은 1보다 작은 값()만큼 위치를 증가시킵니다[cite: 237, 238].
- [cite_start]이를 통해 전체적인 위치 인덱스 길이를 압축하여 긴 시각적 문맥을 효과적으로 처리할 수 있습니다[cite: 229].
- [cite_start]수식은 다음과 같이 표현됩니다[cite: 240]:
[cite_start]여기서 는 과 같은 값 중에서 무작위로 선택됩니다[cite: 246].
학습할 때는 무작위로 이미지마다 무작위로 선택되어 학습이 진행되며 실제 추론시에는 입력된 이미지 수에 따라 결정되어 진행한다.만약 δ = 1, V2PE reverts to the conventional positional encoding used in InternVL2.
- 고급 후속 학습 (Post-Training)
사전 학습 단계 이후 아래와 같은 두개의 후속 학습 전략을 선택한다.
-
[cite_start]지도 미세 조정 (SFT): 사전 학습이 끝난 모델에 3D, GUI, 비디오, 창의적 글쓰기 등 더 다양하고 품질 높은 데이터(약 2,170만 개)를 학습시켜 대화 및 지시 수행 능력을 강화합니다[cite: 300, 304, 305, 331].
In this phase, the techniques of random JPEG compression, square loss re-weighting,
and multimodal data packing proposed in InternVL2.5 방식 또한 적용된다. -
[cite_start]혼합 선호도 최적화 (MPO): 좋은 답변(positive sample)과 나쁜 답변(negative sample)을 모두 활용하여 모델이 응답의 절대적, 상대적 품질을 학습하게 합니다[cite: 300, 302]. [cite_start]이를 통해 모델의 추론 능력을 더욱 향상시킵니다[cite: 309].
During Pre-training and SFT, the model is trained to predict the next token
conditioned on previous ground-truth tokens. However, during inference, the model predicts each token based on its own prior outputs.
모델이 학습을 진행할 때는 다음 토큰을 생성하기 위해 previous ground-truth tokens을 기반으로 학습을 진행하지만 실제 추론 시에는 on its own prior outputs을 기반으로 생성하게 된다. 이는 한번 잘못 추론하게 되면 누적은 점점 커져 잘못된 결과를 불러오고 이는 특히 COT에서 큼. 이를 distribution shift라 함.
L_p (Preference loss)
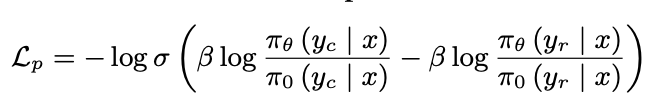
positive vs negative 응답 쌍을 비교해서, positive 응답의 확률이 더 높아지도록 조정
일반적으로 ranking loss나 pairwise logistic loss 사용
L_q (Quality loss)
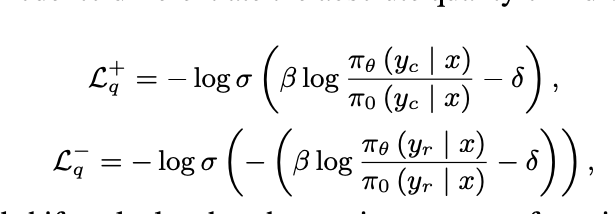
응답의 전반적인 품질 점수(예: 가독성, 문법, 일관성)를 높이도록 유도
예: GPT 평가 점수, 휴리스틱 품질 점수
L_g (Generation loss)
전통적인 cross-entropy loss로 next token prediction
모델이 언어 생성 능력을 잃지 않도록 유지
기존 SFT만 한 모델:
“정답을 계속 들려주는 과외 선생님” → 시험에서 혼자 풀면 갑자기 실수 잦아짐
MPO 적용 모델:
“정답뿐 아니라, 틀린 풀이도 같이 보여주고, 어떤 게 더 좋은지 비교해서 학습” → 시험 상황에서도 흔들리지 않음
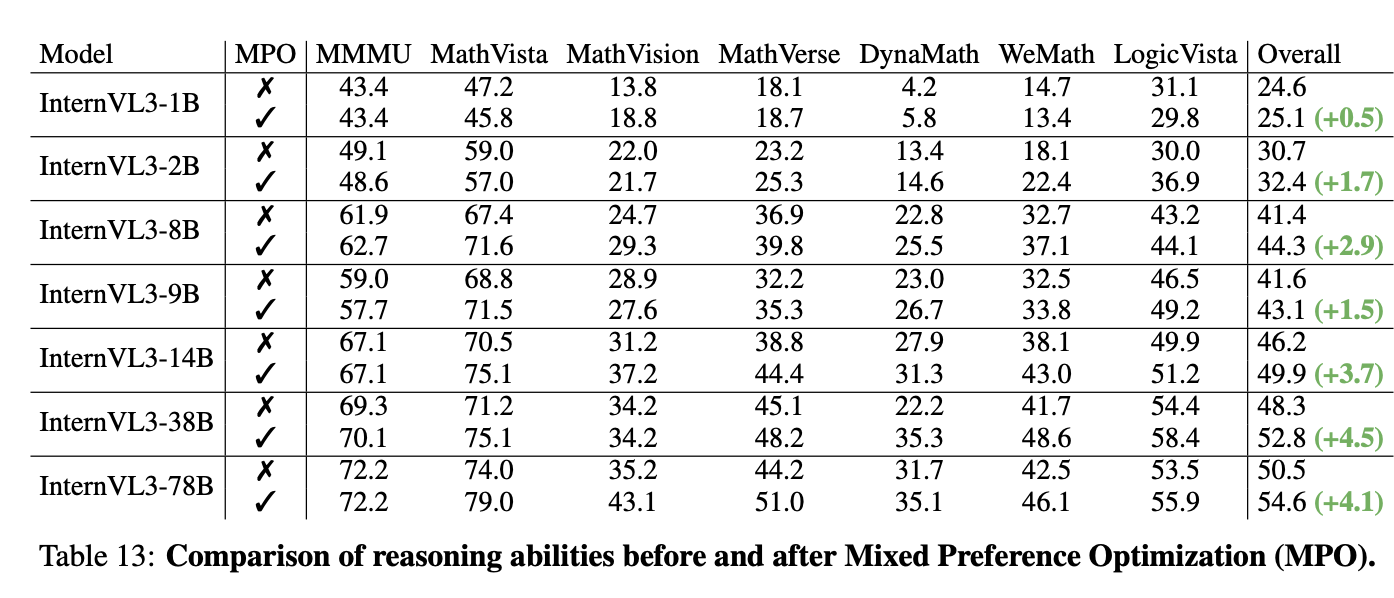
- 테스트 시점 확장 (Test-Time Scaling)
- [cite_start]추론(답변 생성) 시점에 Best-of-N 전략을 사용합니다[cite: 337, 338]. [cite_start]즉, 여러 개의 답변 후보를 생성한 뒤, 별도의 평가 모델(VisualPRM-8B)을 사용해 각 단계의 점수를 매겨 가장 좋은 답변을 선택하는 방식입니다[cite: 338]. 이를 통해 추론 및 수학 문제 해결 능력을 크게 향상시킬 수 있습니다.
Dataset / 실험 조건
- [cite_start]사전 학습 데이터: InternVL2.5에서 사용된 데이터셋을 기반으로 GUI, 툴 사용, 3D, 비디오 관련 데이터를 추가했습니다[cite: 283, 285]. [cite_start]또한, InternLM2.5의 텍스트 데이터에 오픈소스 텍스트 데이터셋을 추가하여 언어 능력을 보강했습니다[cite: 288]. [cite_start]총 학습 토큰 수는 약 2,000억 개(언어 500억, 멀티모달 1,500억)입니다[cite: 297].
전반적으로 학습 데이터가 늘어나지는 않았지만 MLP만을 학습시키는 것이 아닌 모든 파라미터를 학습하므로써 성능 향상이 존재했다.
- [cite_start]후속 학습 데이터: SFT 단계에서는 2,170만 개의 샘플을 [cite: 331][cite_start], MPO 단계에서는 약 30만 개의 선호도 쌍(preference pairs) 데이터를 사용했습니다[cite: 334].
- [cite_start]평가 벤치마크: MMMU(종합 추론), MathVista(수학), DocVQA(문서 이해), OCRBench(OCR), LongVideoBench(비디오) 등 매우 광범위한 벤치마크를 사용하여 종합적인 성능을 측정했습니다[cite: 365].
- [cite_start]비교 대상: GPT-4o, Claude 3.5 Sonnet, Gemini 2.5 Pro와 같은 최신 상용 모델 및 Qwen2.5-VL과 같은 다른 최신 오픈소스 모델들과 성능을 비교했습니다[cite: 139].
Results table 해석
주요 벤치마크 성능 비교 (Figure 1)
| 모델 | MMMU (종합) | MathVista (수학) | OCRBench (OCR) | LongVideoBench (비디오) |
|---|---|---|---|---|
| InternVL3-78B | [cite_start]72.2% [cite: 48] | [cite_start]79.6% [cite: 58] | [cite_start]906 [cite: 112] | [cite_start]65.7% [cite: 121] |
| ChatGPT-4o-latest | [cite_start]72.9% [cite: 52] | [cite_start]71.6% [cite: 62] | [cite_start]894 [cite: 115] | - |
| Gemini-2.5 Pro | [cite_start]74.7% [cite: 53] | [cite_start]80.9% [cite: 63] | [cite_start]862 [cite: 116] | - |
| Qwen2.5-VL 72B | [cite_start]70.2% [cite: 49] | [cite_start]74.8% [cite: 59] | [cite_start]885 [cite: 113] | [cite_start]60.7% [cite: 122] |
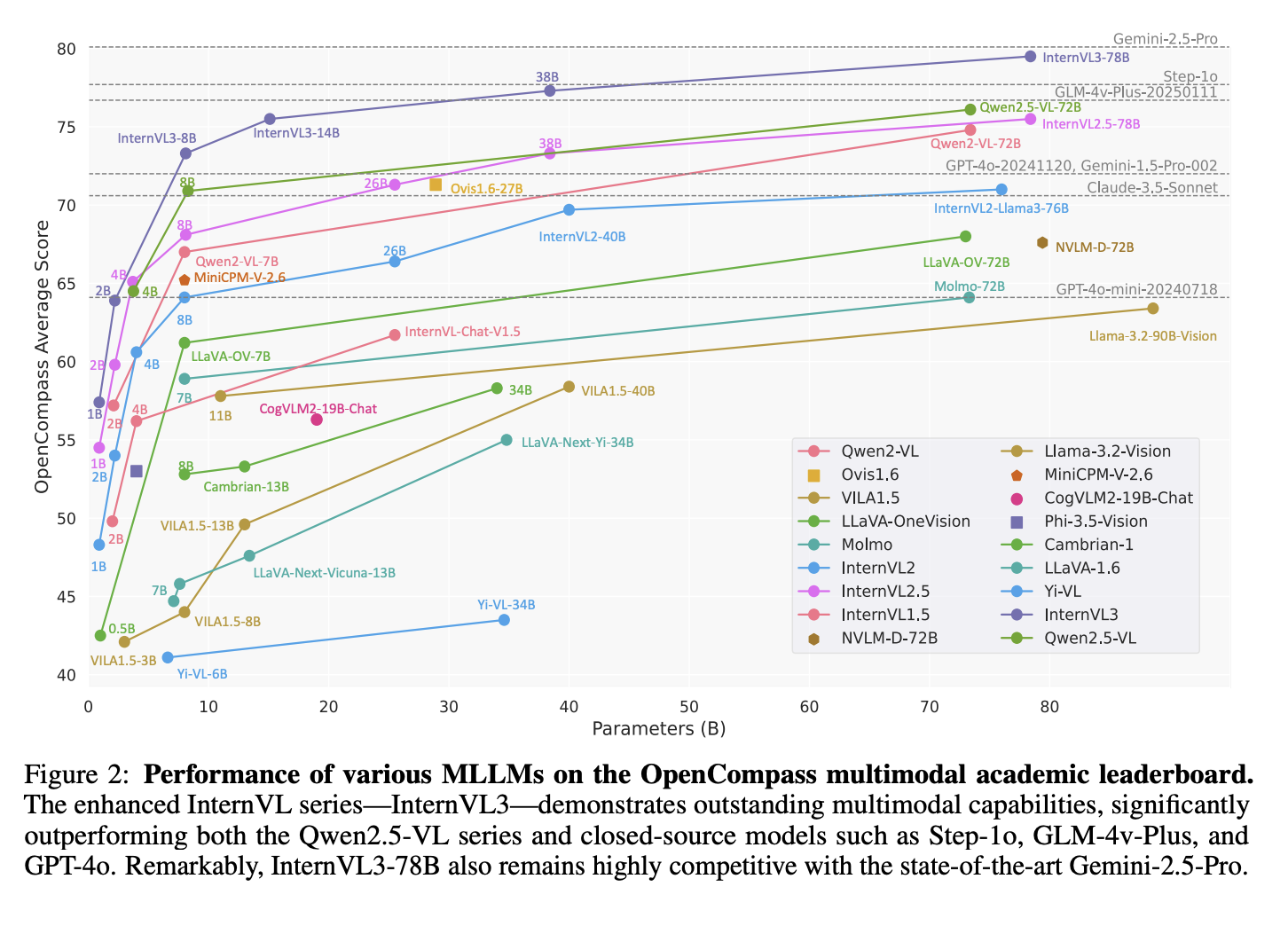
- [cite_start]종합 성능: InternVL3-78B는 MMMU 벤치마크에서 72.2점을 기록하여, 현존하는 모든 오픈소스 MLLM 중 최고 성능을 달성했습니다[cite: 13, 140, 369]. 이는 복잡한 다분야 멀티모달 문제를 해결하는 능력이 뛰어남을 의미합니다.
- [cite_start]수학 및 OCR 능력: MathVista(79.6%)와 OCRBench(906점)에서는 상용 모델인 ChatGPT-4o를 능가하는 강력한 성능을 보여주었습니다[cite: 58, 62, 112, 115].
- [cite_start]상용 모델과의 경쟁: Gemini 2.5 Pro가 일부 벤치마크(MMMU, MathVista, HallusionBench)에서 여전히 우위를 보이고 있지만 [cite: 14, 373][cite_start], InternVL3는 여러 핵심 분야에서 상용 모델과 대등하거나 그 이상의 성능을 보여주며 격차를 크게 줄였습니다[cite: 127, 139].
- [cite_start]언어 능력: 멀티모달 데이터를 함께 학습했음에도 불구하고, 순수 언어 능력 평가에서 Qwen2.5 Chat 모델보다 일관되게 우수한 성능을 보였습니다[cite: 536]. [cite_start]이는 네이티브 멀티모달 학습 방식이 언어 능력을 저해하지 않고 오히려 강화할 수 있음을 시사합니다[cite: 538, 539].
한계점 / 향후 연구
한계점
- [cite_start]시각적 위치 찾기(Visual Grounding) 성능 정체: 다른 능력들은 크게 향상되었지만, 이미지 내 특정 객체의 위치를 찾는 grounding 성능은 최상위 모델(78B)에서 이전 버전(InternVL2.5-78B)보다 소폭 하락했습니다[cite: 467]. [cite_start]이는 학습 데이터 확장이 grounding 관련 데이터를 추가로 포함하지 않았기 때문일 수 있습니다[cite: 468].
- [cite_start]일부 벤치마크에서의 열세: MuirBench와 같은 특정 다중 이미지 이해 벤치마크에서는 Qwen2.5-VL과 같은 다른 모델에 비해 여전히 성능 격차가 존재합니다[cite: 420].
- [cite_start]환각(Hallucination) 문제: MMHal과 같은 일부 환각 평가 벤치마크에서는 미미한 성능 하락이 관찰되어, 이 문제를 해결하기 위한 지속적인 연구가 필요함을 시사합니다[cite: 459].
향후 연구
- [cite_start]공개 과학(Open Science) 기여: 논문 저자들은 연구의 투명성과 재현성을 보장하고 커뮤니티의 발전을 촉진하기 위해 학습 데이터와 모델 가중치를 모두 공개할 것이라고 밝혔습니다[cite: 15, 208, 596].
- [cite_start]지속적인 개선: Gemini 2.5 Pro와 같은 모델이 일부 태스크에서 여전히 우위를 점하고 있으므로, InternVL 시리즈의 지속적인 개선이 필요함을 인정하고 있습니다[cite: 373].
- [cite_start]동적 GUI 환경으로 확장: 현재의 GUI 이해 능력을 정적인 화면을 넘어, 더 동적이고 상호작용이 가능한 환경으로 확장하는 연구를 진행할 계획입니다[cite: 512].
- [cite_start]3D 장면 이해 응용: 뛰어난 공간 추론 능력을 바탕으로 자율 주행과 같은 다양한 3D 장면 이해 관련 응용 프로그램에 모델을 통합하는 연구를 모색할 것입니다[cite: 521].
🔗 관련 글
