AdaIN (Arbitrary Style Transfer in Real-Time With Adaptive Instance Normalization) 의 논문 리뷰를 수행하겠다.
이전 Style Transfer 연구 배경
1. Style Reconstruction 과 Content Reconstruction 초창기 방법 (CVPR 2016)
content Image P 와 stle Image a 를 준비한 다음, 노이즈 이미지 x 에 대해 노이즈 이미지의 내용은 P를 따르고 스타일은 a를 따르도록 업데이트 한다. (Style Transfer)
학습 방법은 이미지를 사전 학습된 네트워크에 넣고 역전파를 통해서 기울기를 구한 다음, 기울기 값으로 각각의 픽셀값들을 조금씩 업데이트 한다.

어떻게 Style 정보와 Content 정보를 추출할까 ?
아래 보이는 그림의 오른쪽의 네트워크는 사전 학습된 CNN 이다.

- Content Loss 는 이미지를 CNN에 넣엇을 때, 특정 레이어의 Feature 값 자체가 같아지는 방향으로 업데이트를 수행
- Style Loss 는 단순히 Feature 가 같아지는 것이 아니라 이미지를 넣어서 얻은 Feature 에 대해서 gram Matrix 를 구한 뒤에 이러한 gram matrix 가 유사해질 수 있도록 업데이트를 수행
즉 특징값 자체가 유사해질 수 있도록 만드는 것은 Content 를 유사하게 만드는 것이고,
특징에 gram matrix 가 유사해질 수 있도록 만드는 것은 같은 스타일을 가지도록 만드는 것과 같다.
Style Reconstructions 을 수행 할 때는 앞쪽에서부터 뒤쪽 레이어까지 모두 사용하는 방식을 채택했고,
Content Reconstructions 을 수행할 떄는 단순히 특정 레이어의 feature 값이 유사해 질 수 있도록 만든다.
여기서 중요한 두가지는
1. 스타일 이미지로 부터 스타일을 또는 컨텐트 이미지로 컨텐트를 가져올 때 모두 사전 학습되어 있는 CNN 을 feature 를 추출하는 목적으로 사용
2. 한장의 이미지 x 를 업데이트해서 style tranfer를 수행한 결과 이미지를 만들어 낼 떄는
이러한 CNN에 이미지 넣었을 때 얻은 feature 값 자체가 다른 이미지의 feature 값과 같아질 수 있는 형태로 업데이트 하는 방식을 사용
Style Reconstruction 과 Content Reconstruction 초창기 방법의 단점
학습 과정에서 ("학습 방법은 이미지를 사전 학습된 네트워크에 넣고 역전파를 통해서 기울기를 구한 다음, 기울기 값으로 각각의 픽셀값들을 조금씩 업데이트 한다.") 너무 많은 BackProp 과 업데이트가 필요하기 때문에 많은 시간을 소요할 수 있다.
따라서 이후 연구에서는 이미지를 네트워크에서 한번 Forward 만 하면 그 네트워크가 스타일 Transfer 를 수행한 결과를 바로 뱉어낼 수 Feed Forward 를 만드는 방식으로 많은 후속 연구가 진행되었다.
2. CIN (Conditional Instance Normalization) 을 통한 Style Transfer
본 논문에서는 Adaptive Instance Normalization 을 제안했다.
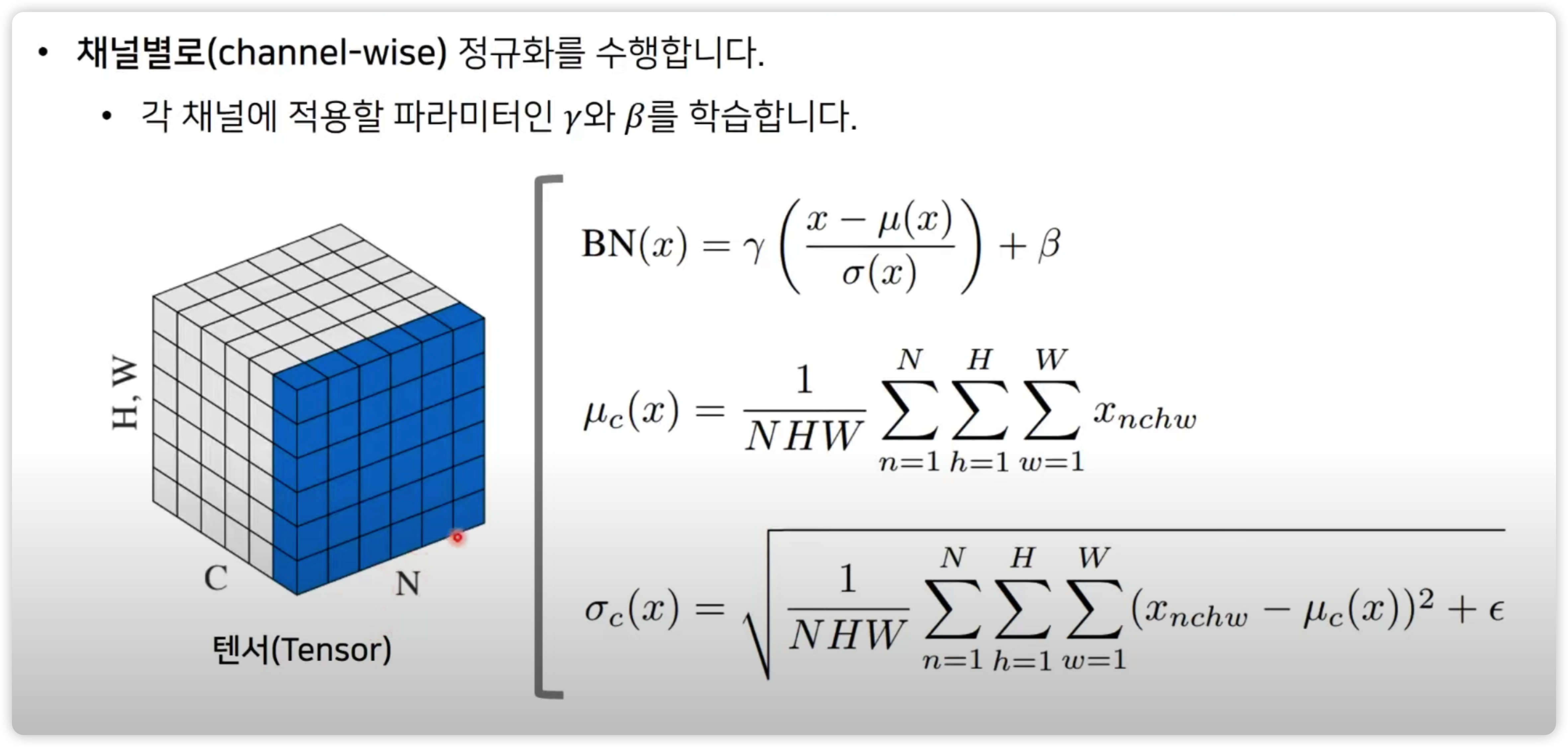
이를 이해하기 위해 Batch Normalization 을 간단하게 설명하자면 아래 그림과 같다.
Instance Normalization
BN 이후에 나온 것이 IN 인데,
- 개별적인 이미지(인스턴스) 에 대하여 각 채널별로 정규화를 수행한다.
- 개별적인 샘플(이미지)에 대하여 수행한다는 점이 BN 과 차이점이다.
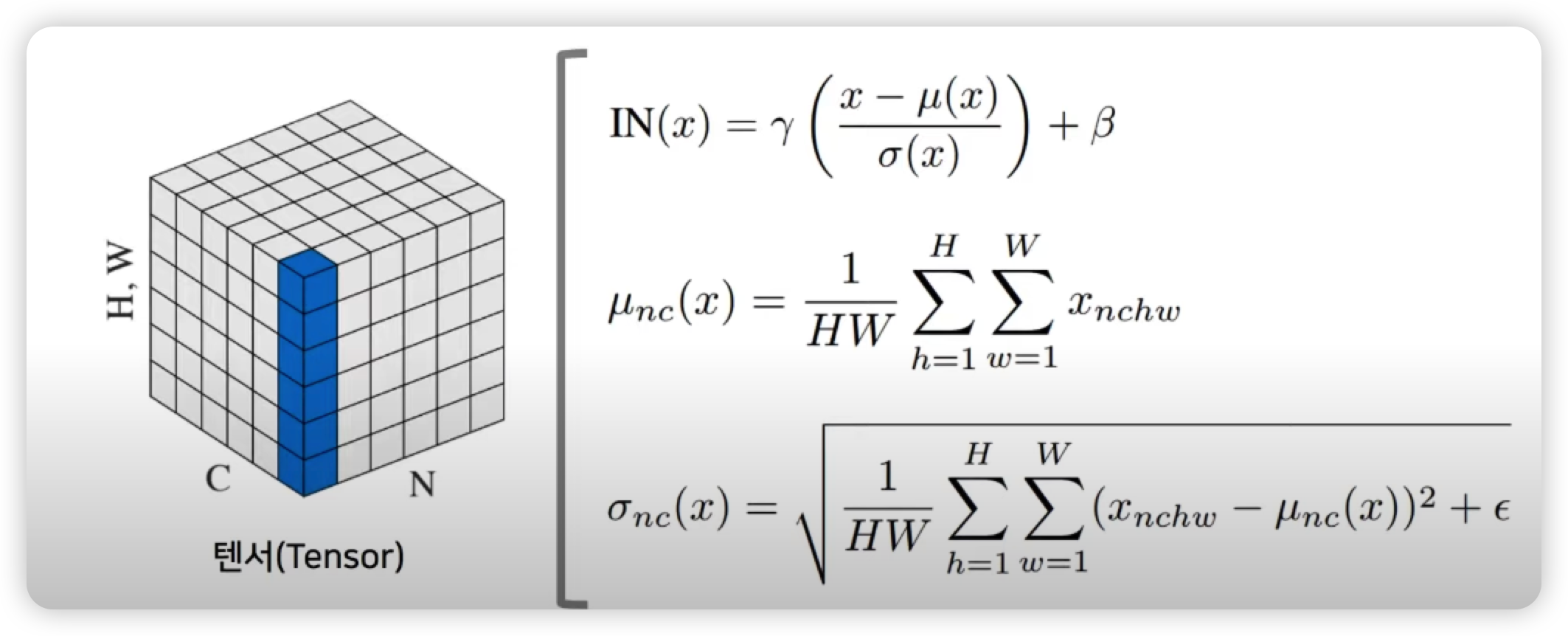
Conditional Instance Normalization
이러한 Instance Normalization 를 조금 변경 해 Conditional Instance Normalization을 수행 할 수 있다.
Conditional Instance Normalization 과 Instance Norm (IN)이 다른점은 조건에 따라 다른 feature statistics 를 갖도록 하는 것이 다르다.
아래 공식을 확인해보면
각각의 스타일 별로 감마와 배타 값이 다르게 들어가는데,
미리 정해놓은 감마와 베타 값에 의해서 완전히 다른 스타일을 적용할 수 있다는 것을 보여준다.
즉 IN 을 수행할 때 감마와 배타 값을 바꿔줘서 서로 다른 statistics 를 갖도록 만드는 것만으로도 다른 스타일을 갖도록 만들기에 충분했다는 것이다.
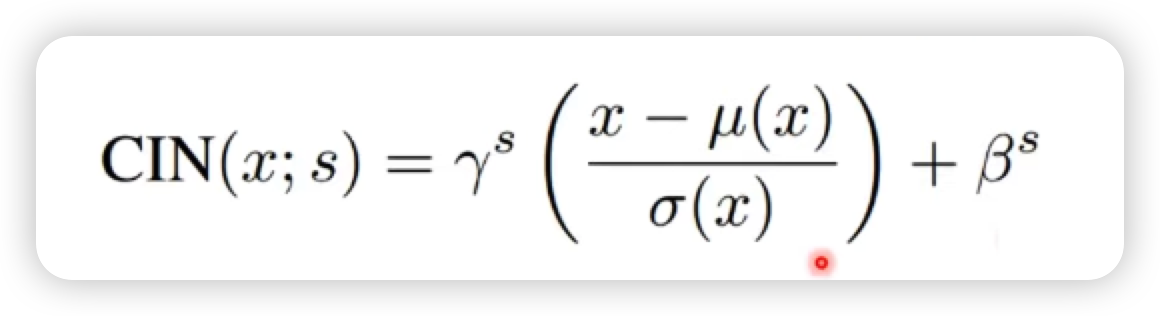
예를 들면

위 그림처럼 몇개의 스타일을 정해놓고 각각의 스타일 마다 서로 다른 감마와 배타값을 갖도록 만드는 것 만으로도 style transfer 효과를 낼 수 있다.
이러한 방법을 쓰게 되면 2FS 만큼의 추가적인 파라미터가 필요하다.
- F : Feature Map 의 개수
- S : Style
본론
지금까지는 이전에 나왔던 다양한 논문들에 대해서 알아보았고,
이제 본 논문에서 메인 아이디어를 알아보자.
-
연구 동기 : CIN으로 feature statistics를 변경하는 것만으로 style transfer 의 효과를 낼 수 있음
- 그렇다면 미리 고정된 style을 사용하지 말고 임의의 (arbitrary) 이미지로부터 스타일을 가져오자 ! -
AdaIN을 이용해 다른 원하는 이미지에서 스타일(style) 정보를 가져와 적용할 수 있습니다.
- 학습시킬 파라미터가 필요하지 않음. (감마와 베타 사용하지 않음, 이유는 다른 이미지에서 mean 과 std 값을 가져오기 때문에 별도의 파라미터가 필요하지 않음.)
- feed-forward 방식의 style transfer 네트워크에서 사용되어 좋은 성능을 보임

위 식을보면
감마와 베타를 다른 이미지로 부터 가져온 feature 상의 sigma와 mean 값으로 바꿔줬다.
즉 기존의 content 이미지에 feature 의 statistic 을 스타일 이미지에서 가져온 정보로
바꿔줌으로써 style transfer 를 수행할 수 있다.
쉽게말하면 이전에 CIN에서 사용한 조건에 대한 정보(감마와 베타)를 스타일 이미지에서 가져온 것으로 대체해보자는 아이디어다.
네트워크 구조
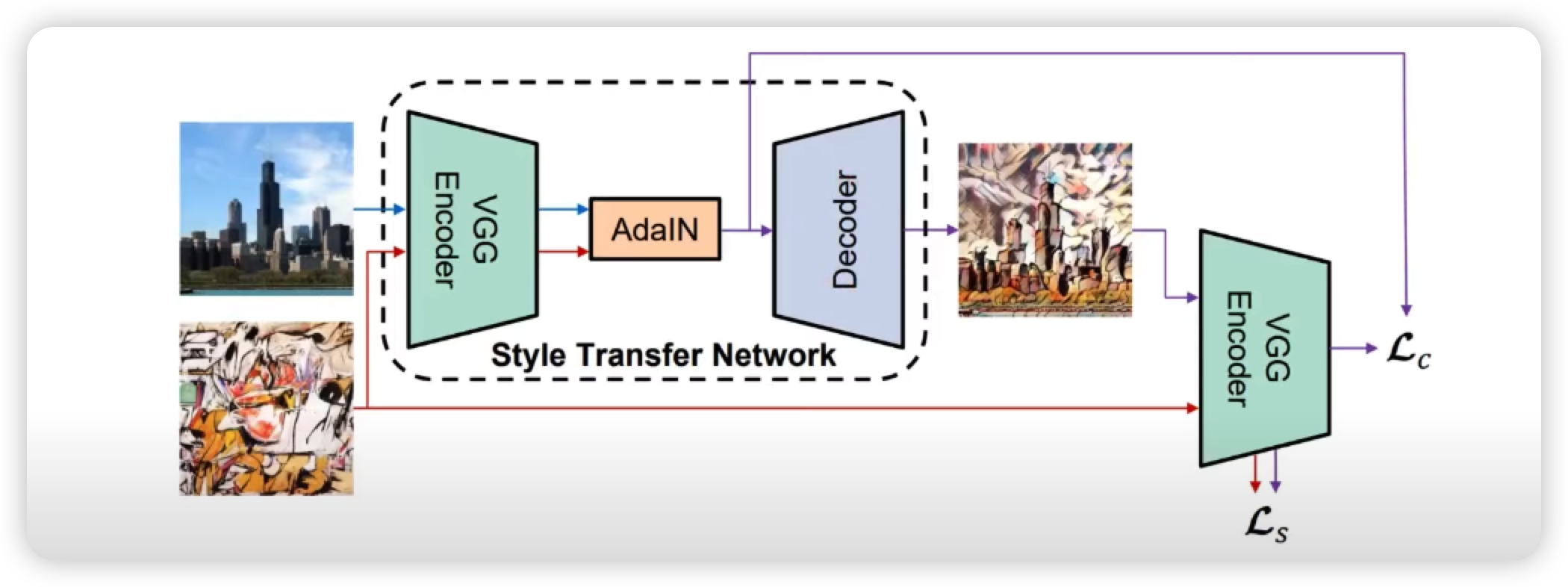
- 네트워크 중간에 있는 AdaIN이 스타일 전송(style transfer) 역할을 수행
- VG Encoder : 특징 추출 목적으로 사전 학습되어 고정된 네트워크 (학습 X)
- Decoder : 학습할 네트워크이며 결과 이미지를 생성하는 역할 수행
전체 Loss 는 Contents Loss (Lc) , Style Loss (Ls)로 구성된다.
그래서 결과 이미지의 스타일이 원본 스타일이미지를 따라갈 수 있도록 학습을 진행하고,
컨텐트의 경우에는 컨텐트 이미지를 따라갈 수 있도록 학습을 진행한다.
목적 함수

서론
최초의 Neural Style Transfaer 를 제안한 Gatys의 Style Transfer 방식은 다양한 Style을 Arbitrary 하게 (그때 그때 새로운 스타일을) 적용할 수 있는 반면에, 굉장히 느린 속도로 style transfer 를 수행한다는 단점이 있다.
이를 극복하기 위해 Feed-forward 방식으로 Style Transfer를 수행하는 방식들이 제안되었는데, 이들은 빠른속도의 Style Transfer 가능했지만, 몇가지 미리 학습된 Style 에 대해서만 Style Transfer가 가능했다.
이에 비해 AdanIN 방식은 빠른속도로 추론이 가능하면서 동시에 Arbitrary하게 새로운 스타일을 적용할 수 있는 방식이다.
Architecture 구조
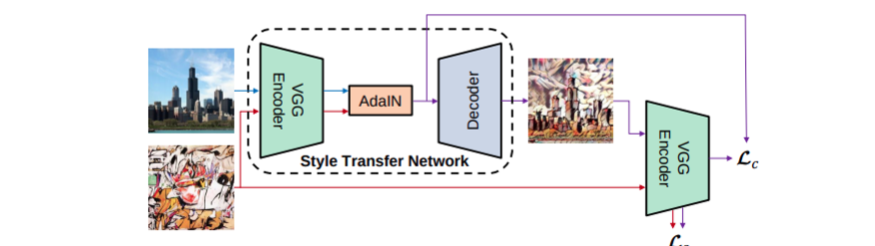
AdaIN의 네트워크 구조는 위와 같으며, 녹색의 VGG 의 pretrained 모델을 통해 Encoding을 수행하며, 이 encoder 를 feature 를 인코딩할 때, 그리고 Loss Function을 구할 때 사용한다.
즉 Encoder 는 학습 시키지 않는다는 점이 포인트다.
그러므로 네트워크 상에서 학습시키는 것을 Decoder 뿐이며, 저자들의 표현을 빌리자면, 이 Decoder 는 AdaIN으로 생성된 feature들이 decoder를 통해서 image spaace로 invert하는 법을 학습한다. 아직 설명하지 않았지만, AdaIN 내에서는 learnable parameter가 없다.
AdaIN Layer
AdaIN은 어떻게 생겼나 ?
이를 알기 전에 Style Transfer의 개념에 대해서 간단하게 알고 있어야 한다.
Style Transfer는 특정 이미지에서 Style을 뽑고, 다른 이미지에서 Contents 를 뽑아서 이를 합성한다.
AdaIN에서는 Style과 Contents에 대한 정보를 VGG Encoder 를 통해서 추출할 수 있다고 주장한다.
아주 조금만 더 깊게 들어가서...초기 연구인 Gatys 방식에서는 VGG에서 나온 Feature들에 Gram Matrix를 사용해서 Style을 표현(representation) 있다는 것을 실험적으로 보였다. 이러한 Gram Matrix가 대표적인 feature space 상의 statistics를 추출해내는 방법인데, 이 이후 많은 연구가 이루어지면서 feature space상의 여러 statistics가 Style을 표현하는데 유용하다는 것이 실험적으로 많이 밝혀졌다.
statistics? 잘모르겠다고 생각한다면 이 논문에서는 그냥 평균(mean)과 분산(variance)라고 생각해도 무방하다. AdaIN은 feature space 상의 평균과 분산이 Style에 영향을 끼친다면, 이들을 뽑아서 즉석으로 교환해주는 방식을 택한 것이다. 식을 보자면 아래와 같다.
