1. Basic concept


-
Human can recognize that the query is pangliln based on difference between four images, but it is chellenging for computer because there are a few images
-
traditional purpose of deep learning is recognizing certain class from the image, however in few shot learning, it's purpose is learning to learn -> learning similarity and differences between objects
-
few shot learning is kind of meta learning
What is meta learning

- meta learning is learn to learn. For example, there are query which is unknown and there are 6 support set. Then, you might know the query is otter by comparing query with support set.
Supervised learning vs few shot learning
supervised learning

- test samples are from known classes
few shot learning

- Query samples are from unknown classes
Relation between accuracy and ways
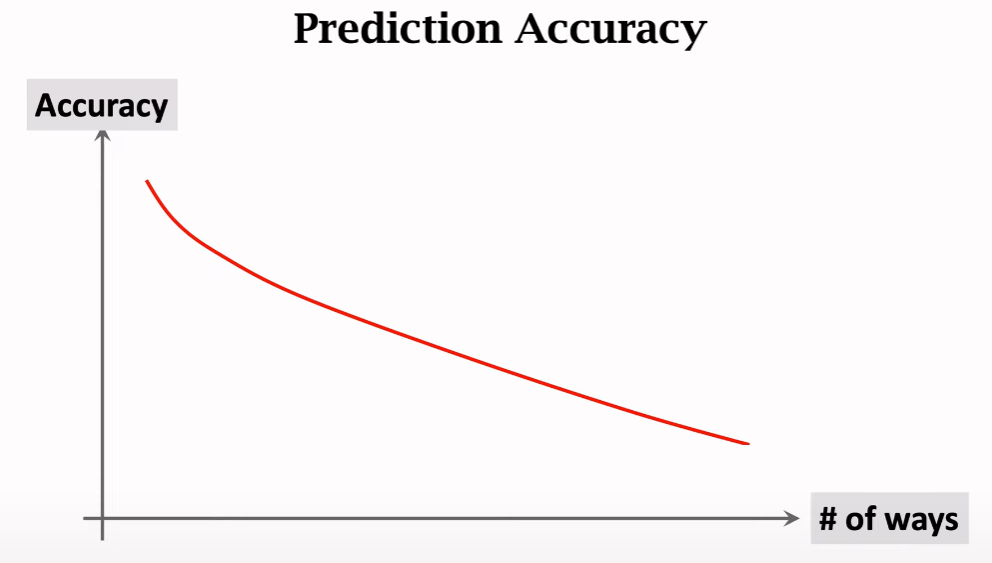
Relation between accuracy and shots
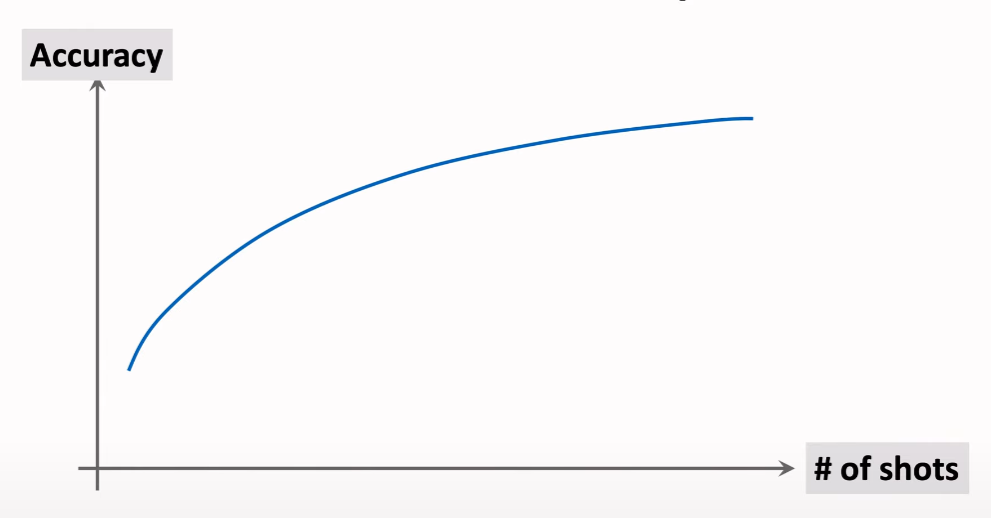
2. Siamese Network
- there are two ways for training this network
2.1: Learning Pairwise Similiarity Scores

There are two kind of samples ( Positive samples and negative samples )
2.1.1: CNN for Feature Extraction
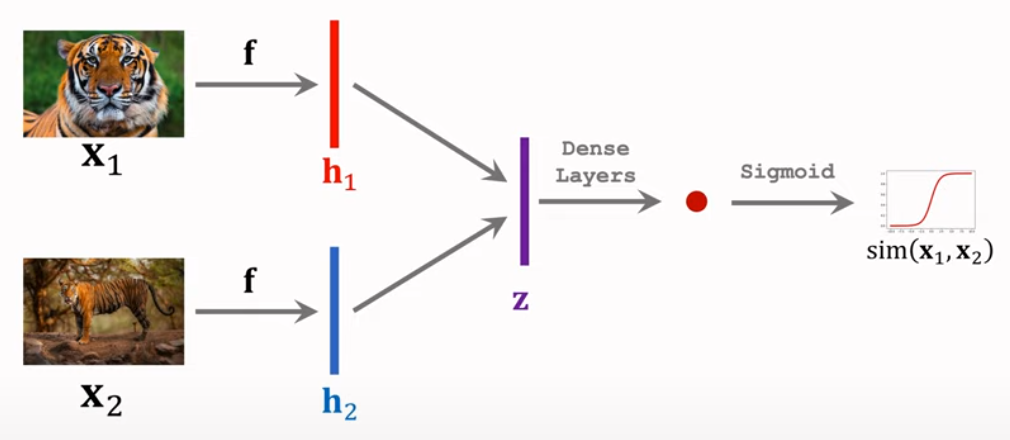
First, the model should extract features from sample with CNN(f). f will produce two feature vectors(h1 & h2). Then the difference between two vector(z) will go through dense layers and sigmoid. The output should be 1 if input sample is positive sample. Otherwise, the output should be 0(when negative sample). The fully connected layer will scale the difference between two object 0 to 1.
As you can see, the structure looks like siamese twins. The loss will go through dense layser and CNN for backpropagation

(when input is negative sample)
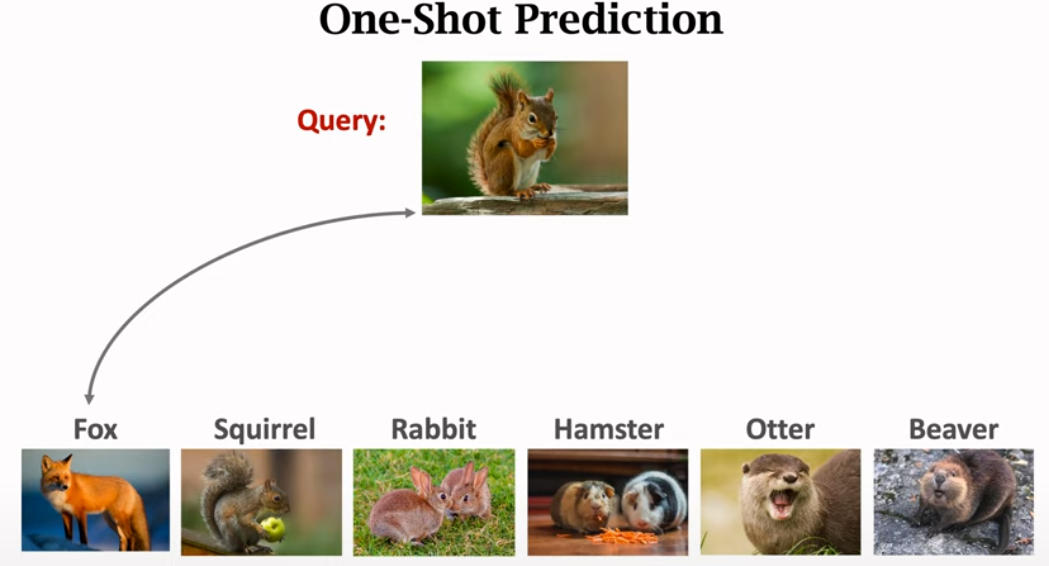
2.1.2: One-show Prediction
2.2: Triplet Loss
Another method for training siamese network
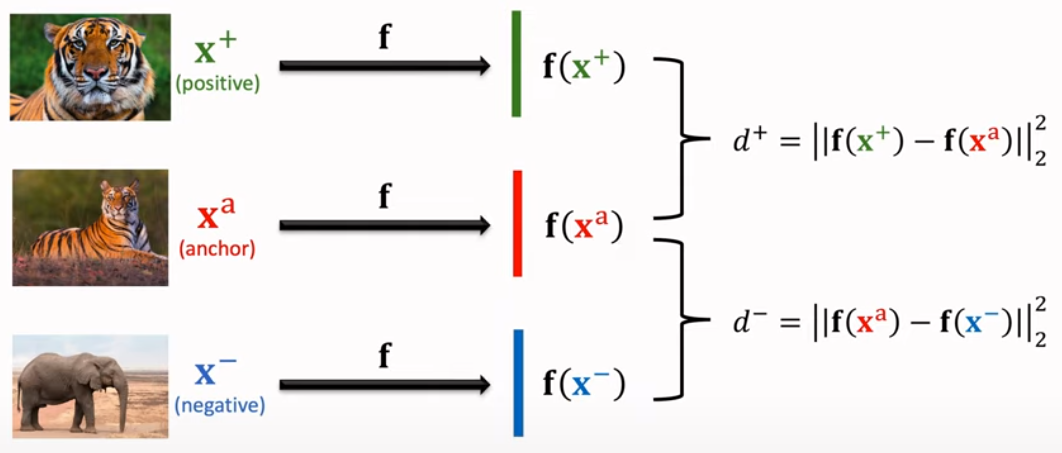
First, choose anchor object. After then choose one positive object and negative object from datset. By calculating feacture vector from these three objects, finally calculate postive distance and negative distance. The positive distance should be small and negative distance big enough.

Finally, the loss function should be like upper image.
After training siamese network, use the network for one-shot prediction
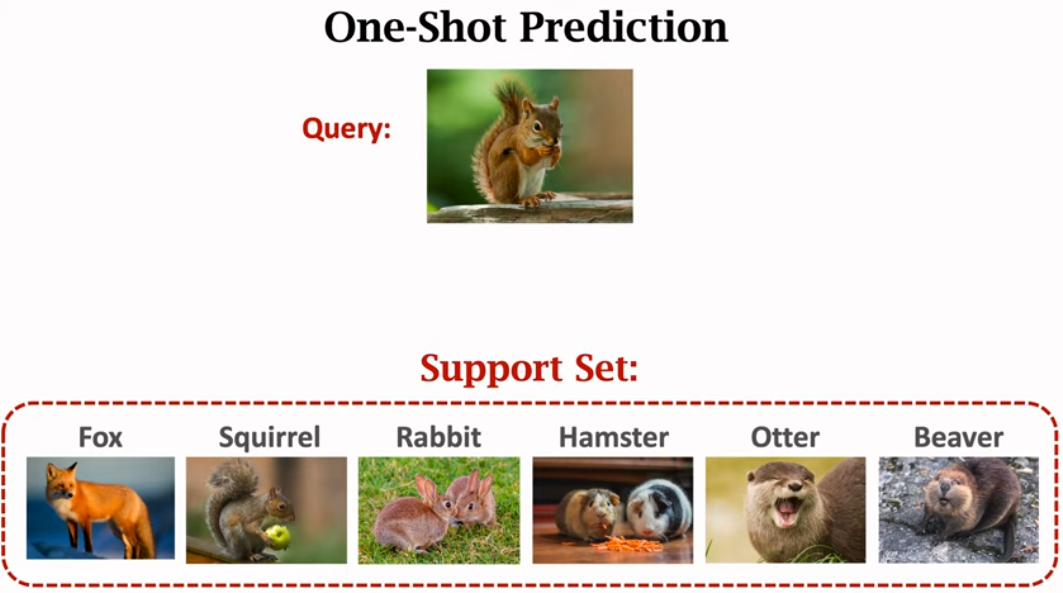
3. Pretraining and Fine Tuning
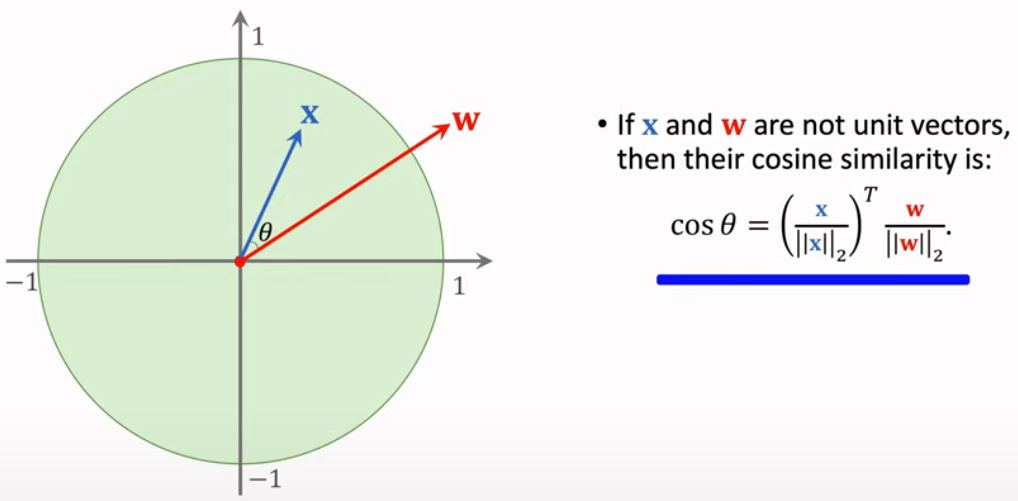
3.1: Cosine Similarity
The cosine similarity means how two vectors are similiar to each other.
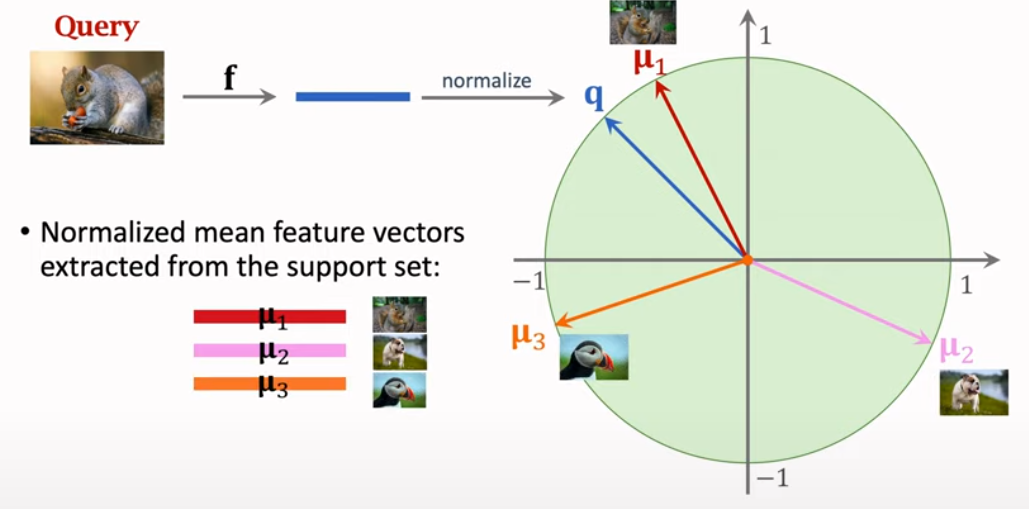
3.2: Extracting Feature Vector
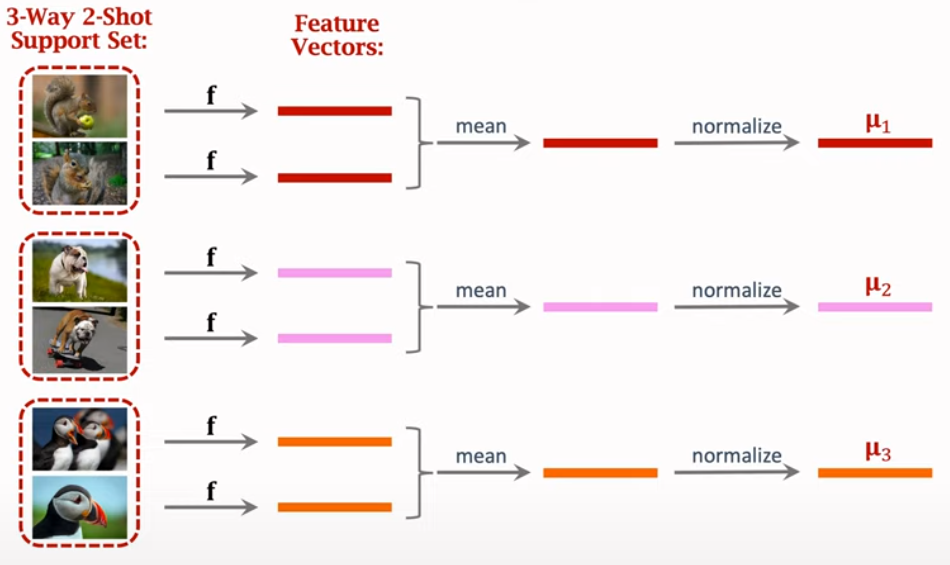
3.3: Making Few-Shot prediction
There are three normalized feature vectors, and calculate softmax to choose most similar object.
3.4: Fine tuning
In fine tuning, it updates weight and bias of feature extractor(CNN) based on support set.

3.5: Entropy Regularization
In few shot learning, there are a few dataset and can cause overfitting. To prevent the case we can sue entropy regularization and it makes good sense.

references
