Momentum Contrast for Unsupervised Visual Representation Learning(MoCo) Review
cv_paper_reviews
목록 보기
8/22
1. Abstract & Introduction
- 이 논문은 dynamic dictionary(queue)와 contrastive loss를 이용한 이미지에서의 unsupervised learning을 실행하였다. 여기서 unsupervised learning은 dynamic dictionary를 참조할 수 있도록 인코더를 학습하는데 같은 key의 데이터는 가깝게, 반대로 다른 key는 멀도록 학습을 시킨다. 학습은 contrastive loss가 작도록 진행된다.
- MoCo는 크고 일관된 dictionary를 만드는 것이 목표인데 이 dictionary는 queue형태이며, 현재의 mini batch의 representation이 enqueue되고, 가장 오래된 representation이 dequeue되는 방식이다. 또한 momentum 방식을 이용해 queue의 일관성을 높였다.
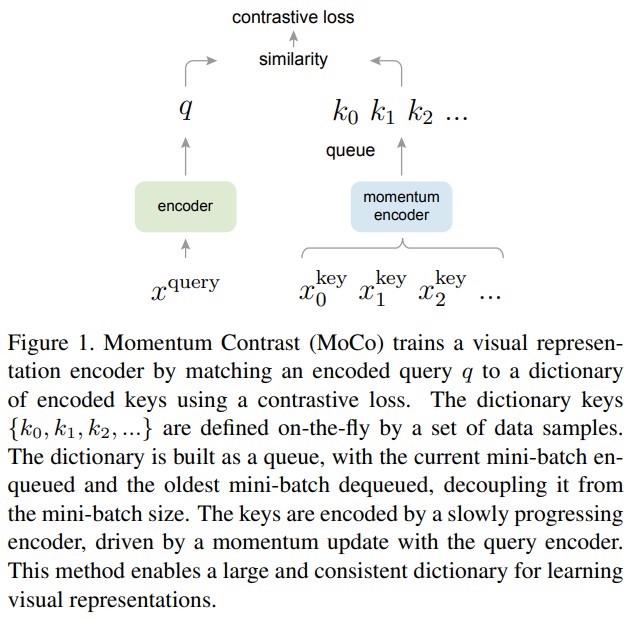
- MoCo는 pretext task로 discrimination task를 선택했다.
- unsupervise learning의 목적은 down-stream 작업에서 높은 성능을 낼 수 있는 pre-train representation들을 학습하는 것이다. 이 논문에서는 7가지 down-stream task를 진행했고 좋은 성능을 보였다고 한다.
What is contrastive loss?
- 서로 유사한 이미지 쌍(positive pair)인 가 있다면 이 둘은 가까워지도록 학습이 되어야 한다. 따라서 거리가 멀수록 loss가 크다면 이 loss를 줄이도록 학습을 진행할 것이다. 즉 ()loss =
- 반대로 서로 유사점이 거의 없는 negative pair 에서는 서로 멀어지도록 학습이 되어야 한다. 이를 위해 margin이라는 개념을 사용하였는데 이는 negative pair가 가져야 하는 최소한의 거리를 뜻한다. 따라서 ()loss =,
- 이 둘을 합치면 contrastive loss는 다음과 같다.
=
결과적으로 positive pair는 가깝게, negative pair는 최소한 margin의 거리만큼 멀어지도록 학습할 수 있다.
3. Method
3.1) Contrastive Learning as Dictionary Look-up
Equation (1)과 같은 Contrastive loss function이 사용되었다고 한다.
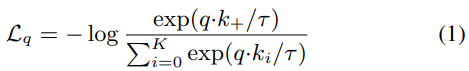
- 타우는 temperature hyper-parameter이고 loss funciton의 매개변수로 이미지 뿐만이 아닌 patch나 문맥을 이루고 있는 patch set이 들어갈 수 있다.
3.2) Momentum Contrast
- 이 논문에서는 key가 계속 주입되는 dynamic dictionary를 사용했는데 이 키들은 랜덤하게 뽑힌 키들이다.
- 여기서 두 가지의 가정이 사용되었는데 첫째는 많은 negative sample을 가지고 있는 큰 dictionary를 통해 좋은 feature를 학습할 수 있다는 가정이고, 둘째는 key가 계속 주입되는 상황에서도 dictionary key는 가능한 최대한 일관되어야 한다는 가정이다.
Dictionary as a queue
- MoCo의 핵심은 dictionary를 queue형태로 만들었다는 것에 있다. queue를 쓰게 되면 인코딩된 키들을 저장해서 학습에 사용할 수 있고, queue의 크기를 조절함에 따라 dictionary의 크기를 유연하게 조절할 수 있다.
- queue의 또다른 특징은 오래된 mini-batch 데이터를 순차적으로 제거하여 업데이트를 해준다는 것이다. 이는 새로 들어온 key와 차이가 많은 오래된 key를 내보내는 것이므로, consistency를 유지하는데 중요한 역할을 한다.
Momentum update
- 큰 dictionary를 사용하게 된다면 안의 key를 전부다 back-propagtaion을 해줘야한다. 문제는 key이 개수가 상당히 많다는 점이다. 이를 해결하기 위해 query의 인코더를 그대로 복사해서 key 인코더로 사용하였지만 이는 성능이 매우 좋지 않았다. 논문에서는 이 이유를 query의 값이 매우 빠르게 변하고 그에따라 key인코더의 값도 빠르기 때문이라 생각했고 momentum update를 적용해서 해결하고자 했다. 그 결과 key 인코더의 weight를 천천히 업데이트 하여 consistency를 만족할 수 있었고, momentum의 값이 0.9일 때보다 0.999일 때 더 좋은 성능을 보였다고 한다.
Relations to previous mechanisms
- 이 부분에서는 MoCo와 선행 연구되었던 2모델을 비교하였다.
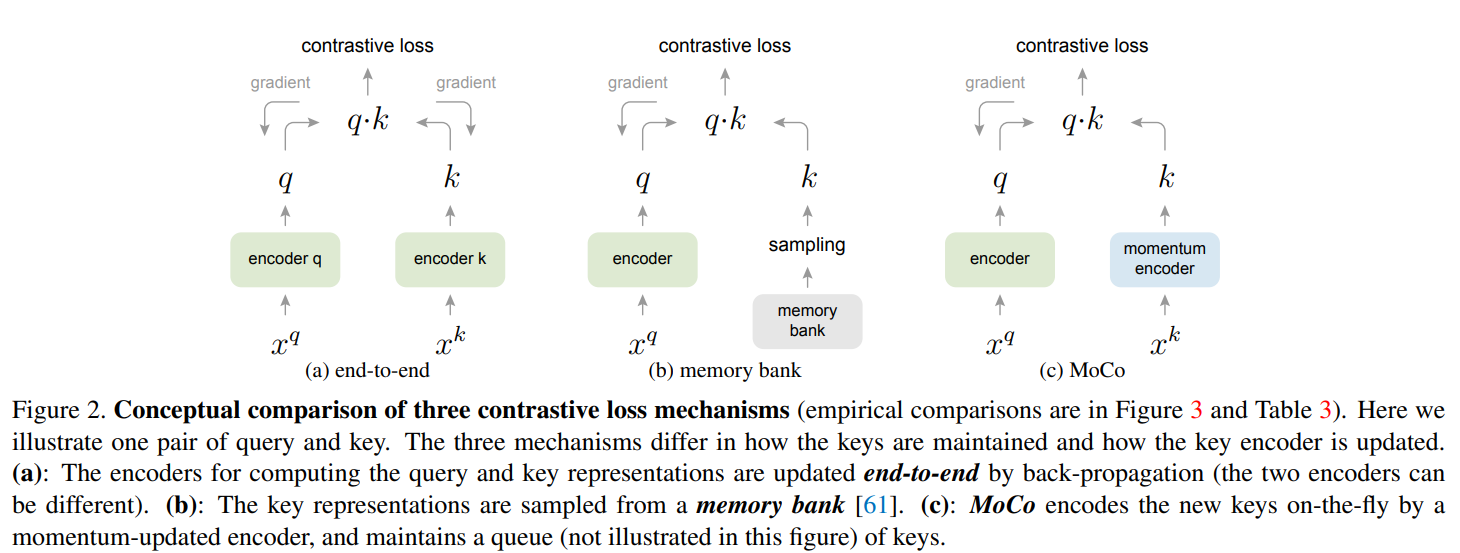
- 처음 비교한 모델은 end-to-end 모델이다. 이 모델은 미니 배치 내의 샘플을 dicitonary로 사용한다. 이는 큰 dictionary를 사용하고 싶은 경우나, local position과 같은 pretext task를 적용하기 어렵다는 단점이 있다.
- 그 다음은 momery bank 모델과 비교하였다. 이 모델도 back propagation하는 과정이 없어 dictionary에 많은 데이터를 저장할 수 있다는 장점이 있다. 그러나 dictionary의 representation은 쓰여질 때만 update되는 방식을 가지고 있어 dictionary에 오래전에 업데이트 된 representation도 포함되어 있다는 단점이 있다.
3.3) Pretext Task
- 이 논문에서는 instance discrimination task라는 pretext task를 진행하였고, 같은 이미지에서의 augmentation된 이미지 쌍은 positive pair로, 다른 이미지에서의 augmentation된 이미지 쌍은 negative pair로 분류하여 학습하였다고 한다. 미니 배치에서 postive pair이면 인코더에, negative pair이면 momentum 인코터와 queue에 데이터를 넣어주었다고 한다.
Techinical details
- 이 논문에서는 인코더로 ResNet을 사용하였고, 이 인코더에서는 L2 norm을 사용하여 벡터를 출력하는데 이 벡터가 query나 key이다.
Equation (1)의 temperature값은 0.07로 정해주었다.
Shuffling BN
- 이 논문에서 쓰인 인코더()는 batch normalization을 포함하고 있다. 그런데 이 논문의 경우 batch nomalization은 모델의 학습을 방해한다고 한다.
- 논문에서는 이를 해결하기 위해, suffling BN으로 해결했다.
-보류 - (batch normalization에 대한 추가적인 공부가 필요하다 ㅠㅠ)
참조

호수공원