1. Introduction
- In this paper, it proposed semantic segmentation with one-shot learning which is pixel-level prediction with a single image and it's mask.
- A simple implementation of one-shot learning for segmentation may cause overfitting and hard to optimize. This paper will deal with such problems
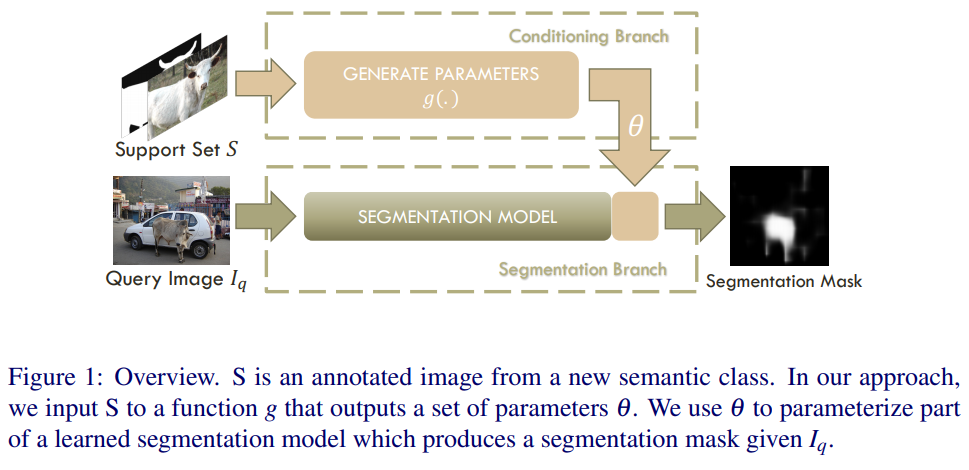
- This paper proposed two-branched approach to one-shot segmentation. Figure 1 shows overall structure of the branches. First branch takes labeled image as input and produces a vector of parameters as output. Second branch takes these parameters as well as a new image as input and produces a segmentation mask of the image for the new class as output.
3. Problem Setup
- The main purpose of this paper is to learn model f() that, when given a support set and query image, predicts a binary mask for the semantic class.
- During training, the model will consume image-mask pairs and at testing, the query images are only annotated for new semantic classes. As a result, there is no same image class for train set and test set.
4. Proposed Method
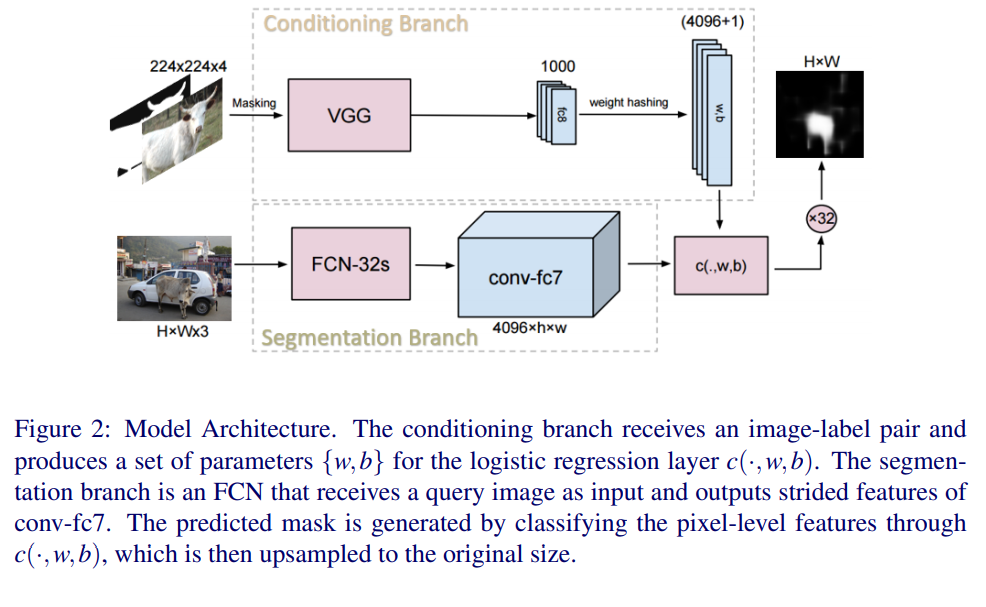
4.1: Producing Parameters from Labeled Image
- VGGnet is used for base model to genreate conditioning branch.
- label contains only the target object
- weight hashing is good for avoiding overfitting
4.2: Dense Feature Extraction
- FCN-32s is used
4.3: Training Procedure
- selects image-label pair and maximize the log likelihood of the ground-truth mask.
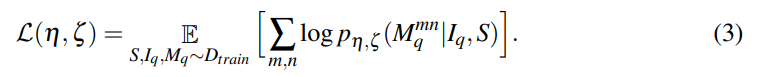
4.4: Extension to k-shot
In k-shot learning, it contains more support sets.
8. Conclusion
In this paper, the proposed model learn to learn an ensemble classier and use it to classify pixels. As the result, the model is faster and good performance.

References
https://arxiv.org/abs/1709.03410

호수공원