1부
랭체인(LangChain) 정리 (LLM 로컬 실행 및 배포 & RAG 실습)
2부
오픈소스 LLM으로 RAG 에이전트 만들기 (랭체인, Ollama, Tool Calling 대체)
🎯 목표
- LangChain, LangServe, LangSmith, RAG 학습
😚 외부 AI API VS 오픈소스 LLM

오픈소스 LLM 장점
보안
- 데이터가 외부로 유출될 위험이 없음
비용 효율성
- 장기적으로 외부 API 사용 비용보다 저렴
커스터마이징
- RAG(Retrieval-Augmented Generation) 아키텍처 커스터마이징 자유도가 높아 필요한 데이터를 잘 연동할 수 있음
비교 상세
| 항목 | 오픈소스 LLM | 외부 AI API |
|---|---|---|
| 초기 비용 | 높음 (고성능 GPU 및 하드웨어 구입) | 없음 |
| 운영 비용 | 낮음 (전기, 유지 보수 등) | 높음 (API 호출당 비용 발생) |
| 설치 및 설정 | 복잡 (하드웨어 설치 및 소프트웨어 설정 필요) | 간단 (API 키 획득 및 사용) |
| 유지 보수 | 직접 관리 (업데이트, 최적화 필요) | 없음 (API 제공자가 관리) |
| 확장성 | 제한적 (하드웨어 추가 필요) | 우수 (필요에 따라 쉽게 확장 가능) |
| 커스터마이징 자유도 | 높음 (모델 조정 및 도메인별 최적화 가능) | 제한적 (API 제공 범위 내에서만 가능) |
| 데이터 보안 | 우수 (데이터가 로컬에서 처리됨) | 주의 필요 (데이터를 외부 서비스에 전송) |
| 성능 | 고성능 가능 (적절한 하드웨어 사용 시) | 고성능 (API가 고성능 서버에서 제공됨) |
| 지속 가능성 | 우수 (초기 투자 후 장기적으로 저렴) | 비용 증가 가능 (사용량에 따라 비용 증가) |
| 초기 설정 시간 | 길음 (하드웨어 및 소프트웨어 설정 필요) | 짧음 (API 키 발급 및 통합) |
| 장기적 비용 효율성 | 우수 (초기 투자 후 운영 비용 낮음) | 제한적 (사용량이 많을수록 비용 증가) |
주요 모델 소개
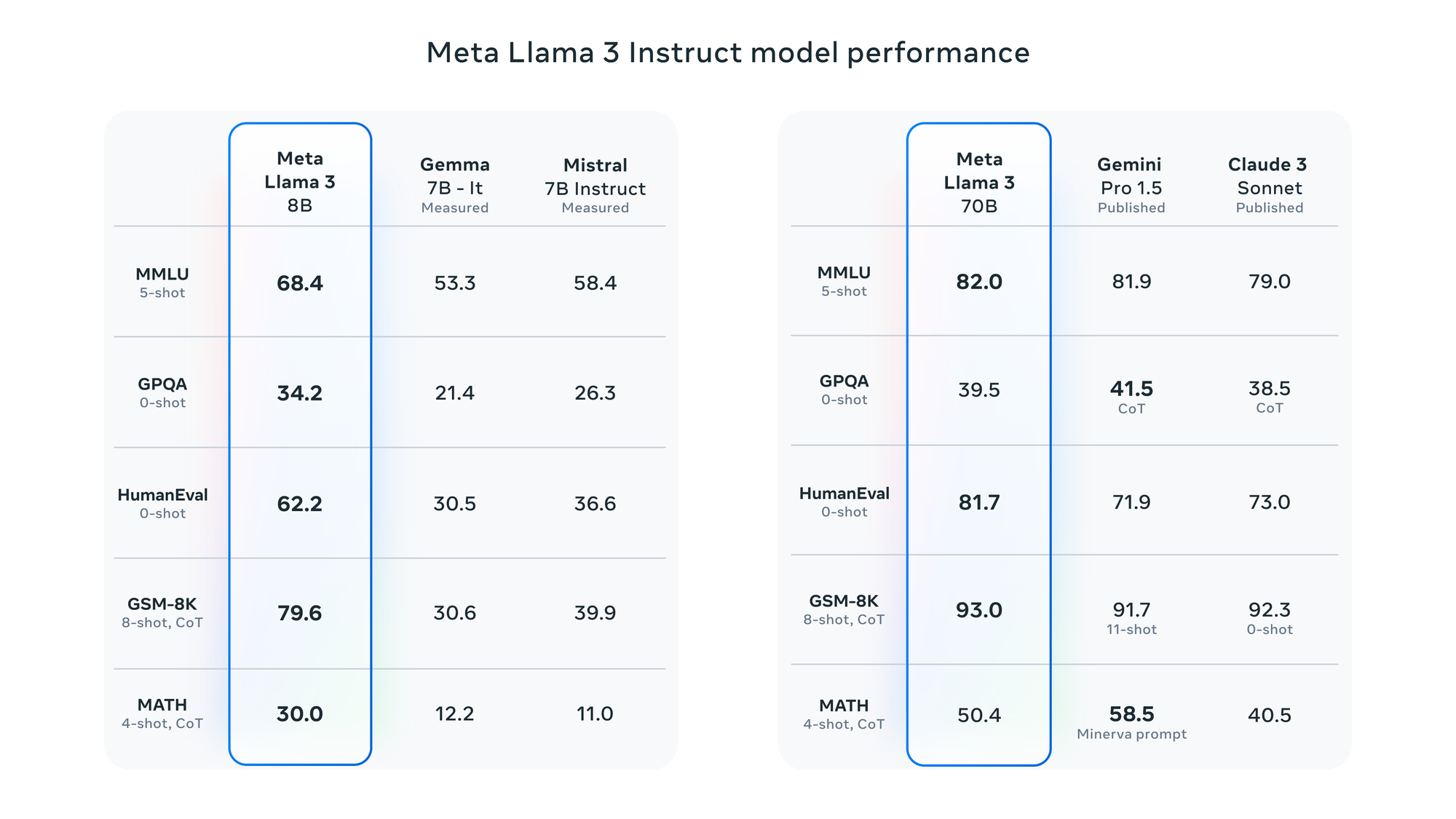
Llma3
킹메타에서 공개한 LLM

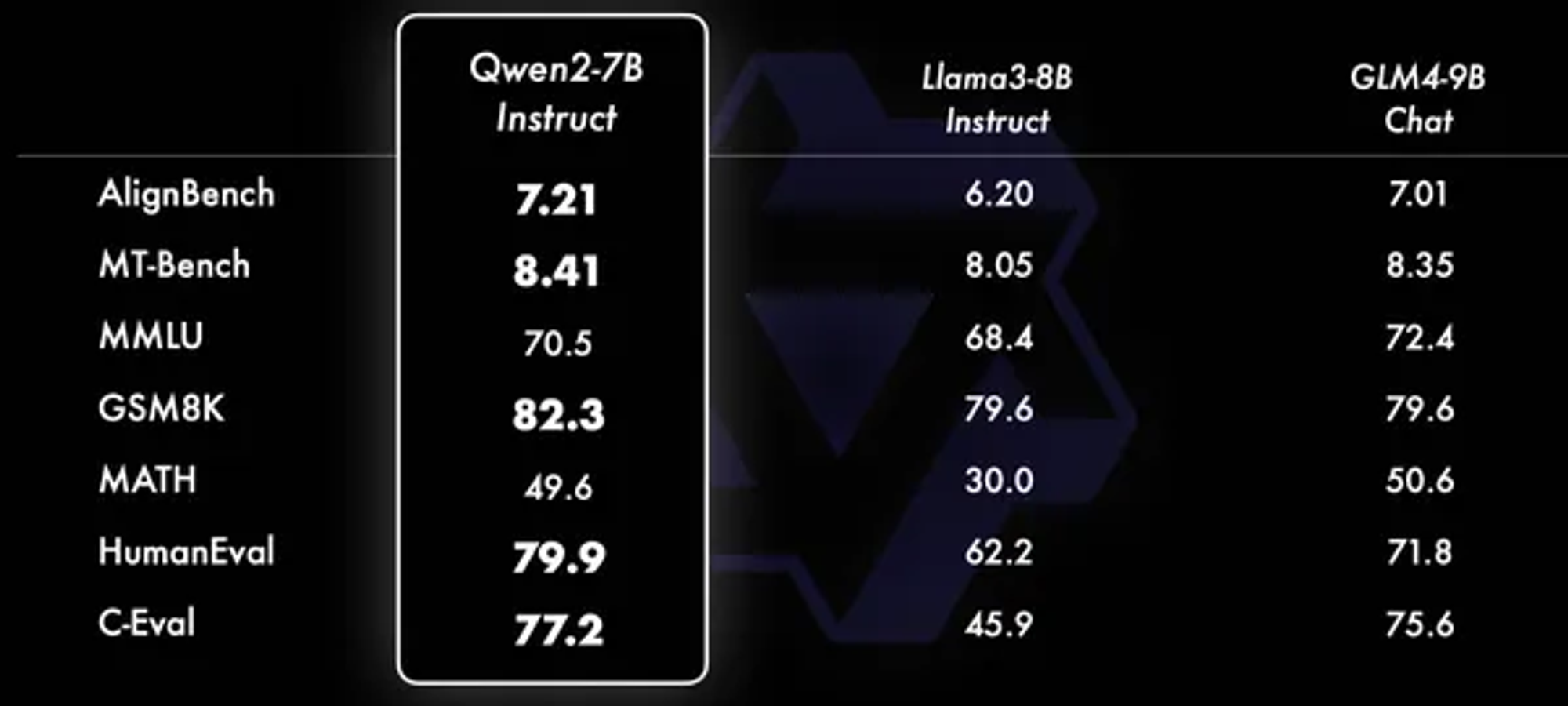
Qwen2
알리바바에서 공개한 LLM
기타
- Gemma: 구글에서 공개한 LLM
- Phi: MS에서 공개한 LLM
- Mixtral: Mistral에서 공개한 LLM
- Solar: 업스테이지에서 공개한 LLM
😚 Ollama

Ollama?
로컬에서 대규모 언어 모델(LLM)을 실행할 수 있도록 하는 오픈소스
Ollama 설치
LLM 모델 셋팅
방법 1. Llama3 모델 다운로드
https://ollama.com/library 에서 마음에 드는 모델 다운로드
ollama pull llama3:<태그>
방법 2. GGUF 사용 및 모델 생성
세상에는 고수들이 참 많다, 감사한 마음으로 한국어 파인튜닝된 모델 가져다 쓰도록 하자
- GGUF: 딥러닝 모델을 저장 용도의 단일 파일 포맷
- GGUF 다운로드
- https://huggingface.co/teddylee777/Llama-3-Open-Ko-8B-gguf
- Huggingface : 머신러닝, 자연어 처리, 이미지 생성 모델 등 분야의 다양한 라이브러리 공유 플랫폼
- GGUF 파일명에 Q 의미 : 양자화 수준. 모델 파라미터와 연산을 보다 작은 비트 크기로 표현하여 모델의 메모리 사용량을 줄이고, 추론 속도를 향상시키기 위한 기술
- https://huggingface.co/teddylee777/Llama-3-Open-Ko-8B-gguf
- Ollama LLM 모델 생성
- Modelfile 파일 작성 (Modelfile.md)
- Modelfile : Ollama로 모델을 만들고, 공유하기 위함
- 모델마다 템플릿이 달라서 찾아봐야 함
- ollama show 명령어로 템플릿을 알아낼 수도 있음
- Modelfile 파일 작성 (Modelfile.md)
FROM Llama-3-Open-Ko-8B-Q8_0.gguf
TEMPLATE """{{- if .System }}
<s>{{ .System }}</s>
{{- end }}
<s>Human:
{{ .Prompt }}</s>
<s>Assistant:
"""
SYSTEM """A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions."""
PARAMETER temperature 0
PARAMETER num_predict 3000
PARAMETER num_ctx 4096
PARAMETER stop <s>
PARAMETER stop </s>- 모델 생성
ollama create {모델명}
Ex) ollama create Llama-3-Open-Ko-8B-Q8_0 -f Modelfile
LLM 모델 리스트 조회
ollama list
LLM 모델 실행
ollama run {모델명}
Ex) ollama run Llama-3-Open-Ko-8B-Q8_0:latest
😚 LangChain
- 대규모 언어 모델(LLM)을 활용한 애플리케이션 개발을 위한 프레임워크
- LCEL(LangChain Expression Language) 사용
- 프롬프트, 모델, 출력 파서 등의 구성 요소를 파이프 연산자( | )를 사용해서 단일 체인으로 구성
LangChain 설치
pip install langchain이후 설명에서 기타 다른 모듈들 설치 명령어는 생략하겠음
LangChain LLM 모델 실행
Ollama 서버 실행 중인지 확인 후, 실행
from langchain_community.chat_models import ChatOllama
llm = ChatOllama(model="llama3:latest")
llm.invoke("What is stock?")- 실행결과

PromptTemplate 사용
원시 사용자 입력을 더 나은 입력으로 변환
PromptTemplate, ChatPromptTemplate, FewShotPromptTemplate 등이 있음
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages([
("system", "You are a helpful, professional assistant named 권봇. Introduce yourself first, and answer the questions. answer me in Korean no matter what. "),
("user", "{input}")
])
chain = prompt | llm
chain.invoke({"input": "What is stock?"})- 실행결과

OutputParser 사용
채팅 메시지를 문자열로 변환하는 출력 구문 분석기
StrOutputParser, PydanticOuputParser, JsonOutputParser, StructuredOuputParser 등이 있음
from langchain_core.output_parsers import StrOutputParser
chain = prompt | llm | StrOutputParser()
chain.invoke({"input": "What is stock?"})- 실행결과

체인 스트림 출력
chain = prompt | llm | output_parser
for token in chain.stream(
{"input": "What is stock?"}
):
print(token, end="")체인 여러개 연결
# 첫번째 체인
prompt1 = ChatPromptTemplate.from_template("[{korean_input}] translate the question into English. Don't say anything else, just translate it.")
chain1 = (
prompt1
| llm
| StrOutputParser()
)
message1 = chain1.invoke({"korean_input": "주식이 뭐야?"})
print(f'message1: {message1}') # What is a stock?
# 두번째 체인
prompt2 = ChatPromptTemplate.from_messages([
("system", "You are a helpful, professional assistant named 권봇. answer the question in Korean"),
("user", "{input}")
])
chain2 = (
{"input": chain1}
| prompt2
| llm
| StrOutputParser()
)
message2 = chain2.invoke({"korean_input": "주식이 뭐야?"})
print(f'message2: {message2}') # 주식은 한 회사의 소유권을 나타내는 증권입니다. 즉, 특정 기업에 투자하여 (중략)- 실행결과

체인 병렬 실행
joke_chain = (
ChatPromptTemplate.from_template("{topic}에 관련해서 짧은 농담 말해줘")
| llm)
poem_chain = (
ChatPromptTemplate.from_template("{topic}에 관련해서 시 2줄 써줘")
| llm)
# map_chain = {"joke": joke_chain, "poem": poem_chain} # 체인에서 이처럼 사용할 때, 자동으로 RunnableParallel 사용됨
# map_chain = RunnableParallel({"joke": joke_chain, "poem": poem_chain})
map_chain = RunnableParallel(joke=joke_chain, poem=poem_chain)
map_chain.invoke({"topic": "애플"})- 실행결과

😚 LangServe
앱을 구축했으니까 이제 배포해야 함
LangServe는 LangChain 앱을 REST API로 배포하는 데에 도움을 줌
배포
Default
from agent import chain as chain
(중략)
app = FastAPI(
title="LangChain Server",
version="1.0",
description="A simple API server using LangChain",
)
add_routes(
app,
chain,
path="/chain"
)
if __name__ == "__main__":
import uvicorn
# uvicorn: ASGI(Asynchronous Server Gateway Interface) 서버를 구현한 비동기 경량 웹 서버
uvicorn.run(app, host="localhost", port=8000)- 실행결과

Chat
class InputChat(BaseModel):
messages: List[Union[HumanMessage, AIMessage, SystemMessage]] = Field(
..., # Pydantic에서 필수 필드임을 의미
description="The chat messages representing the current conversation.",
)
add_routes(
app,
chat_chain.with_types(input_type=InputChat),
path="/chat",
enable_feedback_endpoint=True,
enable_public_trace_link_endpoint=True,
playground_type="chat",
)- 실행결과

RemoteRunnable
원격에 배포된 LangServe URL이 있는 경우 RemoteRunnable 사용해서 로컬 체인인 것처럼 불러와서 상호 작용 가능
from langserve import RemoteRunnable
# URL 넣는 부분에 배포된 LangServe URL 아무거나 넣으면 됨
remote_chain = RemoteRunnable("http://localhost:8000/chain/")
message = remote_chain.invoke({
"input": "What is stock?",
})
print(f'message : {message}')😚 외부에 앱 배포
Ngrok
로컬 개발 환경을 외부에서 접근할 수 있도록 해주는 터널링 소프트웨어
이를 통해 개발 중인 웹 서버나 애플리케이션을 로컬에서 실행하면서 외부에서 접근하여 테스트 가능
배포
ngrok http http://localhost:8000
고정 도메인 있으면
ngrok http --domain=precious-iguana-bursting.ngrok-free.app 8000😚 LangSmith
LLM 애플리케이션을 위한 통합 DevOps 플랫폼
- 테스트, 배포, 모니터링을 위한 통합 환경 제공
- 프롬프트 작성, 버전 관리, 공유 기능 제공(LangChain Hub)
- LLM 애플리케이션의 전체 실행 과정을 추적하는 Trace 기능
- 오류 및 성능 문제 원인 파악에 용이
- 데이터셋 구축 및 평가를 통해 모델 개선
셋팅
https://docs.smith.langchain.com/
위 사이트 참고해서 셋팅
import os
os.environ["LANGCHAIN_PROJECT"] = "KWON_TEST_PROJECT"
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = "your key" # LangSmith KEY (https://smith.langchain.com/)결과
https://smith.langchain.com/ 에서 확인
😚 RAG

검색 증강 생성 (Retrieval Augemented Generation)
LLM에 검색 기능을 추가
새로운 데이터를 VectorStore에 저장하고, 이를 활용함으로써 할루시네이션 방지와 보다 더 정확한 정보를 반영한 답변 생성
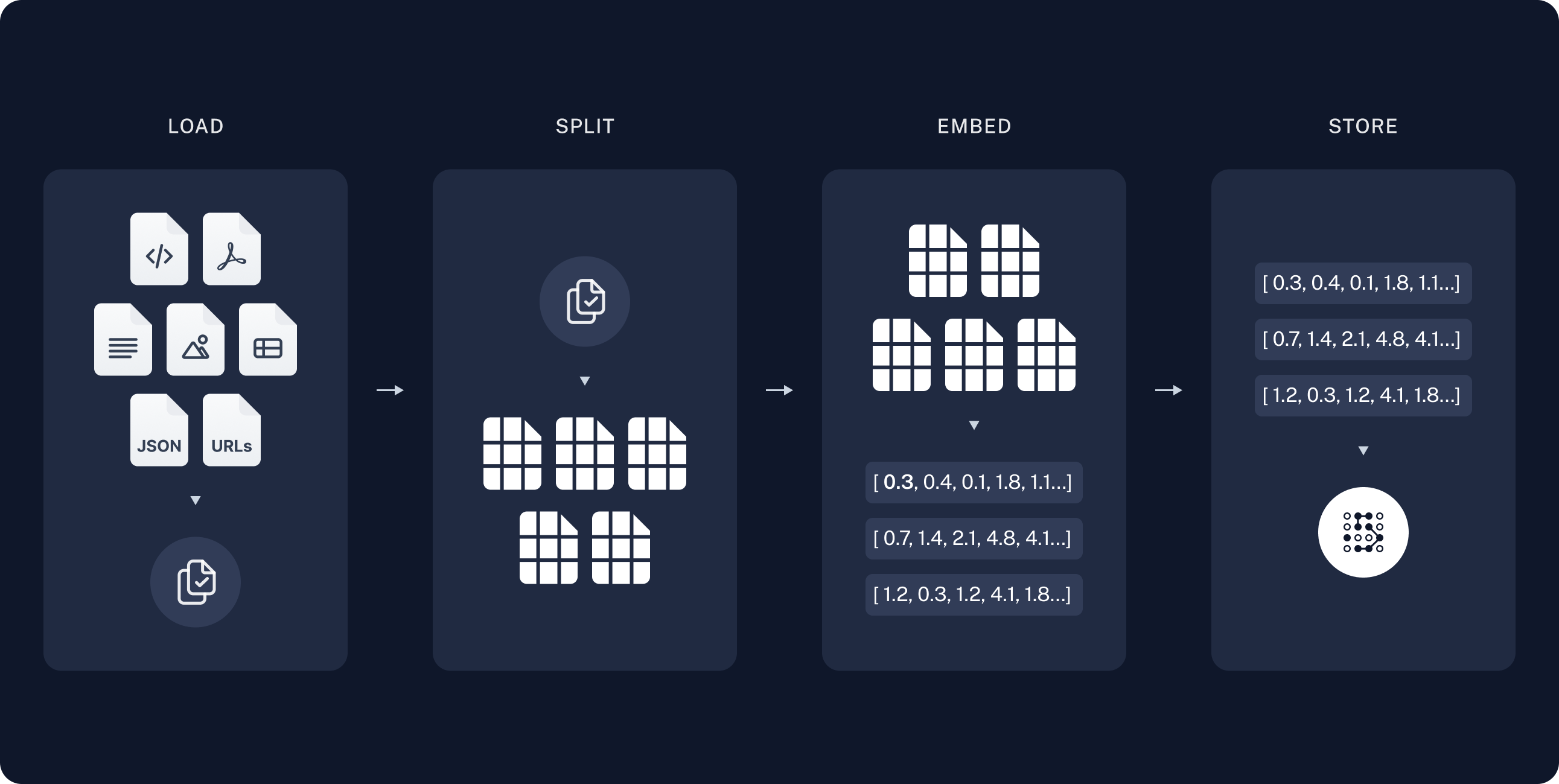
- 인덱싱
- 로드: 데이터를 로드. DocumentLoader 사용
- 분할: VectorStore에 저장하기 위해 긴 컨텍스트를 작은 청크로 나눠야 함. 긴 컨텍스트는 검색이 어렵고, LLM 모델의 유한한 컨텍스트 윈도우에 맞지 않음. Splitter 사용
- 저장: 청크 데이터를 저장하고 인덱싱할 곳이 필요. VectorStore와 Embedding 모델을 사용
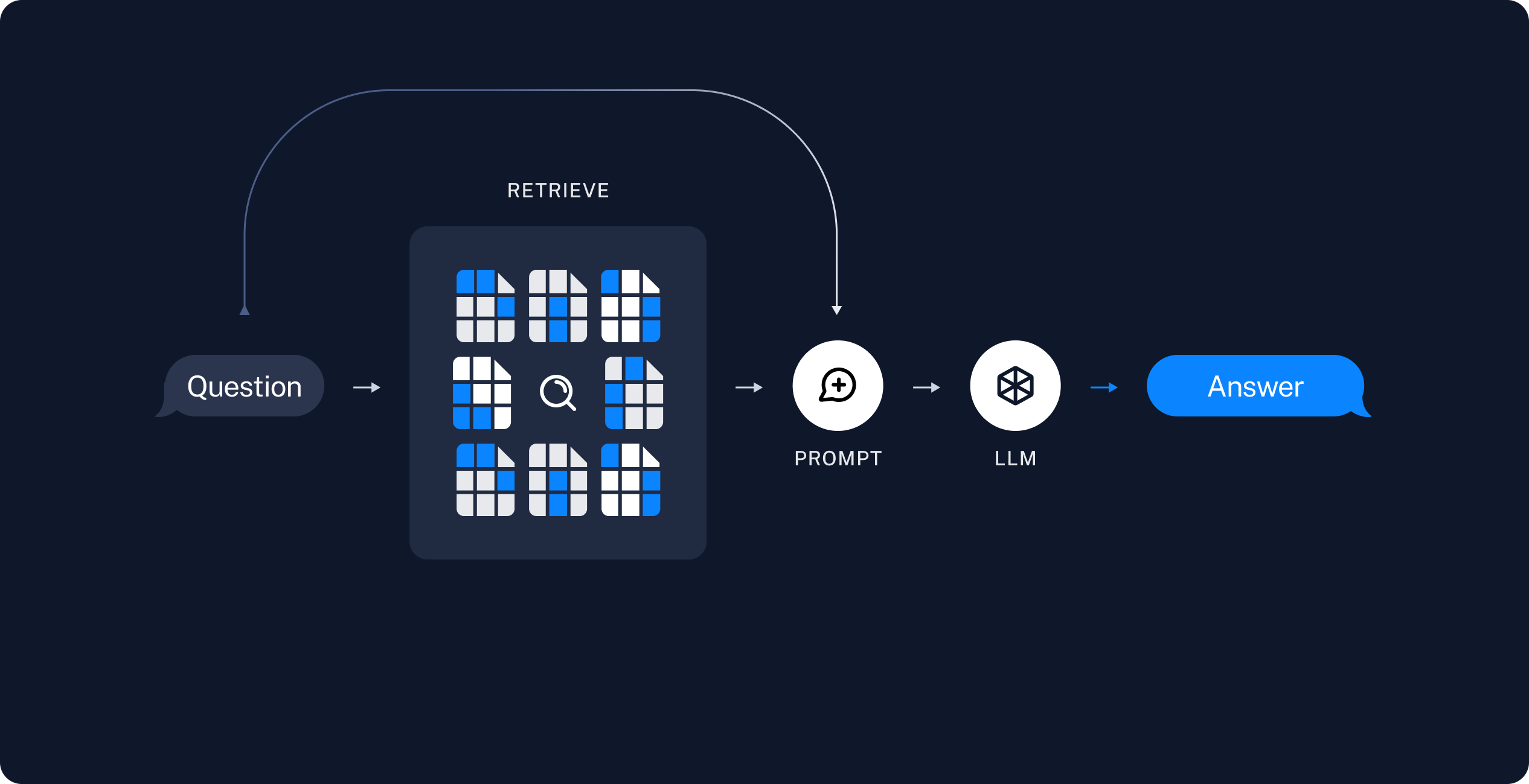
- 검색 및 생성
- 검색: 사용자 질문과 관련된 청크를 저장소에서 검색
- 생성: LLM은 검색된 데이터가 포함된 프롬프트를 사용해서 답변을 생성
로드 (DocumentLoader)
TEXT, CSV, HTML, WEB, PDF, DOCX, XLSX 등 로드할 수 있음
이 글에서는 TEXT, WEB, PDF 로드에 대해 다룸
Text
from langchain_community.document_loaders import TextLoader
loader = TextLoader('../assets/news.txt')
data = loader.load()
print(f'type : {type(data)} / len : {len(data)}')
print(f'data : {data}')
print(f'page_content : {data[0].page_content}')Web
import bs4
from langchain_community.document_loaders import WebBaseLoader
# BeautifulSoup : HTML 및 XML 문서를 파싱하고 구문 분석하는 데 사용되는 파이썬 라이브러리. 주로 웹 스크레이핑(웹 페이지에서 데이터 추출) 작업에서 사용되며, 웹 페이지의 구조를 이해하고 필요한 정보를 추출하는 데 유용
loader = WebBaseLoader(
web_paths=("https://www.aitimes.com/news/articleView.html?idxno=159102"
, "https://www.aitimes.com/news/articleView.html?idxno=159072"
, "https://www.aitimes.com/news/articleView.html?idxno=158943"
),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
"article", # 태그
attrs={"id": ["article-view-content-div"]}, # 태그의 ID 값들
)
),
)
data = loader.load()
print(f'type : {type(data)} / len : {len(data)}')
print(f'data : {data}')
for d in data:
print(f'page_content : {d.page_content}')from langchain_community.document_loaders import PyMuPDFLoader
loader = PyMuPDFLoader("../assets/생성형_AI_신기술_도입에_따른_선거_규제_연구_결과보고서.pdf")
pages = loader.load()
print(f'type : {type(pages)} / len : {len(pages)} / pages : {pages}')-
PDF를 그대로 RAG하는 것보다 마크다운 형식으로 변환 후 RAG하면 성능이 더 좋음
import pymupdf4llm md_text = pymupdf4llm.to_markdown("input.pdf") -
PDF 생긴게 워낙 다양해서 여러 전처리 과정이 필요함
def remove_newlines_except_after_period(text): """마침표 다음의 줄바꿈을 제외한 모든 줄바꿈을 제거""" return re.sub(r'(?<!\.)(\n|\r\n)', ' ', text) def process_pages(pages: List[Document]) -> List[Document]: return [Document(page_content=remove_newlines_except_after_period(page.page_content), metadata=page.metadata) for page in pages] processed_data = process_pages(data)
분할 (Splitter)
chunk size와 overlap은 문서마다 최적의 값이 문서마다 다를 수 있으니 최적의 값은 테스트 필요
RecursiveJsonSplitter, CharacterTextSplitter, RecursiveCharacterTextSplitter 등이 있음
RecursiveCharacterTextSplitter
"\n\n", "\n", " ", "" 재귀적으로 청킹
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
splits = text_splitter.split_documents(data)
print(f'len(splits[0].page_content) : {len(splits[0].page_content)}')
splits- 실행결과
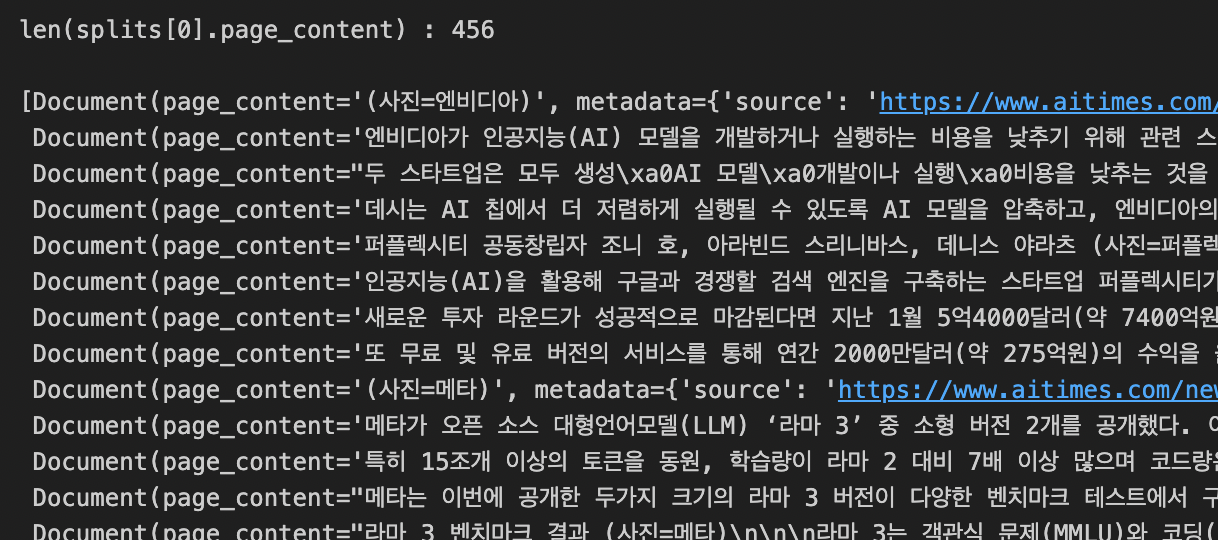
chunk_size를 300으로 줄여보면 len(splits[0].page_content)이 300 아래로 줄어드는 것을 볼 수 있음
임베딩 (Embeddings)
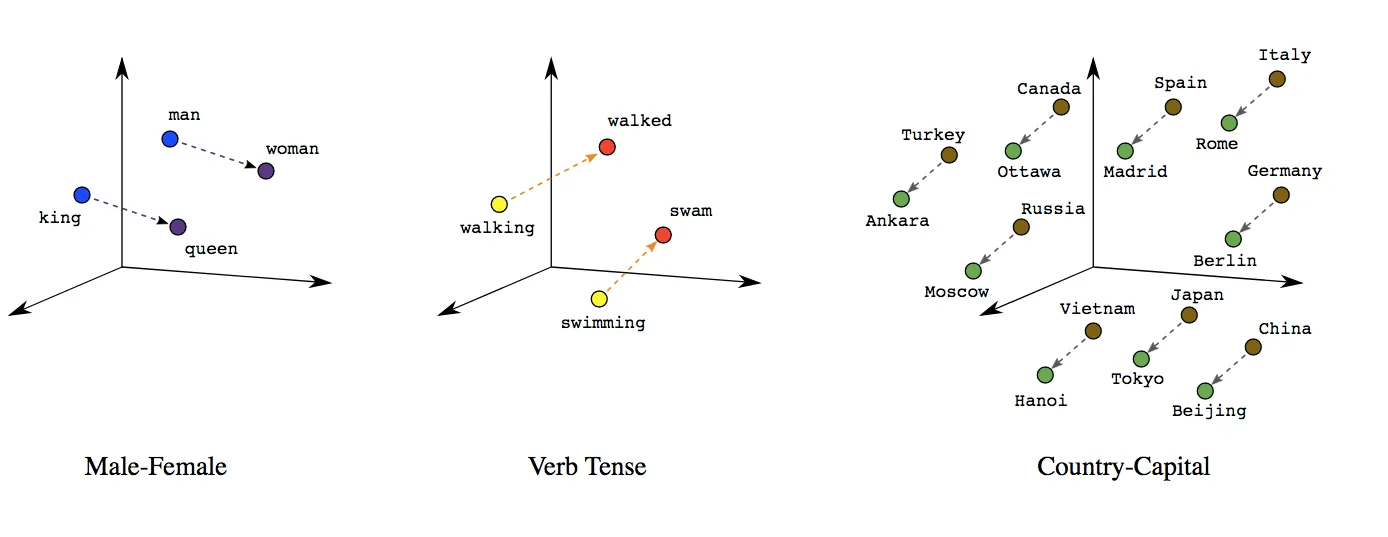
텍스트의 의미나 문맥을 벡터값, 수치적으로 변환 (비정형 데이터 -> 고차원의 벡터 형태)
텍스트를 기계가 이해하고 처리할 수 있도록 함
자연어 처리(NLP), 머신러닝에서 중요한 역할을 함
OpenAIEmbeddings, GoogleGenerativeAIEmbeddings, HuggingFaceEmbeddings, OllamaEmbeddings 등이 있음
https://huggingface.co/BAAI/bge-m3 모델이 오픈소스 모델 중에 한국어 임베딩 성능이 좋다고 함
from langchain_community.embeddings import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(
model_name="BAAI/bge-m3",
model_kwargs = {'device': 'cpu'}, # 모델이 CPU에서 실행되도록 설정. GPU를 사용할 수 있는 환경이라면 'cuda'로 설정할 수도 있음
encode_kwargs = {'normalize_embeddings': True}, # 임베딩 정규화. 모든 벡터가 같은 범위의 값을 갖도록 함. 유사도 계산 시 일관성을 높여줌
)
embed = embeddings.embed_documents(
[
"안녕 영광",
"동해물과 백두산",
"마르고 닳도록",
"하느님이 보우하사",
"우리나라 만세"
]
)
print(f"len(embed): {len(embed)}")
print(f"len(embed[0]): {len(embed[0])}")
print(f"len(embed[1]): {len(embed[1])}")
print(f"embed: {embed}")- 실행결과

from langchain_core.documents import Document
docs_for_test_embed = [
Document(page_content="사과", metadata=dict(page=1)),
Document(page_content="애플", metadata=dict(page=1)),
Document(page_content="바나나", metadata=dict(page=2)),
Document(page_content="오렌지", metadata=dict(page=2)),
Document(page_content="고양이", metadata=dict(page=3)),
Document(page_content="야옹", metadata=dict(page=3)),
Document(page_content="강아지", metadata=dict(page=4)),
Document(page_content="멍멍", metadata=dict(page=4)),
Document(page_content="해", metadata=dict(page=5)),
Document(page_content="달", metadata=dict(page=5)),
Document(page_content="물", metadata=dict(page=6)),
Document(page_content="불", metadata=dict(page=6)),
]
db = FAISS.from_documents(docs_for_test_embed, embeddings)
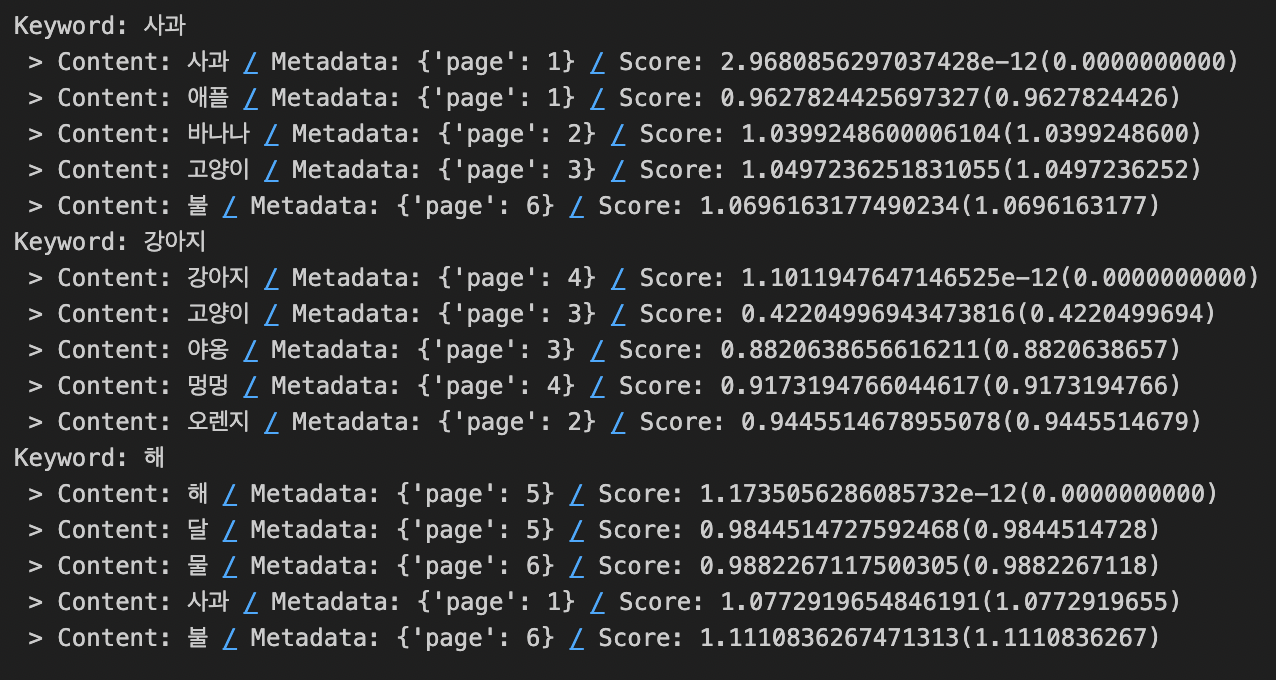
def similarity_search_with_score(keyword: str) -> None:
results_with_scores = db.similarity_search_with_score(keyword, k=5)
print(f"Keyword: {keyword}")
for doc, score in results_with_scores:
print(f" > Content: {doc.page_content} / Metadata: {doc.metadata} / Score: {score}({score:.10f})")
similarity_search_with_score("사과")
similarity_search_with_score("강아지")
similarity_search_with_score("해")- 실행결과
저장 (VectorStore)
FAISS(Facebook AI Similarity Search), Chroma, Pinecone, Amazon OpenSearch, ElasticSearch 등이 있음
from langchain_community.vectorstores import FAISS
from langchain_community.vectorstores.utils import DistanceStrategy
vectorstore = FAISS.from_documents(splits,
embedding = embeddings,
)
# 로컬에 DB 저장
MY_FAISS_INDEX = "MY_FAISS_INDEX"
vectorstore.save_local(MY_FAISS_INDEX)검색 (Retriever)
유사도 높은 5문장 추출
# 로컬 DB 불러오기
vectorstore = FAISS.load_local(MY_FAISS_INDEX,
embeddings,
allow_dangerous_deserialization=True # 잠재적으로 위험한 데이터 구조나 객체를 포함할 수 있는 인덱스 파일의 로딩을 허용. 주로 자신이 직접 생성하고 저장한 인덱스 파일을 로드할 때 사용
)
retriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": 5}) # 유사도 높은 5문장 추출
retrieved_docs = retriever.invoke("라마3")
retrieved_docs-
실행결과

-
Search Type 비교
| 특징 | 유사도 검색 (Similarity Search) | MMR (Maximal Marginal Relevance) |
|---|---|---|
| 기본 원리 | 벡터 간의 유사도를 계산하여 가장 유사한 결과를 반환 | 유사도와 다양성을 모두 고려하여 결과를 반환 |
| 주요 목적 | 입력 쿼리에 가장 유사한 항목 찾기 | 입력 쿼리에 유사하면서도 중복되지 않는 다양한 항목 찾기 |
| 검색 방법 | 코사인 유사도, 유클리드 거리 등 벡터 간 거리 측정 | 유사도 점수와 함께 정보의 다양성을 고려한 점수 계산 |
| 사용 사례 | 추천 시스템, 검색 엔진, 정보 검색 | 문서 요약, 중복 없는 검색 결과 제공 |
| 장점 | 구현이 간단하고 빠른 검색 가능 | 검색 결과의 다양성과 정보 제공의 균형 유지 |
| 단점 | 검색 결과가 중복되거나 편향될 수 있음 | 구현이 복잡하고 계산 비용이 높을 수 있음 |
검색
from langchain import hub
from langchain_core.runnables import RunnablePassthrough
prompt = hub.pull("rlm/rag-prompt") # https://smith.langchain.com/hub/rlm/rag-prompt
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| output_parser
)
chain.invoke('퍼플렉시티가 투자받은 금액?')- 실행결과

성능 개선
Ensemble Retriever
Dense Retriever와 Sparse Retriever 둘을 적절하게 섞으면 결과가 더 좋음
| 특징 | Dense Retriever | Sparse Retriever |
|---|---|---|
| 주요 알고리즘 | 신경망 기반 (BERT, RoBERTa 등) | 전통적 IR 모델 (BM25, TF-IDF 등) |
| 연산 효율성 | 계산 복잡도 높음 | 계산 복잡도 낮음 |
| 메모리 사용량 | 메모리 사용량 높음 | 메모리 사용량 낮음 |
| 검색 성능 | 높은 정확도 (특히 문맥 이해) | 낮은 정확도 (단순 단어 매칭) |
| 훈련 필요성 | 대규모 데이터로 훈련 필요 | 훈련 불필요 (사전 구축된 모델 사용) |
| 장점 | 높은 검색 정확도, 문맥 이해 능력 | 빠른 검색 속도, 낮은 메모리 사용 |
| 단점 | 높은 계산 비용, 대규모 데이터 필요 | 낮은 정확도, 문맥 이해 부족 |
Context Reorder
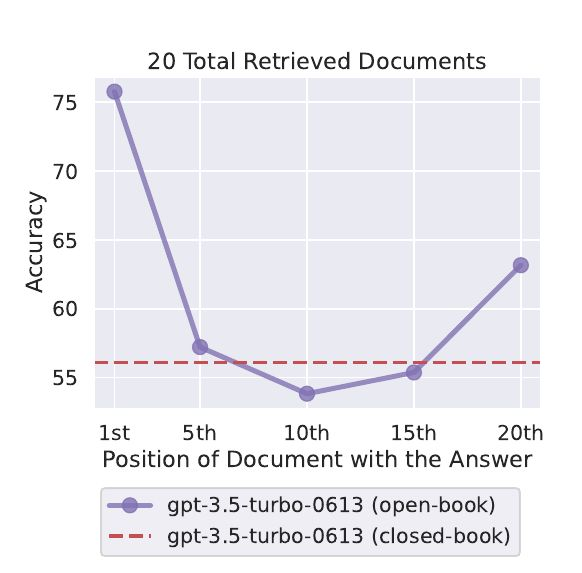
모델이 긴 컨텍스트 중앙에 있는 검색 문서들을 거의 무시하다시피 함
LongContextReorder 사용해서 재정렬 필요
관련 논문 (중간에서 길을 잃다: 언어 모델이 긴 맥락을 사용하는 방법)
😚 참조
https://ollama.com/
https://python.langchain.com/docs/get_started/introduction/
https://python.langchain.com/docs/langserve/
https://docs.smith.langchain.com/
https://wikidocs.net/book/14473
https://wikidocs.net/book/14314
https://wikidocs.net/24603
https://github.com/teddylee777/langchain-kr

13개의 댓글





안녕하세요~! 게시글 잘 봤습니다.
RAG 수행 결과가 "I'm not sure about that, but I can check it out for you"와 같은 답변만 반복하는데, 차이가 어디서 나는건지 궁금하더라구요! 혹시 이런 케이스가 있으셨나요?

저는 langchain의 프레임워크를 사용해 왔으며 이 프레임워크로 AI 애플리케이션을 구현하는 것은 매우 간단하며 이 프레임워크를 사용하여 웹사이트를 구현하기도 했습니다 https://tiktok-emoji.com
와 제가 lanchain poc 하면서 알고 싶었던 모든 내용이 하나의 포스트에 다 정리되어있네요....!
잘 읽었습니다! 적게 일 하고 많이 버세요👏