Tensor 란?
Tensor : 배열
- 배열인데 Rank 시스템이 있다.
- 0 Rank Tensor : Scalar
- 1 Rank Tensor : Array(Vector) - 1차원 배열
- 2 Rank Tensor : Matrix - 행렬
- 3 Rank Tensor : 3차원 배열
- 4 Rank Tensor : 4차원 배열
Tensorflow는?
- Tensor가 흘러다니는 계산그래프를 미리 만들어 놓고 Tensor를 훈련시에 흘려(Flow)보낸다.
import tensorflow as tf
import numpy as np📍 각종 시퀀스들을 Tensor로 변환이 가능
- list -> tensor
tf.constant([1, 2, 3])
~~>
<tf.Tensor: shape=(3,), dtype=int32, numpy=array([1, 2, 3], dtype=int32)>- tuple -> tensor
tf.constant((1, 2, 3))
~~>
<tf.Tensor: shape=(3,), dtype=int32, numpy=array([1, 2, 3], dtype=int32)>- ndarray -> tensor
arr = np.array([1, 2, 3])
tf.constant(arr)
~~>
<tf.Tensor: shape=(3,), dtype=int64, numpy=array([1, 2, 3])>Tensor 정보 확인하기
tensor = tf.constant([1, 2, 3])
tensor.shape
~~>
TensorShape([3])
tensor.dtype # 데이터 타입
~~>
tf.int32
tensor = tf.constant(np.random.randn(2, 3))
tensor.dtype
~~>
tf.float64💡 텐서를 구성하는 원소 중 데이터 타입이 가장 큰 것이 텐서의 데이터 타입이 된다.
- 예를 들어 텐서에 정수와 실수가 섞여져 있으면 텐서의 타입은 실수가 된다.
tensor = tf.constant([1, 2.1, 3])
tensor.dtype
~~>
tf.float32📍 텐서를 만들 때 데이터 타입을 지정
tensor = tf.constant([1, 2, 3], dtype=tf.float32)
tensor.shape
~~>
TensorShape([3])
tensor.dtype
~~>
tf.float32📍 tf.cast 를 활용해서 텐서의 타입을 변경
tf.cast(tensor, tf.int32).dtype
~~>
tf.int32📍 numpy, tensorflow는 상호간에 호환이 가능
- tensor를 ndarray로 바꿔보기
tensor.numpy()
~~>
array([1., 2., 3.], dtype=float32)- np.array를 이용해서 tensor를 ndarray로 바꿀 수 있다.
np.array(tensor)
~~>
array([1., 2., 3.], dtype=float32)Tensorflow의 난수 생성
📍 numpy로 정규분포 난수 생성하기
np.random.randn(9)
~~>
array([ 0.497915 , -0.14458704, 0.46473898, 0.32639101, -0.48926386,
-1.3619899 , 2.29910261, -1.58208874, -0.77126096])📍 tensorflow로 정규분포 난수 생성하기
tf.random.normal((3, 3))
~~>
<tf.Tensor: shape=(3, 3), dtype=float32, numpy=
array([[-0.8549297 , 0.59345984, -0.8717115 ],
[-0.22827858, 1.1352422 , 1.1079745 ],
[ 1.8956741 , 1.0118338 , -0.8103193 ]], dtype=float32)>📍 tensorflow로 균등분포 난수 생성하기
tf.random.uniform((3, 3))
~~>
<tf.Tensor: shape=(3, 3), dtype=float32, numpy=
array([[5.2254391e-01, 9.0136385e-01, 5.8752489e-01],
[9.0100038e-01, 7.5068498e-01, 6.9210362e-01],
[8.7932229e-01, 1.7571449e-04, 9.3903482e-01]], dtype=float32)>Tensorflow의 Keras를 활용해서 MNIST 분류기 만들어 보기
import tensorflow as tf
# keras에 필요한 레이어가 다 준비되어 있어서 가져다가 쓰기만 하면 된다.
from tensorflow.keras.layers import Dense, Flatten
# 레이어를 묶어 놓을 모델
from tensorflow.keras.models import Squential📍 데이터 호출
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train.shape, y_train.shape
~~>
((60000, 28, 28), (60000, ))📍 이미지 정규화 : / 255.0
x_train = x_train / 255.0
x_test = x_test / 255.0📍 keras의 Sequential 모델을 사용하여 모델링 하기
- Dense 레이어를 이용해서 Fully Connected Layer 구축
- 데이터가 어쨋든 간에 평탄화가 되어야 한다. -> Flatten 레이어를 사용
num_classes = 10
model = Sequential([
Flatten(input_shape=(28, 28)), # 평탄화 레이어, 항상 첫 번째 레이어는 input_shape을 지정해야 한다. ( 배치를 제외한 )
# Fully Connected Layer 설정하기( Dense )
Dense(512, activation='relu'), # 은닉 1층
Dense(256, activation='relu'), # 은닉 2층
Dense(128, activation='relu'), # 은닉 3층
Dense(num_classes, activation='softmax') # 출력층의 활성화 함수는 softmax
])
model.summary()
~~>
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 784) 0
_________________________________________________________________
dense (Dense) (None, 512) 401920
_________________________________________________________________
dense_1 (Dense) (None, 256) 131328
_________________________________________________________________
dense_2 (Dense) (None, 128) 32896
_________________________________________________________________
dense_3 (Dense) (None, 10) 1290
=================================================================
Total params: 567,434
Trainable params: 567,434
Non-trainable params: 0
_________________________________________________________________
y_train.shape
~~>
(60000, )📍 학습을 하기 위해서 모델에 대한 최적화 기법, loss 선정, 평가 기준 지정
model.compile(
optimizer = 'adam', # 최적화 기법
loss = 'sparse_categorical_crossentropy', # 다중 분류, OHE 안되어있을 때 쓴다.
metrice=['acc']📍 훈련 시작
model.fit(x_train,
y_train,
validation_split=0.2 # 훈련 데이터의 20%를 검증용 데이터로 사용
epochs = 20 # 에폭 횟수
batch_size = 32
)
~~>
Epoch 1/20
1500/1500 [==============================] - 8s 4ms/step - loss: 0.3685 - acc: 0.8869 - val_loss: 0.1161 - val_acc: 0.9638
Epoch 2/20
1500/1500 [==============================] - 5s 3ms/step - loss: 0.0894 - acc: 0.9715 - val_loss: 0.1233 - val_acc: 0.9651
Epoch 3/20
1500/1500 [==============================] - 5s 3ms/step - loss: 0.0635 - acc: 0.9807 - val_loss: 0.1092 - val_acc: 0.9678
Epoch 4/20
1500/1500 [==============================] - 5s 3ms/step - loss: 0.0471 - acc: 0.9851 - val_loss: 0.0996 - val_acc: 0.9750
Epoch 5/20
1500/1500 [==============================] - 5s 3ms/step - loss: 0.0375 - acc: 0.9893 - val_loss: 0.0788 - val_acc: 0.9778
Epoch 6/20
1500/1500 [==============================] - 5s 3ms/step - loss: 0.0249 - acc: 0.9921 - val_loss: 0.0885 - val_acc: 0.9765
Epoch 7/20
1500/1500 [==============================] - 5s 3ms/step - loss: 0.0260 - acc: 0.9923 - val_loss: 0.1249 - val_acc: 0.9723
Epoch 8/20
1500/1500 [==============================] - 5s 3ms/step - loss: 0.0242 - acc: 0.9926 - val_loss: 0.1330 - val_acc: 0.9688
Epoch 9/20
1500/1500 [==============================] - 5s 3ms/step - loss: 0.0216 - acc: 0.9938 - val_loss: 0.0949 - val_acc: 0.9784
Epoch 10/20
1500/1500 [==============================] - 5s 3ms/step - loss: 0.0176 - acc: 0.9946 - val_loss: 0.1002 - val_acc: 0.9771
Epoch 11/20
1500/1500 [==============================] - 5s 3ms/step - loss: 0.0162 - acc: 0.9954 - val_loss: 0.1072 - val_acc: 0.9786
Epoch 12/20
1500/1500 [==============================] - 5s 3ms/step - loss: 0.0140 - acc: 0.9959 - val_loss: 0.1781 - val_acc: 0.9712
Epoch 13/20
1500/1500 [==============================] - 5s 3ms/step - loss: 0.0174 - acc: 0.9949 - val_loss: 0.1297 - val_acc: 0.9757
Epoch 14/20
1500/1500 [==============================] - 5s 3ms/step - loss: 0.0156 - acc: 0.9957 - val_loss: 0.1133 - val_acc: 0.9772
Epoch 15/20
1500/1500 [==============================] - 5s 3ms/step - loss: 0.0090 - acc: 0.9973 - val_loss: 0.1579 - val_acc: 0.9707
Epoch 16/20
1500/1500 [==============================] - 5s 3ms/step - loss: 0.0139 - acc: 0.9958 - val_loss: 0.1495 - val_acc: 0.9769
Epoch 17/20
1500/1500 [==============================] - 5s 3ms/step - loss: 0.0149 - acc: 0.9962 - val_loss: 0.1294 - val_acc: 0.9780
Epoch 18/20
1500/1500 [==============================] - 5s 3ms/step - loss: 0.0094 - acc: 0.9975 - val_loss: 0.1588 - val_acc: 0.9759
Epoch 19/20
1500/1500 [==============================] - 5s 3ms/step - loss: 0.0114 - acc: 0.9971 - val_loss: 0.1578 - val_acc: 0.9733
Epoch 20/20
1500/1500 [==============================] - 5s 3ms/step - loss: 0.0106 - acc: 0.9968 - val_loss: 0.1331 - val_acc: 0.9781
<tensorflow.python.keras.callbacks.History at 0x7fd901c40810>CNN 구축하기
import tensorflow as tf
from tensorflow.keras import datasets
import matplotlib.pyplot as plt
%matplotlib inline(x_train, y_train), (x_test, y_test) = datasets.mnist.load_data()
# 이미지 형상(shape) 확인하기
image = x_train[0]
image.shape
~~>
(28, 28)
# 이미지 시각화
plt.imshow(image, 'gray')
plt.show()
~~>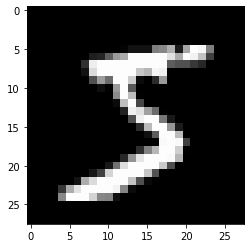
✨ 실제 CNN 레이어에 데이터를 집어 넣기 위해서 는 4차원 데이터를 유지 해야 한다.
- ( N, H, W, C ) -> ( 배치크기, 높이, 가로, 채널 )
- MNIST 손글씨 이미지 : 높이 - 28px, 가로 - 28px, 채널 1개 - (28, 28, 1)
- 장수는 한장만 할거니깐 (28, 28) -> (1, 28, 28, 1)로 바꿔 준다.
image = image[np.newaxis, ..., np.newaxis]
image.shape
~~>
(1, 28, 28, 1)Conv2D 레이어 사용하기
keras의 대표적인 CNN 레이어는 두가지가 있다.
-
- Conv2D
stride가 2방향으로 움직인다.( 가로, 세로 )- 이미지 분석을 위해 사용되는 일반적인 합성곱 레이어
- Conv2D
-
- Conv1D
stride가 한쪽 방향으로만 움직인다.( 세로 )- 텍스트 분석을 위해 사용되는 레이어(
char CNN) 등등
- Conv1D
매개변수 정리
filters: 필터의 개수kernel_size: 필터의 세로, 가로 크기strides: 몇 개의 픽셀을 건너뛰면서 필터가 이미지를 훑게 할지 결정( 세로로 움직일 크기, 가로로 움직일 크기 )padding: 0으로 쌓여진 패딩을 만들 것인지에 대한 설정VALID: 패팅을 만들지 않음
SAME: 패팅 생성
tf.keras.layers.Conv2D(
filters = 3, # 필터 개수
kernel_size = (3, 3), # 필터의 가로, 세로 크기
strides = (1, 1), # 필터가 움직이는 크기
padding = 'SAME', # 패딩 여부
activation = 'relu' # 활성화 함수 적용( 여기에 안넣고 활성화 함수 레이어로 적용 가능 )
)💡 필터의 세로, 가로 크기 및 스트라이드의 세로 가로가 똑같다면 굳이 튜플로 넣어줄 필요는 없다.
tf.keras.layers.Conv2D(
filters=3,
kernel_size=3,
strides=1,
padding='SAME',
activation='relu'
)Conv 레이어 시각화
📍 image를 tensor로 만들기
image = tf.cast(image, dtype=tf.float32)
image.dtype
~~>
tf.float32layer = tf.keras.layers.Conv2D(filter=5, kernel_size=3, strides=1, padding='SAME')📍 tensorflow에서 레이어에 데이터를 전달 하는 방법
output = layer(image)
output.shape
~~>
TensorShape([1, 28, 28, 5])📍 MNIST 이미지 5개에 대한 Conv 레이어 통과 후 시각화
_, axes = plt.subplots(nrows=1, ncols=6, figsize=(20, 10))
axes[0].imshow(image[0, ..., 0], cmap='gray')
axes[0].set_title('Original Image')
for idx, ax in enumerate(axes[1: ]):
ax.set_title('Output : {}' .format(idx + 1))
ax.imshow(output[0, ..., idx], cmap='gray')
plt.show()
~~>
Filter 시각화 하기
- CNN에서 Filter의 역할은 실제 CNN 레이어가 이미지의 무엇을 보고 있는가를 이야기 한다.
- keras의 레이어들은
get_weight()함수를 이용해서 편향과 가중치 등을 볼 수 있다.
📍 케라스의 모든 계산 가능한 레이어에서 매개변수 뽑아내기( 가중치, 편향 )
- layer : Conv2D 레이어의 필터 모양 : (3, 3, 1, 5) - ( 필터 세로, 필터 가로, 필터의 채널 수, 필터의 개수 )
weights = layer.get_weights()
print('가중치의 형상 : {}' .format(weights[0].shape))
print('편향의 형상 : {}' .format(weight[1].shape))
~~>
가중치의 형상 : (3, 3, 1, 5)
편향의 형상 : (5, )📍 시각화
_, axes = plt.subplots(nrows=1, ncols=5, figsize=(20, 10))
for idx, ax in enumerate(axes):
ax.set_title('filter {}' .format(idx + 1))
ax.imshow(weights[0][..., 0, idx], cmap='gray')
plt.show()
~~>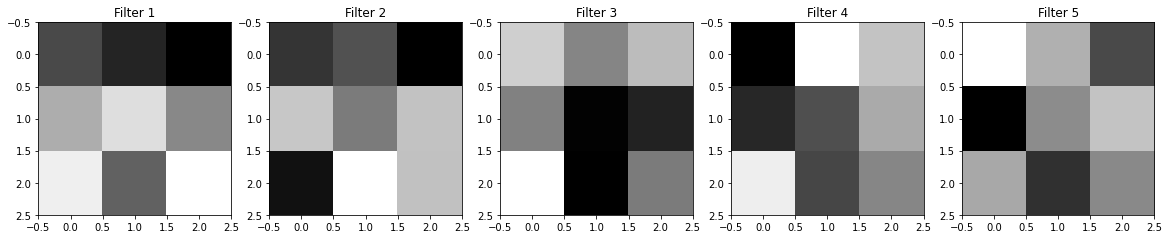
ReLU 레이어 시각화
- 이미지 분석에서 ReLU가 자주 사용된다.
- 이미지 데이터에서 음수 데이터는 필요가 없는 데이터이기 때문이다.
- 필요 없는 음수 데이터는 제거하고, 의미 있는 양수 데이터만 강조하기 위해서 사용
np.min(output), np.max(output)
~~>
(-200.86574, 208.96964)act_layer = tf.keras.layers.ReLU()
act_ouput = act_layer(output) # Conv 결과를 활성화 레이어에 집어 넣는다.
act_output.shape
~~>
TensorShape([1, 28, 28, 5])
np.min(act_output), np.max(act_output)
~~>
(0.0, 139.89272)
_, axes = plt.subplots(nrows=1, ncols=6, figsize=(20, 10))
axes[0].imshow(image[0], ..., 0], 'gray')
axes[0].set_title('Original Image')
for idx, ax in enumerate(axes[1:]):
ax.set_title('ReLU Output : {}' .format(idx + 1))
ax.imshow(act_output[0, ..., idx], cmap='gray')
plt.show()
~~>

data science!!, data analyst!! ///// hello world