Diffusion 모델은 이미지 생성에서 이미 표준으로 자리잡았다. 최근에는 이 기술을 비디오로 확장하는 연구가 활발히 진행되고 있다. 하지만 비디오는 단순히 여러 이미지 프레임을 이어 붙이는 것이 아니라, 시간 축에서 자연스러운 움직임과 장면의 일관성을 유지해야 하기 때문에 훨씬 더 어려운 기술이라 볼 수 있다.
이번 글에서는 Text-to-Video 분야에서 중요한 세 가지 연구를 살펴본다.
1. Video Diffusion Models
- Diffusion을 비디오로 확장한 초기 연구와 그 한계.
2. Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
- Latent 공간에서 비디오를 생성해 계산 효율을 크게 높이고, 단계적 학습으로 고해상도와 긴 시퀀스까지 안정적으로 학습한 방법.
3. Lumiere: A Space–Time Diffusion Model for Video Generation
- 기존 keyframe → temporal super-resolution 방식 대신, 시공간을 함께 처리하는 STUNet으로 한 번에 긴 영상을 생성하는 구조.
이 흐름을 통해 Video Diffusion이 어떻게 발전해 왔는지, 그리고 왜 Stable Video Diffusion과 Lumiere가 중요한지 살펴본다.
1. Video Diffusion Models
1.1 연구 주제와 주요 기여
'Video Diffusion Models' 논문은 이미지 생성에서 우수한 성능을 보인 Diffusion 모델을 비디오 생성 분야로 확장한 최초의 연구이다. 본 논문의 주요 기여는 다음과 같다.
- 이미지 기반 확산 모델인 DDPM을 비디오로 확장하여 비디오 생성의 시간적 일관성과 높은 화질을 달성
- 공간과 시간 정보를 함께 처리할 수 있는 3D U-Net 아키텍처를 제안
- 이미지와 비디오 데이터를 병렬로 학습하여 데이터 효율성과 비디오 생성 성능을 향상
이 연구는 비디오 생성 분야에서 확산 모델의 실용성과 우수성을 최초로 입증했다는 점에서 중요한 표준적 기초를 제공했다.
1.2 연구 배경과 관련 연구
Diffusion Models
디퓨전 모델은 데이터에 노이즈를 점진적으로 추가한 후 다시 제거하는 과정을 반복하여 데이터를 생성하는 방식이다. 대표적인 모델은 DDPM(Denoising Diffusion Probabilistic Models)으로, 이미지 생성에서 높은 품질을 달성했다.
기존 모델의 한계
기존의 비디오 생성 연구는 주로 GAN이나 VAE 기반으로 진행되었다. GAN은 학습 과정이 불안정하고 긴 비디오의 일관성 유지가 어려우며, VAE는 생성 품질이 낮고 고해상도의 비디오 생성에 제한이 있었다. 따라서 이미지 생성에서 성공적인 확산 모델을 비디오 생성에 적용하는 연구가 필요했다.
1.3 주요 제안
1.3.1 3D U-Net 구조
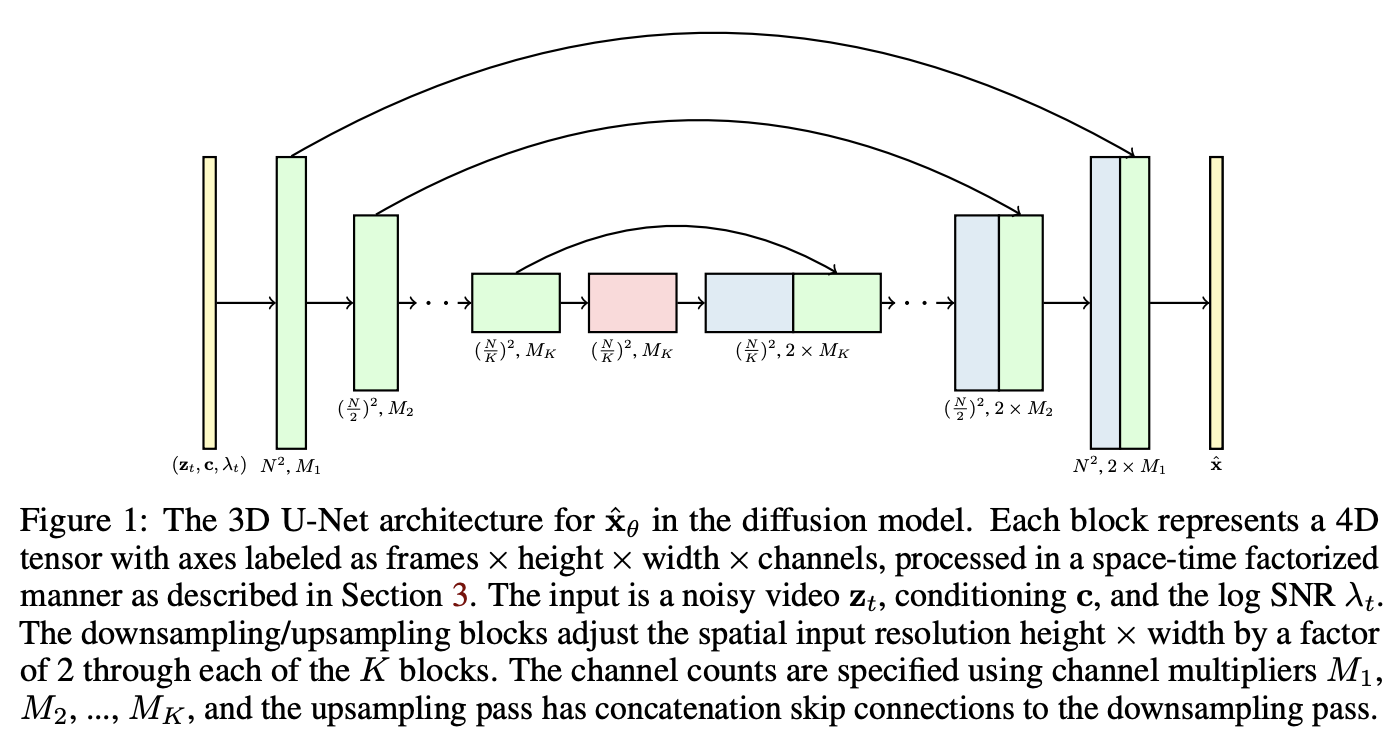
기존 이미지 확산 모델이 사용하는 2D U-Net 구조를 비디오의 공간과 시간 정보를 함께 다룰 수 있도록 3D U-Net으로 확장하였다. 이 구조는 영상 프레임들을 동시 처리하여, 각 프레임 간의 일관성을 자연스럽게 유지할 수 있다. 예를 들어 사람이 걷는 장면을 생성할 때 모든 프레임에서 움직임이 매끄럽게 연결되도록 돕는다.
1.3.2 이미지와 비디오의 병렬 학습
이미지 데이터와 비디오 데이터를 동시에 학습하여 각 데이터가 가진 고유한 정보를 상호 보완적으로 활용하였다. 예를 들어, 이미지를 학습할 때 얻은 세밀한 질감 표현을 비디오 생성에 활용해, 높은 품질의 프레임을 생성할 수 있게 하였다.
1.3.3 조건부 비디오 생성 기법
텍스트나 특정 조건을 입력으로 받아 원하는 내용을 반영한 비디오를 생성할 수 있는 조건부 생성 방식을 제시하였다. 사용자가 원하는 동작(예: 로봇이 물체를 미는 동작)을 명시하면, 이를 정확하게 반영한 비디오를 생성할 수 있다.
1.4 주요 실험 내용 및 결과
본 논문은 다양한 비디오 데이터셋(UCF-101, BAIR Robot Pushing 등)을 통해 제안된 방법의 성능을 평가하였다.
-
UCF-101 데이터셋 실험
- 기존 GAN 기반 모델 대비 비디오 품질이 월등히 뛰어남
- 프레임 간의 움직임과 전환이 매우 부드럽고 자연스러움
- 특히 사람의 움직임이나 스포츠 장면과 같은 복잡한 동작도 일관성 있게 생성
-
BAIR Robot Pushing 데이터셋 실험
- 로봇이 물체를 미는 행동과 같은 구체적이고 연속적인 동작을 정확히 표현
- 조건부 생성을 통해 특정 조건(로봇의 이동 경로 등)을 잘 반영하였고, 정확도 또한 매우 높았음
추가로, 이미지와 비디오 데이터를 함께 학습하는 방식이 개별로 학습하는 방식보다 데이터 활용 효율성이 뛰어나고 생성된 비디오의 품질이 더 우수하다는 점을 실험적으로 증명하였다.
1.5 결론
'Video Diffusion Models' 논문은 확산 모델을 비디오 생성에 최초로 적용하여 시공간적 일관성과 높은 품질의 영상 생성이 가능함을 입증하였다. 3D U-Net 아키텍처와 이미지-비디오 병렬 학습 방식을 통해 기존 비디오 생성 방법의 한계를 효과적으로 극복하였다. 이 연구는 이후 등장한 텍스트-투-비디오 모델 연구에 표준적인 기초가 되었으며, 비디오 콘텐츠 생성 및 다양한 응용 분야에서의 활용 가능성을 크게 확장하였다.
2. Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets

2.1 연구 주제와 주요 기여
'Stable Video Diffusion(SVD)' 논문은 기존 Video Diffusion Models 이후 등장한 최신 연구로, Latent Diffusion 기반의 비디오 생성 모델을 대규모 데이터셋으로 확장해 더 높은 품질과 효율을 달성한 연구이다. 본 논문의 주요 기여는 다음과 같다.
- Latent 공간에서 비디오 확산을 수행해 기존 픽셀 도메인 방식 대비 GPU 메모리 사용과 연산량을 획기적으로 줄이고, 더 빠른 샘플링을 가능하게 했다.
- 약 6억~10억 프레임 규모의 비디오 데이터셋을 체계적으로 전처리·필터링해 사전학습과 고품질 파인튜닝 데이터셋을 구축하고, 이를 활용해 훨씬 다양한 장면과 더 높은 해상도의 영상을 안정적으로 생성할 수 있게 했다.
- 단계적 학습 전략(Stage I: 텍스트-이미지 사전학습 → Stage II: 대규모 저해상도 비디오 사전학습 → Stage III: 고해상도 파인튜닝)을 도입해 긴 시퀀스(최대 25프레임 이상)와 고해상도(576×1024)에서도 안정적으로 학습 및 생성할 수 있는 실질적 방법론을 제시했다.
이 연구는 "Latent 기반 Video Diffusion을 산업·서비스 수준으로 스케일링하는 구체적 레시피를 제공"했다는 점에서 기존 연구 대비 큰 진전을 이루었다.
2.2 연구 배경과 기존 한계
기존 Video Diffusion Models의 한계
Ho et al.(2022)이 제안한 Video Diffusion Models는 픽셀 도메인에서 3D U-Net을 사용해 시공간적 비디오 생성을 성공적으로 수행했으나, 다음과 같은 한계가 있었다.
- 픽셀 공간에서 직접 확산을 수행하다 보니 GPU 메모리 사용량이 매우 크고, 샘플링 속도가 느려 긴 시퀀스나 고해상도 비디오 생성에 한계가 있었다.
- 실험은 작은 해상도(64×64 ~ 128×128), 짧은 길이(16프레임)에 머물러 복잡한 장면이나 긴 동영상 생성에는 적용하기 어려웠다.
이를 개선하기 위해 SVD에서는 Stable Diffusion에서 검증된 latent space diffusion을 비디오 생성에 도입해 이러한 한계를 근본적으로 해결하고자 했다.
✅ 픽셀 공간에서의 diffusion vs. latent 공간에서의 diffusion
픽셀 공간에서 diffusion을 수행한다는 것은, 예를 들어 256x256 크기의 실제 RGB 이미지(또는 비디오 프레임 시퀀스)에 직접 노이즈를 점차 추가하고 이를 역으로 제거하면서 이미지를 복원하는 방식이다. 이렇게 하면 디테일을 그대로 다뤄야 하기 때문에 계산량과 메모리 소모가 막대하다.반면 Latent 공간 diffusion은 원본 이미지를 먼저 Encoder(VAE)를 통해 훨씬 작은 Latent 벡터(예: 256x256 이미지를 32x32로 압축)로 변환한 뒤, 이 압축된 표현에서 노이즈를 추가하고 이를 점진적으로 제거(denoising)하는 방식이다. 이후 Decoder를 거쳐 다시 원래 이미지 크기로 복원한다.
이렇게 하면 픽셀 공간에서 직접 복원하는 것보다 연산량이 수십 배 줄어들고, Decoder가 세부적인 질감을 대신 채워주기 때문에 훨씬 효율적이며 더 긴 비디오도 안정적으로 생성할 수 있다.
2.3 주요 제안
2.3.1 Latent Video Diffusion
Stable Video Diffusion은 VAE(Variational Autoencoder) 기반의 latent 공간에서 비디오 확산을 수행한다. 즉, 비디오 프레임을 encoder로 낮은 차원의 latent space로 압축하고, 이 latent space에서 diffusion 과정을 거쳐 다시 decoder를 통해 고해상도 픽셀 공간으로 복원한다.
기존에는 예를 들어 256×256 해상도의 RGB 비디오를 직접 생성했지만, SVD는 약 1/64로 압축된 latent 표현에서만 연산을 수행하기 때문에 같은 GPU 환경에서도 훨씬 큰 해상도와 더 긴 비디오를 처리할 수 있다. 이를 통해 기존 대비 약 64배 이상의 계산 효율성을 달성했으며, 논문에서도 "시간-공간 일관성을 유지하면서 리소스를 획기적으로 절감했다"는 점을 강조했다.
2.3.2 단계적 학습 (Recipe-based Scaling)
SVD는 긴 시퀀스와 고해상도를 한 번에 학습하면 gradient 폭주나 collapse가 발생하기 쉽다는 점을 지적하며, 이를 해결하기 위해 단계적으로 스케일을 확장하는 학습 전략을 제안했다.
1. Stage I: Image Pretraining
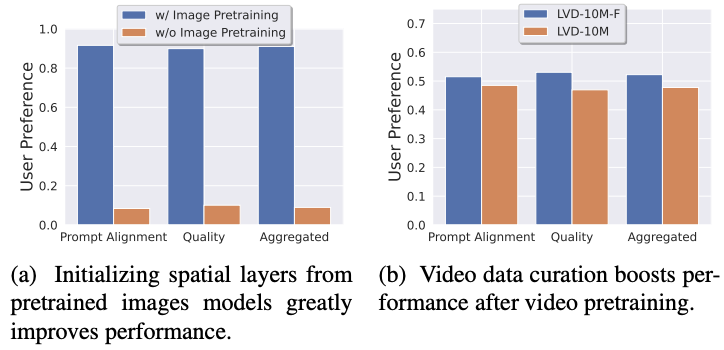
- 이 단계는 텍스트-이미지(T2I) 데이터만을 사용해서 diffusion model을 학습하는 단계로, Stable Diffusion 2.1 (SD 2.1) 모델을 기반으로 한다.
- 다만 SD 2.1을 그대로 사용하는 것이 아니라, EDM(Elucidated Diffusion Models) 프레임워크에 맞춰 noise schedule과 preconditioning function을 변경한 뒤, 이미지 데이터로 다시 finetuning을 진행한다.
- 기존 SD 2.1은 discrete noise level (1000개 σ)로 학습되어 있어, high noise regime에서 SNR이 너무 높아 dark / heavily noised 이미지 생성이 불안정했기에 재학습 한 것
- 구체적으로, 첫 1k iteration 동안에는 기존 SD 2.1에서 가져온 pretrained backbone의 time embedding layer만 학습하고 나머지는 freeze해, 새로운 EDM-style preconditioning에 부드럽게 적응시킨다.
- 이후 전체 backbone (spatial convolution & attention layers 포함)을 unfreeze하고, EDM-style 설정으로 이미지 학습을 30k iteration 추가 수행한다.
- 이렇게 해서 완성된 모델은 강력한 텍스처 및 구조(geometry, texture) 표현 능력을 가진 T2I diffusion backbone이 된다.
🔍 EDM(Elucidated Diffusion Models) 이란?
EDM은 NVIDIA의 Tero Karras 등이 발표한 논문에서 나온 것으로, Diffusion 모델을 학습할 때
- noise schedule
(어떤 σ 분포를 사용해 얼마나 noisy 한 샘플들을 학습에 넣을지)- preconditioning function
(σ에 따라 입력, 출력, skip connection을 어떻게 scale할지)- loss weighting
(σ 별로 loss를 얼마나 비중있게 줄지)같은 핵심 요소들을 체계적(이론적으로) 다시 설계한 방법이다. 이를 통해 기존 DDPM/Score matching 방식보다 훨씬 안정적이고 고품질의 샘플을 만들 수 있게 했고, 특히 고해상도 생성과 강한 노이즈 영역에서의 안정성을 크게 개선했다.
(σ (sigma): 노이즈의 표준편차. 얼마나 노이지하게 만들지?)
2. Stage II: Video Pretraining
- Stage II에서는 Stage I에서 준비된 강력한 spatial backbone에 temporal layer(temporal conv, temporal attention)를 삽입해 비디오 데이터를 학습한다.
- 약 6억 개 클립으로 이루어진 대규모 LVD-F 데이터셋을 사용하며, 해상도는 256×384, 길이는 14프레임으로 구성한다.
- 아키텍처는 SD 2.1의 U-Net에 temporal layer를 넣어 총 1.5B 파라미터 규모로 확장했다 (기존 spatial layer는 freeze하지 않고 joint training).
- 이 단계에서 temporal layer가 시공간 패턴을, decoder는 그에 맞는 texture를 동시에 학습하여 latent motion representation과 texture decoder가 자연스럽게 맞춰진다.
- training은 AdamW, LR=1e-4, batch=1536, 15%의 dropout으로 classifier-free guidance를 적용하며 진행했다.
3. Stage III: High-resolution Fine-tuning
- Stage III에서는 더 적은 수(약 25만)지만 훨씬 고품질의 비디오를 사용해 해상도를 576×1024로 올려 fine-tuning한다.
- noise schedule을 EDM-style에서 더 high noise 영역으로 이동(Pmean=0.5~1.0)시켜, 고해상도 질감 표현에서도 robust하게 학습되도록 한다.
- decoder의 일부를 selective unfreeze하여 spatial detail(사람 옷 주름, 머리카락, 배경의 fine texture 등)을 세밀하게 조정한다.
- 이 단계의 fine-tuning은 보통 50k iteration 정도 수행하며, exponential moving average를 사용해 안정성을 높였다.
논문은 이 3단계 학습 전략을 단순히 데이터만 늘리는 것이 아니라, motion과 texture를 점진적으로 맞추며 안정성과 장기 temporal consistency를 확보하기 위한 "핵심 레시피"라고 강조한다. 예를 들어, Stage II에서 걷기 같은 기본 motion과 질감을 익히고 Stage III에서 이를 더 긴 시퀀스로 자연스럽게 확장하며 마지막에 고해상도로 세밀함을 보강하는 식이다.
2.3.3 Noise Conditioning & Frame Interpolation
Latent noise를 시간 축에서 적절히 조절하고, 프레임 사이가 불연속적으로 보이는 경우 interpolation을 활용해 자연스럽게 이어주는 전략도 사용했다. 예를 들어 16~25프레임만 생성했을 때 프레임 간 차이가 커서 뚝뚝 끊겨 보이는 문제를 latent noise scheduling과 보간을 통해 부드럽게 만들었다. 이를 통해 긴 시퀀스에서도 자연스러운 motion flow를 유지할 수 있었다.
2.3.4 다양한 downstream finetuning 및 활용
논문에서는 이렇게 단계적으로 학습된 강력한 video diffusion backbone을 기반으로 여러 task-specific 모델을 빠르게 fine-tuning하여 아래와 같은 확장된 활용을 보였다.
1. 고해상도 Text-to-Video
- 576×1024 해상도의 text-to-video dataset(~1M)으로 fine-tuning하여, text prompt에 부드럽게 맞는 고해상도 비디오를 생성.
- UCF-101 zero-shot text-to-video 벤치마크에서 기존 모델 대비 월등히 낮은 FVD(242)를 기록.
FVD(Fréchet Video Distance)는 생성된 비디오가 실제 비디오와 얼마나 유사한지를 시간적 일관성까지 포함해 측정하는 지표로, 값이 낮을수록 더 자연스럽고 현실적인 비디오를 생성했음을 의미한다.
2. 고해상도 Image-to-Video
- text embedding을 CLIP image embedding으로 대체해 한 장의 이미지를 conditioning으로 넣어 비디오를 생성.
- channel-wise noise augmentation, temporal layer를 그대로 활용해 14, 25프레임 두 가지 버전을 학습.
- classifier-free guidance를 프레임 축을 따라 선형적으로 증가(linearly increasing)시켜 consistency와 saturation 문제를 해결.
3. Camera Motion LoRA

- temporal attention block에 low-rank adapter(LoRA, rank=16)를 삽입해 카메라 움직임 스타일을 제어.
- horizontal, zooming, static 등 LoRA를 통해 동일 conditioning frame에서 다양한 camera path를 입힐 수 있음.
4. Frame Interpolation
- 5프레임 출력 중 처음과 마지막을 conditioning으로 넣고, 중간 3프레임을 예측해 frame rate를 4배로 증가.
- 단 10k iteration 만에 부드러운 interpolation 성능 달성.
5. Multi-View Generation

- SVD의 strong motion prior를 활용해 single view 이미지를 입력받아 multi-view 비디오를 생성.
- Objaverse와 MVImgNet 데이터로 fine-tune하여 GSO test에서 Zero123XL, SyncDreamer 대비 PSNR, LPIPS, CLIP-S에서 모두 우수한 성능.
Stable Video Diffusion은 이렇게 EDM-style 단계별 학습으로 강력 motion+texture prior를 확보하고, 다양한 downstream task에 빠르게 확장해 state-of-the-art 성능을 훨씬 적은 자원으로 달성하는 범용적인 video generative framework를 구축했다는 데 큰 의의가 있다.
2.4 주요 실험 내용 및 결과
본 논문은 수억~10억 프레임 규모의 웹 비디오 데이터셋 및 기존 벤치마크(UCF-101, BAIR Robot Pushing 등)에서 성능을 평가했다.
- 해상도 및 시퀀스 길이 확장
- 기존 모델들이 주로 64×64 해상도에 16프레임으로 한정되었던 것과 달리, Stable Video Diffusion은 256×384 ~ 576×1024 해상도에서 14~25프레임을 안정적으로 생성하며, longer sequence fine-tuning에서도 robust함을 보였다.
- 다양한 스타일과 씬 생성
- 실사, 애니메이션, 시뮬레이션 등 다양한 스타일을 자연스럽게 생성했으며, 장면 변화가 큰 영상에서도 시간-공간적 일관성을 유지했다.
- FVD 및 사용자 평가
- FVD 및 사용자 평가에서도 더 향상된 결과를 보여줌
이러한 실험 결과는 "Latent 기반 확산과 단계적 학습이 실제로 긴 시퀀스와 고해상도에서도 강력하게 동작함을 입증"하는 중요한 근거가 되었다.
2.5 실험 환경 및 학습 세팅
Stable Video Diffusion 논문에서 사용한 실험 환경과 학습 세팅은 다음과 같다.
- 하드웨어 및 분산 학습
- NVIDIA A100 GPU 여러 대를 사용해 PyTorch 기반으로 학습을 수행했다.
- 데이터 병렬화(distributed data parallel)를 적용하여 수백만~10억 프레임 규모의 데이터셋을 효율적으로 학습했다.
- PyTorch DDP (Distributed Data Parallel)와 Slurm 스케줄링 기반으로 대규모 분산 학습을 수행했다.
Slurm은 대규모 GPU 서버나 슈퍼컴퓨터에서 작업(Job)을 관리하는 오픈소스 스케줄러이다. 쉽게 말해 여러 노드와 GPU를 가진 클러스터에서 "어떤 GPU에서 어떤 작업을 언제 실행할지"를 자동으로 배분하고 관리해주는 시스템이다. Stable Video Diffusion에서는 이러한 Slurm 기반 클러스터 환경을 사용해 수십~수백 대의 GPU에 모델 학습을 분산 배치하고, 각 작업의 실행, 모니터링, 오류 재시도 등을 자동으로 관리했다. 덕분에 대규모 비디오 데이터셋을 안정적이고 효율적으로 학습할 수 있었다.
- 데이터와 학습 기간
- 웹에서 수집한 대규모 비디오 데이터셋(총 수억~10억 프레임)을 사용해 단계별로 학습했다.
- 짧은 클립(14~16프레임) pretraining과, 25프레임 고해상도 fine-tuning을 포함해 전체적으로 수 주 이상 소요되었다.
이러한 분산 학습 및 단계적 스케일 전략 덕분에 고해상도·장시간 비디오를 안정적으로 학습할 수 있었으며, 논문에서는 이 과정을 통해 "산업적으로도 바로 활용 가능한 대규모 video diffusion 학습 방법론"을 정립했다고 강조한다.
2.6 결론
'Stable Video Diffusion'은 Video Diffusion Models의 픽셀 공간 처리 한계를 극복하고, Latent 공간에서의 효율적 확산을 통해 연산량과 품질을 동시에 확보하였다. 단계적 학습과 Noise Scheduling 기법을 통해 수억~10억 프레임의 대규모 데이터셋에서도 안정적으로 학습했으며, 이를 통해 고해상도·장시간·다양한 스타일의 비디오를 생성할 수 있는 실질적 T2V 파운데이션을 마련하였다.
이 연구는 이후 Seedance(2025)나 Lumiere(2024) 같은 최신 텍스트-투-비디오 모델에서 Latent 기반 고해상도 생성 방식을 채택하게 만든 직접적 계기가 되었으며, 산업 및 서비스 수준에서 대규모 비디오 생성 파이프라인을 설계할 때 중요한 참고가 되는 연구로 자리 잡았다.
3. Lumiere: A Space–Time Diffusion Model for Video Generation

3.1 연구 주제와 주요 기여
'Lumiere' 논문은 기존 텍스트-투-비디오 또는 비디오 생성 모델들이 겪던 시간 축 불연속성과 짧은 시퀀스의 한계를 극복하기 위해, 시공간(Space–Time)을 동시에 처리하는 새로운 확산 모델을 제안했다. 주요 기여는 다음과 같다.
- 기존에는 비디오를 프레임 단위 혹은 짧은 클립 단위로 생성한 후 이어붙이는 방식이라 움직임과 배경이 불연속적으로 보이는 문제가 존재
- Lumiere는 전체 타임라인을 한 번에 다루는 Space–Time U-Net 구조를 제안해 긴 시퀀스에서도 자연스럽고 일관된 비디오를 생성할 수 있음을 보여줌
- 이로써 텍스트-투-비디오 생성에서 장면의 자연스러운 변화, 등장 인물의 일관성, 배경의 지속성을 획기적으로 개선
3.2 기존 기술의 한계
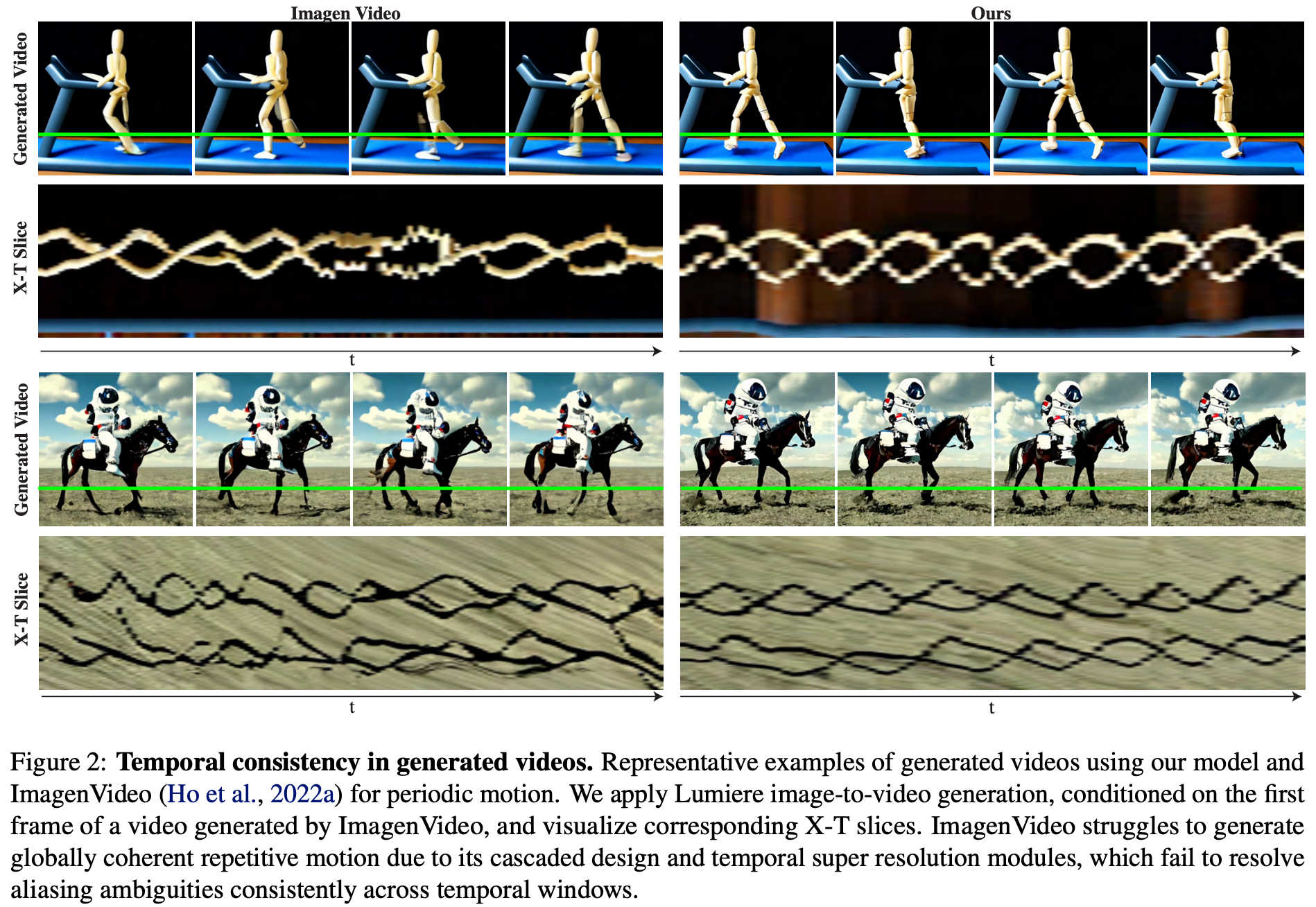
기존 Video Diffusion Models나 Stable Video Diffusion 같은 모델은 주로 "짧은 비디오를 여러 번 생성 → 나중에 시간 축으로 이어붙이는 방식"이었다. 구체적으로 Stable Video Diffusion은 보통 16~32프레임 정도의 짧은 클립을 생성해 이를 여러 번 나눠 만들고, 후처리(interpolation)나 연결 방식으로 긴 비디오처럼 이어 붙였다. 해상도 역시 256x256 정도의 latent space 해상도에서 diffusion을 수행해 최종적으로 복원했다.
이런 방식은
- 움직임의 연속성이 깨져 사람이 순간이동하거나 배경이 갑자기 바뀌는 문제가 생겼다. 예를 들어 같은 사람이 걸어가는데 옷 주름이나 그림자가 프레임 단위로 미묘하게 달라져 부자연스럽게 보였다.
- 장시간 시퀀스를 한 번에 학습하기 어려워, 시간적 일관성을 유지하기 위해 추가적으로 보간(interpolation)이나 smoothing을 넣어야 했다.
3.3 Lumiere 주요 제안
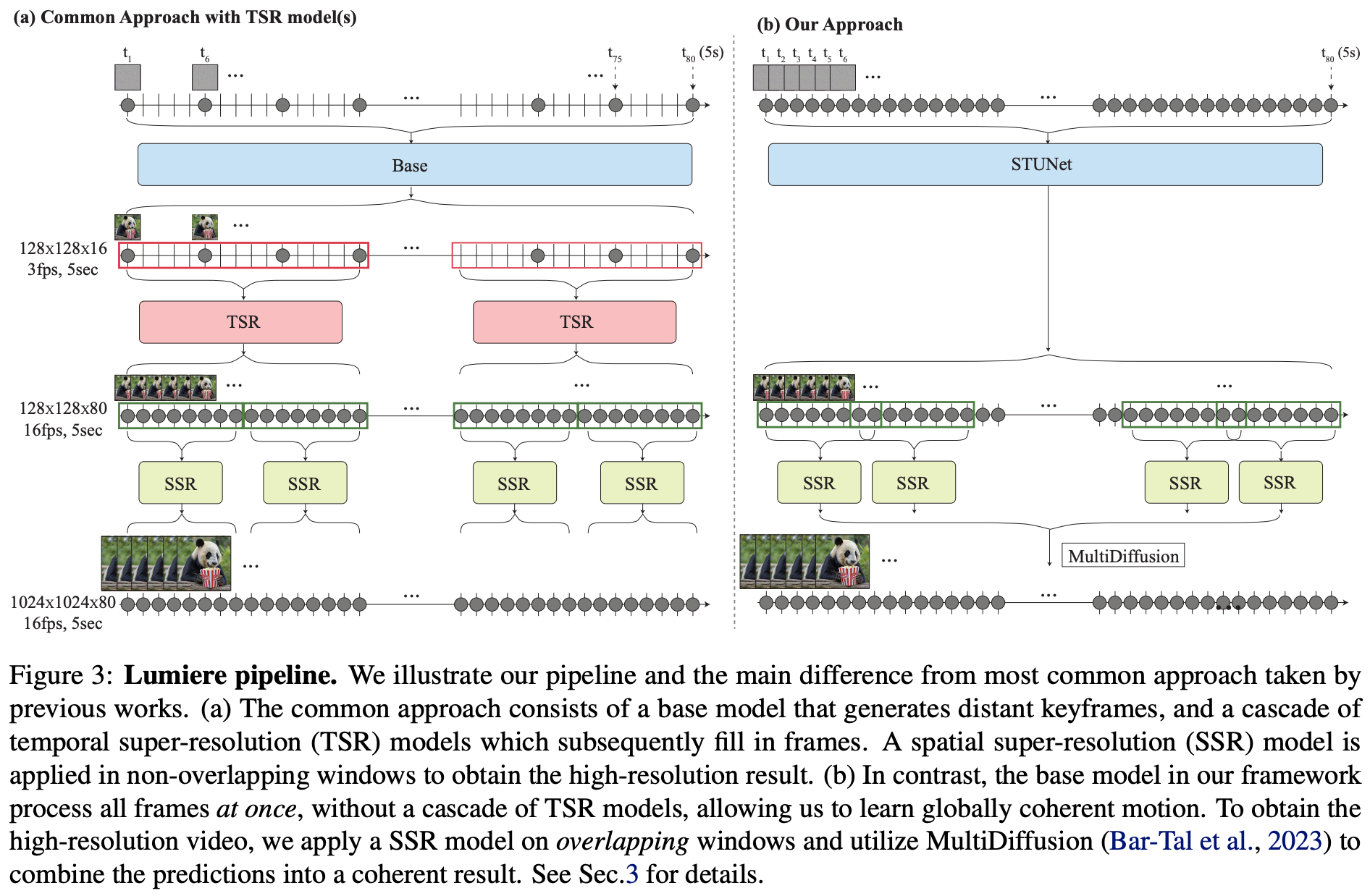
Lumiere는 기존 T2V(text-to-video) 모델들이 가진 ‘cascade + temporal super-resolution(TSR)’ 방식의 근본적 한계를 지적하고, 이를 해결하기 위해 시공간을 한번에 처리하는 Space–Time U-Net(STUNet)과 SSR(Spatial Super-Resolution)을 결합한 아키텍처를 고안했다.
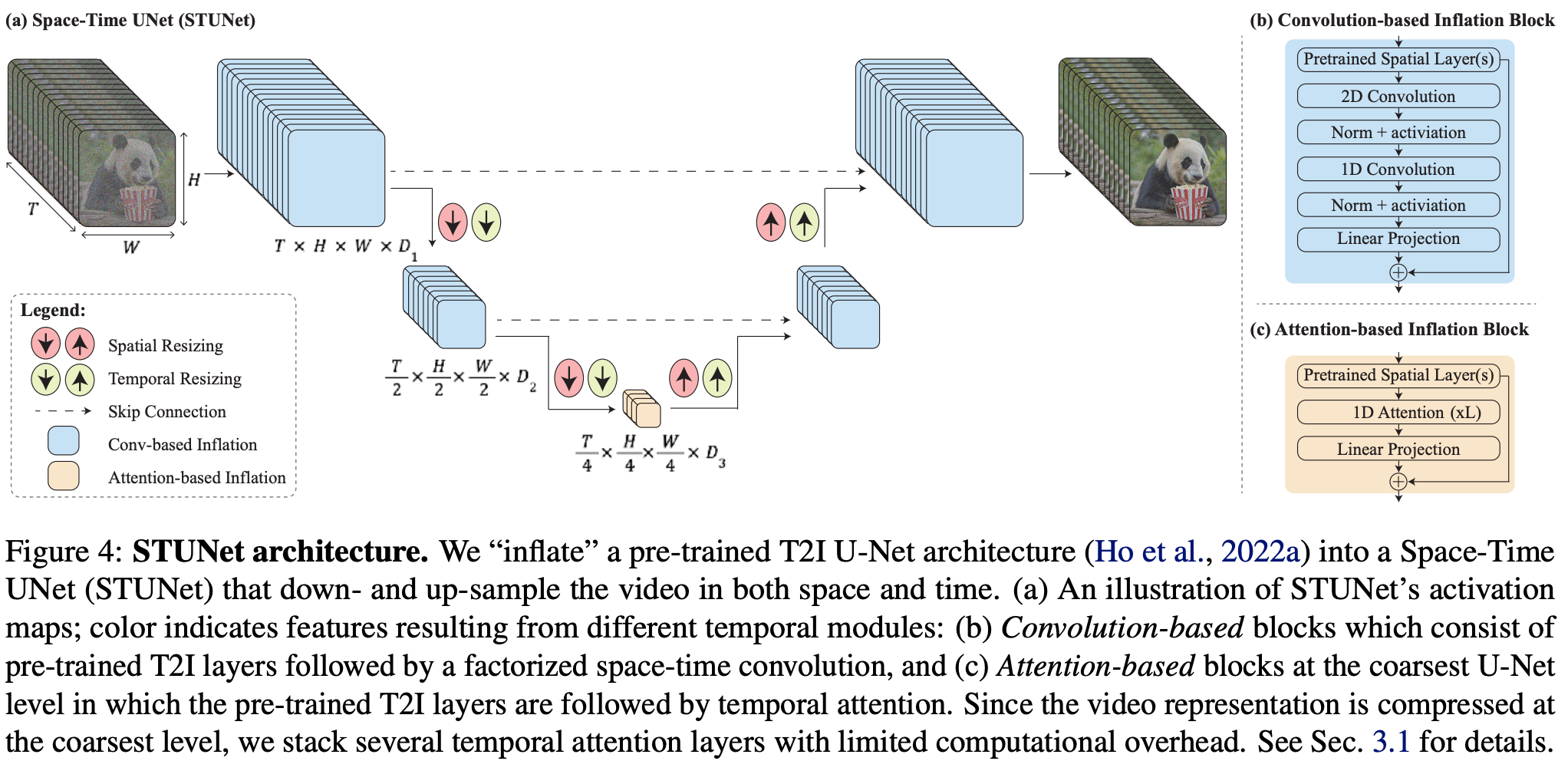
3.3.1 STUNet
- Lumiere의 핵심은 STUNet, 즉 3D U-Net으로 시간(T)과 공간(H, W)을 동시에 처리한다.
- 입력은 (batch, channels, time, height, width) 형태로 들어가며, U-Net의 downsampling과 upsampling이 3D kernel로 시공간을 함께 축소·확대해 비디오의 전반적인 움직임과 구조를 한꺼번에 학습한다.
- 이를 통해 비디오 전체(수십~수백 프레임)를 한 번에 보고, 시공간적 구조와 움직임을 하나의 연속된 latent 흐름으로 학습한다.
- 3D convolution block: factorized 3D conv(공간 + 시간)과 coarsest layer에서 temporal attention을 사용해 효율적으로 시공간 정보를 결합.
- 시공간 skip connection: coarse motion(저해상도, 큰 구조)과 fine detail(고해상도, 세부 질감)을 함께 전달하여 장면의 일관성과 세밀함을 동시에 유지.
💡 기존 3D Unet과 다른점
- STUNet은 시간축으로도 단계적으로 줄였다가(temporal downsampling) 다시 늘림(temporal upsampling)
- temporal attention을 수행
- coarse level(feature map이 가장 작아진, resolution이 가장 작은 단계)에서만 수행
- 시간축이 충분히 줄어있어서 메모리, 연산 부담이 적음
- 결론적으로 기존 3D Unet 대비 메모리 사용량, 연산량을 크게 줄이고 temporal attention으로 long-range 의존성을 학습하게 함.
─────────────────────────────────────────────
[ 기존 3D U-Net ]
─────────────────────────────────────────────
입력: (T=80, H=128, W=128)
Downsample Stage 1
→ (T=80, H=64, W=64) # 시간축 유지
Downsample Stage 2
→ (T=80, H=32, W=32)
Downsample Stage 3 (coarsest)
→ (T=80, H=16, W=16)
==> 시간축 그대로 유지. Temporal context가 convolution receptive field로만 커짐.
Upsample Stage 1
→ (T=80, H=32, W=32)
Upsample Stage 2
→ (T=80, H=64, W=64)
Upsample Stage 3
→ (T=80, H=128, W=128)
─────────────────────────────────────────────
[ STUNet (Lumiere) ]
─────────────────────────────────────────────
입력: (T=80, H=128, W=128)
Downsample Stage 1
→ (T=40, H=64, W=64) # 시간축도 절반
Downsample Stage 2
→ (T=20, H=32, W=32)
Downsample Stage 3 (coarsest)
→ (T=10, H=16, W=16)
==> coarse level에서 temporal attention 수행 (O(T²) → O(10²)로 크게 감소)
Upsample Stage 1
→ (T=20, H=32, W=32)
Upsample Stage 2
→ (T=40, H=64, W=64)
Upsample Stage 3
→ (T=80, H=128, W=128)
3.3.2 SSR
- STUNet은 저해상도(128×128) 비디오를 출력한다.
- 이를 SSR(Spatial Super-Resolution) 네트워크가 temporal window 단위로 업스케일해 1024×576 해상도로 복원한다.
- MultiDiffusion
- 일반적으로 SSR을 프레임 단위로 하면 경계에서 불연속(flickering, popping artifacts)이 생기기 쉽다.
- Lumiere는 MultiDiffusion을 적용해 window를 겹치게(temporal overlapping) 처리하고, 여러 결과를 선형 결합하여 부드럽게 이어지게 한다.
- 이를 통해 장면 전환 없이 자연스러운 시퀀스를 유지.
- 이 STUNet이 만든 낮은 해상도(128×128) 비디오는 SSR 네트워크에서 temporal window 단위로 업스케일되어 고해상도(1024×576)로 복원된다. SSR은 단순한 프레임별 업스케일이 아니라, MultiDiffusion 기법을 사용해 시퀀스를 부드럽게 처리하고 경계에서의 불연속성을 줄인다.
기존 방식과 비교를 하면...
- 기존 cascade + TSR 방식은 keyframe을 생성하고, TSR로 중간 프레임들을 채워서 글로벌 consistency가 깨지기 쉬웠다. 또한 super resolution은 비디오 전체에는 적용 불가능해 window 별 처리를 하여 경계 부분에서 질감이 깨져 보였다.
- Lumiere는 STUNet을 이용하여 시공간을 처음부터 같이 down/up-sampling하여 하나의 연속된 latent flow로 비디오 전체를 학습한다. 또한 MultiDiffusion으로 window를 겹치며 경계없는 부드러운 업스케일링을 하는 것.
실제로 논문에서 Lumiere는 기존에 SVD가 주로 한 번에 14~25프레임 정도를 생성했던 것에 비해, 80프레임(5초, 16fps 기준) 정도를 한 번에 end-to-end로 생성하도록 설계되었다. 이를 위해 Space–Time U-Net(STUNet) 구조를 사용해 시간과 공간을 동시에 다운샘플링·업샘플링하면서 처리한다.
다만 3D convolution과 temporal attention을 포함해 시공간을 한꺼번에 처리하기 때문에 계산량과 메모리 사용량이 기존보다 훨씬 커진다. 논문에서는 이를 완화하기 위해 temporal attention을 가장 coarse한 feature level에서만 수행해 메모리 부담을 줄였지만, 여전히 전체 시퀀스를 하나로 end-to-end 처리하기 때문에 GPU 자원 요구가 크다.
3.4 실험 및 결과
Lumiere는 약 30M 개의 비디오(80프레임, 16fps, 5초 길이)로 구성된 대규모 텍스트-비디오 데이터셋에서 학습되었다. 기본 모델은 128×128 해상도에서 학습되었고, 이후 고해상도(1024×576)로 SSR(Spatial Super-Resolution)을 통해 업스케일되었다.
3.4.1 실험 환경 및 세팅
- Google Research의 A100 GPU 클러스터에서 PyTorch 기반으로 학습이 진행되었다.
- Space–Time U-Net(STUNet)은 pre-trained text-to-image diffusion model(Imagen 기반) 위에 temporal block을 삽입하는 형태로 구성되었으며, coarse level에서만 temporal attention을 수행해 메모리 사용을 조절했다.
- temporal downsampling 및 upsampling을 통해 압축된 시공간 표현에서 대부분의 연산을 수행함으로써 computational cost를 효율화했다.
3.4.2 비교 실험
- Lumiere는 ImagenVideo, AnimateDiff, ZeroScope, VideoLDM, StableVideoDiffusion(SVD) 등과 비교되었다.
- 사용자 평가(AMT 기반 2AFC)에서 Lumiere는 대부분의 경우 "더 자연스럽고 스토리가 이어지는 비디오"로 선택되었으며, 특히 등장 인물의 헤어스타일, 옷 색깔, 배경이 긴 시퀀스에서도 안정적으로 유지되었다.
- Zero-shot UCF101 평가에서는 FVD 332.49, IS 37.54로 기존 모델과 비슷하거나 더 나은 수치를 기록했다.
3.4.3 Ablation 실험

- temporal attention을 coarse level에서만 넣은 구조가 full resolution attention 대비 메모리 사용량과 연산 속도에서 효율적이면서도 temporal consistency에는 큰 손실이 없음을 확인했다.
- Multidiffusion을 temporal window에 적용해 SSR 단계에서 발생할 수 있는 temporal boundary artifact를 효과적으로 줄였다.
이러한 결과는 Lumiere의 Space–Time U-Net 구조가 기존의 cascade TSR 방식보다 전반적으로 더 자연스럽고 globally coherent한 영상을 만들어낸다는 것을 실험적으로 입증했다.
3.5 결론
Lumiere는 기존 텍스트-투-비디오 생성 방식의 한계(짧은 클립 생성과 시간 축 불연속성)를 근본적으로 개선해, 하나의 일관된 긴 영상을 Space–Time diffusion으로 만들어냈다. 이를 통해 자연스럽게 스토리텔링이 가능한 비디오 생성의 새로운 표준을 제시했다.
