FCN에서는 작거나 큰 객체를 잘 라벨링하지 못하거나, 객체의 디테일한 특징이 사라지는 문제점이 있었다. 이러한 점을 보완하기 위해 Encoder-Decoder 구조를 도입한 여러 segmentation 모델들이 고안되었다.
DeconvNet

DeconvNet은 위의 그림과 같은 architecture를 가지고 있는데, encoder와 decoder가 대칭의 형태를 이루고 있다.
encoder는 FCN과 유사한 architecture이고, decoder는 upsampling 역할을 한다.
decoder에서는 unpooling과 transposed convolution이 반복적으로 이루어지는데, 전자는 디테일한 경계를 포착하고, 후자는 전반적인 모습을 포착한다.
unpooling
unpooling이란, pooling 연산으로 소실된 정보를 복원하는 과정이다.
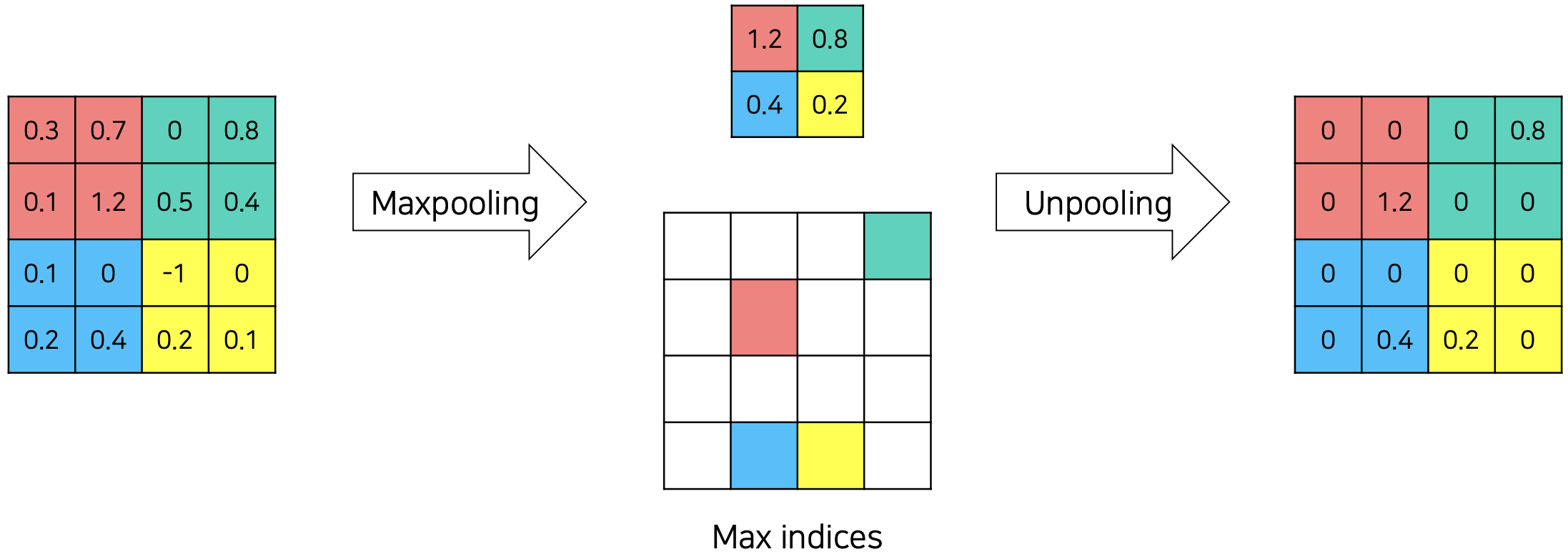
max pooling 등으로 각 kernel을 통과하며 최대값만이 남았을 때, unpooling을 수행하면 pooling을 하며 채택했던 값의 인덱스를 저장해뒀다가 해당 인덱스에 pooling 값을 채우고 나머지 칸은 0으로 채운다. 이 연산은 학습이 필요없기 때문에 속도가 빠르지만, 나머지 칸이 0으로 채워져 정보가 sparse하기 때문에 이를 채울 필요가 있다. 이를 채워주는 것인 transposed convolution이다.
코드로 구현해보면, return_indices=True를 이용해 pooling 과정에서 채택했던 값의 인덱스를 저장할 수 있고, 이는 unpooling 과정에서 사용된다.
self.pool = nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True, return_indices=True
SegNet
SegNet은 속도가 크게 향상되어 real-time semantic segmentation을 가능하게 한 모델이다.

DeconvNet처럼 encoder-decoder 구조로 되어 있으며, DeconvNet과 비교하면 가운데의 7 7 convolutional layer, 1 1 convolutional layer, 7 7 deconvolutional layer를 제거해서 파라미터 수를 줄였고, 그에 따라 속도가 향상될 수 있었다.
decoder에서 upsampling하는 과정에 transposed convolution이 아닌 unpooling을 사용함으로써 이 부분에 대해 학습이 필요하지 않도록 했다.
unpooling해서 sparse하게 복원된 정보를 채울 때 DeconvNet에서는 deconvolution을 했지만 SegNet에서는 convolution을 사용했다.
Encoder-Decoder 구조 뿐만 아니라 skip connection 구조를 이용해서도 segmentation의 성능을 높이는 연구가 진행되었다. skip connection이란, neural network에서 이전 layer의 output을 일부 layer를 건너 뛴 후의 layer에게 입력으로 제공하는 것이다. (ex) FCN-8s, FCN-16s) 이러한 모델의 예로는 FC DenseNet, UNet 등이 있다.
receptive field를 확장시키는 방식으로도 성능이 향상된 segmentation 모델들이 개발되었다. receptive field란, neuron이 얼마 만큼의 영역을 보고 있는지를 의미한다. receptive field가 작다면, 객체에 대한 정보를 부분적으로만 포함하게 되므로 예측 정확도가 낮아진다. (FCN이 가지고 있던 문제점이기도 하다.) 따라서 아래 모델들은 receptive field를 확장시켜 이러한 문제점을 해결하고 segmentation 성능을 향상시키고자 했다.
DeepLab v1
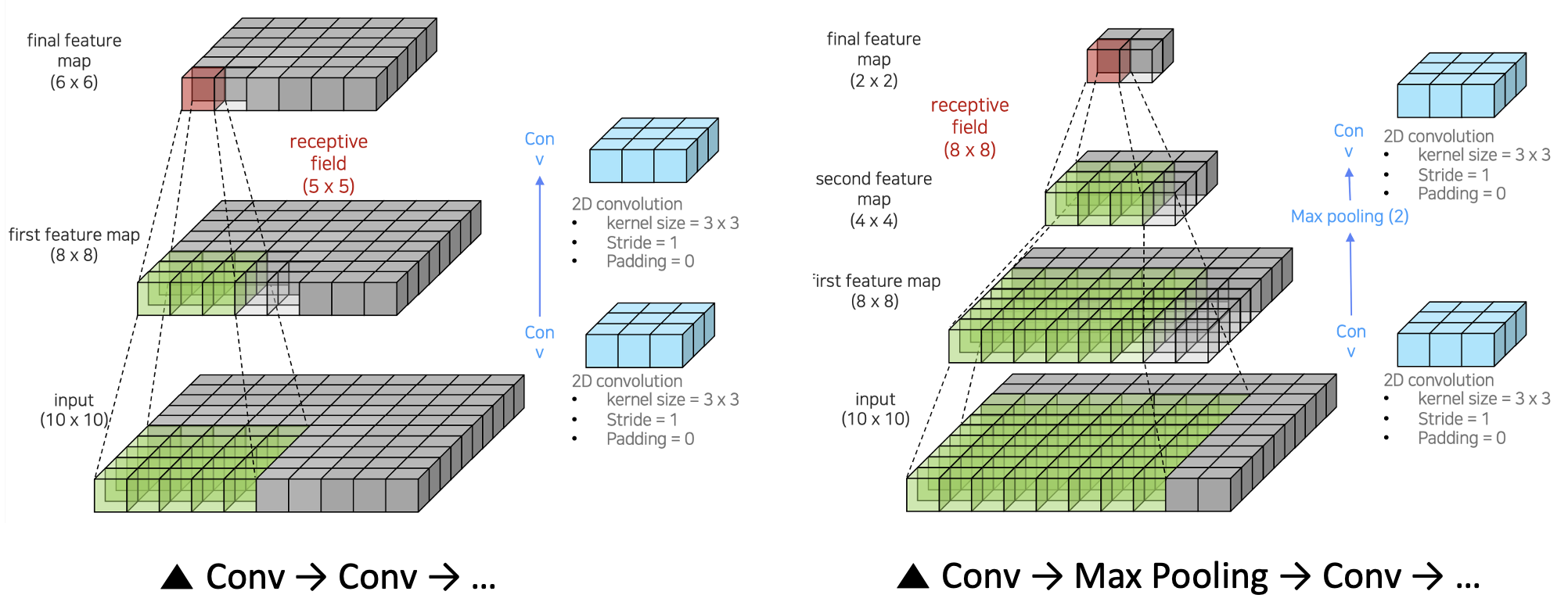
위 그림에서 볼 수 있듯이 같은 3 3 kernel을 이용하더라도 convolution만 반복하는 것보다는 max pooling을 섞어서 반복했을 때 효율적으로 receptive field를 넓힐 수 있다. (좌 : receptive field = 5 5, 우 : receptive field = 8 8)
그러나 이 과정을 거치면 이미지의 크기가 많이 줄어들면서 resolution이 낮아진다는 문제가 생긴다.
이 문제를 해결하여 이미지의 크기를 덜 줄이면서도 (→ resolution 보존) 효율적으로 receptive field를 늘리는 Dilated convolution(a.k.a. atrous convolution)을 도입했다. 아래 이미지가 dilated convolution이 작동하는 방식을 나타내고 있다.
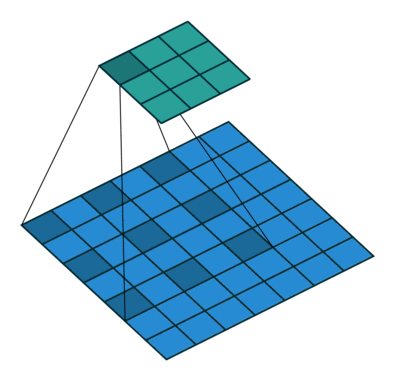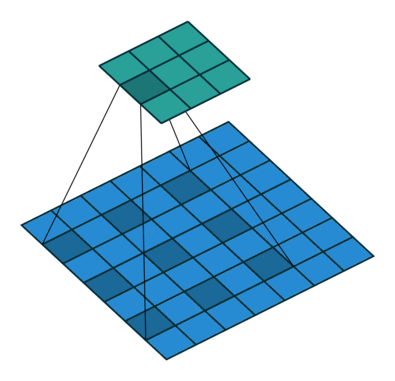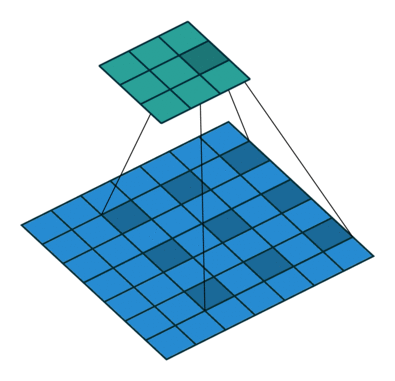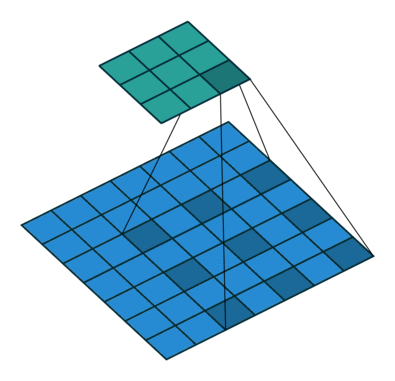
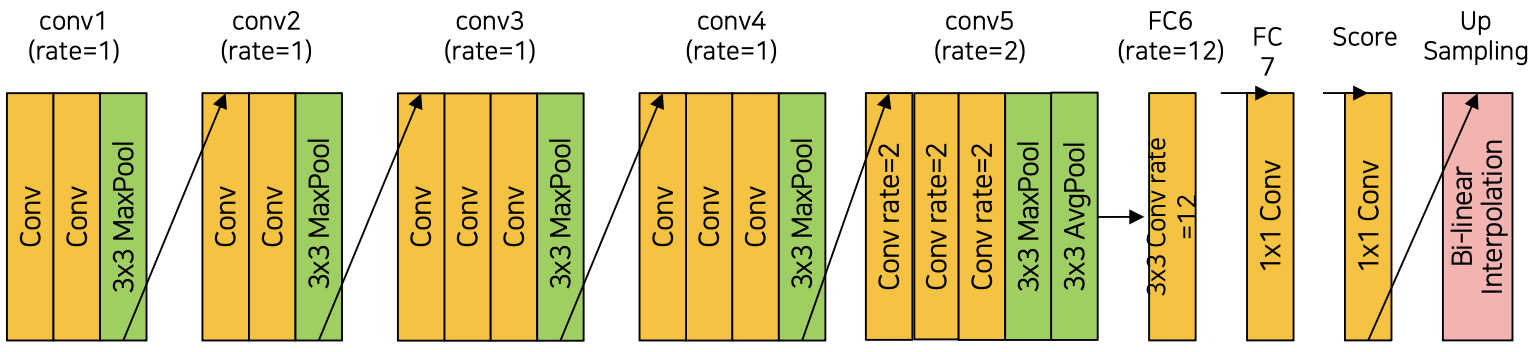
위가 DeepLab v1의 architecture를 나타내고 있는데, FC5와 FC6에서 rate가 큰 (→ 간격이 넓어지는) dilated convolution이 작동하면서 0으로 채워진 칸이 많아지게 된다. 이 때 bilinear interpolation을 이용해 그 칸들을 채우게 된다. (upsampling)
하지만 bilinear interpolation으로는 픽셀 단위의 정교한 segmentation이 불가능한데, 이 때 Dense CRF (Conditional Random Field) 를 적용해 후처리를 해주면 더 정밀하게 픽셀 단위의 segmentation 결과를 얻을 수 있다.
DilatedNet
DeepLab과 아키텍쳐가 거의 유사하지만 보다 효율적으로 구성한 네트워크이다.
3 3 대신 2 2 max pooling을 사용하고 4, 5번째 블록에서 pooling 연산을 생략했다.
upsampling 과정에서 bi-linear interpolation이 아닌 deconvolution을 사용했다.
upsampling 전 Basic Context Module을 추가한 버전도 있는데, 이를 통해 이미지의 문맥적인 정보를 더 잘 포착할 수 있다.
References
